







1.简介
上一篇文章里我们介绍了【图像生成】的几种模型以及最直观的DNN的代码和效果,当然可以看出来不足的地方。这篇文章里主要介绍GAN模型的原理,以及它是怎么解决以上问题的。
2.原理
之前DNN的最大问题在于损失计算方法,如果用MSE计算loss的话生成图片将会失去随机性。那么有没有一种损失计算方法,又可以去确保生成图像的真实性,又可以确保生成图像的随机性呢?
GAN提出了这样一种方法,还是用之前的DNN来生成图像(生成器),然后让另外一个额外的DNN网络输入图片(判别器),去判断这张图片是否是真实的还是生成的(输出概率)。
怎么训练生成器和判别器可以使得生成器生成和真实图像相似的虚假图像呢?判别器的训练很好理解,把真实和虚假图像输入去训练就可以,但生成器的训练很难实现,因为它本身的输出(图像)没法与标签直接产生联系,而是需要输入进判别器后得到一个反馈才行。所以生成器的训练会很大程度上受到判别器的制约,这也是为什么GAN训练不稳定的原因。
根据以上不严谨的理解,我们可以大致得到一个pipeline:
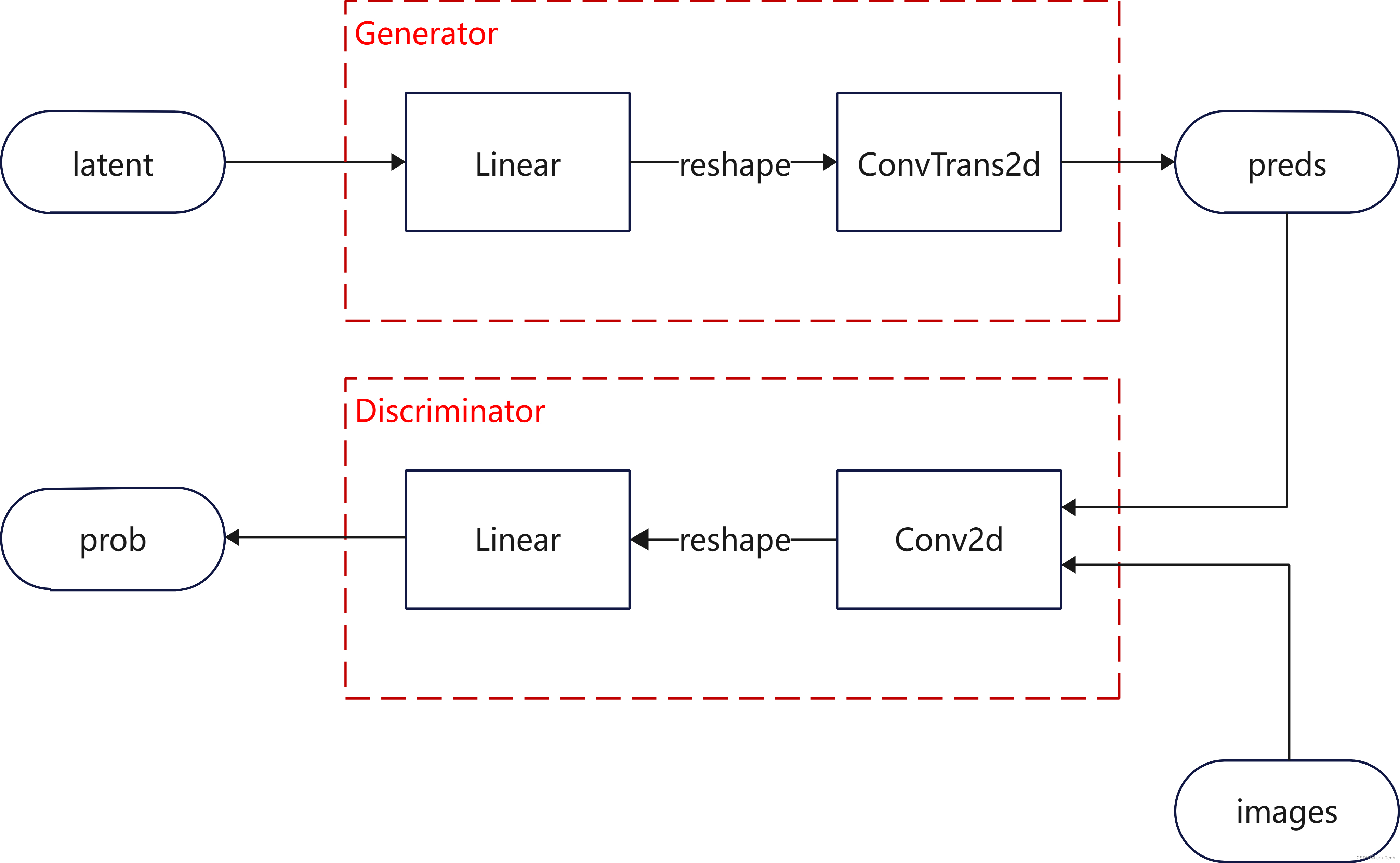
用什么loss训练呢?这个还是需要严谨的推导。
总体来说,我们需要用生成器生成图片,生成图片的分布需要和原始数据集相似,可以表示为,那么似然函数也就是
,现在我们要做的是根据
的分布来找到最大化
的
:
总体来说就是将log似然的期望转换为积分运算,或者直接理解成最小化两个分布的KL散度,也就是相对熵。这个其实是表达generator生成数据和原始数据的相似性,但是我们要通过discriminator来进行表达。具体的loss表现为:
简单点说就是想要真实数据输入进D之后预测为1,虚假数据输入进D之后预测为0。对上式进行求导后发现,所以最优情况下两个概率分布相等,discriminator输出为0.5为最优。
3.代码
OK,接下来我们就用pytorch来实现GAN在MNIST数据集上的生成。需要注意的是数据集和推理部分和之前DNN的没有区别,因此不再着重描述,主要对模型和训练方法上进行说明。
3.1模型
我们在之前只有Generator的基础上加上了Discriminator,两个模型都采用了简单的全连接层和卷积层/反卷积层结构。
class Generator(nn.Module):
def __init__(self, input_dim=100, output_dim=1, class_num=10):
'''
初始化生成网络
:param input_dim:输入维度,也是latent维度
:param output_dim:输出维度,表示最终生成图片的通道数
:param class_num:图像种类,代表condition种类
'''
super(Generator, self).__init__()
# 网络的输入是latent的维度拼接上condition向量的维度
self.input_dim = input_dim + class_num
self.output_dim = output_dim
self.fc = nn.Sequential(
nn.Linear(self.input_dim, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, 128 * 7 * 7),
nn.BatchNorm1d(128 * 7 * 7),
nn.ReLU(),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, 2, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, self.output_dim, 4, 2, 1),
nn.Tanh(),
)
def forward(self, input):
x = self.fc(input)
x = x.view(-1, 128, 7, 7)
x = self.deconv(x)
return x
class Discriminator(nn.Module):
def __init__(self, input_dim=1, output_dim=1):
'''
初始化判别网络
:param input_dim:输入通道数
:param output_dim:输出通道数
'''
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.conv = nn.Sequential(
nn.Conv2d(self.input_dim, 64, 4, 2, 1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
)
self.fc = nn.Sequential(
nn.Linear(128 * 7 * 7, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, self.output_dim),
nn.Sigmoid(),
)
def forward(self, input):
x = self.conv(input)
x = x.view(-1, 128 * 7 * 7)
x = self.fc(x)
return x3.3训练
训练时对D和G分别更新,对D更新需要计算
def train(self):
print('训练开始!!')
for epoch in range(self.epoch):
self.G.train()
self.D.train()
loss_mean_G = 0
loss_mean_D = 0
for i, (images, labels) in enumerate(self.train_dataloader):
# 生成对应batch和维度的latent
z = torch.rand((self.batch_size, self.z_dim)).to(self.device)
images, labels = images.to(self.device), labels.to(self.device)
### 更新D ###
self.optimizerD.zero_grad()
# 真实图像输入D
D_real = self.D(images)
D_real_loss = self.loss(D_real, self.y_real)
# 虚假图像输入D
images_fake = self.G(z)
D_fake = self.D(images_fake)
D_fake_loss = self.loss(D_fake, self.y_fake)
# 整合并更新
D_loss = D_real_loss + D_fake_loss
D_loss.backward()
self.optimizerD.step()
loss_mean_D += D_loss.item()
### 更新G ###
self.optimizerG.zero_grad()
# 虚假图像输入D
images_fake = self.G(z)
D_fake = self.D(images_fake)
# G想要D认为虚假图像是真的,所以与y_real做loss
G_loss = self.loss(D_fake, self.y_real)
# 更新
G_loss.backward()
self.optimizerG.step()
loss_mean_G += G_loss.item()
train_loss_G = loss_mean_G / len(self.train_dataloader)
train_loss_D = loss_mean_D / len(self.train_dataloader)
print('epoch:{}, training loss G:{:.4f}, loss D:{:.4f}'.format(
epoch, train_loss_G,train_loss_D))
self.visualize_results(epoch)3.4推理&可视化
最后我们使用训练好的模型进行推理和可视化。噪声我们使用了固定的随机噪声,最后生成的结果如下:

可以看到结果并不好,训练的时候G的loss也在不断上升,这就是GAN训练不稳定造成的。
4. Wasserstein改进及代码实现
GAN训练不稳定的根本原因是什么呢?我们之前得到了完美情况下的判别器的表达为,把这个式子带入loss表达式可以写成:
这种情况下,就完全依赖与两个概率分布的JS散度,JS散度表示两个分布的相似性。我们通过训练可以将两个分布不断地拉近,最终让。但是当两个概率分布完全没有交集时,JS散度为0,公式就变成了
,因此梯度为0,无法更新。
Wasserstein用类似于“推土机”的方式将两个分布拉近,从而让它们有更多交集。具体的推导公式太过复杂(其实也没怎么看懂)就不在这里细述,感兴趣的可以参考这篇文章:令人拍案叫绝的Wasserstein GAN - 知乎 (zhihu.com)
总结下来其实Wasserstein相比于GAN只改进了4个点:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
我们基于这4点对代码进行改动:
4.1 判别器
这里把判别器最后一层的Sigmoid去掉,意味着我们不再把输出范围限制在0-1,而是负无穷到正无穷。越接近正无穷表示输入图像越真实,越接近负无穷表示输入图像越虚假。
class Discriminator(nn.Module):
def __init__(self, input_dim=1, output_dim=1):
'''
初始化判别网络
:param input_dim:输入通道数
:param output_dim:输出通道数
'''
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.conv = nn.Sequential(
nn.Conv2d(self.input_dim, 64, 4, 2, 1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
)
self.fc = nn.Sequential(
nn.Linear(128 * 7 * 7, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, self.output_dim),
# nn.Sigmoid(),
)
def forward(self, input):
x = self.conv(input)
x = x.view(-1, 128 * 7 * 7)
x = self.fc(x)
return x4.2 loss
由于判别器的输出范围改变,我们也改变了loss的计算方式,用单纯的输出大小来表示loss,从而满足越接近正无穷表示输入图像越真实,越接近负无穷表示输入图像越虚假的条件。
### 判别器更新 ###
# 真实图像输入D
D_real = self.D(images)
# 想要真实图像的D输出尽可能大
D_real_loss = -torch.mean(D_real)
# 虚假图像输入D
images_fake = self.G(z)
D_fake = self.D(images_fake)
# 想要虚假图像的D输出尽可能小
D_fake_loss = torch.mean(D_fake)### 生成器更新 ###
# 虚假图像输入D
images_fake = self.G(z)
D_fake = self.D(images_fake)
# 想要虚假图像的D输出尽可能大
G_loss = -torch.mean(D_fake)4.3 参数截断
按照论文设置的c=0.01对判别器参数进行截断
for p in self.D.parameters():
p.data.clamp_(-self.c, self.c)4.4 判别器
优化器改为非动量优化器
self.optimizerG = optim.RMSprop(self.G.parameters(), lr=self.lr)
self.optimizerD = optim.RMSprop(self.D.parameters(), lr=self.lr)4.5 完整代码及结果
以下是完整的Wasserstein GAN代码及结果:
import torch, time, os
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
import torch.nn.functional as F
class Generator(nn.Module):
def __init__(self, input_dim=100, output_dim=1, class_num=10):
'''
初始化生成网络
:param input_dim:输入维度,也是latent维度
:param output_dim:输出维度,表示最终生成图片的通道数
:param class_num:图像种类,代表condition种类
'''
super(Generator, self).__init__()
# 网络的输入是latent的维度拼接上condition向量的维度
self.input_dim = input_dim + class_num
self.output_dim = output_dim
self.fc = nn.Sequential(
nn.Linear(self.input_dim, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, 128 * 7 * 7),
nn.BatchNorm1d(128 * 7 * 7),
nn.ReLU(),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, 2, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, self.output_dim, 4, 2, 1),
nn.Tanh(),
)
def forward(self, input):
x = self.fc(input)
x = x.view(-1, 128, 7, 7)
x = self.deconv(x)
return x
class Discriminator(nn.Module):
def __init__(self, input_dim=1, output_dim=1):
'''
初始化判别网络
:param input_dim:输入通道数
:param output_dim:输出通道数
'''
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.conv = nn.Sequential(
nn.Conv2d(self.input_dim, 64, 4, 2, 1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
)
self.fc = nn.Sequential(
nn.Linear(128 * 7 * 7, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, self.output_dim),
# nn.Sigmoid(),
)
def forward(self, input):
x = self.conv(input)
x = x.view(-1, 128 * 7 * 7)
x = self.fc(x)
return x
class ImageGenerator(object):
def __init__(self):
'''
初始化,定义超参数、数据集、网络结构等
'''
self.epoch = 50
self.sample_num = 100
self.batch_size = 64
self.z_dim = 100
self.lr = 0.0002
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.init_dataloader()
self.G = Generator(input_dim=self.z_dim, output_dim=self.output_dim, class_num=0).to(self.device)
self.D = Discriminator(input_dim=self.output_dim, output_dim=1).to(self.device)
self.initialize_weights(self.G)
self.initialize_weights(self.D)
self.optimizerG = optim.RMSprop(self.G.parameters(), lr=self.lr)
self.optimizerD = optim.RMSprop(self.D.parameters(), lr=self.lr)
self.c = 0.01
self.n_critic = 5
self.fixed_z = torch.rand((self.sample_num, self.z_dim)).to(self.device)
def initialize_weights(self, net):
for m in net.modules():
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
elif isinstance(m, nn.ConvTranspose2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
def init_dataloader(self):
'''
初始化数据集和dataloader
'''
tf = transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = MNIST('./data/',
train=True,
download=True,
transform=tf)
self.train_dataloader = DataLoader(train_dataset, batch_size=self.batch_size, shuffle=True, drop_last=True)
val_dataset = MNIST('./data/',
train=False,
download=True,
transform=tf)
self.val_dataloader = DataLoader(val_dataset, batch_size=self.batch_size, shuffle=False, drop_last=True)
self.output_dim = self.train_dataloader.__iter__().__next__()[0].shape[1]
def train(self):
print('训练开始!!')
for epoch in range(self.epoch):
self.G.train()
self.D.train()
loss_mean_G = 0
loss_mean_D = 0
for i, (images, labels) in enumerate(self.train_dataloader):
# 生成对应batch和维度的latent
z = torch.rand((self.batch_size, self.z_dim)).to(self.device)
images, labels = images.to(self.device), labels.to(self.device)
### 更新D ###
self.optimizerD.zero_grad()
# 真实图像输入D
D_real = self.D(images)
# 想要真实图像的D输出尽可能大
D_real_loss = -torch.mean(D_real)
# 虚假图像输入D
images_fake = self.G(z)
D_fake = self.D(images_fake)
# 想要虚假图像的D输出尽可能小
D_fake_loss = torch.mean(D_fake)
# 整合并更新
D_loss = D_real_loss + D_fake_loss
D_loss.backward()
self.optimizerD.step()
loss_mean_D += D_loss.item()
# 截断
for p in self.D.parameters():
p.data.clamp_(-self.c, self.c)
### 更新G ###
# 每隔一定间隔再更新G
if (i+1) % self.n_critic == 0:
self.optimizerG.zero_grad()
# 虚假图像输入D
images_fake = self.G(z)
D_fake = self.D(images_fake)
# 想要虚假图像的D输出尽可能大
G_loss = -torch.mean(D_fake)
# 更新
G_loss.backward()
self.optimizerG.step()
loss_mean_G += G_loss.item()
train_loss_G = loss_mean_G / len(self.train_dataloader) * self.n_critic
train_loss_D = loss_mean_D / len(self.train_dataloader)
print('epoch:{}, training loss G:{:.4f}, loss D:{:.4f}'.format(
epoch, train_loss_G,train_loss_D))
self.visualize_results(epoch)
@torch.no_grad()
def visualize_results(self, epoch):
self.G.eval()
# 保存结果路径
output_path = 'results/GAN'
if not os.path.exists(output_path):
os.makedirs(output_path)
tot_num_samples = self.sample_num
image_frame_dim = int(np.floor(np.sqrt(tot_num_samples)))
z = self.fixed_z
generated_images = self.G(z)
# generated_images = (generated_images + 1) / 2
save_image(generated_images, os.path.join(output_path, '{}.jpg'.format(epoch)), nrow=image_frame_dim)
if __name__ == '__main__':
generator = ImageGenerator()
generator.train()

如果训练正常,那么G的loss会是正数,并随着训练不断接近于0,D的loss会是负数,也不断接近于0。这表示判别器越来越分不清生成器生成的虚假图像和真实图像,也就是两个分布越来越接近。
需要注意的是,我们最后没有采用将输出结果(x+1)/2的操作。之所以有这个操作是因为tanh的输出范围是-1到1,所以最终可视化的时候需要将范围调整到0到1,但是经过尝试之后发现调整至0到1之后图像会发白。我分析可能是对真实图像预处理时是将范围调整至0到1而不是-1到1,因此训练使得两个概率分布相似,导致生成器输出的范围也是0到1。
4.5 condition代码及结果
如果我们要生成condition条件下的图像,那么我们按照上一篇DNN的做法,直接把labels进行热编码后与网络输入拼接。注意的是不光生成器,判别器也需要拼接。完整的代码和结果如下:
import torch, time, os
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
import torch.nn.functional as F
class Generator(nn.Module):
def __init__(self, input_dim=100, output_dim=1, class_num=10):
'''
初始化生成网络
:param input_dim:输入维度,也是latent维度
:param output_dim:输出维度,表示最终生成图片的通道数
:param class_num:图像种类,代表condition种类
'''
super(Generator, self).__init__()
# 网络的输入是latent的维度拼接上condition向量的维度
self.input_dim = input_dim + class_num
self.output_dim = output_dim
self.fc = nn.Sequential(
nn.Linear(self.input_dim, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, 128 * 7 * 7),
nn.BatchNorm1d(128 * 7 * 7),
nn.ReLU(),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, 2, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, self.output_dim, 4, 2, 1),
nn.Tanh(),
)
def forward(self, input, labels):
x = torch.cat((input, labels), dim=1)
x = self.fc(x)
x = x.view(-1, 128, 7, 7)
x = self.deconv(x)
return x
class Discriminator(nn.Module):
def __init__(self, input_dim=1, output_dim=1, class_num=10):
'''
初始化判别网络
:param input_dim:输入通道数
:param output_dim:输出通道数
'''
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.conv = nn.Sequential(
nn.Conv2d(self.input_dim, 64, 4, 2, 1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
)
self.fc = nn.Sequential(
nn.Linear(128 * 7 * 7 + class_num, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, self.output_dim),
# nn.Sigmoid(),
)
def forward(self, input, labels):
x = self.conv(input)
x = x.view(-1, 128 * 7 * 7)
x = torch.cat((x, labels), dim=1)
x = self.fc(x)
return x
class ImageGenerator(object):
def __init__(self):
'''
初始化,定义超参数、数据集、网络结构等
'''
self.epoch = 50
self.sample_num = 100
self.batch_size = 64
self.z_dim = 100
self.lr = 0.0002
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.init_dataloader()
self.G = Generator(input_dim=self.z_dim, output_dim=self.output_dim, class_num=10).to(self.device)
self.D = Discriminator(input_dim=self.output_dim, output_dim=1, class_num=10).to(self.device)
self.initialize_weights(self.G)
self.initialize_weights(self.D)
self.optimizerG = optim.RMSprop(self.G.parameters(), lr=self.lr)
self.optimizerD = optim.RMSprop(self.D.parameters(), lr=self.lr)
self.c = 0.01
self.n_critic = 5
self.fixed_z = torch.rand((self.sample_num, self.z_dim)).to(self.device)
def initialize_weights(self, net):
for m in net.modules():
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
elif isinstance(m, nn.ConvTranspose2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
def init_dataloader(self):
'''
初始化数据集和dataloader
'''
tf = transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = MNIST('./data/',
train=True,
download=True,
transform=tf)
self.train_dataloader = DataLoader(train_dataset, batch_size=self.batch_size, shuffle=True, drop_last=True)
val_dataset = MNIST('./data/',
train=False,
download=True,
transform=tf)
self.val_dataloader = DataLoader(val_dataset, batch_size=self.batch_size, shuffle=False, drop_last=True)
self.output_dim = self.train_dataloader.__iter__().__next__()[0].shape[1]
def train(self):
print('训练开始!!')
for epoch in range(self.epoch):
self.G.train()
self.D.train()
loss_mean_G = 0
loss_mean_D = 0
for i, (images, labels) in enumerate(self.train_dataloader):
# 生成对应batch和维度的latent
z = torch.rand((self.batch_size, self.z_dim)).to(self.device)
images, labels = images.to(self.device), labels.to(self.device)
labels = F.one_hot(labels, num_classes=10)
### 更新D ###
self.optimizerD.zero_grad()
# 真实图像输入D
D_real = self.D(images, labels)
# 想要真实图像的D输出尽可能大
D_real_loss = -torch.mean(D_real)
# 虚假图像输入D
images_fake = self.G(z, labels)
D_fake = self.D(images_fake, labels)
# 想要虚假图像的D输出尽可能小
D_fake_loss = torch.mean(D_fake)
# 整合并更新
D_loss = D_real_loss + D_fake_loss
D_loss.backward()
self.optimizerD.step()
loss_mean_D += D_loss.item()
# 截断
for p in self.D.parameters():
p.data.clamp_(-self.c, self.c)
### 更新G ###
# 每隔一定间隔再更新G
if (i+1) % self.n_critic == 0:
self.optimizerG.zero_grad()
# 虚假图像输入D
images_fake = self.G(z, labels)
D_fake = self.D(images_fake, labels)
# 想要虚假图像的D输出尽可能大
G_loss = -torch.mean(D_fake)
# 更新
G_loss.backward()
self.optimizerG.step()
loss_mean_G += G_loss.item()
train_loss_G = loss_mean_G / len(self.train_dataloader) * self.n_critic
train_loss_D = loss_mean_D / len(self.train_dataloader)
print('epoch:{}, training loss G:{:.4f}, loss D:{:.4f}'.format(
epoch, train_loss_G,train_loss_D))
self.visualize_results(epoch)
@torch.no_grad()
def visualize_results(self, epoch):
self.G.eval()
# 保存结果路径
output_path = 'results/GAN'
if not os.path.exists(output_path):
os.makedirs(output_path)
tot_num_samples = self.sample_num
image_frame_dim = int(np.floor(np.sqrt(tot_num_samples)))
z = self.fixed_z
labels = F.one_hot(torch.Tensor(np.repeat(np.arange(10), 10)).to(torch.int64), num_classes=10).to(self.device)
generated_images = self.G(z, labels)
save_image(generated_images, os.path.join(output_path, '{}.jpg'.format(epoch)), nrow=image_frame_dim)
if __name__ == '__main__':
generator = ImageGenerator()
generator.train()

业务合作/学习交流+v:lizhiTechnology
如果想要了解更多图像生成相关知识,可以参考我的专栏和其他相关文章:
【图像生成】(一) DNN 原理 & pytorch代码实例_pytorch dnn代码-优快云博客
【图像生成】(二) GAN 原理 & pytorch代码实例_gan代码-优快云博客
【图像生成】(三) VAE原理 & pytorch代码实例_vae算法 是如何生成图的-优快云博客
【图像生成】(四) Diffusion原理 & pytorch代码实例_diffusion unet-优快云博客
如果想要了解更多深度学习相关知识,可以参考我的其他文章:
【优化器】(一) SGD原理 & pytorch代码解析_sgd优化器-优快云博客



















 9024
9024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









