



 本文采用CNN实现运动鞋品牌分类识别,介绍了实现代码与执行结果,包括引入库、导入数据、构建模型等步骤。还详细讲解了常用学习率衰减方法、自适应学习率方法,以及设置动态学习率ExponentialDecay,能帮助优化算法收敛,提高模型性能。
本文采用CNN实现运动鞋品牌分类识别,介绍了实现代码与执行结果,包括引入库、导入数据、构建模型等步骤。还详细讲解了常用学习率衰减方法、自适应学习率方法,以及设置动态学习率ExponentialDecay,能帮助优化算法收敛,提高模型性能。
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
文章目录
前言
本文将采用CNN实现运动鞋品牌分类识别。较上篇文章,本文在训练模型时增加callbacks增加设置动态学习率以及早停与保存最佳模型参数。简单讲述实现代码与执行结果,并浅谈涉及知识点,涉及知识点包括。
关键字:常用的学习率衰减方法,自适应学习率方法,设置动态学习率ExponentialDecay。
一、我的环境
- 电脑系统:Windows 11
- 语言环境:python 3.8.6
- 编译器:pycharm
- 深度学习环境:TensorFlow 2.10.1
二、代码实现与执行结果
1.引入库
from PIL import Image
import numpy as np
from pathlib import Path
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印
2.设置GPU(如果使用的是CPU可以忽略这步)
'''前期工作-设置GPU(如果使用的是CPU可以忽略这步)'''
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0], "GPU")
本人电脑无独显,故该步骤被注释,未执行。
3.导入数据
'''前期工作-导入数据'''
data_dir = r"D:\DeepLearning\data\SneakerBrands"
data_dir = Path(data_dir)
4.查看数据
'''前期工作-查看数据'''
image_count = len(list(data_dir.glob('*/*/*.jpg')))
print("图片总数为:", image_count)
roses = list(data_dir.glob('train/nike/*.jpg'))
image = Image.open(str(roses[0]))
# 查看图像实例的属性
print(image.format, image.size, image.mode)
plt.imshow(image)
plt.show()
执行结果:
图片总数为: 578
JPEG (240, 240) RGB
5.加载数据
'''数据预处理-加载数据'''
batch_size = 32
img_height = 224
img_width = 224
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir / "train",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir / "test",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
# 我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names
print(class_names)
运行结果:
Found 502 files belonging to 2 classes.
Found 76 files belonging to 2 classes.
['adidas', 'nike']
6.可视化数据
'''数据预处理-可视化数据'''
plt.figure(figsize=(25, 20))
for images, labels in train_ds.take(1):
for i in range(20):
ax = plt.subplot(5, 4, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]], fontsize=40)
plt.axis("off")
# 显示图片
plt.show()

7.再次检查数据
'''数据预处理-再次检查数据'''
# Image_batch是形状的张量(32,224,224,3)。这是一批形状224x224x3的32张图片(最后一维指的是彩色通道RGB)。
# Label_batch是形状(32,)的张量,这些标签对应32张图片
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
运行结果
(32, 224, 224, 3)
(32,)
8.配置数据集
本人电脑无GPU加速,故并未起到加速作用
'''数据预处理-配置数据集'''
AUTOTUNE = tf.data.AUTOTUNE
# shuffle():打乱数据,关于此函数的详细介绍可以参考:https://zhuanlan.zhihu.com/p/42417456
# prefetch():预取数据,加速运行
# cache():将数据集缓存到内存当中,加速运行
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
9.构建CNN网络模型
'''构建CNN网络'''
"""
关于卷积核的计算不懂的可以参考文章:https://blog.youkuaiyun.com/qq_38251616/article/details/114278995
layers.Dropout(0.4) 作用是防止过拟合,提高模型的泛化能力。
关于Dropout层的更多介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/115826689
"""
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1. / 255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Dropout(0.3),
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.3),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(len(class_names)) # 输出层,输出预期结果
])
model.summary() # 打印网络结构
网络结构结果如下:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling (Rescaling) (None, 224, 224, 3) 0
conv2d (Conv2D) (None, 222, 222, 16) 448
average_pooling2d (AverageP (None, 111, 111, 16) 0
ooling2D)
conv2d_1 (Conv2D) (None, 109, 109, 32) 4640
average_pooling2d_1 (Averag (None, 54, 54, 32) 0
ePooling2D)
dropout (Dropout) (None, 54, 54, 32) 0
conv2d_2 (Conv2D) (None, 52, 52, 64) 18496
dropout_1 (Dropout) (None, 52, 52, 64) 0
flatten (Flatten) (None, 173056) 0
dense (Dense) (None, 128) 22151296
dense_1 (Dense) (None, 2) 258
=================================================================
Total params: 22,175,138
Trainable params: 22,175,138
Non-trainable params: 0
10.编译模型
'''编译模型'''
# 损失函数(loss):用于衡量模型在训练期间的准确率。
# 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
# 指标(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率
# 设置初始学习率
initial_learning_rate = 0.1
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=10, # 敲黑板!!!这里是指 steps,不是指epochs
decay_rate=0.92, # lr经过一次衰减就会变成 decay_rate*lr
staircase=True)
# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
# 编译
model.compile(optimizer=optimizer,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
11.训练模型
'''训练模型'''
epochs = 50
# 保存最佳模型参数
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
save_weights_only=True)
# 设置早停
earlystopper = EarlyStopping(monitor='val_accuracy',
min_delta=0.001,
patience=20,
verbose=1)
history = model.fit(train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks=[checkpointer, earlystopper])
训练记录如下:
Epoch 1/50
16/16 [==============================] - ETA: 0s - loss: 0.7337 - accuracy: 0.4681
Epoch 1: val_accuracy improved from -inf to 0.53947, saving model to best_model.h5
16/16 [==============================] - 6s 314ms/step - loss: 0.7337 - accuracy: 0.4681 - val_loss: 0.6872 - val_accuracy: 0.5395
Epoch 2/50
16/16 [==============================] - ETA: 0s - loss: 0.6844 - accuracy: 0.5299
Epoch 2: val_accuracy improved from 0.53947 to 0.60526, saving model to best_model.h5
16/16 [==============================] - 5s 308ms/step - loss: 0.6844 - accuracy: 0.5299 - val_loss: 0.6728 - val_accuracy: 0.6053
Epoch 3/50
16/16 [==============================] - ETA: 0s - loss: 0.6778 - accuracy: 0.5498
Epoch 3: val_accuracy did not improve from 0.60526
16/16 [==============================] - 5s 298ms/step - loss: 0.6778 - accuracy: 0.5498 - val_loss: 0.6649 - val_accuracy: 0.6053
Epoch 4/50
16/16 [==============================] - ETA: 0s - loss: 0.6633 - accuracy: 0.6255
Epoch 4: val_accuracy did not improve from 0.60526
16/16 [==============================] - 5s 305ms/step - loss: 0.6633 - accuracy: 0.6255 - val_loss: 0.6528 - val_accuracy: 0.6053
Epoch 5/50
16/16 [==============================] - ETA: 0s - loss: 0.6513 - accuracy: 0.6096
Epoch 5: val_accuracy did not improve from 0.60526
16/16 [==============================] - 7s 415ms/step - loss: 0.6513 - accuracy: 0.6096 - val_loss: 0.6491 - val_accuracy: 0.6053
Epoch 6/50
16/16 [==============================] - ETA: 0s - loss: 0.6442 - accuracy: 0.6414
Epoch 6: val_accuracy did not improve from 0.60526
16/16 [==============================] - 7s 452ms/step - loss: 0.6442 - accuracy: 0.6414 - val_loss: 0.6385 - val_accuracy: 0.5658
Epoch 7/50
16/16 [==============================] - ETA: 0s - loss: 0.6272 - accuracy: 0.6394
Epoch 7: val_accuracy improved from 0.60526 to 0.61842, saving model to best_model.h5
16/16 [==============================] - 8s 487ms/step - loss: 0.6272 - accuracy: 0.6394 - val_loss: 0.6389 - val_accuracy: 0.6184
Epoch 8/50
16/16 [==============================] - ETA: 0s - loss: 0.6178 - accuracy: 0.6594
Epoch 8: val_accuracy did not improve from 0.61842
16/16 [==============================] - 8s 471ms/step - loss: 0.6178 - accuracy: 0.6594 - val_loss: 0.6260 - val_accuracy: 0.5921
Epoch 9/50
16/16 [==============================] - ETA: 0s - loss: 0.6116 - accuracy: 0.6594
Epoch 9: val_accuracy improved from 0.61842 to 0.63158, saving model to best_model.h5
16/16 [==============================] - 8s 496ms/step - loss: 0.6116 - accuracy: 0.6594 - val_loss: 0.6356 - val_accuracy: 0.6316
Epoch 10/50
16/16 [==============================] - ETA: 0s - loss: 0.6066 - accuracy: 0.6912
Epoch 10: val_accuracy improved from 0.63158 to 0.64474, saving model to best_model.h5
16/16 [==============================] - 8s 476ms/step - loss: 0.6066 - accuracy: 0.6912 - val_loss: 0.6316 - val_accuracy: 0.6447
Epoch 11/50
16/16 [==============================] - ETA: 0s - loss: 0.5989 - accuracy: 0.6753
Epoch 11: val_accuracy improved from 0.64474 to 0.68421, saving model to best_model.h5
16/16 [==============================] - 7s 471ms/step - loss: 0.5989 - accuracy: 0.6753 - val_loss: 0.6101 - val_accuracy: 0.6842
Epoch 12/50
16/16 [==============================] - ETA: 0s - loss: 0.5851 - accuracy: 0.7331
Epoch 12: val_accuracy did not improve from 0.68421
16/16 [==============================] - 7s 464ms/step - loss: 0.5851 - accuracy: 0.7331 - val_loss: 0.6167 - val_accuracy: 0.6316
Epoch 13/50
16/16 [==============================] - ETA: 0s - loss: 0.5838 - accuracy: 0.6972
Epoch 13: val_accuracy did not improve from 0.68421
16/16 [==============================] - 8s 475ms/step - loss: 0.5838 - accuracy: 0.6972 - val_loss: 0.6129 - val_accuracy: 0.6447
Epoch 14/50
16/16 [==============================] - ETA: 0s - loss: 0.5720 - accuracy: 0.7291
Epoch 14: val_accuracy did not improve from 0.68421
16/16 [==============================] - 7s 467ms/step - loss: 0.5720 - accuracy: 0.7291 - val_loss: 0.6002 - val_accuracy: 0.6711
Epoch 15/50
16/16 [==============================] - ETA: 0s - loss: 0.5661 - accuracy: 0.7430
Epoch 15: val_accuracy did not improve from 0.68421
16/16 [==============================] - 8s 474ms/step - loss: 0.5661 - accuracy: 0.7430 - val_loss: 0.5981 - val_accuracy: 0.6579
Epoch 16/50
16/16 [==============================] - ETA: 0s - loss: 0.5612 - accuracy: 0.7390
Epoch 16: val_accuracy did not improve from 0.68421
16/16 [==============================] - 8s 475ms/step - loss: 0.5612 - accuracy: 0.7390 - val_loss: 0.5989 - val_accuracy: 0.6579
Epoch 17/50
16/16 [==============================] - ETA: 0s - loss: 0.5555 - accuracy: 0.7251
Epoch 17: val_accuracy did not improve from 0.68421
16/16 [==============================] - 7s 467ms/step - loss: 0.5555 - accuracy: 0.7251 - val_loss: 0.5902 - val_accuracy: 0.6711
Epoch 18/50
16/16 [==============================] - ETA: 0s - loss: 0.5548 - accuracy: 0.7530
Epoch 18: val_accuracy did not improve from 0.68421
16/16 [==============================] - 8s 473ms/step - loss: 0.5548 - accuracy: 0.7530 - val_loss: 0.5889 - val_accuracy: 0.6842
Epoch 19/50
16/16 [==============================] - ETA: 0s - loss: 0.5519 - accuracy: 0.7331
Epoch 19: val_accuracy did not improve from 0.68421
16/16 [==============================] - 8s 471ms/step - loss: 0.5519 - accuracy: 0.7331 - val_loss: 0.5958 - val_accuracy: 0.6579
Epoch 20/50
16/16 [==============================] - ETA: 0s - loss: 0.5466 - accuracy: 0.7331
Epoch 20: val_accuracy improved from 0.68421 to 0.69737, saving model to best_model.h5
16/16 [==============================] - 8s 484ms/step - loss: 0.5466 - accuracy: 0.7331 - val_loss: 0.5814 - val_accuracy: 0.6974
Epoch 21/50
16/16 [==============================] - ETA: 0s - loss: 0.5463 - accuracy: 0.7351
Epoch 21: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 470ms/step - loss: 0.5463 - accuracy: 0.7351 - val_loss: 0.5878 - val_accuracy: 0.6842
Epoch 22/50
16/16 [==============================] - ETA: 0s - loss: 0.5408 - accuracy: 0.7470
Epoch 22: val_accuracy did not improve from 0.69737
16/16 [==============================] - 8s 476ms/step - loss: 0.5408 - accuracy: 0.7470 - val_loss: 0.5808 - val_accuracy: 0.6842
Epoch 23/50
16/16 [==============================] - ETA: 0s - loss: 0.5397 - accuracy: 0.7430
Epoch 23: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 456ms/step - loss: 0.5397 - accuracy: 0.7430 - val_loss: 0.5813 - val_accuracy: 0.6842
Epoch 24/50
16/16 [==============================] - ETA: 0s - loss: 0.5390 - accuracy: 0.7470
Epoch 24: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 458ms/step - loss: 0.5390 - accuracy: 0.7470 - val_loss: 0.5804 - val_accuracy: 0.6842
Epoch 25/50
16/16 [==============================] - ETA: 0s - loss: 0.5360 - accuracy: 0.7629
Epoch 25: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 452ms/step - loss: 0.5360 - accuracy: 0.7629 - val_loss: 0.5782 - val_accuracy: 0.6974
Epoch 26/50
16/16 [==============================] - ETA: 0s - loss: 0.5343 - accuracy: 0.7629
Epoch 26: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 472ms/step - loss: 0.5343 - accuracy: 0.7629 - val_loss: 0.5765 - val_accuracy: 0.6842
Epoch 27/50
16/16 [==============================] - ETA: 0s - loss: 0.5318 - accuracy: 0.7530
Epoch 27: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 467ms/step - loss: 0.5318 - accuracy: 0.7530 - val_loss: 0.5802 - val_accuracy: 0.6842
Epoch 28/50
16/16 [==============================] - ETA: 0s - loss: 0.5327 - accuracy: 0.7450
Epoch 28: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 469ms/step - loss: 0.5327 - accuracy: 0.7450 - val_loss: 0.5774 - val_accuracy: 0.6974
Epoch 29/50
16/16 [==============================] - ETA: 0s - loss: 0.5293 - accuracy: 0.7570
Epoch 29: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 462ms/step - loss: 0.5293 - accuracy: 0.7570 - val_loss: 0.5791 - val_accuracy: 0.6842
Epoch 30/50
16/16 [==============================] - ETA: 0s - loss: 0.5306 - accuracy: 0.7629
Epoch 30: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 462ms/step - loss: 0.5306 - accuracy: 0.7629 - val_loss: 0.5786 - val_accuracy: 0.6842
Epoch 31/50
16/16 [==============================] - ETA: 0s - loss: 0.5310 - accuracy: 0.7649
Epoch 31: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 464ms/step - loss: 0.5310 - accuracy: 0.7649 - val_loss: 0.5745 - val_accuracy: 0.6842
Epoch 32/50
16/16 [==============================] - ETA: 0s - loss: 0.5294 - accuracy: 0.7530
Epoch 32: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 459ms/step - loss: 0.5294 - accuracy: 0.7530 - val_loss: 0.5758 - val_accuracy: 0.6974
Epoch 33/50
16/16 [==============================] - ETA: 0s - loss: 0.5314 - accuracy: 0.7470
Epoch 33: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 456ms/step - loss: 0.5314 - accuracy: 0.7470 - val_loss: 0.5786 - val_accuracy: 0.6842
Epoch 34/50
16/16 [==============================] - ETA: 0s - loss: 0.5278 - accuracy: 0.7629
Epoch 34: val_accuracy did not improve from 0.69737
16/16 [==============================] - 8s 474ms/step - loss: 0.5278 - accuracy: 0.7629 - val_loss: 0.5770 - val_accuracy: 0.6974
Epoch 35/50
16/16 [==============================] - ETA: 0s - loss: 0.5277 - accuracy: 0.7550
Epoch 35: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 460ms/step - loss: 0.5277 - accuracy: 0.7550 - val_loss: 0.5760 - val_accuracy: 0.6974
Epoch 36/50
16/16 [==============================] - ETA: 0s - loss: 0.5260 - accuracy: 0.7510
Epoch 36: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 456ms/step - loss: 0.5260 - accuracy: 0.7510 - val_loss: 0.5752 - val_accuracy: 0.6842
Epoch 37/50
16/16 [==============================] - ETA: 0s - loss: 0.5293 - accuracy: 0.7570
Epoch 37: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 457ms/step - loss: 0.5293 - accuracy: 0.7570 - val_loss: 0.5752 - val_accuracy: 0.6842
Epoch 38/50
16/16 [==============================] - ETA: 0s - loss: 0.5251 - accuracy: 0.7649
Epoch 38: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 464ms/step - loss: 0.5251 - accuracy: 0.7649 - val_loss: 0.5762 - val_accuracy: 0.6974
Epoch 39/50
16/16 [==============================] - ETA: 0s - loss: 0.5270 - accuracy: 0.7510
Epoch 39: val_accuracy did not improve from 0.69737
16/16 [==============================] - 7s 465ms/step - loss: 0.5270 - accuracy: 0.7510 - val_loss: 0.5759 - val_accuracy: 0.6974
Epoch 40/50
16/16 [==============================] - ETA: 0s - loss: 0.5250 - accuracy: 0.7669
Epoch 40: val_accuracy did not improve from 0.69737
16/16 [==============================] - 8s 472ms/step - loss: 0.5250 - accuracy: 0.7669 - val_loss: 0.5752 - val_accuracy: 0.6842
Epoch 40: early stopping
12.模型评估
'''模型评估'''
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(loss))
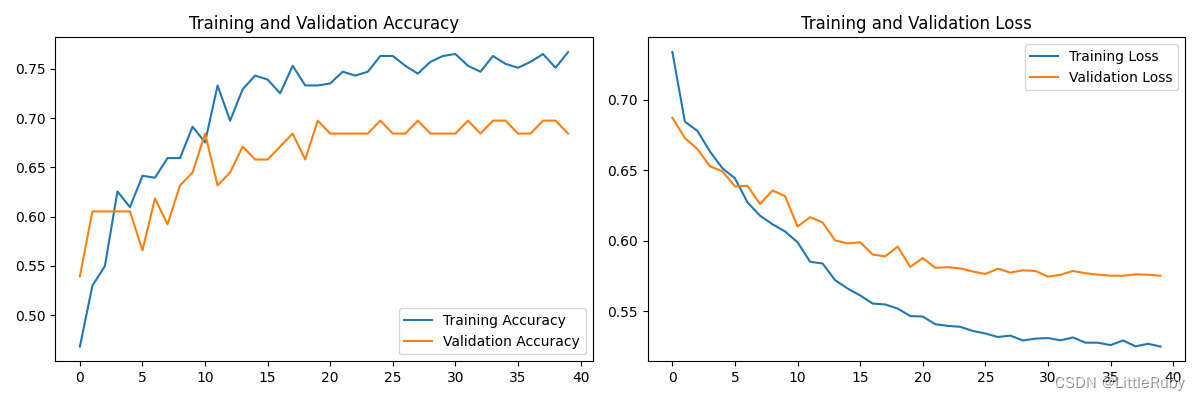
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
执行结果
13.指定图片进行预测
'''指定图片进行预测'''
# 加载效果最好的模型权重
model.load_weights('best_model.h5')
# img = Image.open("D:/DeepLearning/data/monkeypox_recognition/Others/NM01_01_00.jpg") #这里选择你需要预测的图片
img = Image.open(r"D:\DeepLearning\data\SneakerBrands\test\adidas\26.jpg") #这里选择你需要预测的图片
print("type(img):", type(img), "img.size:", img.size)
# 对数据进行处理
img_array0 = np.asarray(img) # img.size=(224,224),tf.image.resize需传入3维或四维向量,采用np.asarray转换img_array.shape=(224,224,3)
print("img_array0.shape:", img_array0.shape)
image = tf.image.resize(img_array0, [img_height, img_width])
image1 = tf.keras.utils.array_to_img(image)
print("image:", type(image), image.shape)
print("image1:", type(image1), image1.size)
plt.imshow(image1)
plt.show()
img_array = tf.expand_dims(image, 0)
print("img_array:", type(img_array), img_array.shape)
predictions = model.predict(img_array) # 这里选用你已经训练好的模型
print("预测结果为:", class_names[np.argmax(predictions)])
运行结果:

type(img): <class 'PIL.JpegImagePlugin.JpegImageFile'> img.size: (240, 240)
img_array0.shape: (240, 240, 3)
image: <class 'tensorflow.python.framework.ops.EagerTensor'> (224, 224, 3)
image1: <class 'PIL.Image.Image'> (224, 224)
img_array: <class 'tensorflow.python.framework.ops.EagerTensor'> (1, 224, 224, 3)
1/1 [==============================] - 0s 99ms/step
预测结果为: adidas
三、知识点详解
1.常用的学习率衰减方法
深度学习中的学习率是一个非常重要的超参数,对模型的训练和结果影响极大。在深度学习模型中,学习率决定了参数更新的步长,因此合理设置学习率对于优化算法的收敛速度、模型的训练效果以及泛化性能都有很大的影响。
1.1 学习率衰减
学习率衰减是一种常见的优化算法,它可以随着训练的进行,逐渐减小学习率,从而使得模型在训练初期能够快速地收敛,而在训练后期能够更加稳定地更新参数。学习率衰减的方法有很多种,包括Step Decay、Exponential Decay、Polynomial Decay等。
Step Decay是一种常见的学习率衰减方法,它是在训练的过程中,根据固定的步数对学习率进行逐步地降低。例如,假设初始学习率为0.1,每隔10个epoch将学习率降低10倍,那么当训练到第11个epoch时,学习率将变为0.01,当训练到第21个epoch时,学习率将变为0.001,以此类推。这种方法简单易行,但是需要手动设置衰减的步数和衰减的幅度,不太灵活。
Exponential Decay是一种常见的指数衰减方法,它可以根据训练的epoch数来逐渐减小学习率。具体而言,Exponential Decay方法的学习率衰减规则如下:
α = α 0 ⋅ e − k t \alpha= \alpha_0 · e^{-kt} α=α0⋅e−kt
其中, α 0 \alpha_0 α0 表示初始学习率, k k k为衰减系数, t t t表示训练的epoch数。随着训练的进行,t tt会不断增大,因此学习率会不断减小。Exponential Decay方法可以通过设置不同的k kk值来控制学习率的衰减速度,从而达到更好的训练效果。
Polynomial Decay是一种常见的多项式衰减方法,它可以通过多项式函数来逐渐减小学习率。具体而言,Polynomial Decay方法的学习率衰减规则如下:
α
=
α
⋅
(
1
−
t
T
)
p
\alpha=\alpha\cdot (1 - \frac{t}{T})^p
α=α⋅(1−Tt)p
其中, α 0 \alpha_0 α0 表示初始学习率, p p p为多项式的幂次数, t t t表示训练的epoch数, T T T为总的训练epoch数。随着训练的进行, t t t会不断增大,因此学习率会不断减小,同时随着 p p p的增大,学习率的衰减速度也会加快。
1.2 余弦退火
余弦退火(Cosine Annealing)是一种新兴的学习率衰减方法,它通过余弦函数来逐渐减小学习率,从而达到更好的训练效果。具体而言,余弦退火方法的学习率衰减规则如下:
α
=
α
0
⋅
1
+
cos
(
π
⋅
t
T
)
2
\alpha = \alpha_0 \cdot \frac{1 + \cos(\frac{\pi \cdot t}{T})}{2}
α=α0⋅21+cos(Tπ⋅t)
其中, α 0 \alpha_0 α0 表示初始学习率, t t t表示训练的epoch数, T T T为总的训练epoch数。随着训练的进行, t t t会不断增大,因此学习率会不断减小,同时余弦函数的周期也会不断缩小,从而使得学习率在训练过程中逐渐降低。
1.3 One Cycle Learning Rate
One Cycle Learning Rate是一种比较新的学习率衰减方法,它通过在训练初期使用一个较大的学习率,从而快速地收敛到一个局部最优解,然后在训练后期使用一个较小的学习率,从而逐步地优化模型。具体而言,One Cycle Learning Rate方法的学习率变化规则如下:
- 在训练初期,使用较大的学习率(如初始学习率的10倍),从而快速地收敛到一个局部最优解;
- 然后在训练中期,使用较小的学习率,从而逐步地优化模型;
- 最后在训练后期,再次使用较小的学习率,从而让模型更加稳定。
One Cycle Learning Rate方法可以有效地提高模型的训练速度和泛化性能,但是需要仔细调整超参数,否则容易导致模型的过拟合。
2. 自适应学习率方法
除了学习率衰减方法之外,深度学习中还有很多自适应学习率方法,包括Adagrad、Adadelta、Adam等。这些方法都是基于梯度信息来自适应地调整学习率,从而在训练过程中更加稳定和高效。
2.1 Adagrad
Adagrad是一种自适应学习率方法,它可以根据参数梯度的大小来动态地调整学习率。具体而言,Adagrad方法的学习率更新规则如下:
θ
t
+
1
,
i
=
θ
t
,
i
−
η
∑
j
=
0
t
(
g
j
,
i
)
2
+
ϵ
g
t
,
i
θ_{ t+1,i}=θ_{t,i} − \frac{η}{∑_{j=0}^t(g_{j,i })^2 +ϵ} g_{t,i}
θt+1,i=θt,i−∑j=0t(gj,i)2+ϵηgt,i
其中, η η η 表示初始学习率, g t , i g_{t,i} gt,i 表示 t t t时刻第 i i i 个参数的梯度, ϵ \epsilon ϵ是一个非常小的常数,用于防止分母为0。Adagrad方法的优点在于它可以根据参数的梯度大小自适应地调整学习率,从而更好地适应不同的数据分布和参数更新。但是Adagrad方法也有一些缺点,比如需要存储梯度平方和的累积值,导致内存占用较大;另外,由于学习率是逐渐减小的,因此可能会导致模型在后期训练时收敛速度变慢。
2.2 Adadelta
Adadelta是一种自适应学习率方法,它可以根据参数梯度的大小和历史梯度信息来动态地调整学习率Adadelta方法的优点在于它可以动态地调整学习率,并且不需要存储梯度平方和的累积值,因此内存占用较小。但是Adadelta方法也有一些缺点,比如需要手动设置一些超参数,例如平均梯度的衰减率和初始的平均梯度值等。
2.3 Adam
Adam是一种自适应学习率方法,它可以根据参数梯度的大小和历史梯度信息来动态地调整学习率,并且还可以适应不同的数据分布和参数更新。具体而言,Adam方法的学习率更新规则如下:
m
t
=
β
1
⋅
m
t
−
1
+
(
1
−
β
1
)
⋅
g
t
m_t = β_1 ⋅ m_{ t − 1} + ( 1 − β_1 ) ⋅ g_t
mt=β1⋅mt−1+(1−β1)⋅gt
v
t
=
β
2
⋅
v
t
−
1
+
(
1
−
β
2
)
⋅
g
t
2
v_t = β_2 ⋅ v_{t − 1} + ( 1 − β_2 ) ⋅ g_t^2
vt=β2⋅vt−1+(1−β2)⋅gt2
m
^
t
=
m
t
1
−
β
1
t
\hat{m} ^ t = \frac{m_t}{ 1 − β_1^t}
m^t=1−β1tmt
v
^
t
=
v
t
1
−
β
2
t
\hat{v} ^ t =\frac{ v_t }{1− β_2^t}
v^t=1−β2tvt
Δ
x
t
=
−
α
v
t
+
ϵ
⋅
m
^
t
Δ_{x_t} = −\frac{ α}{\sqrt {v ^ t} + ϵ } ⋅\hat{m} ^ t
Δxt=−vt+ϵα⋅m^t
其中,
g
t
g_t
gt 表示参数的梯度,
m
t
m_t
mt 和
v
t
v_t
vt分别表示梯度的一阶和二阶矩,
β
1
β_1
β1和
β
2
β _2
β2是衰减率,
m
^
t
\hat{m}_t
m^t和
v
^
t
\hat{v}_t
v^t分别表示修正后的一阶和二阶矩,
α
\alpha
α表示初始学习率,
ϵ
\epsilon
ϵ是一个非常小的常数,用于防止分母为0。
Adam方法的优点在于它不仅可以动态地调整学习率,还可以适应不同的数据分布和参数更新,从而在训练过程中更加稳定和高效。但是Adam方法也有一些缺点,比如需要手动设置一些超参数,例如衰减率和初始学习率等。
三、学习率预热
学习率预热是一种常见的训练技巧,它可以在训练初期使用一个较小的学习率,从而避免模型在训练初期过度更新参数,导致模型不稳定。具体而言,学习率预热的方法是在训练前先使用一个较小的学习率进行一些预热操作,例如在训练初期进行一些预热的epoch,然后再逐步地增加学习率,从而使得模型更加稳定和高效。
学习率预热的方法可以有效地避免模型在训练初期过度更新参数,导致模型不稳定,同时也可以加速模型的收敛速度,提高训练效率和泛化性能。
3.设置动态学习率ExponentialDecay
ExponentialDecay函数:
tf.keras.optimizers.schedules.ExponentialDecay是 TensorFlow 中的一个学习率衰减策略,用于在训练神经网络时动态地降低学习率。学习率衰减是一种常用的技巧,可以帮助优化算法更有效地收敛到全局最小值,从而提高模型的性能。
函数原型
tf.train.exponential_decay(
learning_rate,初始学习率
global_step,当前迭代次数
decay_steps,衰减速度(在迭代到该次数时学习率衰减为learning_rate * decay_rate)
decay_rate,学习率衰减系数,通常介于0-1之间。
staircase=False,(默认值为False,当为True时,(global_step/decay_steps)则被转化为整数) ,选择不同的衰减方式。
name=None
)
🔎 主要参数:
● initial_learning_rate(初始学习率):初始学习率大小。
● decay_steps(衰减步数):学习率衰减的步数。在经过 decay_steps 步后,学习率将按照指数函数衰减。例如,如果 decay_steps 设置为 10,则每10步衰减一次。
● decay_rate(衰减率):学习率的衰减率。它决定了学习率如何衰减。通常,取值在 0 到 1 之间。
● staircase(阶梯式衰减):一个布尔值,控制学习率的衰减方式。如果设置为 True,则学习率在每个 decay_steps 步之后直接减小,形成阶梯状下降。如果设置为 False,则学习率将连续衰减。
注:这里设置的动态学习率为:指数衰减型(ExponentialDecay)。在每一个epoch开始前,学习率(learning_rate)都将会重置为初始学习率(initial_learning_rate),然后再重新开始衰减。计算公式如下:
learning_rate = initial_learning_rate * decay_rate ^ (global_step / decay_steps)
直观解释:假设给定初始学习率learning_rate为0.1,学习率衰减率为0.1,decay_steps为10000。
则随着迭代次数从1到10000,当前的学习率decayed_learning_rate慢慢的从0.1降低为0.10.1=0.01,
当迭代次数到20000,当前的学习率慢慢的从0.01降低为0.10.1^2=0.001,以此类推。
也就是说每10000次迭代,学习率衰减为前10000次的十分之一,该衰减是连续的,这是在staircase为False的情况下。
如果staircase为True,则global_step / decay_steps始终取整数,也就是说衰减是突变的,每decay_steps次变化一次,变化曲线是阶梯状。
学习率大与学习率小的优缺点分析:
学习率大
● 优点:
1、加快学习速率。
2、有助于跳出局部最优值。
● 缺点:
1、导致模型训练不收敛。
2、单单使用大学习率容易导致模型不精确。
学习率小
● 优点:
1、有助于模型收敛、模型细化。
2、提高模型精度。
● 缺点:
1、很难跳出局部最优值。
2、收敛缓慢。
总结
通过本次的学习,能通过tenserflow框架创建cnn网络模型进行运动鞋品牌识别,学习了新的知识点,那就是学习率可动态设置,可以帮助优化算法更有效地收敛到全局最小值,从而提高模型的性能,相比上一章节新增了训练早停回调函数,模型训练在指定epoch次都没有提升的情况下,提前停止训练。

















 8104
8104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









