



 本文详细解读了Hadoop FileInputFormat源码,介绍了其在逻辑切片文件和InputSplit处理中的关键作用,以及TextInputFormat、CombineTextInputFormat、KeyValueTextInputFormat和NLineInputFormat这四个常见实现类的具体应用场景和工作原理。
本文详细解读了Hadoop FileInputFormat源码,介绍了其在逻辑切片文件和InputSplit处理中的关键作用,以及TextInputFormat、CombineTextInputFormat、KeyValueTextInputFormat和NLineInputFormat这四个常见实现类的具体应用场景和工作原理。
2021SC@SDUSC
研究内容简略介绍
上周我们分析了ID类,对ID类的作用有了初步的了解,然后开始了对其子类的分析,我们以JobID为例,探讨了它的源码,了解了其中的重点方法。同时我们阅读了InputFormat的源码,分析了其的功能。接下来我们将对InputFormat的几个重要子类,如FileInputFormat等展开详细的分析。
org.apache.hadoop.mapreduce.lib.input.FileInputFormat源码分析

FileInputFormat是所有基于文件的InputFormats的基类 。
FileInputFormat作为InputFormat的子类,实现了getSplits方法,用于对源文件进行逻辑切片。FileInputFormat还可以覆盖该 isSplitable(JobContext, Path)方法以防止在某些情况下拆分输入文件。可能处理不可拆分文件的实现必须覆盖此方法,因为默认实现假定拆分始终是可能的。
FileInputFormat作为InputFormat的子类,实现了getSplits方法,用于对源文件进行逻辑切片。
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
boolean ignoreDirs = !getInputDirRecursive(job)
&& job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);
for (FileStatus file: files) {
if (ignoreDirs && file.isDirectory()) {
continue;
}
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}
FileInputFormat的getSplits方法主要完成的功能如下:
(1)程序先找到数据存储的目录。
(2)开始遍历处理目录下的每一个文件。
(3)遍历第一个文件first.txt。
a. 获取文件大小fs.sizeOf(first.txt);
b. 计算切片大小;
computeSplitSize(Math.max(minSize,Math.min(maxSize,blocksize)))= blockSize = 128M
c. 默认情况下,切片大小=blockSize;
d. 开始切片,形成第1个切片;
first.txt—0:128M,第2个切片:first.txt—128:256M,第3个切片:first.txt—256:300M;
每次切片之前会判断切完剩下部分是否大于blockSize的1.1倍,不大于1.1倍就划分为一块切片
e. 将切片元数据信息(包含切片的起始位置、长度和所在节点列表等)写到一个规划文件InputSplit中;
f. 将每个逻辑切片文件的规划文件InputSplit,放入List中返回;
g. 整个切片过程在getSplit( )方法中完成;
(4)提交切片规划文件到Yarn上,Yarn上的MrAppMaster就可以根据切片规划文件InputSplit,计算需要开启MapTask的个数(一个InputSplit规划文件,对应启动一个MapTask)。
FileInputFormat的实现类概述
在上面,Yarn中已经计算出启动多少个MapTask;每一个MapTask运行对应的一部分切片文件,下面开始MR程序,首先是Mapper阶段,将切片文件数据解析成<k,v>。
MR程序中包含的方法,链接,待续
在运行MR程序时,输入的文件格式包括:基于行的日志文件、二进制格式文件、数据库表等;
针对不同的输入数据类型,MR的FileInputFormat也提供了常用的几个实现类,包括:
TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义的InputFormat等。
在MapReduce编程中,一个MR程序就是一个job,在job运行时,在代码中需要指定是采用的哪个实现类来解析HDFS输入原始数据文件,默认使用TextInputFormat。
job.setInputFormatClass(TextInputFormat.class);
1.TextInputFormat(逐行读取)
文件源码如下:
public class TextInputFormat extends FileInputFormat<LongWritable, Text> {
@Override
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
String delimiter = context.getConfiguration().get(
"textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter)
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
return new LineRecordReader(recordDelimiterBytes);
}
@Override
protected boolean isSplitable(JobContext context, Path file) {
final CompressionCodec codec =
new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
if (null == codec) {
return true;
}
return codec instanceof SplittableCompressionCodec;
}
}
TextInputFormat继承了父类的createRecordReader方法,对切片文件数据解析成<k,v>键值对。
public RecordReader<LongWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context) {
TextInputFormat是默认的FileInputFormat实现类。
按行读取每条记录,
key是存储当前行在整个文件中的起始字节偏移量,LongWritable类型;
Value是当前行的内容,不包括任何终止符(换行符和回车符),Text类型。
例如:
初始切片文件:
Rich learning form
Intelligent learning engine
Learning more
From the real demand
键值对:
(0,Rich learning form)
(19,Intelligent learning engine)
(47,Learning more)
(72,From the real demand)
然后将<k,v>作为Map Task任务中Mapper的输入参数,框架每获取一个<k,v>就会调用一次map任务进行计算。
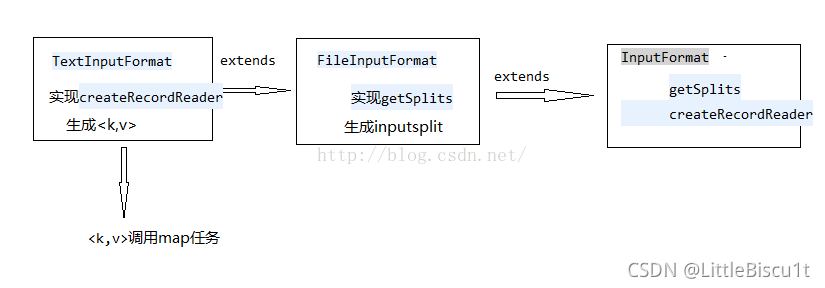
2.CombineTextInputFormat(小文件合并)
框架默认的TextInputFormat切片机制是对任务按照文件规划InputSplit切片,不管文件多小,都是一个单独的切片,交给一个MapTask;
这样如果有大量小文件,就会产生大量的MapTask,处理效率及其低下。
CombineTextInputFormat就是用于这种小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样多个小文件交给一个MapTask处理。
虚拟存储切片最大值设置:
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304); // 4M
生成切片过程包括两部分:虚拟存储过程和切片过程
A. 虚拟存储过程
将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值进行比较:
(1)如果<=设置的最大值4M,逻辑上划分一个块
(2)如果输入文件>设置的最大值4M,且>最大值两倍8M,那么先把4M作为一个块,剩余部分平均分成两块
(3)如果输入文件>设置的最大值4M,且<=最大值两倍8M,此时将文件平均分成2个虚拟存储块(防止出现太小切片)
eg:setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M文件平均切分成2.01M和2.01M两个文件块。
B. 切片过程
对于上一过程中切分出来的各个小文件,进行合并
(1)判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片
(2)如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片
3.KeyValueTextInputFormat(分隔符)
public class KeyValueTextInputFormat extends FileInputFormat<Text, Text> {
@Override
protected boolean isSplitable(JobContext context, Path file) {
final CompressionCodec codec =
new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
if (null == codec) {
return true;
}
return codec instanceof SplittableCompressionCodec;
}
public RecordReader<Text, Text> createRecordReader(InputSplit genericSplit,
TaskAttemptContext context) throws IOException {
context.setStatus(genericSplit.toString());
return new KeyValueLineRecordReader(context.getConfiguration());
}
}
每一行都是一条记录,被分隔符分隔成key-value;
可以通过驱动类中设置conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR,"\t")来设置每行的分隔符,
默认分隔符是\t,若文件中每行没有制表符,则全部为key,value为空。
键值对中key就是每行分隔符前的Text序列。
例如:
初始切片文件:
line1——>Rich learning form
line2——>Intelligent learning engine
line three——>Learning more
line four——>From the real demand
键值对:
(line1,Rich learning form)
(line2,Intelligent learning engine)
(line three,Learning more)
(line four,From the real demand)
4.NLineInputFormat(按行数N划分InputSplit和MapTask个数)
如果使用NLineInputFormat,代表每个map进程处理的InputSplit不再按Block块去划分,而是按照NLineInputFormat指定的行数N来划分。
即输入文件的总行数/N=切片数,如果不能整除,则切片数=输入文件的总行数/N + 1
例如,一共5行,N为2,则开启3个MapTask:
初始切片文件:
Rich learning form
Intelligent learning engine
Learning more
From the real demand
The Last
键值对:
第一个MapTask收到两行:
(0,Rich learning form)
(19,Intelligent learning engine)
第二个MapTask收到两行:
(47,Learning more)
(72,From the real demand)
第三个MapTask收到最后一行
(104,The Last)
总结
本次我们在了解了InputFormat的源码并分析其的功能的基础上,进一步分析了输入类FileInputFormat(切片)及其4个实现类(kv)的用法,对这部分核心源码有了更深的了解。

















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









