



onnx转TensorRT的问题
TensorRT7.0.1.1转换没出问题
TensorRT8.2.4.2一直报下面的错误
4: [shapeCompiler.cpp::nvinfer1::builder::DynamicSlotBuilder::evaluateShapeChecks::832] Error Code 4: Internal Error (kOPT values for profile 0 violate shape constraints: condition '==' violated. IAssertionLayer (Unnamed Layer* 5) [Assertion]: condition[0] is false: (EQUAL (# 2 (SHAPE input0)) (# 2 (SHAPE input1))). For input: 'input0' all named dimensions that share the same name must be equal. Note: Named dimensions were present on the following axes: 2 (name: 'height'), 2 (name: 'height'))
原因是:
input0 input1 input2 在实际使用的时候,width height大小是/2递减的,而在保存onnx的时候,命名的时候是相同的(上一辈留下的问题,心里苦)
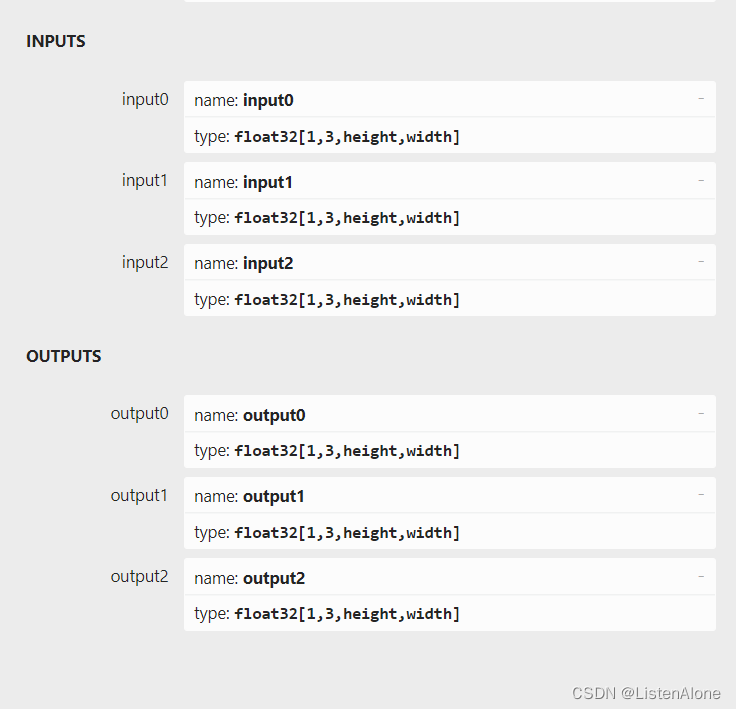

TensorRT8.2.4.2中要求,相同name的维度需要一致,input0中叫height,如果在input1中也有相同名字的height,那么这两个大小必须一致,不然就会报错。
解决方法,生成的onnx的时候,分别命名即可:
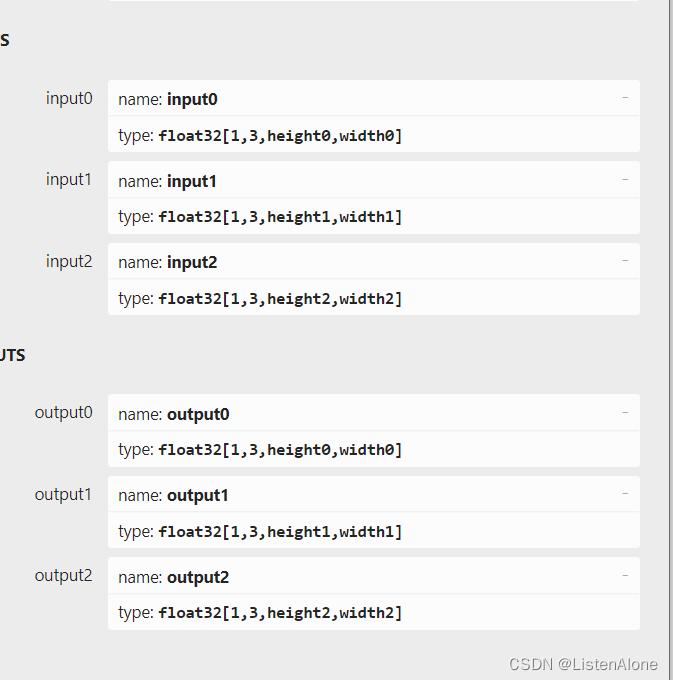
增加onnx直接修改名字的代码:
import onnx
import torch
import argparse
import os
def Test_Onnx_Change_Param_Name(onnx_model):
for input in onnx_model.graph.input:
dim1 = input.type.tensor_type.shape.dim[2]
dim2 = input.type.tensor_type.shape.dim[3]
dim1.dim_param = "height" + input.name[-1]
dim2.dim_param = "width" + input.name[-1]
for output in onnx_model.graph.output:
dim1 = output.type.tensor_type.shape.dim[2]
dim2 = output.type.tensor_type.shape.dim[3]
dim1.dim_param = "height" + output.name[-1]
dim2.dim_param = "width" + output.name[-1]
def apply(transform, infile, outfile):
model = onnx.load(infile)
transform(model)
onnx.save(model, outfile)
parser = argparse.ArgumentParser(description='Configurations for Change Onnx Name')
parser.add_argument('--onnx_path', type=str, default=r'D:\networks\deblur\rst/model.onnx', help='src onnx path')
parser.add_argument('--save_new_path', type=str, default=r'D:\networks\deblur\rst/modified.onnx', help='new onnx path')
args = parser.parse_args()
if __name__ == "__main__":
apply(Test_Onnx_Change_Param_Name, args.onnx_path, args.save_new_path)



















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











