






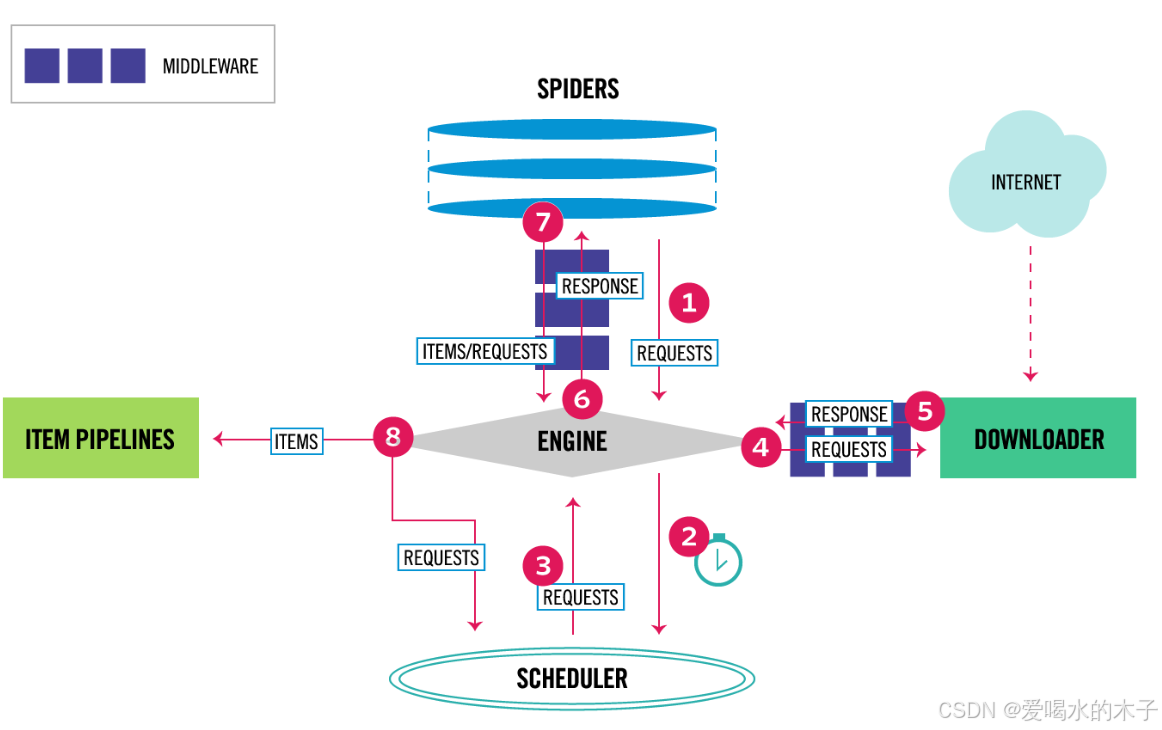
1. 步骤 1:Spider 生成请求
Spider(爬虫)是 Scrapy 中定义爬取逻辑的组件。它会首先生成初始的 Request(请求),这些请求通常指向要爬取的目标网页,比如示例中爬取名言网站的起始页面链接。
2. 步骤 2:Engine 传递请求到 Scheduler
Engine(引擎)是 Scrapy 框架的核心,负责调度和协调各个组件的工作。它接收到 Spider 生成的 Request 后,会将其传递给 Scheduler(调度器)。
3. 步骤 3:Scheduler 调度请求
Scheduler 会对收到的 Request 进行管理,包括去重、优先级排序等操作,然后按照一定的策略(比如先进先出、优先级高先处理等)将 Request 再传递回 Engine。
4. 步骤 4:Engine 传递请求到 Downloader Middleware
Engine 从 Scheduler 拿到调度后的 Request,会先将其传递给 Downloader Middleware(下载中间件)。下载中间件可以在请求发送前对其进行一系列处理,比如添加请求头、设置代理、处理 Cookies 等,以模拟更真实的浏览器请求,或者应对网站的反爬机制。
5. 步骤 5:Downloader 发送请求到互联网并获取响应
经过 Downloader Middleware 处理后的 Request 会被传递给 Downloader(下载器)。Downloader 负责向互联网上的目标服务器发送 HTTP 请求,然后接收服务器返回的 Response(响应),这个响应包含了网页的内容。
6. 步骤 6:Engine 传递响应到 Spider Middleware
Downloader 获取到 Response 后,会将其返回给 Engine。Engine 接着把 Response 传递给 Spider Middleware(爬虫中间件)。爬虫中间件可以在 Response 被 Spider 处理前进行操作,比如修改响应内容、过滤不需要的响应等。
7. 步骤 7:Spider 处理响应并生成 Item 或新的 Request
Spider 接收到经过 Spider Middleware 处理的 Response 后,会对其进行解析。一方面,它会提取出需要的数据,封装成 Item(数据项,用于存储结构化数据,比如示例中名言的文本、作者、标签等);另一方面,如果发现还有需要跟进的链接(如下一页链接),会生成新的 Request,以便继续爬取。
8. 步骤 8:Engine 传递 Item 到 Item Pipeline
Spider 生成的 Item 会被返回给 Engine,Engine 再将 Item 传递给 Item Pipeline(项目管道)。Item Pipeline 用于对 Item 进行后续处理,比如数据清洗(去除无用字符、修正格式等)、验证(检查数据是否符合预期)、存储(保存到数据库、文件等)。
各组件作用总结
- Spider:定义爬取规则,生成初始请求,解析响应提取数据或生成新请求。
- Engine:框架核心,负责各组件间的通信与调度,确保数据在组件间有序流转。
- Scheduler:管理请求队列,进行请求的调度与去重。
- Downloader:发送 HTTP 请求到目标网站,获取响应内容。
- Downloader Middleware:在请求发送前和响应返回后进行自定义处理,增强请求灵活性与适应性。
- Spider Middleware:在响应被 Spider 处理前和请求被 Spider 生成后进行处理,定制 Spider 的输入和输出。
- Item Pipeline:对提取的
Item进行后期处理与持久化存储。
通过这样一套完整的流程,Scrapy 能够高效、有序地完成从网页请求到数据获取与处理的整个爬虫工作。

















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









