




Table Calculations are one of the most powerful features in Tableau. They enable solutions that really couldn't be achieved any other way (short of writing a custom application or complex custom SQL scripts!). The features include the following:
-
They make it possible to use data that isn't structured well and still get quick results without waiting for someone to fix the data at the source
-
They make it possible to compare and perform calculations on aggregate values across rows of the resulting table
-
They open incredible possibilities for analysis and creative approaches to solving problems, highlighting insights, or improving the user experience
Table Calculations range in complexity from incredibly easy to create (a couple of clicks) to extremely complex (requiring an understanding of addressing, partitioning, and data densification[densɪfɪˈkeɪʃn]加密). We'll start off simple and move toward complexity in this chapter. The goal is to gain a solid foundation for creating and using Table Calculations, understanding how they work, and looking at some examples of how they can be used. We'll consider these topics:
-
An overview of Table Calculations
-
Quick Table Calculations
-
Scope and direction
-
Addressing and partitioning
-
Custom Table Calculations
-
Practical examples
-
Data densification
The examples in this chapter will return to the sample Superstore data that we used in the first chapter. To follow along with the examples, use the Chapter 05 Starter.twbx workbook.
An overview of Table Calculations
Table Calculations are different from all other calculations in Tableau. Row-level, aggregate calculations, and LOD expressions(Level of detail calculations), which we considered in the previous chapterhttps://blog.youkuaiyun.com/Linli522362242/article/details/123188872, are performed as part of the query to the data source. If you were to examine the queries sent to the data source by Tableau, you'd find the code for your calculations translated into whatever flavor of SQL the data source used.
Table Calculations, on the other hand, are performed after the initial query. Here's an extended diagram that shows how aggregated results are stored in Tableau's cache:
Table Calculations are performed on the aggregate table of data in Tableau's cache right before the data visualization is rendered. As we'll see, this is important to understand for multiple reasons, including the following:
-
Aggregation: Table Calculations operate on aggregate data. You cannot reference fields in a Table Calculation without referencing it as an aggregate.
-
Filtering: Regular filters will be applied before Table Calculations. This means that Table Calculations will only be applied to data returned from the source to the cache. You'll need to avoid filtering any data necessary for Table Calculations to work as desired.
-
Late Filtering: Table Calculations used as filters will be applied after the aggregate results are returned from the data source. 用作过滤器的表计算将在聚合结果 从数据源返回后 应用The order becomes important: row-level and aggregate filters are applied first, the aggregate data is returned to the cache, then the Table Calculation is applied as a filter that effectively hides data from the view.
This allows for some creative approaches to solving certain kinds of problems that we'll consider in some of the examples. -
Performance: If you are using a live connection to an enterprise database server, then row-level and aggregate-level calculations will be taking advantage of enterprise-level hardware. Table Calculations are performed in the cache, which means they will be performed on whatever machine is running Tableau. You will not likely need to be concerned if your Table Calculations are operating on a dozen or even hundreds of rows of aggregate data, or if you anticipate publishing to a powerful Tableau Server. However, if you are getting back hundreds of thousands of rows of aggregate data on your local machine, then you'll need to consider the performance of your Table Calculations. At the same time, there are cases where Table Calculations might be used to avoid an expensive filter or calculation at the source.
Creating and editing Table Calculations
There are several ways to create Table Calculations in Tableau, including:
-
Using the drop-down menu for any active field used as a numeric aggregate in the view, select Quick Table Calculation and then the desired calculation type
-
Using the drop-down menu for any active field that is used as a numeric aggregate in the view, select Add Table Calculation, then select the calculation type, and adjust any desired settings
-
Create a calculated field and use one or more Table Calculation functions to write your own custom Table Calculations
The first two options create a Quick Table Calculation, which can be edited or removed using the drop-down menu on the field and selecting Edit Table Calculation... or Clear Table Calculation. The third option creates a calculated field, which can be edited or deleted as any other calculated field.
A field on a shelf in the view that is using a Table Calculation, or which is a calculated field using Table Calculation functions, will have a delta symbol icon as follows:
Following is the snippet of Active Field: ![]()
Following is the Active Field with Table Calculation:![]()
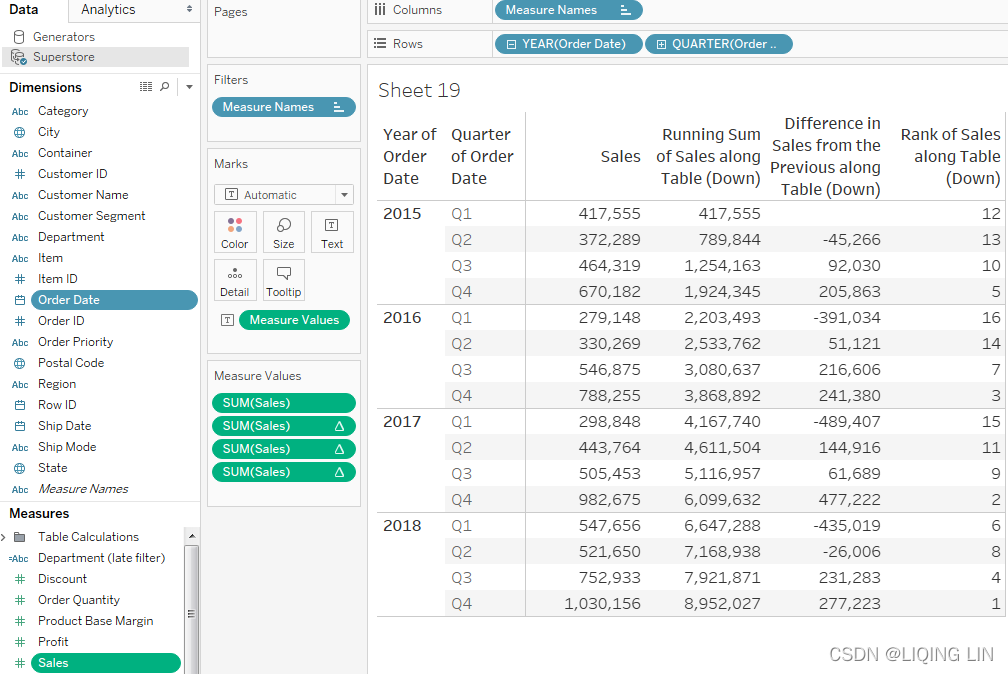
Most of the examples in this chapter will utilize text tables/cross tab reports as these most closely match the actual aggregate table in the cache. This makes it easier to see how the Table Calculations are working.
Tip
Table Calculations can be used in any type of visualization. However, when building a view that uses Table Calculations, especially more complex ones, try using a table with all dimensions on the Rows shelf and then adding Table Calculations as discrete values on Rows to the right of the dimensions. Once you have all the Table Calculations working as desired, you can rearrange the fields in the view to give you the appropriate visualization.
Quick Table Calculations
Quick Table Calculations are predefined Table Calculations that can be applied to any field used as a measure in the view. These calculations include common and useful calculations such as running total, difference, percent difference, percent of total, rank, percentile, moving average, YTD total, compound growth rate, Year over Year Growth, and YTD growth. You'll find applicable options on the drop-down list on a field used as a measure in the view, as shown in the following screenshot: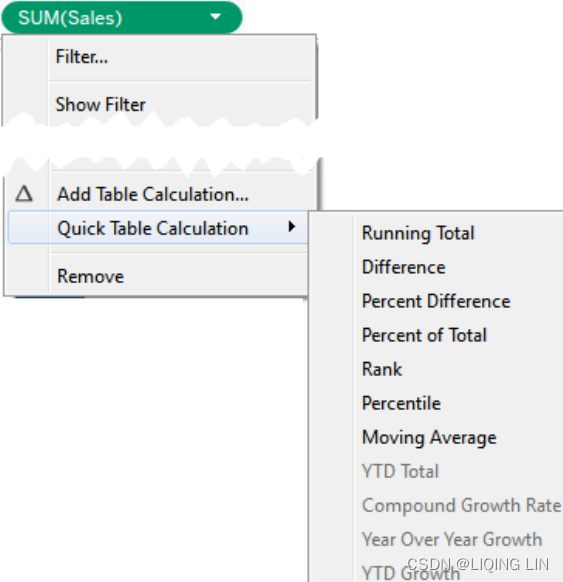 Quick Table Calculations | Runing Total
Quick Table Calculations | Runing Total
Consider the following example using the sample Superstore Sales data: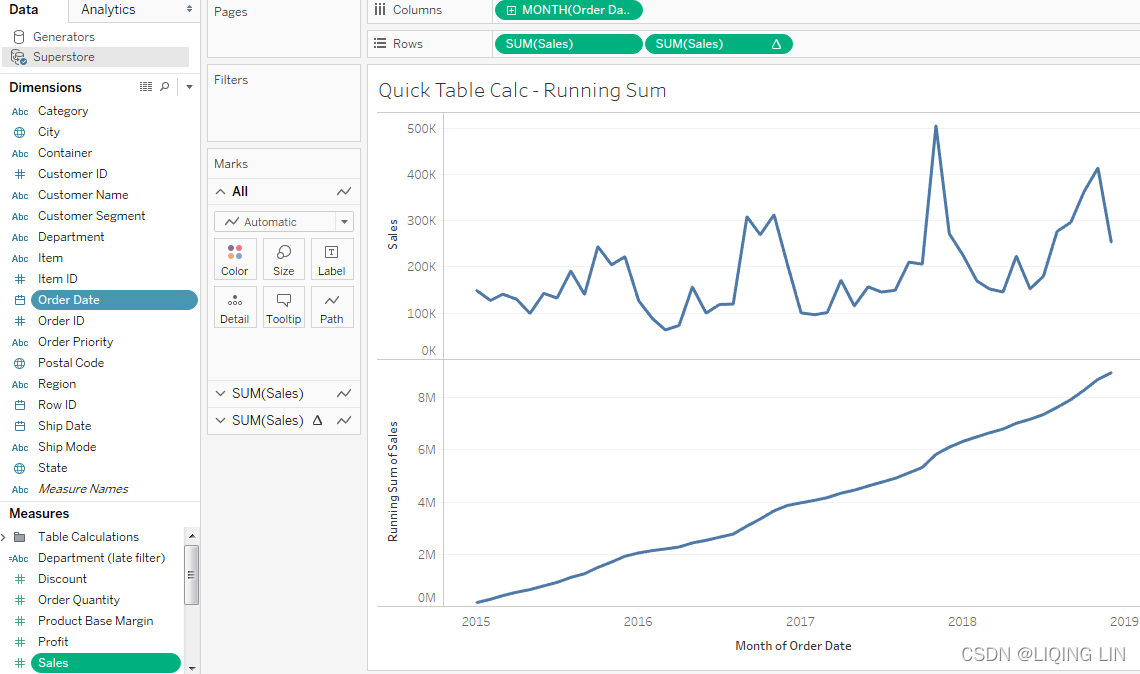
Here, Sales over time are shown. Sales has been placed on the Rows shelf twice and the second SUM(Sales) field has had the Running Total Quick Table Calculation applied(accumulation of sales). Using the Quick Table Calculation avoided writing any code.
Tip
You can actually see the code that the Quick Table Calculations uses by double-clicking the Table Calculation field in the view.  This turns it into an ad hoc calculation. You can also drag an active field with a Quick Table Calculation applied to the data pane,
This turns it into an ad hoc calculation. You can also drag an active field with a Quick Table Calculation applied to the data pane, which will turn it into a calculated field available to reuse in other views.
which will turn it into a calculated field available to reuse in other views.
The following table demonstrates some of the Quick Table Calculations available:
-
double click Sales under the Measures, then click
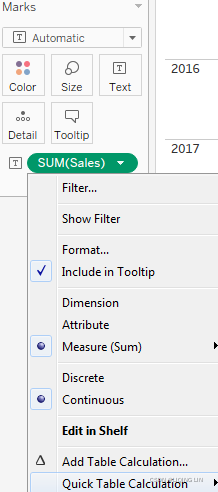 Running Total==>
Running Total==>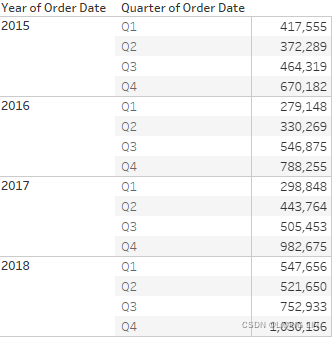 ==>accumulation of sales==>
==>accumulation of sales==>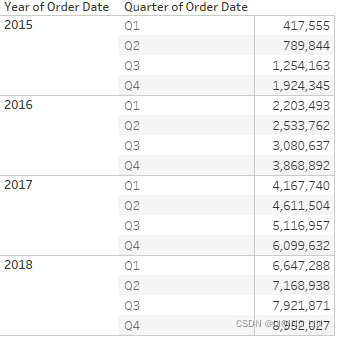
-
double click Sales under the Measures, then click Quick Table Calculations | Difference
-
double click Sales under the Measures, then click Quick Table Calculations | Rank
-
double click Sales under the Measures, then rearrange the fields in the view
-
On the Format menu, select Workbook.
Relative versus fixed
We'll take a look at some of the options for Table Calculations shortly. Based on the options, you can compute Table Calculations in one of the two following ways:
-
Relative: The Table Calculation will be computed relative to the layout of the table. They might move across or down the table. Rearranging dimensions in a way that changes the table will change the Table Calculation results. As we'll see, the key for relative Table Calculations is scope and direction. When you set a Table Calculation to use a relative computation, it will continue to use the same relative scope and direction, even if you rearrange the view.
-
Fixed: The Table Calculation will be computed using one or more dimensions. Rearranging those dimensions will not change the computation of the Table Calculation. Here the scope and direction remain fixed to one or more dimensions, no matter where they are moved within the view. When we talk about fixed Table Calculations, we'll focus on the concepts of partitioning and addressing.
You can see these concepts in the user interface. The following is the Table Calculation editor that appears when you select Edit Table Calculation from the menu of a Table Calculation field: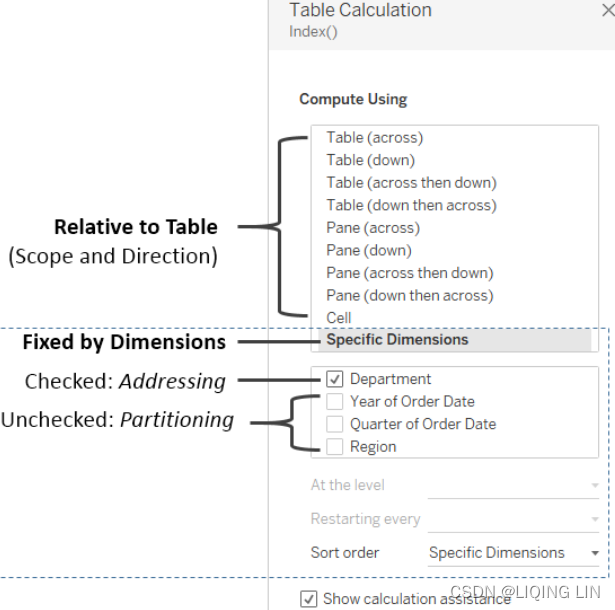
We'll explore the options and terms in more detail, but for now, notice the options that relate to specifying a Table Calculation that is computed relative to Rows and Columns, and options that specify a Table Calculation that is computed fixed to certain dimensions in the view.
Scope and direction
Scope and direction are terms that describe how a Table Calculation is computed relative to the table. When a Table Calculation is relative to the layout of the table, rearranging the fields in the view will not change the scope and direction:
-
Scope: The scope defines the boundaries within which a given Table Calculation can reference other values
-
Direction: The direction defines how the Table Calculation moves within the scope
You've already seen Table Calculations being calculated table (across) (the running sum of sales over time销售额随时间的运行总和) and table (down) (in the previous table). In these cases, the scope was the entire table and the direction was either across or down. For example, the running total calculation ran across the entire table, adding subsequent values as it moved from left to right.
To define scope and direction for a Table Calculation, use the drop-down menu for the field in the view and select Compute Using. You will get a list of options that will vary slightly depending on the
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











