




 文章探讨了数据库国产化的背景,介绍了Shared-Everything、Shared-Nothing和Shared-Storage等主流数据库架构,重点讨论了数据库选型、测试、数据同步和业务改造等国产化过程中的关键环节,分享了实际操作中的实践经验,如使用中间件进行数据层切换和双写方案以确保业务连续性。
文章探讨了数据库国产化的背景,介绍了Shared-Everything、Shared-Nothing和Shared-Storage等主流数据库架构,重点讨论了数据库选型、测试、数据同步和业务改造等国产化过程中的关键环节,分享了实际操作中的实践经验,如使用中间件进行数据层切换和双写方案以确保业务连续性。
首先,讲一下数据库国产化的大背景。
一、数据库国产化的背景
国家战略方面的,随着外部形势的日益复杂,核心技术急需实现自主可控、安全可靠、高效开放;另一个要求是业务方面的,当业务高速发展后各种问题会接踵而至,单机数据库达到瓶颈,业务拆分、垂直拆分、水平拆分等,都需要花费大量的研发时间。
二、主流的数据库架构
首先和大家分享一下目前主流的数据库架构。目前业内主流的数据库架构大体分为三类:Shared-Everything、Shared-Nothing,Shared-Storage。
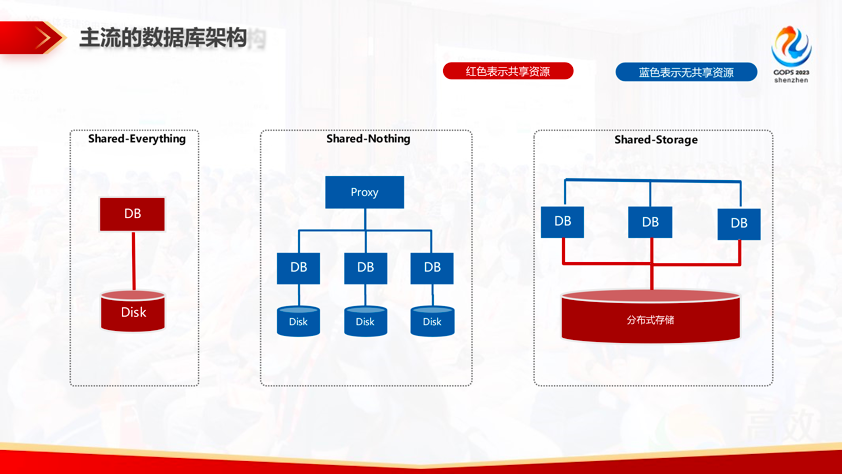
-
Shared-Everything
这一种架构可能大家都比较熟悉,是很经典的一个架构,主机上的所有进程共享CPU、内存、IO,任意一个硬件达到了瓶颈,也就意味着数据库达到了瓶颈。
-
Shared-Nothing
这里可以再细分出两个架构,一种是基于 Proxy 的架构,这个架构由传统的单机数据库演变而来,当我们单机数据库达到瓶颈以后,我们再往上加一层 Proxy,通过 Proxy 把我们的数据打散到不同的节点上,以此来解决数据扩展性问题;另一种 Shared-Nothing 架构,是目前在国内比较火的像 TiDB、OB 这样的数据库。
-
Shared-Storage
这种架构在业内比较有名的是的 Aurora,还有目前在国内也比较火的阿里的 PolarDB。
首先,先详细介绍一下 Shared-Everything 架构。这个架构可能大家都比较熟悉,它是一种传统的单机数据库架构,当我们的数据库达到瓶颈以后,我们通常会采用各种各样的方式把我们的数据打散到各个 set 里面去,以此来解决数据库当地容量上限的问题。
有很多公司会通过这种方式来实现,把应用层、接入层、网关层都根据同样的分片逻辑,把数据整合到一个 set 里面,从而实现数据在 set 里面的闭环。通过这样的一套架构能做非常多有意思的事情。比如一些全链路在线的压测,因为数据已经在一个 set 里面不闭环了,如果我在一个测试 set 里面做数据压测,它不会污染到线上真实的数据,还可以做一些向线上的灰度引流、灰度发版等。
Shared-Storage 架构中,目前在国外做得特别好的是 AWS 的Aurora,在国内做得比较好的是阿里的 PolarDB。因为它对数据库研发投入非常高,同时需要依托底层一个非常强大的底座,所以一开始这些数据库推出来之后,像 Aurora 至今都是只支持在云上部署。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 8216
8216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









