




# pip install streamlit
import streamlit as st
import tempfile
import os
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_message_histories import StreamlitChatMessageHistory
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain_core.prompts import PromptTemplate
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.agents import create_react_agent, AgentExecutor
from langchain_community.callbacks.streamlit import StreamlitCallbackHandler
from langchain_openai import ChatOpenAI
# 设置Streamlit应用的页面标题和布局
st.set_page_config(page_title="文档问答", layout="wide")
# 设置应用的标题
st.title("文档问答")
# 上传txt文件,允许上传多个文件
uploaded_files = st.sidebar.file_uploader(
label="上传txt文件", type=["txt"], accept_multiple_files=True
)
# 如果没有上传文件,提示用户上传文件并停止运行
if not uploaded_files:
st.info("请先上传按TXT文档。")
st.stop()
# 实现检索器
@st.cache_resource(ttl="1h")
def configure_retriever(uploaded_files):
# 读取上传的文档,并写入一个临时目录
docs = []
temp_dir = tempfile.TemporaryDirectory(dir=r"D:\\")
for file in uploaded_files:
temp_filepath = os.path.join(temp_dir.name, file.name)
with open(temp_filepath, "wb") as f:
f.write(file.getvalue())
# 使用TextLoader加载文本文件
loader = TextLoader(temp_filepath, encoding="utf-8")
docs.extend(loader.load())
# 进行文档分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 使用OpenAI的向量模型生成文档的向量表示
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(splits, embeddings)
# 创建文档检索器
retriever = vectordb.as_retriever()
return retriever
# 配置检索器
retriever = configure_retriever(uploaded_files)
# 如果session_state中没有消息记录或用户点击了清空聊天记录按钮,则初始化消息记录
if "messages" not in st.session_state or st.sidebar.button("清空聊天记录"):
st.session_state["messages"] = [{"role": "assistant", "content": "您好,我是文档问答助手"}]
# 加载历史聊天记录
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 创建检索工具
from langchain.tools.retriever import create_retriever_tool
# 创建用于文档检索的工具
tool = create_retriever_tool(
retriever,
"文档检索",
"用于检索用户提出的问题,并基于检索到的文档内容进行回复.",
)
tools = [tool]
# 创建聊天消息历史记录
msgs = StreamlitChatMessageHistory()
# 创建对话缓冲区内存
memory = ConversationBufferMemory(
chat_memory=msgs, return_messages=True, memory_key="chat_history", output_key="output"
)
# 指令模板
instructions = """您是一个设计用于查询文档来回答问题的代理。
您可以使用文档检索工具,并基于检索内容来回答问题
您可能不查询文档就知道答案,但是您仍然应该查询文档来获得答案。
如果您从文档中找不到任何信息用于回答问题,则只需返回“抱歉,这个问题我还不知道。”作为答案。
"""
# 基础提示模板
base_prompt_template = """
{instructions}
TOOLS:
------
You have access to the following tools:
{tools}
To use a tool, please use the following format:
```
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: {input}
Observation: the result of the action
```
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
```
Thought: Do I need to use a tool? No
Final Answer: [your response here]
```
Begin!
Previous conversation history:
{chat_history}
New input: {input}
{agent_scratchpad}"""
# 创建基础提示模板
base_prompt = PromptTemplate.from_template(base_prompt_template)
# 创建部分填充的提示模板
prompt = base_prompt.partial(instructions=instructions)
# 创建llm
llm = ChatOpenAI()
# 创建react Agent
agent = create_react_agent(llm, tools, prompt)
# 创建Agent执行器
agent_executor = AgentExecutor(agent=agent, tools=tools, memory=memory, verbose=True,
handle_parsing_errors="没有从知识库检索到相似内容")
# 创建聊天输入框
user_query = st.chat_input(placeholder="请开始提问吧!")
# 如果有用户输入的查询
if user_query:
# 添加用户消息到session_state
st.session_state.messages.append({"role": "user", "content": user_query})
# 显示用户消息
st.chat_message("user").write(user_query)
with st.chat_message("assistant"):
# 创建Streamlit回调处理器
st_cb = StreamlitCallbackHandler(st.container())
# agent执行过程日志回调显示在Streamlit Container (如思考、选择工具、执行查询、观察结果等)
config = {"callbacks": [st_cb]}
# 执行Agent并获取响应
response = agent_executor.invoke({"input": user_query}, config=config)
# 添加助手消息到session_state
st.session_state.messages.append({"role": "assistant", "content": response["output"]})
# 显示助手响应
st.write(response["output"])
在终端输入:
(langchain) PS D:\me\study\large_model\langchain\9.langchain-rag> streamlit run doc_chat.py
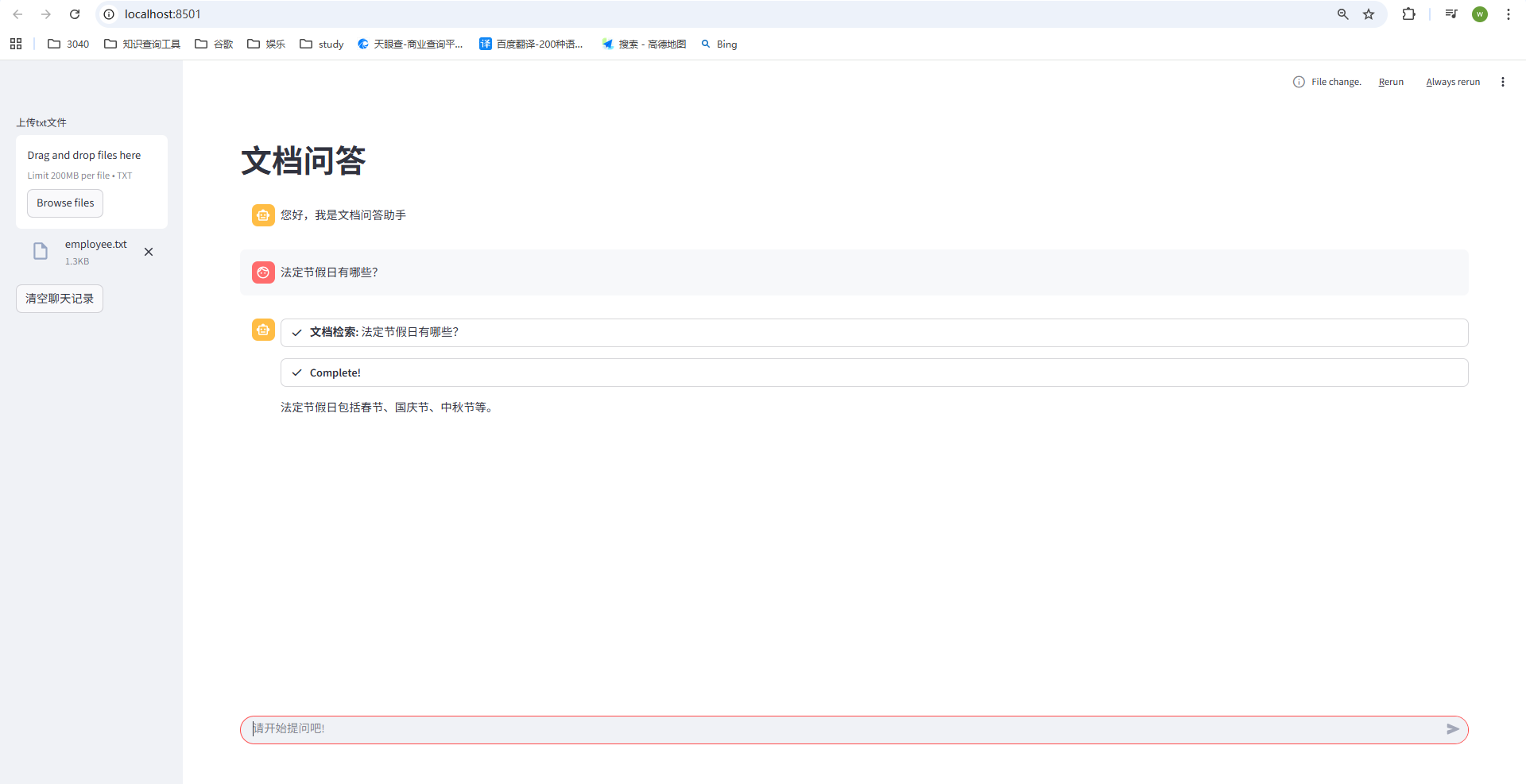
http://localhost:8501/,即可得到

















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









