







 强化学习用于游戏AI开发,通过预测模型和奖励机制寻找最优行动。训练方法包括策略梯度、马尔可夫决策过程和深度Q网络。深度Q网络解决了复杂游戏状态过多的问题,使用神经网络进行优化,并通过双重网络避免连续经验的偏差。
强化学习用于游戏AI开发,通过预测模型和奖励机制寻找最优行动。训练方法包括策略梯度、马尔可夫决策过程和深度Q网络。深度Q网络解决了复杂游戏状态过多的问题,使用神经网络进行优化,并通过双重网络避免连续经验的偏差。
强化学习经常被用来进行游戏AI的开发,其模型在输入输出上具有一些特点
预测模型
强化模型的输入时一个状态,比如游戏中的占位等等,而输出则是在该在状态下最优的行动,二者之间具有一一对应的关系,但问题在于,对于一个游戏,关于最优解我们往往并不能得出统一的最优解标注,因此这与之前的监督分类具有明显的区别。因此我们需要通过游戏的结果来反过来调整行动选择,这是一种奖励机制。
奖励机制
强化学习没有明确的损失模型,取而代之的是经历机制,损失模型主要是让模型调整以使损失函数最小化,而奖励机制则是通过调整使奖励最大化。
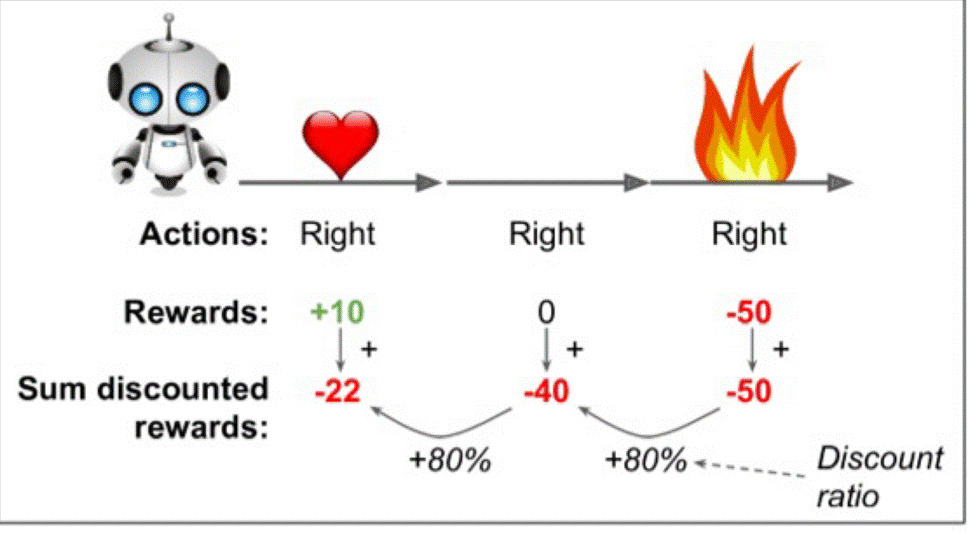
游戏中一个动作连着一个动作,因此奖励不止应当考虑下一步的即时收益,同时要考虑未来的收益,也因此在计算奖励时会引入衰减率。如图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1384
1384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









