







 本文深入浅出地介绍了强化学习的基础概念,包括智能体、环境、状态、动作和奖励等核心要素,对比了强化学习与监督学习的区别,阐述了价值和策略两种学习方式。并通过Flappybird、乒乓球等实例说明强化学习的应用场景,最后通过GYM环境库和PARL框架的使用,展示了强化学习算法的实践过程。
本文深入浅出地介绍了强化学习的基础概念,包括智能体、环境、状态、动作和奖励等核心要素,对比了强化学习与监督学习的区别,阐述了价值和策略两种学习方式。并通过Flappybird、乒乓球等实例说明强化学习的应用场景,最后通过GYM环境库和PARL框架的使用,展示了强化学习算法的实践过程。
强化学习(RL)初印象
参考资料:
- 《Reinforcement Learning: An Introduction》
- 伯克利2018 Deep RL课程:http://rail.eecs.berkeley.edu/deeprlcourse/
- 强化学习库 PARL: https://github.com/PaddlePaddle/PARL
- Paddle: https://www.paddlepaddle.org.cn/documentation/docs/zh/beginners_guide/basic_concept/index_cn.html
Part1 什么是强化学习
- 强化学习(英语:
Reinforcement learning,简称RL)是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。 - 核心思想:智能体
agent在环境environment中学习,根据环境的状态state(或观测到的observation),执行动作action,并根据环境的反馈reward(奖励)来指导更好的动作。
注意:从环境中获取的状态,有时候叫state,有时候叫observation,这两个其实一个代表全局状态,一个代表局部观测值,在多智能体环境里会有差别,但我们刚开始学习遇到的环境还没有那么复杂,可以先把这两个概念划上等号。


举例:
1.Flappy bird

agent是小鸟,environment是小鸟所处环境,reward是得分反馈,state是像素级别的状态,action是agent的输出状态。
2.乒乓球

agent是己方,environment是对手以及环境,reward是得分反馈,state是像素级别图像,action是agent的输出状态,有向上走、向下走、停留不动三种状态。
强化学习特点:
-
跟环境交互;
-
奖励
reward是延迟的。
3.股票

agent是控制器,environment是股票市场,reward是股票累积收益,state是股票历史曲线,action是买入金额、卖出金额。
4.交通治理

agent是交通灯控制器,environment是交通状况,reward是拥堵情况,state是各个路口摄像头输入图像,action是红黄绿灯的亮灭。
Part2 强化学习能做什么
- 游戏(马里奥、Atari、Alpha Go、星际争霸等)
- 机器人控制(机械臂、机器人、自动驾驶、四轴飞行器等)
- 用户交互(推荐、广告、NLP等)
- 交通(拥堵管理等)
- 资源调度(物流、带宽、功率等)
- 金融(投资组合、股票买卖等)
- 其他

Part3 强化学习与监督学习的区别
- 强化学习、监督学习、非监督学习是机器学习里的三个不同的领域,都跟深度学习有交集。
- 监督学习寻找输入到输出之间的映射,比如分类和回归问题。
- 非监督学习主要寻找数据之间的隐藏关系,比如聚类问题。
- 强化学习则需要在与环境的交互中学习和寻找最佳决策方案。
- 监督学习处理认知问题,强化学习处理决策问题。
强化学习与其他机器学习的关系:


监督学习一般指输入 xxx ,输出你想要的 yyy 。例如分类问题判断图片是猫还是狗 ,回归问题预测房价是多少。(任务驱动型)
非监督学习是输入一批 xxx ,你需要分辨这个 xxx 和那个 xxx 不一样。(数据驱动型)
强化学习的 xxx 是环境里面输入的状态,输出的是action,它会和环境进行交互。 (环境驱动型)
监督学习关注认知:

强化学习关注决策:


Part4 强化学习的如何解决问题
- 强化学习通过不断的试错探索,吸取经验和教训,持续不断的优化策略,从环境中拿到更好的反馈。
- 强化学习有两种学习方案:基于价值(
value-based)、基于策略(policy-based)

value-based:每次都选择价值高的。(确定性策略:Sarsa、Q-learning、DQN)
policy-based:策略函数化,一条策略走到底,用最后的reward的来判断该策略是好是坏。(随机性策略:Policy gradient)
Part5 强化学习的算法和环境
- 经典算法:
Q-learning、Sarsa、DQN、Policy Gradient、A3C、DDPG、PPO - 环境分类:离散控制场景(输出动作可数)、连续控制场景(输出动作值不可数)
- 强化学习经典环境库
GYM将环境交互接口规范化为:重置环境reset()、交互step()、渲染render() - 强化学习框架库
PARL将强化学习框架抽象为Model、Algorithm、Agent三层,使得强化学习算法的实现和调试更方便和灵活。
经典算法


左上角为PARL开源库链接二维码
RL编程实践:GYM
Gym:仿真平台、python开源库、RL测试平台
官网:https://gym.openai.com/
Gym提供的环境有两类:
- 离散控制场景:一般使用
atari环境评估 - 连续控制场景:一般使用
mujoco环境评估
Gym的核心接口是environment。提供以下几个核心方法:
(1)reset():重置环境的状态,回到初始环境,方便开始下一次训练。
(2)step(action):推进一个时间步长,返回四个值:
① observation(object):对环境的一次观察;
② reward(float):奖励;
③ done(boolean):代表是否需要重置环境;
④ info(dict):用于调试的诊段信息。
(3)render():重绘环境的一帧图像。
import gym
env = gym.make("ClifWalking-v0")
obs = env.reset()
while True:
action = np.random.randint(0, 4) #0-4代表 上 下 左 右 共四个动作,随机选一个
obs, reward, done, info = env.step(action)
env.render()
if done:
break
Part6 实践 熟悉强化学习环境
GYM是强化学习中经典的环境库,下节课我们会用到里面的CliffWalkingWapper和FrozenLake环境,为了使得环境可视化更有趣一些,直播课视频中演示的Demo对环境的渲染做了封装,感兴趣的同学可以在PARL代码库中的examples/tutorials/lesson1中下载gridworld.py使用。- PARL开源库地址:https://github.com/PaddlePaddle/PARL
!pip install gym
# -*- coding: utf-8 -*-
import gym
import numpy as np
if __name__ == '__main__':
# 环境1:FrozenLake, 可以配置冰面是否是滑的
# env = gym.make("FrozenLake-v0", is_slippery=False) # 0 left, 1 down, 2 right, 3 up
# 环境2:CliffWalking, 悬崖环境
env = gym.make("CliffWalking-v0") # 0 up, 1 right, 2 down, 3 left
# PARL代码库中的`examples/tutorials/lesson1`中`gridworld.py`提供了自定义格子世界的封装,可以自定义配置格子世界的地图
env.reset()
for step in range(100):
action = np.random.randint(0, 4)
obs, reward, done, info = env.step(action)
print('step {}: action {}, obs {}, reward {}, done {}, info {}'.format(\
step, action, obs, reward, done, info))
env.render()
总结

讨论区
问题:GPU运行PARL的QuickStart失败
解答:可能的原因是在GPU机器上安装了cpu版本的paddlepaddle,parl将在下一版本解决该场景的兼容问题,目前建议措施是在运行python train.py之前export CUDA_VISIBLE_DEVICES=""
问题:没有办法在AIStudio里面 from gridworld import CliffWalkingWapper, FrozenLakeWapper
解答:执行这个语句需要当前目录下有gridworld.py文件,可以从https://github.com/PaddlePaddle/PARL/blob/develop/examples/tutorials/lesson1/gridworld.py 下载,主要是实现了对gym两个环境的渲染封装,在本地机器运行的时候可以画出好看的界面,在AIstudio中无法渲染,可以不用这个封装哒。
第一课(环境搭建)作业常见问题6:import parl有很多warning
解决方案:这是因为AIStudio默认安装了pandas和scikit-learn,而且版本比较老,其依赖包与parl的依赖的检查限制有些冲突,但不影响代码运行,大家可以忽略这些warning,或者是pip uninstall -y pandas scikit-learn 卸载一下。
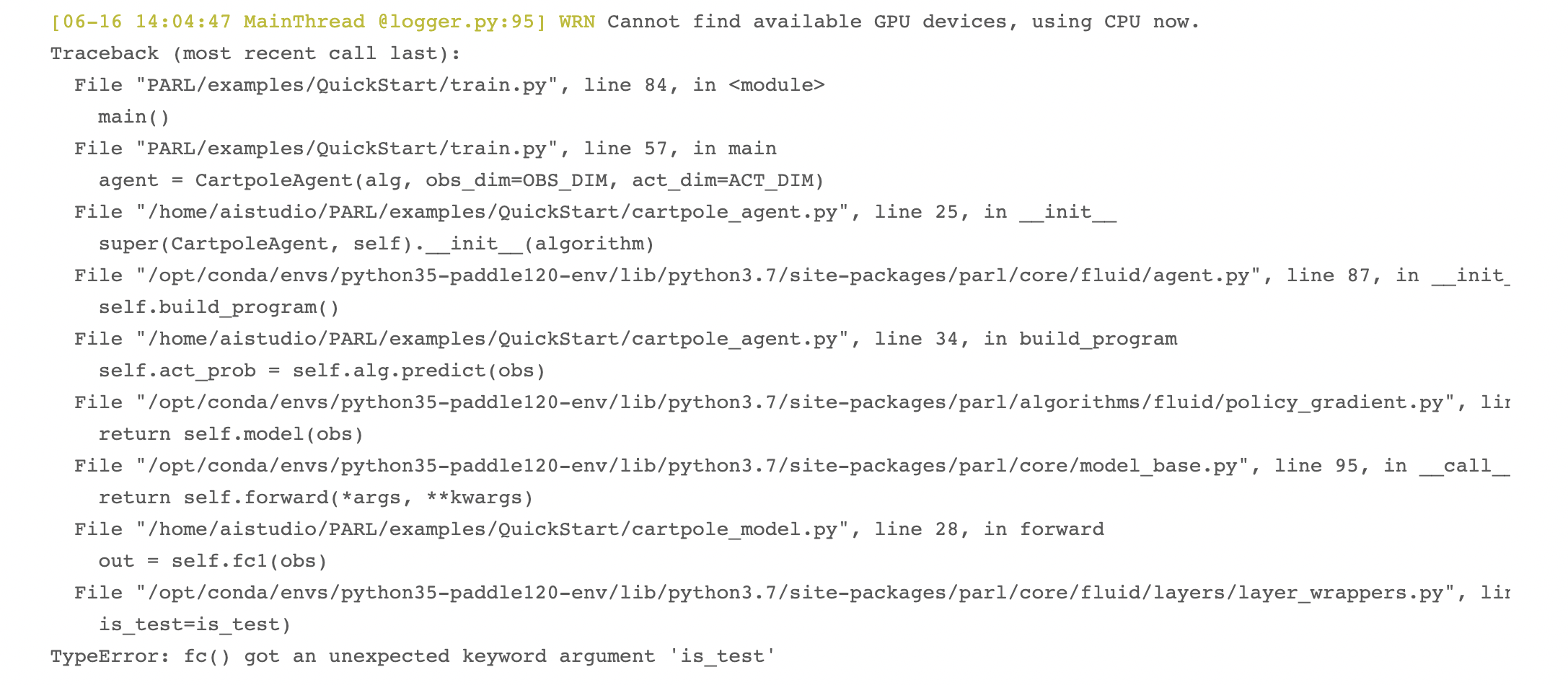
第一课(环境搭建)作业常见问题5:TypeError: fc() got an unexpected keyword argument ‘is_test’
解决方案:python train.py出现这个问题是因为大家第一步没有运行完成就直接运行下面的步骤了,AIStudio平台默认安装了parl1.1.2版本很老,跟paddle1.6不匹配,需要确保parl已经升级到1.3.1了,就不会出现这个问题啦~(所以第一步一定要等安装完成了再执行下面的,可以在终端用python -m pip list | grep parl 查看一下parl的版本信息)
第一课(环境搭建)作业常见问题1:pip install 太慢或超时中断
解决方案1:使用清华源
pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple解决方案2:使用百度源
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
课后作业
搭建环境,运行PARL的QuickStart
Step1 安装依赖
!pip uninstall -y pandas scikit-learn # 提示:在AIStudio中卸载这两个库再import parl可避免warning提示,不卸载也不影响parl的使用
!pip install paddlepaddle==1.6.3
!pip install parl==1.3.1
!pip install gym
Step2 下载PARL代码库
# !git clone --depth=1 https://github.com/PaddlePaddle/PARL.git # 下载PARL代码库
# 改为gitee下载,速度更快
!git clone --depth=1 https://gitee.com/paddlepaddle/PARL.git # 下载PARL代码库
!ls PARL # 查看代码库根目录
Step3 运行QuickStart
!python PARL/examples/QuickStart/train.py


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









