



1.数据预处理
1.1归一化
在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布 的需求,这种需求统称为将数据“无量纲化”。 譬如梯度和矩阵为核心的算法中,譬如逻辑回归,支持向量机,神经网络,无量纲化可以加快求解速度;而在距离类模型,譬如K近邻,K-Means聚类中,无量纲化可以帮我们提升模型精度,避免某一个取值范围特别大的特征对距离计算造成影响。
-
preprocessing.MinMaxScaler
当数据(x)按照最小值中心化后,再按极差(最大值 - 最小值)缩放,数据移动了最小值个单位,并且会被收敛到 [0,1]之间,而这个过程,就叫做数据归一化。 归一化之后的数据服从正态分 布,公式如下:
在sklearn当中,我们使用preprocessing.MinMaxScaler来实现这个功能。
MinMaxScaler有一个重要参数, feature_range,控制我们希望把数据压缩到的范围,默认是[0,1].
from sklearn.preprocessing import MinMaxScaler x = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]] scaler = MinMaxScaler(feature_range=[5,10]) #默认为[0,1] x = scaler.fit_transform(x) -
preprocessing.StandardScale
当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分 布),而这个过程,就叫做数据标准化(Standardization,又称Z-score normalization),公式如下:
在sklearn当中,我们使用preprocessing.StandardScaler来实现这个功能。
from sklearn.preprocessing import StandardScaler x = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]] stdsc = StandardScaler() x = stdsc.fit_transform(x) -
小结
大多数机器学习算法中,会选择StandardScaler来进行特征缩放,因为MinMaxScaler对异常值非常敏 感。在PCA,聚类,逻辑回归,支持向量机,神经网络这些算法中,StandardScaler往往是最好的选择。 MinMaxScaler在不涉及距离度量、梯度、协方差计算以及数据需要被压缩到特定区间时使用广泛,比如数字图像处理中量化像素强度时,都会使用MinMaxScaler将数据压缩于[0,1]区间之中
1.2缺失值处理
-
对于连续值,常常使用均值或者中位数去填充缺失值;
-
对于离散值,常常使用众数填充,或者把缺失值当作一个单独的类别。
-
对于缺失率超过一定阈值的特征,可以考虑直接舍弃。
# 用impute.SimpleImputer进行填补
from sklearn.impute import SimpleImputer
# 对连续值Age进行填充
Age = data.loc[:,"Age"].values.reshape(-1,1) #sklearn当中特征矩阵必须是二维
# 实例化
age_median = SimpleImputer(strategy="median") #用中位数填补 (默认均值填补)
age_0 = SimpleImputer(strategy="constant",fill_value=0) #使用具体值填补,用fill_value指定
# 转化
age_median = age_median.fit_transform(Age) #fit_transform一步完成调取结果
age_0 = age_0.fit_transform(Age)
#把填补后的列赋值回原来的矩阵里
data.loc[:,"Age"] = age_median
# 对离散值Embarked进行填充
Embarked = data.loc[:,"Embarked"].values.reshape(-1,1)
Embarked_most = SimpleImputer(strategy = "most_frequent") #使用众数填补
data.loc[:,"Embarked"] = Embarked_most.fit_transform(Embarked)
# 用Pandas进行填补
import pandas as pd
data.loc[:,"Age"] = data.loc[:,"Age"].fillna(data.loc[:,"Age"].median()) #.fillna 在data1Frame里面直接进行填补
data.dropna(axis=0,inplace=True) #.dropna(axis=0)删除所有有缺失值的行,.dropna(axis=1)删除所有有缺失值的列-
SimpleImputer参数详解
class sklearn.impute.SimpleImputer(*, missing_values=nan, strategy=‘mean’, fill_value=None, verbose=0, copy=True, add_indicator=False)-
missing_values:int, float, str, (默认)np.nan或是None, 即缺失值是什么。
-
strategy:空值填充的策略,共四种选择(默认)mean、median、most_frequent、constant。mean表示该列的缺失值由该列的均值填充。median为中位数,most_frequent为众数。constant表示将空值填充为自定义的值,但这个自定义的值要通过fill_value来定义。
-
fill_value:str或数值,默认为Zone。当strategy == "constant"时,fill_value被用来替换所有出现的缺失值(missing_values)。fill_value为Zone,当处理的是数值数据时,缺失值(missing_values)会替换为0,对于字符串或对象数据类型则替换为"missing_value" 这一字符串。
-
verbose:int,(默认)0,控制imputer的冗长。
-
copy:boolean,(默认)True,表示对数据的副本进行处理,False对数据原地修改。
-
add_indicator:boolean,(默认)False,True则会在数据后面加入n列由0和1构成的同样大小的数据,0表示所在位置非缺失值,1表示所在位置为缺失值。
-
1.3 处理离散特征:编码和哑变量
在sklearn当中,除了专用来处理文字的算法,其他算法在fit的时候全部要求输入数组或矩阵,也不能够导入文字型数据。为了让数据适 应算法和库,我们必须将数据进行编码,即是说,将文字型数据转换为数值型。
-
preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
from sklearn.preprocessing import LabelEncoder y = data.iloc[:,-1] #要输入的是标签,不是特征矩阵,所以允许一维 le = LabelEncoder() #实例化 label = le.fit_transform(y) # 匹配加转化一步到位 print(le.classes_) # 查看有多少类 -
preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数 (一般用于有序变量)
from sklearn.preprocessing import OrdinalEncoder # 类似的,实例化,匹配,转化 x = data_.iloc[:,1:-1] ol = OrdinalEncoder() x_train = ol.fit_transform(x) #接口categories_对应LabelEncoder的接口classes_,一模一样的功能 print(ol.categories_)
1.4 处理连续特征:二值化和分段
-
sklearn.preprocessing.Binarize 用于处理连续变量的二值化
根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量。大于阈值的值映射为1,而小于或等于阈值的值映射为0。默认阈值为0。
from sklearn.preprocessing import Binarizer X = data.iloc[:,0].values.reshape(-1,1) #类为特征专用,所以不能使用一维数组 Age = Binarizer(threshold=30).fit_transform(X) # 以30为阈值,>30为1,<30为0 -
sklearn.preprocessing.KBinsDiscretizer 用于给连续变量分箱
这是将连续型变量划分为分类变量的类,能够将连续型变量排序后按顺序分箱后编码。总共包含三个重要参数:分箱个数n_bins、编码方式encode、定义箱宽的方式strategy
from sklearn.preprocessing import KBinsDiscretizer X = data.iloc[:,0].values.reshape(-1,1) est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform') # 分箱后编码成分类数值 est.fit_transform(X) est = KBinsDiscretizer(n_bins=3, encode='onehot', strategy='uniform') #查看转换后分的箱:变成了哑变量 est.fit_transform(X).toarray()
2.特征提取
在数据维度很高时,我们会从中提取出一些有用的特征,降低数据处理的维度,方便计算,这个过程也被叫做降维。一般常用的降维方法有PCA和LDA。对于有标签的数据就使用LDA,而对于无监督的任务则使用PCA。
-
PCA:非监督降维,降维后数据的方差尽可能的大(方差大,含有的信息量就大)
-
LDA:有监督降维,降维后,组内(同一类别)方差小,组间(不同类别之间)方差大
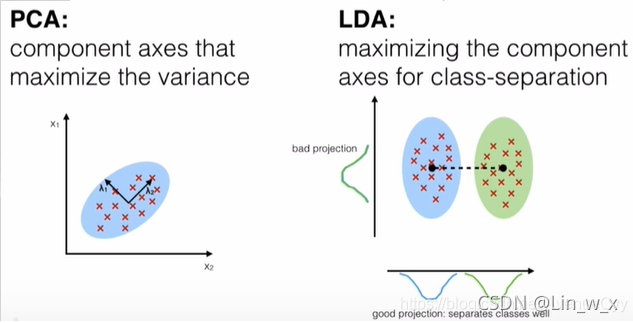
2.1 主成分分析PCA
PCA的一般用途:
-
聚类:把复杂的多维数据转为少量数据,易于分簇
-
降维:降低高维数据,简化计算,达到数据降维,压缩,降噪(去掉不太重要的特征)的目的
PCA的作用:
-
将原有的d维数据集,转为k维数据,k<d
-
新生成的k维数据尽可能多的保留原来d维数据的信息
PCA流程: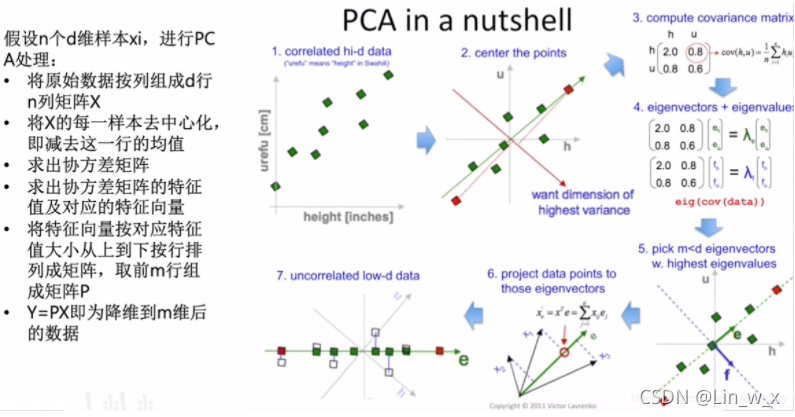
带核函数的PCA:
-
选择一个核函数。
-
根据原始的数据得到正规化的K。(相当于数据向高维的映射)
-
计算特征值和特征向量
-
进行降维
2.2 线性判别分析LDA
线性判别分析,可以做特征降维,也可以做分类方法。
LDA的降维流程:
3.性能评估指标
-
混淆矩阵
混淆矩阵中有着Positive、Negative、True、False的概念,其意义如下:
称预测类别为1的为Positive(阳性),预测类别为0的为Negative(阴性)。 预测正确的为True(真),预测错误的为False(伪)。 对上述概念进行组合,就产生了如下的混淆矩阵:
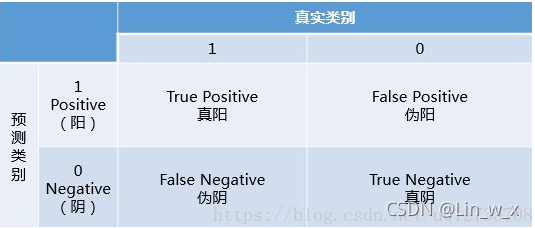
from sklearn.metrics import confusion_matrix y_pred = [0, 2, 1, 3,9,9,8,5,8] y_true = [0, 1, 2, 3,2,6,3,5,9] confusion_matrix(y_true, y_pred)TP、FP、TN、FN,第二个字母表示样本被预测的类别,第一个字母表示样本的预测类别与真实类别是否一致
-
准确率
准确率(Accuracy):正确分类的样本个数占总样本个数, A = (TP + TN) / N
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3,9,9,8,5,8]
y_true = [0, 1, 2, 3,2,6,3,5,9]
accuracy_score(y_true, y_pred)-
精确率
精确率(Precision)(查准率):预测正确的正例数据占预测为正例数据的比例, P = TP / (TP + FP)
from sklearn.metrics import precision_score
y_pred = [0, 2, 1, 3,9,9,8,5,8]
y_true = [0, 1, 2, 3,2,6,3,5,9]
precision_score(y_true, y_pred, average='micro') # 微平均, 宏平均'macro' -
召回率
召回率(Recall)(查全率):预测为正确的正例数据占实际为正例数据的比例, R = TP / (TP + FN)
from sklearn.metrics import recall_score
y_pred = [0, 2, 1, 3,9,9,8,5,8]
y_true = [0, 1, 2, 3,2,6,3,5,9]
recall_score(y_true, y_pred, average='micro') # 微平均, 宏平均'macro' -
F1值
F1 值(F1 score): 调和平均值
from sklearn.metrics import f1_score
y_pred = [0, 2, 1, 3,9,9,8,5,8]
y_true = [0, 1, 2, 3,2,6,3,5,9]
f1_score(y_true, y_pred, average='micro') ## 微平均, 宏平均'macro','weighted'-
ROC曲线
接收者操作特性曲线(receiver operating characteristic curve,简称ROC曲TPR线),是指在特定刺激条件下,以被试在不同判断标准下所得的虚报概率FPR为横坐标,以击中概率TPR为纵坐标,画得的各点的连线。所以需要计算两个值:
1、虚报概率:横坐标,N是真实负样本的个数,FP是N个负样本中被分类器预测为正样本的个数。 FPR=FP/(FP+TN)
2、击中概率:纵坐标, TPR=TP / (TP+FN)TPR
AUC是一个模型评价指标,只能用于二分类模型的评价。AUC的本质含义反映的是对于任意一对正负例样本,模型将正样本预测为正例的可能性大于将负例预测为正例的可能性的概率,是Area under curve的首字母缩写。Area under curve是什么呢,从字面理解,就是一条ROC曲线下面区域的ROC面积。
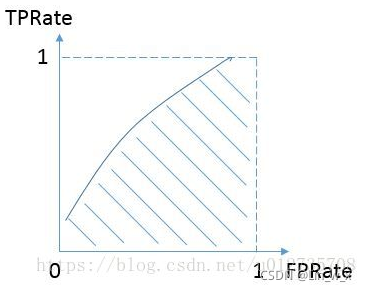
# 1,计算AUC值
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
roc_auc_score(y_true, y_scores)
# 2,ROC曲线
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2)
plt.figure(figsize=(10,10))
plt.plot(fpr, tpr, color='darkorange',
label='ROC curve (area = %0.2f)' % roc_auc_score(y, scores)) ###假正率为横坐标,真正率为纵坐标做曲线
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic curve')
plt.legend(loc="lower right")
plt.show()
##通过decision_function()计算得到的y_score的值,用在roc_curve()函数中
#clf = svm.SVC()
#clf.fit(X_train, y_train)
#y_score = clf.decision_function(X_test)-
小结:
准确率、精确率、召回率、F1 值主要用于分类场景。
准确率可以理解为预测正确的概率,其缺陷在于:当正负样本比例非常不均衡时,占比大的类别会影响准确率。如异常点检测时:99% 的都是非异常点,那我们把所有样本都视为非异常点准确率就会非常高了。
精确率,查准率可以理解为预测出的东西有多少是用户感兴趣的;
召回率,查全率可以理解为用户感兴趣的东西有多少被预测出来了。
一般来说精确率和召回率是一对矛盾的度量。为了更好的表征学习器在精确率和召回率的性能度量,引入 F1 值。
AUC 的一般判断标准
0.5 - 0.7: 效果较低,但用于预测股票已经很不错了
0.7 - 0.85: 效果一般
0.85 - 0.95: 效果很好
0.95 - 1: 效果非常好,但一般不太可能
4.代码案例
人脸识别项目
数据集:特征:rawdata文件夹下的所有文件,按文件名对应标签id;标签:faceDR,faceDS(原始数据),faceDR_cleared.csv,faceDS_cleared.csv(已处理数据)
处理原始文件函数:dataProcessing.py
# 功能:输入一个文件得到一个处理好的列表
import pandas as pd
def loadDataProcessing(file):
with open(file) as f:
s = f.read().splitlines() # 读取逐行数据放入list列表中
allMessage = []
for i in range(len(s)):
# print(s[9])
temp = s[i]
temp = temp.split(' ') # 按空格划分字符串为list列表
while '' in temp: # 删除list中的空元素
temp.remove('')
# print(temp)
# 对单行进行赋值处理
if len(temp) > 10:
id = temp[0]
sex = temp[2][:-1]
age = temp[4][:-1]
race = temp[6][:-1]
face = temp[8][:-1]
prop = temp[10:]
prop[0] = prop[0][2:]
prop.pop(-1)
# 判断prop是否为空,并且根据prop特征的个数来用空格进行拼接
if len(prop) != 0:
str = ''
for i in range(len(prop) - 1):
str = str + prop[i] + ' '
str = str + prop[len(prop) - 1]
prop = str
else:
prop = 'NaN'
# print(prop)
temp = [id, sex, age, race, face, prop]
allMessage.append(temp)
# print(temp)
else:
pass
# id = temp[0]
# temp = [id, "missing descriptor"]
# print(temp)
# allMessage.append(temp)
return allMessage
# 保存为csv文件
# x1 = loadDataProcessing("faceDR")
# x2 = loadDataProcessing("faceDS")
# x = x1 + x2
# print(len(x))
# name = ['id', 'sex', 'age', 'race', 'face', 'prop']
# file = pd.DataFrame(columns=name, data=x)
# # print(file)
# file.to_csv("./myFace.csv", encoding='gbk', index=False)主程序:face_test1.py
import pandas as pd
import os
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
import dataProcessing as dP
from sklearn.preprocessing import LabelEncoder
def roadLabels(path):
# 将字符串标签“male”,“female”处理为1,0
if (type(path).__name__ == 'list'): # 用于处理列表数据
labels = []
for i in range(len(y)):
labels.append(y[i][1])
else: # 用于处理csv文件
df = pd.read_csv(path)
labels = df.iloc[:, 1].values.tolist()
# for i in range(len(labels)):
# if labels[i] == "male":
# labels[i] = 0
# else:
# labels[i] = 1
le = LabelEncoder()
labels = le.fit_transform(labels)
return labels
def roadData(path):
# 读取文件夹下的文件,返回一个list列表
path = path # 文件夹目录
files = os.listdir(path) # 得到文件夹下的所有文件名称
# f = open(path+"/"+files[0],'rb')
# s=np.fromfile(f,dtype=np.ubyte)
# s=np.int_(s)
# flag=0
s = []
for file in files: # 遍历文件夹
with open(path + '/' + file, 'rb') as f:
x = np.fromfile(f, dtype=np.ubyte)
x = np.int_(x)
s.append(x)
return s
x = roadData("./rawdata") # 读取文件夹下的文件
# prat_2使用处理好的文件标签
# y1 = roadLabels("faceDR_cleared.csv")
# y2 = roadLabels("faceDS_cleared.csv")
# y = np.append(y1, y2)
# part_3使用原始数据标签
y1 = dP.loadDataProcessing('faceDR')
y2 = dP.loadDataProcessing('faceDS')
y = y1 + y2
y = roadLabels(y)
# print(y)
# print(len(x))
# print(len(y))
print(len(x[1186]))
print(len(x[1190]))
x.pop(1190)
x.pop(1186)
y = np.delete(y, 1190)
y = np.delete(y, 1186)
# y.pop(1190)
# y.pop(1186)
print(len(x))
print(len(y))
stdsc = StandardScaler() # 标准化
x = stdsc.fit_transform(x)
# # scaler = MinMaxScaler() # 归一化
# # x = scaler.fit_transform(x)
#
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.1)
clf = svm.SVC()
clf.fit(x_train, y_train)
y_hat = clf.predict(x_test)
y_score = clf.decision_function(x_test)
print("混淆矩阵:")
print(confusion_matrix(y_test, y_hat))
print("准确率:", accuracy_score(y_test, y_hat))
print("精确率:", precision_score(y_test, y_hat, pos_label=1, average='binary'))
print("召回率:", recall_score(y_test, y_hat, pos_label=1, average='binary'))
print("F1值:", f1_score(y_test, y_hat, pos_label=1, average='binary'))
y = np.array(y_test)
print("AUC值:", roc_auc_score(y, y_score))
fpr, tpr, thresholds = roc_curve(y, y_score, pos_label=1)
plt.figure(figsize=(5, 5))
plt.plot(fpr, tpr, color='darkorange',
label='ROC curve (area = %0.2f)' % roc_auc_score(y, y_score)) ###假正率为横坐标,真正率为纵坐标做曲线
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic curve')
plt.legend(loc="lower right")
plt.show()结果:
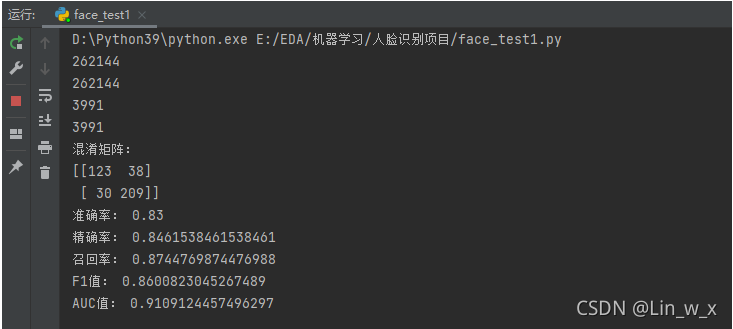
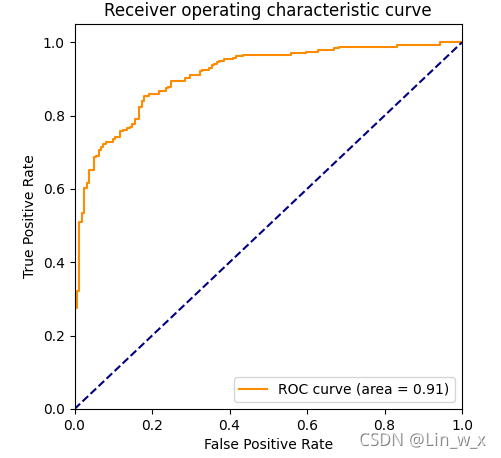
PS:精确率、召回率和F1值计算错误!!!可能原因为混淆矩阵的labels跟各指标的pos_label选取不一致导致。
参考资料:
1.【机器学习】scikit-learn中的数据预处理小结(归一化、缺失值填充、离散特征编码、连续值分箱) - 亚北薯条 - 博客园 (cnblogs.com)
2. 缺失值处理:SimpleImputer(简单易懂 + 超详细)向日葵的专属太阳-优快云博客simpleimputer
3. 数据挖掘:特征提取——PCA与LDA_AvenueCyy的博客-优快云博客_数据挖掘特征提取
4.Python机器学习笔记:常用评估模型指标的用法 - 战争热诚 - 博客园 (cnblogs.com)
5.多分类机器学习评价指标之准确率、精确率、召回率、F1值、ROC、AUC_qwe1110的博客-优快云博客_多分类准确率
6. scikit-learn工具包中分类模型predict_proba、predict、decision_function用法详解_程大海的博客-优快云博客

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









