




前言
本篇博客是我对分别使用MLP和CNN完成姓氏分类系统进行了学习之后,使用费曼学习法通过输出反向倒逼自己"被输入"知识,从而更好的学习这方面的知识.若文中存在任何错误或不当之处,恳请各位不吝赐教.
本文主要分为使用MLP完成姓氏分类系统和使用CNN完成姓氏分类系统两部分.先对不同模型的原理进行分析和讨论,再使用代码实现.
姓氏分类系统的任务是将姓氏分类到其原籍国
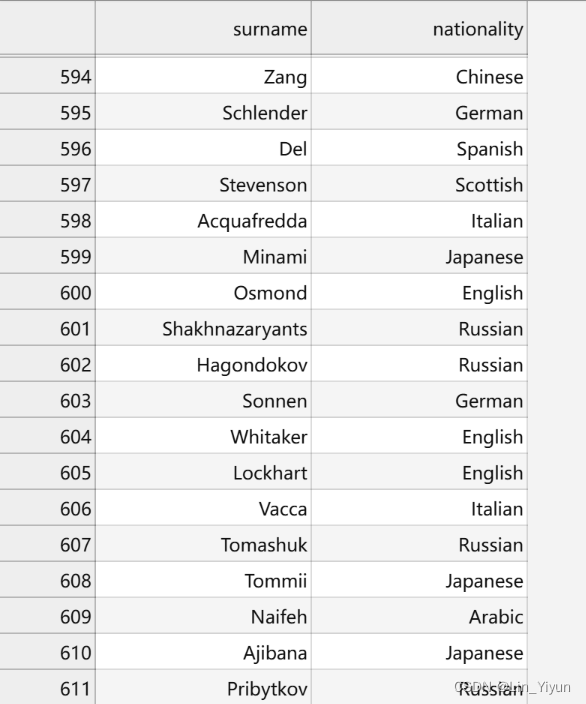
通过让模型学习这些数据,任意给一个姓氏,让模型预测是哪个国家的姓氏
看起来很简单吧,让我们开始吧!
MLP?你小子行吗?
MLP的原理分析
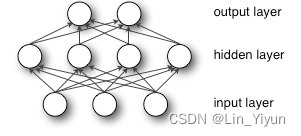
上图就是一个最简单的MLP结构示意图
除了输入层和输出层,多层感知机(MLP)还包括至少一层隐藏层,实际上,可以有多个这样的隐藏层。值得注意的是,这些层之间是全连接的,意味着前一层的每一个神经元都与下一层的所有神经元相连,这种结构确保了信息能够在整个网络中充分传播和交互。
具体来说,隐藏层的作用在于进行非线性变换
什么是线性变换 什么又是非线性变换???
线性变换
在神经网络中,每一层的神经元接收来自前一层的输入,并执行加权求和的操作,再加上一个偏置项(bias)。这个过程可以用矩阵乘法和向量加法表示,本质上是一个线性变换。如果网络只包含这些线性变换,无论有多少层,整体上它仍然只能表达一个线性函数,因为线性函数的复合仍然是线性函数。
非线性变换:激活函数的角色
为了使神经网络能够逼近复杂的非线性函数,我们需要在每一层的线性变换之后添加一个非线性元素,这就是激活函数的由来。激活函数是一个非线性的数学函数,它被应用于每个神经元的加权求和结果上,产生该神经元的最终输出。
举个例子,考虑一个二分类问题,其中两类数据在二维平面上的分布是非线性的,无法通过一条直线分开。在这种情况下,单靠输入层和输出层的线性操作是无法实现有效分类的。但通过添加隐藏层,尤其是多层隐藏层,网络就能学会构建更复杂的决策边界,有效地将这两类数据区分开来。
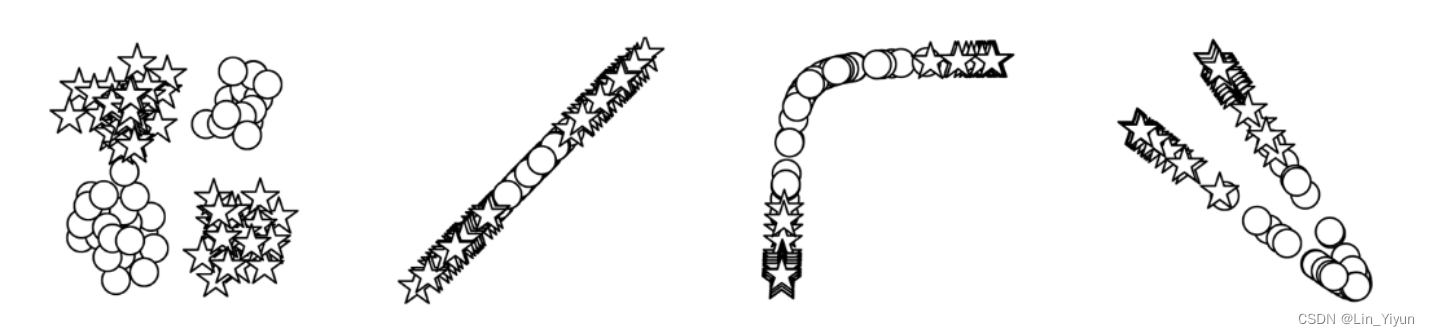
现在我们再把MLP和我们要解决的问题---姓氏分类到其原籍国 联系一下
我们在怎么做?
- 先要有一个数据集,无论是机器学习还是深度学习都遵循着"垃圾进垃圾出"的定律,进行数据清洗,特征工程
- 然后就将数据丢进MLP?不太行吧,MLP也不是什么都吃的 我们得将数据变成MLP能吃下去的形式,所以可以使用词汇表、向量化器和DataLoader将姓氏字符串转换为向量化的minibatches.
- 然后就让MLP这小伙子开始学?把这些姓氏和国籍给他"吃"(学习)一遍,然后就开始考试?显然是不对的吧?以辅导老师的角度想一想,如果让你去辅导MLP这小伙去备战高考,你会怎么做?
- 先让MLP这小伙子把考点熟悉一遍
- 做个小测试,看看他哪些学的好哪些学的不好
- 根据测试结果调整授课侧重点
- 再测试再调整
让我们回到MLP模型的训练上来,把辅导高考的流程转移到训练模型上
- 前向传播---把考点熟悉一遍
- 损失函数---做个小测试
- 梯度下降算法---调整侧重点
- 反向传播---再测试再调整
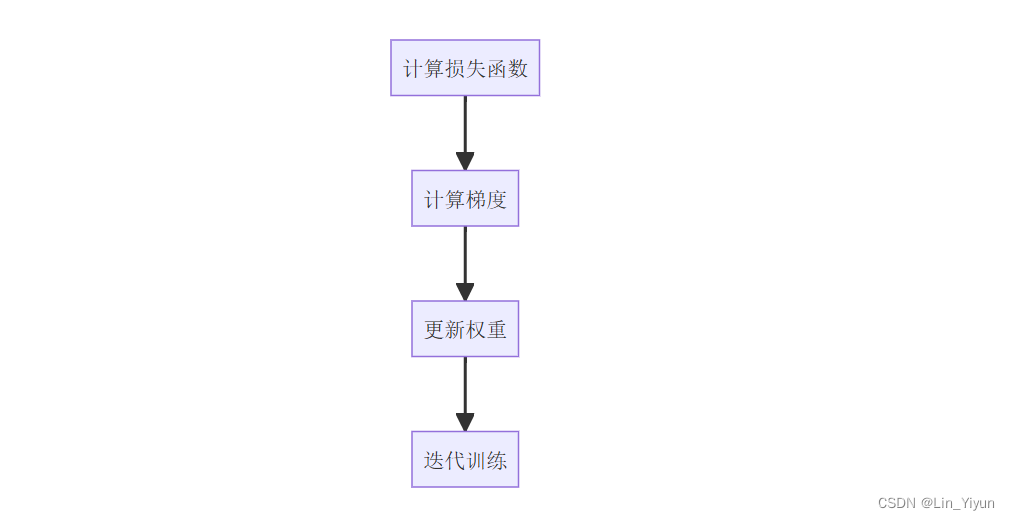
大概流程已经知道了,让我们开始编码吧
编码
向量化
使用词汇表、向量化器和DataLoader将姓氏字符串转换为向量化的minibatches,让MLP能看得懂"考点"
The Vocabulary
class Vocabulary(object):
"""Class to process text and extract vocabulary for mapping"""
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
"""
Args:
token_to_idx (dict): a pre-existing map of tokens to indices
add_unk (bool): a flag that indicates whether to add the UNK token
unk_token (str): the UNK token to add into the Vocabulary
"""
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx
self._idx_to_token = {idx: token
for token, idx in self._token_to_idx.items()}
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token)
def to_serializable(self):
""" returns a dictionary that can be serialized """
return {'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token}
@classmethod
def from_serializable(cls, contents):
""" instantiates the Vocabulary from a serialized dictionary """
return cls(**contents)
def add_token(self, token):
"""Update mapping dicts based on the token.
Args:
token (str): the item to add into the Vocabulary
Returns:
index (int): the integer corresponding to the token
"""
try:
index = self._token_to_idx[token]
except KeyError:
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
def add_many(self, tokens):
"""Add a list of tokens into the Vocabulary
Args:
tokens (list): a list of string tokens
Returns:
indices (list): a list of indices corresponding to the tokens
"""
return [self.add_token(token) for token in tokens]
def lookup_token(self, token):
"""Retrieve the index associated with the token
or the UNK index if token isn't present.
Args:
token (str): the token to look up
Returns:
index (int): the index corresponding to the token
Notes:
`unk_index` needs to be >=0 (having been added into the Vocabulary)
for the UNK functionality
"""
if self.unk_index >= 0:
return self._token_to_idx.get(token, self.unk_index)
else:
return self._token_to_idx[token]
def lookup_index(self, index):
"""Return the token associated with the index
Args:
index (int): the index to look up
Returns:
token (str): the token corresponding to the index
Raises:
KeyError: if the index is not in the Vocabulary
"""
if index not in self._idx_to_token:
raise KeyError("the index (%d) is not in the Vocabulary" % index)
return self._idx_to_token[index]
def __str__(self):
return "<Vocabulary(size=%d)>" % len(self)
def __len__(self):
return len(self._token_to_idx)The Vectorizer
class SurnameVectorizer(object):
""" The Vectorizer which coordinates the Vocabularies and puts them to use"""
def __init__(self, surname_vocab, nationality_vocab):
"""
Args:
surname_vocab (Vocabulary): maps characters to integers
nationality_vocab (Vocabulary): maps nationalities to integers
"""
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
def vectorize(self, surname):
"""
Args:
surname (str): the surname
Returns:
one_hot (np.ndarray): a collapsed one-hot encoding
"""
vocab = self.surname_vocab
one_hot = np.zeros(len(vocab), dtype=np.float32)
for token in surname:
one_hot[vocab.lookup_token(token)] = 1
return one_hot
@classmethod
def from_dataframe(cls, surname_df):
"""Instantiate the vectorizer from the dataset dataframe
Args:
surname_df (pandas.DataFrame): the surnames dataset
Returns:
an instance of the SurnameVectorizer
"""
surname_vocab = Vocabulary(unk_token="@")
nationality_vocab = Vocabulary(add_unk=False)
for index, row in surname_df.iterrows():
for letter in row.surname:
surname_vocab.add_token(letter)
nationality_vocab.add_token(row.nationality)
return cls(surname_vocab, nationality_vocab)
@classmethod
def from_serializable(cls, contents):
surname_vocab = Vocabulary.from_serializable(contents['surname_vocab'])
nationality_vocab = Vocabulary.from_serializable(contents['nationality_vocab'])
return cls(surname_vocab=surname_vocab, nationality_vocab=nationality_vocab)
def to_serializable(self):
return {'surname_vocab': self.surname_vocab.to_serializable(),
'nationality_vocab': self.nationality_vocab.to_serializable()}The Dataset
# 姓氏数据集
class SurnameDataset(Dataset):
def __init__(self, surname_df, vectorizer):
"""
Args:
surname_df (pandas.DataFrame): the dataset
vectorizer (SurnameVectorizer): vectorizer instatiated from dataset
"""
self.surname_df = surname_df
self._vectorizer = vectorizer
self.train_df = self.surname_df[self.surname_df.split=='train']
self.train_size = len(self.train_df)
self.val_df = self.surname_df[self.surname_df.split=='val']
self.validation_size = len(self.val_df)
self.test_df = self.surname_df[self.surname_df.split=='test']
self.test_size = len(self.test_df)
self._lookup_dict = {'train': (self.train_df, self.train_size),
'val': (self.val_df, self.validation_size),
'test': (self.test_df, self.test_size)}
self.set_split('train')
# Class weights
class_counts = surname_df.nationality.value_counts().to_dict()
def sort_key(item):
return self._vectorizer.nationality_vocab.lookup_token(item[0])
sorted_counts = sorted(class_counts.items(), key=sort_key)
frequencies = [count for _, count in sorted_counts]
self.class_weights = 1.0 / torch.tensor(frequencies, dtype=torch.float32)
@classmethod
def load_dataset_and_make_vectorizer(cls, surname_csv):
"""Load dataset and make a new vectorizer from scratch
Args:
surname_csv (str): location of the dataset
Returns:
an instance of SurnameDataset
"""
surname_df = pd.read_csv(surname_csv)
train_surname_df = surname_df[surname_df.split =='train']
return cls(surname_df, SurnameVectorizer.from_dataframe(train_surname_df))
@classmethod
def load_dataset_and_load_vectorizer(cls, surname_csv, vectorizer_filepath):
"""Load dataset and the corresponding vectorizer.
Used in the case in the vectorizer has been cached for re-use
Args:
surname_csv (str): location of the dataset
vectorizer_filepath (str): location of the saved vectorizer
Returns:
an instance of SurnameDataset
"""
surname_df = pd.read_csv(surname_csv)
vectorizer = cls.load_vectorizer_only(vectorizer_filepath)
return cls(surname_df, vectorizer)
@staticmethod
def load_vector 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









