



 本文介绍了机器学习中数据集划分的三种方法:留出法、交叉验证法和自助法。强调了保持训练、测试集合分布一致的重要性,以及在划分过程中应注意的问题,如样本分布、随机种子和避免交集。最后提到了sklearn库中相关函数的应用。
本文介绍了机器学习中数据集划分的三种方法:留出法、交叉验证法和自助法。强调了保持训练、测试集合分布一致的重要性,以及在划分过程中应注意的问题,如样本分布、随机种子和避免交集。最后提到了sklearn库中相关函数的应用。
机器学习中的一个必要问题就是模型评估。因此就需要划分训练集和测试集。
数据集划分有三种方式:留出法(hold-out)、交叉验证法(cross-validation)、自助法(bootstrapping)
留出法: 顾名思义单独留出一部分作为测试集合,并且两个集合互斥。极端情况就是留一法,在样本不足的时候可以考虑使用,否者计算开销太大。
实现 : sklearn.model_selection中的LeaveOneOut,LeavePOut
交叉验证法: 将训练集分成k折,每次取一折作为测试集,其余作为训练集。
实现 : sklearn.model_selection中的KFold,StratifiedKFold
自助法: 有放回的采样n个样本,n为数据集的大小。从概率上讲,大约会有三分一的样本未被采到,可以将未被采到的部分做为测试集,称之为”包外估计“。显然这种方法改变了数据分布,所以用的较少。
实现 : sklearn没有独立的划分实现,但是某些算法对bootstrap进行了支持,例如随机森林。
划分训练集和样本集合需要考虑的几个问题:
- 通常都需要保持训练、测试集合的分布与数据分布相一致。原因之一:试想如果两者分布不一致,而算法采用的又是朴素贝叶斯之类的,这样做的估计都是有偏差的,效果自然不好。第二:如果正例样本相对反例样本来说,占比很少。再经过随机抽样,那么训练样本中的正例更是少的可怜,可能就被分类器忽略掉了。
- 打散样本集合。为了避免训练顺序上某类样本总是先于其他类样本。
- 有时会需要固定随机种子,以保证再次运行得到的样本集都是相同的。避免多次运行能看到所有的样本。
- 训练集和测试集如果有交集,那么模型的评估就不可靠。可以看作是一种overfitting
最后引一下sklearn中关于数据划分的函数

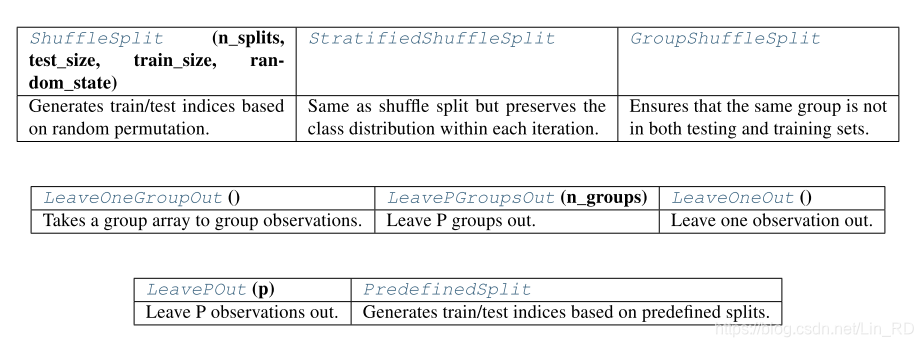
- 带Stratified表示分层抽样,即保持样本集合的分布一致。
- 带Shuffle表示将会打乱样本顺序进行划分。
- 带Group的表示划分以组为单位(要求组数大于折数),使用时需要传入样本集合的分组编号,组编号相同的一类样本将不会被拆分到两个集合中。(虽然我也不知道这个的需求在哪里)
参考:
1、西瓜书
2、scikit-learn官方文档(Release 0.20.1)
ps…作者认知有限,如有错误或者疑问请留言联系我,谢谢阅读。

















 3053
3053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









