




可靠性计算公式
-
可靠性=MTBF/(MTBF+MTTR)
-
MTBF:平均无故障时间,衡量稳定程度
-
MTTR:故障平均修复时间,衡量故障响应修复的速度
-
可靠性无限接近 100%,如果达到 99.999%,意味每年故障时间不超过5分钟
-
可靠性如果达到 99.9999%,意味每年故障时间不超过 30秒
有什么高可靠性技术
-
链路备份技术
-
链路聚合:把多条物理链路聚合在一起,形成一条逻辑链路;采用链路聚合可以提供链路冗余性,又可以提高链路带宽
-
RRPP:快速环网保护协议,专门应用于以太网环的链路层协议;在以太网上一条链路断开时,RRPP能迅速恢复环网上各个节点之间的通信通路具有较高的收敛速度
-
Smart-Link:专用于双上行组网;实现了主备链路的冗余备份,具备快速收敛性能,收敛速度可达亚秒级;
-
-
设备备份技术
-
设备自身的备份技术:主备备份指备用主控板作为主用主控板的一个完全映象,除了不处理业务,不控制系统外,其它与主用主控板保持完全同步。当主用板发生故障或者被拔出时,备用板将迅速自动取代主用板成为新的主用板,以保证设备的继续运行。
-
设备间的备份技术VRRP:虚拟路由冗余协议;VRRP将可以承担网关功能的路由器加入到备份组中,形成一台虚拟路由器;保证主机的下一跳出现故障时,可以及时由另一台设备来代替;
-
-
堆叠技术
-
IRF:智能弹性架构,将多台设备通过堆叠口连接在一起形成一台"联合设备",用户对这台"联合设备"进行管理,实现对堆叠中所有设备进行管理
-
链路聚合是什么?
-
链路聚合是把多条物理链路聚合在一起,形成一条逻辑链路
-
采用链路聚合可以提供链路冗余性,又可以提高链路的带宽
静态链路聚合和动态链路聚合的区别
-
静态聚合:
-
端口不与对端设备交互信息
-
选择参考端口只根据本端设备信息
-
一旦配置好后,端口的选中/非选中状态就不会受网络环境的影响,比较稳定
-
不能根据对端的状态调整端口的选中/非选中状态,不够灵活
-
-
动态聚合:
-
端口 LACP 协议自动使能,与对端设备交互LACP 报文
-
选择参考端口根据本端设备和对端设备交互信息
-
端口的选中/非选中状态容易受网络环境的影响,不够稳定
-
能够根据对端和本端的信息调整端口的选中/非选中状态,比较灵活
-
-
使用静态聚合和动态聚合的场景:
-
静态聚合:
-
一般建议跨厂商设备使用静态聚合,因为不同厂商对接可能因为协议报文的处理机制不同而产生对接异常,而静态聚合则无需担心协商的问题
-
网络规模较小相对稳定的环境拓扑结构相对简单且很少发生变化,不需要频繁调整的场景
-
对网络性能有明确规划和要求的场景,比如需要为某些业务提供稳定且足够的带宽,确保稳定性;
-
-
动态聚合
-
网络规模较大且变化频繁的环境,网络拓扑结构复杂且可能会频繁调整建议使用比较灵活的动态聚合;
-
需要链路自动备份和恢复的场景,动态聚合协议能够实时监测链路的状态,当发现某条链路故障时,自动将流量切换到其他可用链路上
-
-
一端是二层的接口,另一端是三层的接口,链路聚合可以成功吗
-
可以聚合成功,但是需要注意一些条件
-
链路聚合是基于数据链路层的技术,其核心功能是将多个物理端口捆绑为逻辑端口,与网络层的IP路由功能无直接关联;因此,只要两端设备均支持相同的链路聚合协议(如LACP)即使一端为二层接口、另一端为三层接口,也可成功建立聚合链路;
-
但是,需要注意的是,链路聚合的成功取决于网络设备的支持和配置。如果设备不支持链路聚合或配置不正确,则链路聚合可能会失败。
如何查看链路聚合是否成功
-
可以使用命令 display link-aggregation summary来查看,可以通过查看选中端口的个数
-
也可以使用命令 display link-aggregation verbose 来查看端口选中的详细信息
-
可以使用命令 display interface Bridge-Aggregation1 来查看聚合端口的带宽信息
链路聚合端口的第一类配置和第二类配置的意义,分别有哪些配置
有些端口选中有些端口未选中怎么排查?
根据对聚合成员端口状态的影响不同,可以把端口配置分为三类:
-
端口属性类配置:包括速率、双工模式、端口状态(UP/DOWN)这三项配置速率和双工模式会参与参考端口选举,链路状态会影响成员端口是否被选中
-
第一类配置:此类配置可以在聚合端口和成员端口上配置,但不参与操作Key 计算,如 MVRP、MSTP 等,就算成员端口与参考端口的第一类配置不一致,也不会导致端口未选中
-
第二类配置:此类配置参与操作 Key 计算,包括vlan配置、端口类型、BPDU Tunnel、端口隔离、端口属性、QinQ、Mac地址学习配置;成员端口与参考端口的第二类配置不一致,会导致端口未选中
-
一个百兆一个千兆端口能成功建立吗?
-
端口属性类配置无法成功建立
-
(不过在某些产品上面可以使用命令忽略这个去建立)
-
链路聚合成员端口的状态有哪些
-
聚合组中的成员端口有两种状态:Selected 状态和Unselected
-
Selected(选中)状态:处于 Selected 状态的端口可以参与转发用户数据,聚合端口的速率,双工状态由其Selected成员端口决定,速率等于Selected成员端口的速率之和,端口双工状态与成员端口一致
-
Unselected(未选中)状态:处于 Unselected 状态的端口不能转发用户数据
-
链路聚合中操作 Key 有什么作用
-
操作 Key 是在链路聚合时,聚合控制根据成员端口的某些配置自动生成的一个配置组合,包括端口速率、双工模式和链路状态的配置。在聚合组中,处于Selected 状态的成员端口具有相同的操作 Key,其中第一类配置不参与操作Key 的计算、第二类配置会参与操作Key的计算。
-
第一类配置:此类配置可以在聚合端口和成员端口上配置,但是不会参与操作Key 的计算、比如 GVRP、MSTP 等。
-
第二类配置:同一聚合组中,如果成员端口与聚合端口的第二类配置不同,那么该成员端口将不能成为 Selected 端口,第二类配置主要包含如下内容:
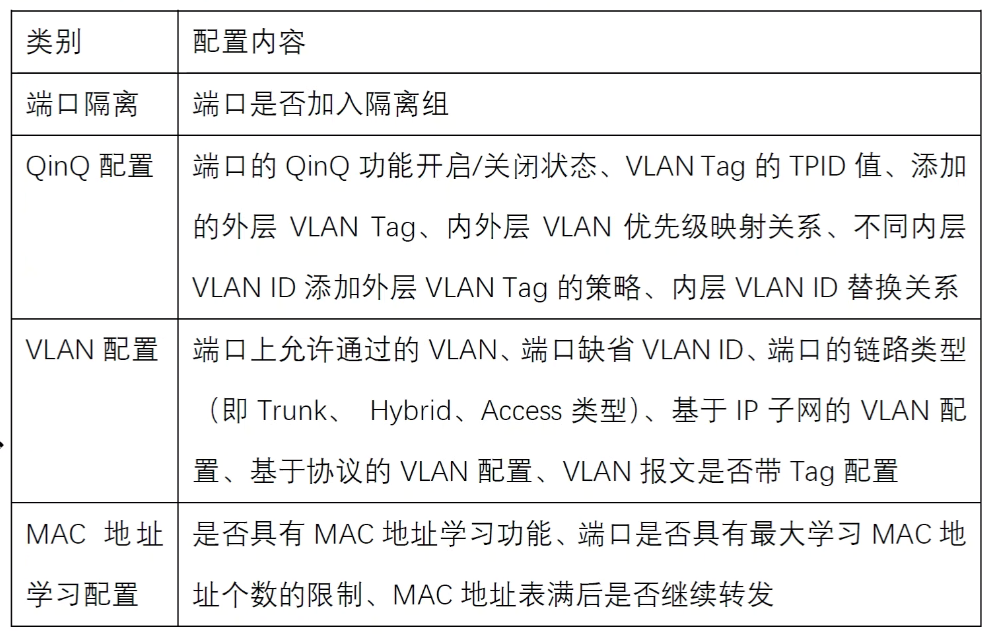
链路聚合的参考端口选举规则
-
参考端口从成员端口中选出,其端口属性类配置和第二类配置将作为同一聚合组内的其它成员端口的参照,以确定这些成员端口的状态
-
静态聚合中的参考端口选举:由于不与对端设备交互,所以聚合链路的两端各自选举各自的参考端口
-
首先比较端口优先级(越小越优)
-
如果优先级相同,依次检查双工模式(全双工>半双工),速率(高速率>低速率)
-
如果优先级一致,速率和双工模式也一致比较端口号(小的成员端口作为参考端口)
-
-
动态聚合中的参考端口选举:端口使用LACP协议与对端交互对端设备交互LACP报文,两台交换机共同选举出一个参考端口
-
先选举出优胜的设备,设备ID小的优先。
-
设备ID=系统LACP 优先级+系统MAC地址。
-
优先级默认32768,优先级数值越小,优先级越高
-
-
再在优胜的设备中,选举参考端口,端口ID 小的优先
-
端口ID=端口LACP优先级+端口号
-
端口优先级默认为32768
-
(与接口带宽无关,接口带宽的大小不影响参考端口的选举,但是接口带宽的大小,会影响最终可以加入聚合组的成员端口)
-
-
可以在系统视图使用lacp system-priority xxx 来设置 LACP 的系统优先级取值范围是 0-65535,可以取范围中的任意值
-
可以在接口视图使用link-aggregationport-priority xx来设置接口的LACP优先级
-
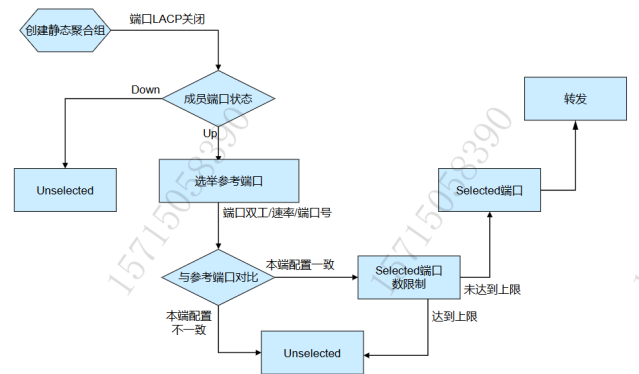
静态聚合流程
-
-
当聚合组内有处于UP 状态的端口时
-
选参考端口:
-
系统按照端口的高端口优先级、全双工/高速率、全双工/低速率、半双工/高速率、半双工/低速率的优先次序,选择优先次序最高且处于 UP 状态的、端口的第二类配置和对应聚合端口的第二类配置相同的端口作为该组的参考端口(优先次序相同的情况下端口号最小的端口为参考端口)
-
-
与参考端口的端口属性配置和第二类配置一致且处于 UP 状态的端口成为可能处于 Selected 状态的候选端口,其它端口将处于 Unseleeted 状态。
-
聚合组中处于 Seleeted 状态的端口数是有限制的
-
当候选端口的数目未达到上限时,所有候选端口都为 Selected 状态,其它端口为 Unselected 状态;
-
当候选端口的数目超过这一限制时,系统将按照端口号从小到大的顺序选择一些候选端口保持在 Selected 状态,端口号较大的端口则变为 Unselected 状态。
-
动态聚合模式中如何完成成员端口的选择
-
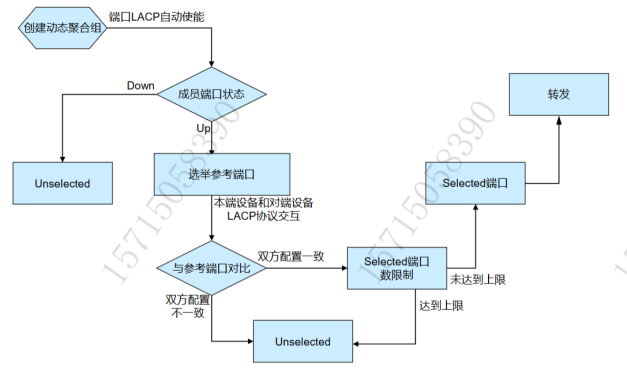
-
当聚合组配置为动态聚合模式后,聚合组中的LACP协议自动开启
-
当聚合组内有处于UP 状态的端口时
-
选参考端口
-
先选举出优胜的设备,设备ID小的优先。
-
再在优胜的设备中,选举参考端口,端口ID 小的优先
-
-
与参考端口的端口属性配置和第二类配置一致且处于 UP 状态的端口成为可能处于 Selected 状态的候选端口,其它端口将处于 Unseleeted 状态。
-
聚合组中处于Selected状态的端口数量有限制:
-
当候选端口的数目未达到上限时,所有端口都为Selected状态,其他端口为Unselected状态
-
当候选端口的数目超过这一限制时,系统将按照端口ID从小到大的顺序选择一些端口保持在Selected状态,端口ID较大的端口则变为Unselected状态
-
同时设备会感知这种状态的改变,相应的端口状态随之改变
-
-
因硬件限制而无法与参考端口聚合的端口将处于Unselected状态
-
信息可通过命令 display link-aggregation verbose 查看。
如果链路聚合的成员端口数量超出了配置的最大选中接口上限,如何决定哪个端口不选中
-
如果有多个端口且第二类配置都与参考端口一致,则按照端口号从小到大的顺序,端口号最大的不被选中
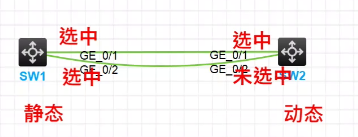
一端是静态聚合,另一端是动态聚合,可以正常聚合成功吗
-
不能聚合成功
-
静态聚合端口不与对端设备交互信息,动态聚合端口需要与对端设备交互LACP报文,所以无法正常聚合成功
-
因为静态聚合的端口不与对端设备交互信息,只要本地的成员端口属性类配置和第二类配置和参考端口的一致,就可以加入静态聚合组,并且端口状态都是显示为选中状态,而动态聚合因为对端不和本端交互 LACP 报文,所以无法聚合成功,端口状态会有一个显示为选中状态,其他接口显示为未选中状态
端口是什么状态?对业务的使用有影响吗?
-
静态接口都是选中状态,动态聚合可能只有一个接口选中,聚合失败
-
对业务的使用有影响,可能会出现丢包的问题,有些链路通,有些不通,两边都是选中端口的可以通;
链路聚合负载分担支持的类型
-
链路聚合的负载分担不明显速率没有提升是什么原因?
-
根据目的去负载分担,都设置同一个接口
-
-
根据报文 MAC 地址进行负载分担
-
根据报文的 VLAN 标签进行负载分担
-
根据报文的服务端口号进行负载分担
-
根据报文的入端口进行负载分担
-
据报文的 IP 地址进行负载分担
-
根据报文的 MPLS 标签进行负载分担
-
在聚合接口视图使用 link-aggregation load-sharing mode xxx 命令来调整负载均衡的方式
LACP 的长超时和短超时
-
LACP协议
-
链路聚合控制协议
-
实现链路动态聚合与解聚合的协议
-
LACP协议通过LACPDU与对端交互信息
-
链路的两端分别称为Actor和Partner
-
双方通过交互LACPDU报文向对端通告自己系统优先级,系统MAC地址,端口优先级,端口号,操作Key
-
对端收到信息后,进行比较选择能够聚合的端口
-
-
怎么检测现有的成员端口是有效还是无效的呢?
-
LACP 超时时间是指成员端口等待接收 LACPDU 的超时时间。在三倍 LACP 超时时间之后,如果本端成员端口仍未收到来自对端的 LACPDU,则认为对端成员端口已失效,LACP 超时时间只有短超时(1秒)和长超时(30 秒)两种取值。
-
链路聚合使能 LACP 协议后,会启动超时时间,超时后仍未收到对方的 LACP报文,则判断为对端不可达,本端成员端口立即变为 Down,不再转发数据。
-
H3C 的 LACP 默认超时时间为长超时 30 秒可以手动配置为短超时时间1秒
LACP 协议除了在链路聚合还在什么地方使用?
-
在对 IRF进行分裂检测时,使用 MAD LACP的方式时会使用到LACP 协议来检查 IRF是否发生了分裂
-
M-LAG
聚合参考端口重新选举时,聚合口会不会 Down
-
不会。
链路聚合的流量转发不均匀时,有什么办法解决?
-
可以根据具体情况调整链路聚合的负载均衡算法,如基于MAC地址或 IP地址等,以实现均衡转发
-
调整链路聚合端口状态如禁用某些端口或调整端口优先级等。
-
通过优化网络拓扑结构,如增加交换机,调整交换机位置等,以改善链路聚合转发不均匀的情况。
Smart-link 的技术优势和使用场景
-
Smart-link 是一种使用在双上行链路组网中的高可靠性技术,通过把一主一备两个端口加入到一个Smart-link组,默认开启主端口,关闭备份端口。当主口故障,自动放开备份端口来实现故障切换
-
Smart-link 的优势在于极快的收敛速度,可以达到厘秒级。由于 Smart-link只运行在双上行连接到上游的下游交换机上,所以链路故障切换无需与其他设备交互任何信息,也无需任何计算,所以可以实现快速收敛。但是Smart-link也只能使用在双上行组网中,如果是多路上行,则无法使用
-
Smart-link 一般用于园区网的接入层双上行到汇聚层的场景,是 H3C的私有协议。该协议与 STP,RRPP 互斥所以加入Smart-link 组的端口需要关闭 STP 特性并不能配置为 RRPP 的端口
-
Smart-link组:灵活链路组
-
主端口(Master):
-
两个端口都处于UP状态超时时,主端口优先进入转发状态;
-
主链路故障,则处于待命状态的副端口切换为转发状态;
-
在没有配置角色抢占的情况下,即使主端口恢复正常,也只能处于待命状态,直到下一次链路切换
-
-
副端口(Slave):
-
两个端口都处于UP状态超时时,副端口保持待命状态
-
主链路故障,则处于待命状态的副端口切换为转发状态
-
-
Flush报文:
-
发送Flash报文通知其他设备进行MAC表和ARP/ND表的刷新操作
-
链路发生故障切换时,Smart-link从新的链路上发送Flush报文,Flush报文中会携带本机所学习到MAC地址表,收到Flush报文的交换机,会在接收报文的端口学习Flush报文中携带的MAC地址记录
-
-
发送控制VLAN:
-
用于发送Flash报文的VLAN
-
当发生链路切换时,设备会在发送控制VLAN内广播发送Flash报文
-
-
接收控制VLAN:
-
用于接收并处理Flush报文的VLAN
-
当发生链路切换时,设备接收并处理属于接收控制VLAN的Flash报文,进行MAC表和ARP/ND表的刷新操作
-
-
保护VLAN:
-
Smart link组控制其转发状态的用户数据VLAN;
-
同一端口上不同的Smart link组保护不同的VLAN
-
端口在保护VLAN上的转发状态由端口在其所属Smart Link组内的状态决定
-
-
Smart-link Flush 报文的作用和配置方法
-
当 Smart Link 组发生链路切换时,非直连的上游交换机原有的 MAC 地址表项将不适用于新的拓扑网络,需要网络中的所有设备进行 MAC 地址转发表项和ARP/ND 表项的更新。
-
这时,SmartLink组通过发送Flush 报文通知其它设备进行 MAC 地址转发表项和 ARP/ND 表项的刷新操作。Flush 报文是普通的组播数据报文,会被阻塞的接收端口丢弃
-
Flush 报文需要使用专门的控制VLAN 进行传递。控制VLAN分为发送控制VLAN和接收控制 VLAN
-
配置控制 VAN,需要在所有 Trunk 链路上放行控制VLAN,Smart-link组中配置控制VLAN,并在上游交换机的Trunk端口上配置允许在控制VLAN中收发Flush报文
-
Smart-link配置步骤
-
在所有交换机上创建业务VLAN和控制VLAN,并配置Trunk放行
-
在Smart-link交换机上创建MST实例,映射相关的保护VLAN和控制VLAN
-
在Smart-Link交换机的相关端口上关闭STP
-
在Smart-Link交换机上创建SMLK组,配置保护VLAN,控制VLAN,主备端口角色
-
在上游交换机的端口上配置允许在控制VLAN收发Flush报文
-
解决VLAN1的环路问题:
-
间VLAN1规划到实例1
-
-
Monitor-link 的作用
-
Monitor-Link是一种端口联动方案,主要用于配合二层拓扑协议的组网应用(如Smart-link),通过监控设备的上行端口,根据其 up/down 状态的变化来触发下行端口 up/down 状态的变化,从而触发下游设备上拓扑协议所控制备份链路的切换
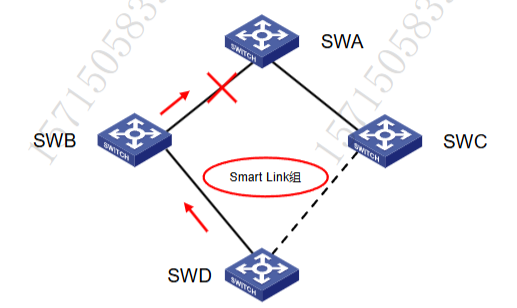
RRPP 的作用和使用场景
-
RRPP 是一个专门应用于以太网环的链路层协议。它在以太网环完整时能够防止数据环路引起的广播风暴,而当以太网环上一条链路断开时能迅速恢复环网上各个节点之间的通信通路,具备较高的收敛速度
-
RRPP 只能使用在环形组网中,且收敛速度可以达到厘秒级
-
RRPP是H3C的私有协议,与STP,Smart-link互斥
RRPP 的 Polling 机制和链路状态变化通知机制、两种机制的关系
-
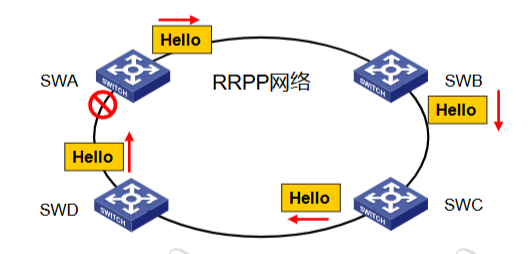
Polling(轮询)机制:主节点周期性地从其主端口发送 Hello 报文,依次经过各传输节点在环上传播。如果环路是健康的,主节点的副端口将在定时器超时前收到 Helo 报文,主节点将保持副端口的阻塞状态。如果环路是断裂的,主节点的副端口在定时器超时前无法收到 Heo 报文,主节点将解除保护 VLAN在副端口的阻塞状态,同时发送 Common-Flush-FDB 报文通知所有传输节点使其更新各自的 MAC 表项和 ARP/ND 表项
-
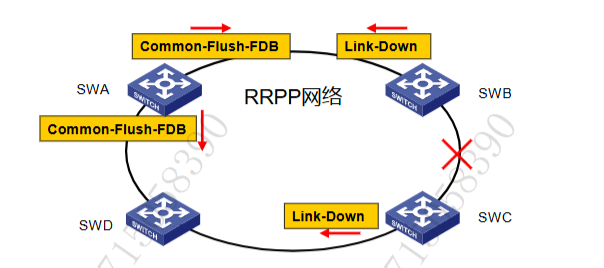
链路状态变化通知机制:当传输节点、边缘节点或者辅助边缘节点发现自己任何一个属于 RRPP 域的端口 DOWN 时,都会立刻发送 Link-Down 报文给主节点。主节点收到 Link-Down 报文后立刻解除保护 VLAN 在其副端口的阻塞状态,并发送 Common-Flush-FDB 报文通知所有传输节点、边缘节点和辅助边缘节点,使其更新各自的 MAC 表项和 ARP/ND 表项。各节点更新表项后数据流则切换到正常的链路上
-
两种机制同时工作,如果链路状态变化机制的Link-Down 报文由于网络拥塞而没有成功传递室主节点由于 Polling 机制的存在,当主节点副端口收不到 Hello报文时,仍然会解除副端口的阻塞状态
RRPP 子环的健康状态检测机制和相关问题
-
子环的健康状态检测机制:子环主节点的主端口周期性发送Hello 报文,Hello报文分别沿主环链路和主环与矛环相交的链路转发。只有子环和主环相交的链路和某一条主环链路同时故障,才会导致子环主节点的副端口无法收到 Hello报文,判断为子环故障。子环故障后,子环主节点立即开启副端口
-
如果存在多个子环公用相同的边缘节点时,当触发子环故障后,共用相同边缘节点的所有子环都会放开副端口,导致环路出现
-
通过主环上子环协议报文通道状态检测机制来解决该环路问题。正常情况下边缘节点周期性沿主环链路和主环与子环相交的链路发送 Edge-hello 报文,该报文会被辅助边缘节点接收。当子环和主环相交的链路和某一条主环链路同时故障,辅助边缘节点无法收到 Edge-hello 报文,立即沿子环链路发送 Major-fault报文边缘节点收到 Major-faut 报文后,立即阻塞所有边缘端口。阻塞完成后,子环主节点开启副端口,这时就不会产生环路
RRPP 的环组机制
-
在主环上子环协议报文通道状态检测机制中,如果存在多子环,边缘节点会周期发送每个子环上的 Edge-hello 报文。其实所有的子环都是共用的同一个边缘节点和辅助边缘节点,没有必要给每个子环都发送相关的报文。
-
在边缘节点和辅助边缘节点上把多个子环加入到一个环组。边缘节点上只有子环 ID 最小的才能发送 Edge-hello 报文。在辅助边缘节点环组内,任意激活子环收到 Edge-hello 报文会通知给其它已激活的子环。这样在边缘节点/辅助边缘节点上分别对应配置 RRPP 环组后,只有一个子环发送/接收 Edge-hello 报文,减少了对设备 CPU 的冲击
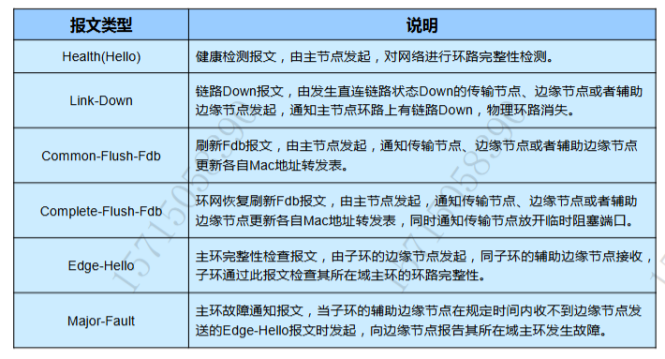
RRPP 报文类型有哪些,各个报文的作用是什么?
VRRP 的协议原理和使用场景
-
VRRP 将可以承担网关功能的一组路由器加入到备份组中,形成一台虚拟路由器,由 VRRP 的选举机制决定哪台路由器承担转发任务,局域网内的主机只需将虚拟路由器配置为缺省网关。当当前转发数据的网关路由器故障后,VRRP备份组内会选举出新的路由器来承担转发任务,而不必主机更换新的网关地址
-
VRRP 使用组播地址 224.0.0.18 来发送协议报文
-
IP协议号112
VRRP 有哪些协议报文?默认周期是多少?是否可以调整?什么情况下可以调整?
-
VRRP报文:通告报文,封装在IP报文中,协议号112;组播地址224.0.0.18
-
字段含义:
-
版本,类型
-
VRID:虚拟路由器标识符范围1-255
-
优先级:0-255,越大越优,默认100
-
IP地址个数:VRRP组中虚拟IP地址的个数
-
认证类型:0-无 ;1-明文 ; 2-MD5
-
通告时间:默认1s
-
校验和
-
IP地址:VRRP虚拟IP地址
-
认证数据
-
-
VRRP 报文:默认周期 100 厘秒(1s),可调整。在希望加速 VRRP 检测故障时可以把周期调小
-
免费 ARP 报文:VRRP 会使用免费 ARP 报文来通告虚拟 MAC地址。报文会在产生新的 Master 设备时发送
VRRP 的虚拟网关的 MAC地址是多少?
-
00-00-5E-00-01-Vrid
-
不能更改
-
虚拟路由器:VRRP为每个组抽象出一台虚拟路由器,是逻辑设备
-
虚拟IP地址:
-
由管理员配置VRRP时指定,通常不会和接口IP地址重叠; 重叠时该路由器无条件成为Master
-
-
虚拟MAC地址:
-
虚拟MAC地址的格式为:00-00-5E-00-01-[VRID};
-
当虚拟路由器回应ARP请求时,回应的是虚拟MAC地址,而不是接口的真实MAC地址。
-
-
VRRP 的选举规则和工作方式
-
VRRP选举规则:
-
优先级大的优先成为Master:优先级默认都是 100,手动配置范围为 1-254
-
优先级255:如果某台设备的真实 IP 和 VRRP 备份组的虚拟 IP地址一致,则优先级自动变成 255,一定为成为 Master 设备;并且接口IP 地址与虚拟 IP地址相同的路由器被称为"IP地址拥有者"。
-
优先级0:当Master设备接口Down,会自动发出优先级为0的VRRP协议报文,退出选举
-
-
运行时间更长的优先
-
IP地址大的优先
-
如果当前还未选出Master,当优先级和运行时间一致时,IP地址大的会成为Master
-
如果当前主备角色已经确定,优先级和运行时间一致时,IP地址大小不影响选举
-
-
-
VRRP的工作方式:
-
抢占方式:(默认工作的方式)一旦发现自己的优先级比当前的 Master 路由器的优先级高,就会对外发送VRRP 通告报文。导致备份组内路由器重新选举Master路由器,并最终取代原有的 Master路由器,同时主动发送免费 ARP 报文。相应地原来的 Master路由器将会变成 Backup路由器。
-
非抢占方式中,只要 Master路由器没有出现故障,Backup 路由器即使随后被配置了更高的优先级也不会成为Master路由器,在非抢占方式中,如果 Master 设备出现故障,Backup 设备在 Master_down_timer 之后会自动变成新的 Master 设备。
-
IP地址不参与抢占
-
-
能不能有两台以上的设备参与VRRP选举?
-
可以
-
-
只有一台设备启动VRRP行不行,可以的话是什么状态?
-
可以,会保持Master角色
-
-
要一个Backup成为新的Master有什么方法可以
-
抢占模式下修改优先级
-
部署VRRP监视(Track)功能,让Master优先级低于Backup
-
把Master设备关闭
-
(在虚拟IP和物理IP不-一致的情况)
-
VRRP 上行接口监视的技术原理
-
VRRP备份组中,只有 Master设备故障,或者抢占模式中出现优先级更高的设备,才会触发 Master 的抢占。如果 Master 设备只是上行接口故障,是不会触发角色抢占的。所以数据的转发任务仍然是当前Master 设备来承担、但是由于上行接口故障,实际上该设备已经无法正常转发数据
-
通过配置 Track 项来监视上行接口,可以实现当被监视的接口故障后,就降低该路由器的优先级至低于 Backup 设备的优先级,从而触发角色抢占
-
VRRP 可以关联哪些 Track
-
设备的直连物理接口或 VLANIF 接口状态
-
BFD
-
NOA
-
-
发生故障没有发送角色抢占的原因?
-
优先级调整太小
-
如果运行 VRRP 的两台路由器的角色都是 Master,要如何排查?
-
做了VRRP后怎么判断当前VRRP状态是否正常?有什么依据呢?
-
观察状态是否有一个Master其他为Backup
-
-
两端的 VRRP 版本是否一致
-
两端的 VRRP 的 VRID 是否一致
-
两端的 VRRP 验证是否一致(v2)
-
是否能正常收到 VRRP 通告报文
-
互联链路的中间设备或接口是否正常
-
互联链路的设备是否存在相应的VLAN,以及 Trunk 链路是否放行 VLAN
-
发送 VRRP 通告报文的链路是否被 STP 阻塞
-
-
执行命令 display cpu-usage,查看设备系统 CPU 资源的使用情况,如果设备CPU 使用率过高,可能存在网络攻击或广播风暴造成VRRP 协议不能被及时处理
-
没有都加入管理备份组
VRRP的成员备份和管理备份,管理备份的作用是什么
-
成员备份:
-
VRRP 的角色有 Master和 Backup,Backup 作为Master 的备份即成员备份
-
-
管理备份
-
设备上配置多个 VRRP 备份组承担流量转发时,因为每个 VRRP 备份组都需要单独维护自己的状态机,所以会产生大量VRRP 报文,对网络和CPU 性能都造成大量负荷。
-
通过将 VRRP 备份组分为管理备份组和成员备份组,当成员备份组关联管理备份组后,成员备份组就不再发送 VRRP 通告报文进行设备间的主备协商,其设备主备状态与管理备份组保持一致,从而大大减少了VRRP通告报文对网络带宽和 CPU 处理性能的影响。
-
-
管理备份的注意:
-
VRRP 管理备份组需要配置路由器在备份组中的优先级、抢占方式及监视功能等功能,保证可以正常选举出 Master 设备,VRRP 成员备份组不需要配置上述功能
-
VRRP 备份组无法同时作为管理备份组和成员备份组
-
可以实现无需对特定的 VRRP 组设置优先级和抢占等信息,可统一通过设置管理备份组的状态来调整成员备份组的状态。各个 VRRP 成员备份组也无需周期发送 VRRP 通告报文,由管理备份组统一发送,可用降低频繁发送VRRP 报文对设备资源消耗的影响
-
由于成员备份组不主动发送 VRRP报文,可能导致下游设备上的 MAC 表项不正确,建议在系统视图上配置 vrp send-gratuitous-arp 命令,配置 IPV4 VRRP Master路由器定时发送免费 ARP 报文。
-
VRRPV3
-
华三默认运行在v2
-
VRRPv3 可以同时支持IPV4 和 IPv6,多用于 IPv6 组网中的多网关冗余
-
VRRPv3 和 VRRPv3 是不兼容
-
VRRPv3 不会检查虚拟IP 地址是否与物理IP地址在同一个网段,但是 VRRPV2 会进行检查
VRRP 负载均衡模式
在同一个VRRP组开启负载均衡
-
在正常情况下,VRRP 中的 Master 设备处于转发状态,而 Backup 则不工作,处于监听状态。虽然可以创建多个备份组来实现对不同网段的负载,但局域网内的主机需要设置不同的网关,增加了配置复杂性。VRRP 可以配置为负载均衡模式,在提供虚拟网关冗余的基础上,实现流量负载均衡。
-
VRRP 负载均衡原理为:该模式下;VRRP 备份组会设置一个虚拟IP,为每个成员设备都分配一个虚拟 MAC;当 PC 发送 ARP 请求来询问网关虚拟 IP 的 MAC 地址时,备份组按照负载均衡的方式为不同的 PC通告不同的虚拟 MAC地址,从而实现所有的成员设备都处于工作状态
-
在系统视图使用 vrrp mode load-balance 命令开启 VRRP 的负载均衡
-
VRRP 的状态机制
-
有哪些角色?有哪些状态?
-
角色:Master路由器,Backup路由器
-
状态:Intialize状态,Master状态,Backup状态
-
-
Initialize(初始状态)
-
VRRP的初始状态;接口down,接口就会停滞在该状态,不会对VRRP报文做任何处理
-
-
Master(主状态)
-
该状态的路由器是当前VRRP组的主路由器,承担数据转发任务
-
工作:
-
定期发送VRRP通告报文,让Backup 路由器可以了解 Master 的状态,缺省1s
-
响应虚拟IP地址的ARP请求,回复的是虚拟 MAC 地址,实现虚拟路由器的冗余和透明切换。
-
转发目的MAC地址为虚拟MAC地址的IP报文
-
处理目的IP地址为虚拟IP地址的IP报文,如果是IP拥有者会接收并处理这个IP报文,如果不是IP拥有者会直接丢弃
-
-
状态转变:
-
当接收到比自己优先级大的报文则转为Backup状态。
-
当收到与自己优先级相同的报文时,保持Master状态。(进一步比较IP地址大小,大的优)
-
当接收到接口的Down事件时,转为Initialize状态。
-
-
-
Backup(备份状态)
-
该状态的路由器是备份路由器,不会参与数据转发工作,会实时监控当前Master路由器的状态,准备接替它的工作
-
工作:
-
接收Master设备发送的VRRP通告报文,判断Master设备的状态是否正常。
-
关于VRRP虚拟IP地址的ARP请求不予回应
-
丢弃目的MAC地址为VRRP虚拟MAC地址的数据帧
-
不接收IP地址为VRRP虚拟IP地址的数据包
-
收到比自己优先级小的VRRP报文时
-
丢弃这个报文,不对定时器重置处理
-
若干次这样处理后,Master_Down定时器到时,路由器转为Master状态
-
-
如果收到优先级和自己相同或者比自己优先级大的报文时,重置Master_Down定时器,不进一步比较IP地址的大小。
-
-
状态变化:
-
当接收到Master_Down定时器超时的事件时,会转为Master状态。
-
抢占模式下,发现自己优先级高于Master,就会取代Master路由器
-
当接收到接口的Down事件时,转为Initialize状态
-
-
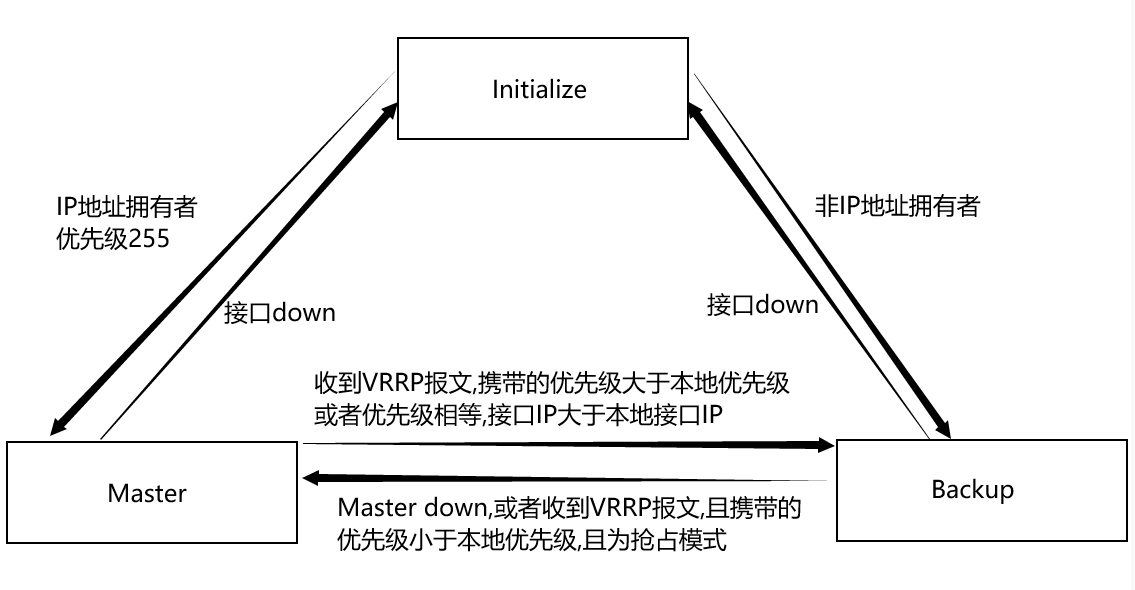
-
路由器启动后,VRRP先进入Initialize(初始化)状态,当接口收到 Startup 消息,将转入 Backup 状态;当本机优先级为 255时,会进入到 Master 状态
-
在 Master 状态中,路由器只有收到比自己优先级大的 VRRP 报文时,才会直接转为 Backup 状态;优先级一样比较IP大小,大的优先,如果是接口 Down,会先转为Initialize 状态
-
当路由器处于 Backup 状态时,将接收 Master 发送的 VRRP 报文。只有在接收到 Master_Down 这个定时器到时的事件时(指计时器超时后都没收到 Master的心跳报文),才会转为 Master。
Master设备状态的通告
-
Master设备周期性地发送VRRP通告报文,在VRRP备份组中通告其配置信息和工作状况。Backup设备通过收到VRRP通告报文来判断Master设备是否工作正常。
-
当Master设备主动放弃Master地位(如Master设备退出备份组)时
-
会发送优先级为0的通告报文,用来使Backup设备快速切换成Master设备
-
此时无需等到Master_Down定时器超时。
-
这个切换的时间称为Skew_Time,计算公式为:(256-Backup设备的优先级)/256,单位为秒。
-
-
当Master设备发生网络故障而不能发送通告报文的时候,Backup设备不能立即知道其工作状况。
-
等到Master_Down定时器超时后,才会认为Master设备无法正常工作,从而将状态切换为Master
-
其中,Master_Down定时器计算公式为:(3* Adver_Interval)+ Skew_Time,单位为秒。
-
Adver_Interval:报文发送时间间隔
-
-
公式如下:
-
Master_Down_Interval=(3*Advertisement Interval)+ Skew_time(偏移时间)
-
Skew Time=(256-Priority)/256
-
Advertisement _interval 默认为 100 厘秒(1s)
-
-
除了优先级还有IP地址还有什么会影响Master的选举呢?
-
优先级一样大,IP地址小反而成为Master
-
VRRP 主备角色频繁抢占如何处理
-
查看状态发现角色频繁发生变化改如何处理?什么原因引起的?
-
产生该故障的原因一般是由于 VRRP 组使能监视接口功能后,被监视端口状态不稳,使 VRRP 主设备的优先级频繁变化,而造成 VRRP 状态的频繁切换。
-
执行命令 display vrrp verbose 查看 VRRP 的参数设置,检查是否在 VRRP 组中启用了监视端口的功能。
-
如果 VRRP 主备角色频繁抢占是由于接口频繁振荡或网络拥塞导致的,可以把VRRP 设置为非抢占模式,或者配置VRRP的抢占延迟
-
VRRP 的抢占延迟是指当触发了VRRP抢占的条件后,不会立即抢占,而会等待一个延迟时间后,再抢占,以防角色频繁切换导致的网络不稳定
VRRP 中 Backup 设备抢占 Master后流量怎样自动的切换?
-
VRRP 的主备角色发生抢占后,会发送免费 ARP 报文来通告虚拟 MAC 地址的变化使流量切换到新的 Master 设备
VRRP 优先级能不能配置为 0有什么用
-
VRRP 优先级的可配置范围是1-254,优先级0在系统中有特殊用途。当 Master设备的接口 Shutdown 后将立即发送优先级为0的通告,告诉其他路由器,自己不参与 VRRP 选举了,让出 Master 的角色;当 Backup 设备收到优先级为0,的 VRRP 报文后,将立即启动一个不足1秒的计时器,等待新的 Master 设备发出的 VRRP 报文,有效阻止所有 Backup 不必要的频繁切换
mstp 和 vrrp 一起使用有什么注意事项
-
保持 mstp 域的一致性。在同一个mstp 域内,所有的交换机应该使用相同的域名、版本号、实例和 vlan 映射。如果域内的交换机配置不一致,会导致生成树的计算错误或者无法收敛
-
合理规划mstp实例和 vrrp 备份组。为了实现流量的负载分担和冗余备份,应该将不同的vlan 映射到不同的 而stp 实例,并且将不同的 mstp 实例对应到不同的 vrrp备份组。例如,vlan10 映射到 mstp 实例 1vlan20 映射到 mstp 实例2,这样,可以使得不同的van 走不向的链路和网关,提高网络性能和可靠性;
-
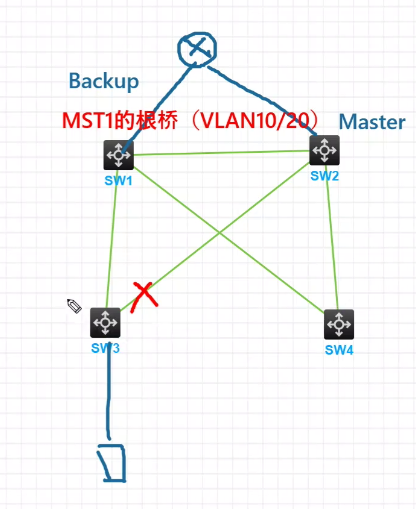
-
实例的根桥角色和VRRP的Master设备要在同一台设备,避免次优
-
-
配置端口优先级和路径开销。为了控制生成树的形状和阻塞端口的选择,可以在各个交换机上配置端口优先级和路径开销。端口优先级用来决定在同一段链路上,哪个端口成为指定端口,哪个端口被阻塞。路径开销用来决定数据包从源到目的地的最佳路径。一般来说,优先级越高,越容易成为指定端口;路径开销越小,越容易成为最佳路径。
-
置根保护和环路保护。为了防止生成树被恶意或者错误地修改,可以在各个交换机上配置根保护和环路保护功能。根保护用来防止非预期的根桥出现在网络中,如果一个端口收到了比当前根桥优先级更高的 BPDU,那么这个端口会进入根不一致状态,并停止转发数据包。环路保护用来防止由于双向链路故院而导致的环路产生,如果一个指定端口收到了来自同一个 mstp 实例的 BPDU那么这个端口会进入环路不一致状态,并停止转发数据包。
VRRP 的故障切换时间是多久,如何加快故障检测时间
-
VRRP 心跳报文默认 100 厘秒发送一次,当 Backup 设备在3个心跳报文周期加上 Skew_time 的时长都没有收到 Master 的心跳报文后,会切换为 MasterSkew_time=(256-Backup 设备优先级)/256 秒。
-
设计 Skew time 是考虑到如果有多个 Backup 设备的话,可以使每个 Backup设备的切换时间不一致,从而避免抢占冲突
-
加快故障检测时间可以使用 BFD 来实现
VRRPV2 和 VRRPV3 有什么区别
-
VRRPV2版本(RFC3768)只支持IPV4VRRP,使用 VRRPV2 时、备份组中的所有路由器必须配置相同的 VRRP 通告报文发送间隔
-
VRRPV3 版本(RFC5798)支持IPv4 VRRP 和 IPv6 VRRP
-
H3C Comware V7 设备缺省使用 VRRPV3 版本
-
VRRPV3 相对 VRRPv2 有较大的改动
-
VRRPV3 版本的 IPV4 VRRP 和 IPV6 VRRP 均不支持对 VRRP 报文进行认证
-
使用 VRRPV3 时,备份组中的路由器上配置的 VRRP 通告报文发送间隔可以不同,Master 路由器根据自身配置的报文发送间隔定时发送通告报文,并在通告报文中携带 Master 路由器上配置的发送间隔;
-
IPV4 VRRPV3 可以工作在负载均衡模式。版本2也支持
-
VRRPV2 会对虚 IP 是否与接口IP 同网段做检查,若实虚IP不在同一网段时 VRRP 组无法建立。而 VRRPV3 没有做该限制,视为配置错误,需要在配置时规避。
-
同时 VRRPV3 在日志输出这一块更为丰富,VRRPV3 出现故障可充分利用日志打印。
-
-
v2和v3的虚拟MAC是否一致?
-
一致
-
IRF 的技术原理和优势
-
IRF 是通过虚拟化技术把多台物理交换机虚拟成为一台逻辑交换机
-
IRF 的优势:
-
简化配置管理:形成 IRF后,所有成员设备的配置会自动同步成一致,所以只需配置一台即可,可以登录到统一的逻辑设备管理整个 IRF堆叠以及其内所有成员设备。
-
提高整体设备性能:IRF成员设备之间也不需要运行生成树协议,IRF形成的逻辑设备运行的各种控制协议也是作为单一设备运行,省去设备间大量协议报文的交互,缩短了收敛时间。
-
设备扩展简便:扩展新的设备只需要把新的交换机加入IRF即可,对原IRF结构无影响,可以实现新增的设备加入或离开 IRF 架构时可以实现“热插拔"不影响其他设备的正常运行
-
大幅提高设备可靠性:RF的高可靠性体现在链路、设备和协议三个方面
-
跨成员设备的链路聚合:IRF和上、下层设备之间的物理链路支持聚合功能,并且不同成员设备上的物理链路可以聚合成一个逻辑链路,多条物理链路之间可以互为备份也可以进行负载分担,当某个成员设备离开IRF,其它成员设备上的链路仍能收发报文,从而提高了聚合链路的可靠性。
-
1:N备份:IRF由多台成员设备组成,其中,主设备负责IRF的运行、管理和维护,从设备在作为备份的同时也可以处理业务。一旦主设备故障,系统会迅速自动选举新的主设备,以保证业务不中断,从而实现了设备的1:N备份。
-
-
消除逻辑环路,无需再运行住何防环的机制
-
IRF 形成堆叠的过程
-
IRF形成的过程
-
建立物理连接
-
拓扑收集:
-
与直接相邻的其他成员设备交互hello报文来收集整个网络拓扑关系,经过拓扑收敛所有设备收集到完整拓扑信息;
-
Hello报文携带拓扑信息,堆叠口连接关系,成员设备编号,成员设备优先级.成员设备的成员桥MAC地址等信息
-
-
选举 Master 设备:
-
选举失败的设备会自动重启,重启完成后成为Slave设备(重启同步Master配置)
-
-
堆叠维护:
-
进入到 IRF 维护阶段,周期发送 Hello 报文来维护 IRF
-
-
IRF建立的必要条件
-
物理堆叠口必须是万兆以上的接口
-
一台设备上最多2个逻辑堆叠口
-
一台设备的1号堆叠口必须连接到另一台设备的2号堆叠口
-
所有堆叠物理设备的操作系统版本必须一致
-
成员设备的 IRF Domain ID 要一致
IRF的 Master 角色选举规则有哪些
-
发生角色选举的情况:
-
IRF建立
-
主设备离开或者故障
-
IRF分裂
-
独立运行的两个(或者多个)IRF合并为一个IRF
-
-
1.当前主设备优先
-
在 IRF已经形成后,不会因为有新的成员设备加入而重新选举主设备。在IRF 形成时,因为没有主设备,所有加入的设备都认为自己是主设备,则继续下一条规则的比较。
-
选举后备设备会重启,为了防止原设备重启影响业务
-
-
2.优先级高的成为 Master
-
默认为1,如果优先级相同,则继续下一条规则的比较。
-
-
3.系统运行时间长的成为 Master
-
在 IRF 中,成员设备启动时间间隔精度为 10 分钟,即 10 分钟之内启动的设备,则认为它们是同时启动的,则继续下一条规则的比较。
-
运行时间长的业务上线可能比较多,重启的影响面比较大
-
-
4.CPU MAC地址小的成为 Master
-
相关 MAC 地址,可在设备上通过 display irf 命令进行查看
-
-
通过以上规则选出的最优成员设备即为主设备,其它成员设备则均为从设备
-
IRF建立时,所有从设备必须重启加入IRF
-
独立运行的IRF合并时,竞选失败方的所有成员设备必须重启加入获胜方
IRF 中主从设备角色有什么作用
-
主用设备(简称为主设备)Maste:负责管理和控制整个IRF;网络协议计算收敛;转发业务报文。
-
从属设备(简称为从设备 Standby):转发业务报文的同时作为主设备的备份设备运行。当主设备故障时,系统会自动从从设备中选举一个新的主设备接替原主设备工作。
-
主用设备和从属设备均由角色选举产生。一个IRF中同时只能存在一台主用设备,其它成员设备都是从属设备。
配置 IRF 时,如果 一端配置为 IRF port 是 1/1,对端应该配置成什么
-
IRF端口:一种专用于IRF成员设备之间进行连接的逻辑接口,每台成员设备上可以配置两个IRF端口,分别为IRF-Port1和IRF-Port2。它需要和物理端口绑定之后才能生效。
-
IRF端口编号规格:
-
在独立运行模式下,IRF端口采用一维编号,编号为IRF-Port1和IRF-Port2;
-
在IRF模式下,IRF端口采用二维编号,编号为IRF-Portn/1和IRF-Portn/2,其中n为设备的成员编号。
-
-
IRF要求一台设备的1号堆叠口必须连接到另一台设备的2号堆叠口。所以当一端的 IRF port 是 1/1,对端应该是 2/2。
-
前面的是设备ID,后面的堆叠口的逻辑编号
配置 IRF 的基本步骤
-
规划 IRF 的拓扑结构和 IRF 接口的互联情况
-
为成员设备分配唯一的设备 ID,并且保存重启生效
-
将要加入 IRF 的堆叠口关闭
-
将堆叠口关联到相应的 IRF 接口
-
将堆叠口激活
-
保存配置
-
将IRF配置激活
IRF DomainID 的作用和 Active ID 的作用
-
DomainID用于区分不同的IRF堆叠组,默认值为0,一个IRF 堆叠组内的所有成员设备的 DomainID 是需要一致的,IRF 使用 MAD 检测冲突时会检查报文的Domain lD
-
Active ID 指的是当前 Domain 中 Master设备的成员编号,即本域中 Master设备的成员编号,ActiveID也是 MAD 检测时一个重要的判断依据
-
Domain ID 和 Active lD 的判断依据
-
如果 Domain ID 不同,则属于不同的 IRF 域,不进行 MAD 处理
-
如果 DomainID 相同,并且ActiveID 也相同、则IRF 工作正常,未发生分裂
-
如果Domain亿 相同,但是 ActivelD 不同,则认为发生 IRF 分裂,需要进行MAD处理
-
IRF分裂检测-MAD四种检测机制
| 检测方式 | 优势 | 限制 | 适用组网 |
|---|---|---|---|
| LACP MAD | 检测速度快;利用现有聚合组网即可实现,无需占用额外接口 | 需要使用H3C设备(支持扩展LACP协议报文)作为中间设备 | IRF使用聚合链路和上行设备或下行设备连接 |
| BFD MAD | 检测速度较快;使用中间设备时,不要求中间设备必须为H3C设备 | 需要专用的物理链路和三层接口,这些接口不能再传输普通业务流量 | 对组网没有特殊要求;如果不使用中间设备仅适用于成员设备少,且物理距离较近的环境 |
| ARP MAD | 可以不使用中间设备;使用中间设备时,不要求中间设备必须为H3C设备;无需占用额外接口 | 检测速度慢于LACP MAD和BFD MAD;使用以太网端口实现ARP MAD时必须配合生成树 | 使用以太网实现ARP MAD时,适用于使用生成树,没有使用链路聚合的ipv4组网环境 |
| ND MAD | 可以不使用中间设备;使用中间设备时,不要求中间设备必须为H3C设备;无需占用额外接口 | 检测速度慢于LACP MAD和BFD MAD;使用以太网端口实现ND MAD时必须配合生成树 | 使用以太网端口实现ND MAD时,适用于使用生成树,没有使用链路聚合的ipv6组网环境 |
IRF堆叠分裂后会出现仟么情况,如何检测和解决?
-
IRF链路散障会导致一个 IRF 变成多个新的IRF。这些 IRF 拥有相同的 IP 地址等三层配置,会引起地址冲突,导致故障在网络中扩大。
-
为了提高系统的可用性当IRF分裂时我们就需要一种机制,能够检测出网络中同时存在多个 IRF,并进行相应的处理,尽量降低IRF分裂对业务的影响。一般通过 MAD 机制来实现。
-
多主检测 MAD:一种检测和处理堆叠分裂的协议,链路故障导致堆叠系统分裂后,MAD可以实现堆叠分裂的检测、冲突处理和故障恢复,降低堆叠分裂对业务的影响。
-
MAD 通常分为三种形式:ARP/ND MAD、BFD MAD、LACP MAD
-
ARP/ND MAD:
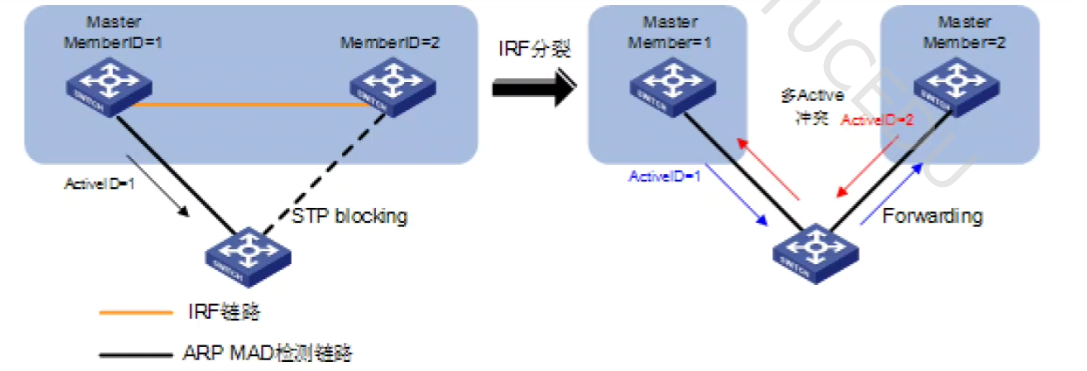
-
ARP MAD 是利用免费 ARP 报文来携带IRF的 Active ID,成员设备通过对比 ARP/ND 报文中的 DomainID(IRF 域编号)和 ActiveID(本域 Master 设备的成员编号),如果 Domain ID 和本机相同而 Active ID 不同,说明一个域中出现了多个 Master,则判断为IRF 分裂
-
ARP MAD 在配置时需要结合 STP 来完成,只需要配置置一个 SVI接口地址即可
-
检测到分裂后,会先比较IRF成员的健康值,健康状态好的继续工作(健隶值小的表示更优),如果健康值一致,则进一步比较IRF设备的成员 ID,会使 Master 成员编号最小的 IRF 处于 Active 状态继续正常工作,其他 IRF切换到 MAD Recovery 状态(将其他成员设备除了保留端口之外的其他所有物理接口关闭),自动关闭所有相关接口
-
同一个IRF中可以配置一个或多个检测机制。
-
-
什么情况发送分裂
-
堆叠线发生断裂
-
修复好会会恢复吗
-
-
堆叠线会不会参与数据的转发?
-
会,(都用万兆的线了)
-
MAD 检测到冲突之后,如何进行处理
-
IRF堆叠分裂后,通过分裂检测机制IRF会检测到网络中存在其它处于正常工作状态的 IRF,让正常工作状态的IRF设备承担业务流量转发。
-
对于 BFD MAD 和 LACP MAD 检测,冲突处理方式为:
-
比较两个 IRF 的健康状态,健康状态较好的 IRF 继续工作,其它IRF 迁移到Recovery 状态(即禁用状态)。IRF 的健康状态可以通过 display systemhealth 命令查看。(数值越小越优)
-
如果健康检查结果相同,则比较两个IRF 中成员设备的数量:数量多的IR继续正常工作,数量少的迁移到 Recovery状态(即禁用状态)。
-
如果成员数量相等,则主设备成员编号小的IRF 继续正常工作,其它 IRF迁移到 Recovery 状态。
-
-
对于 ARP MAD 和 ND MAD 检测,冲突处理方式为:
-
比较两个 IRF 的健康状态,健康状态较好的 IRF 继续工作,其它 IRF 迁移到Recovery 状态(即禁用状态)。IRF 的健康状态可以通过 display systemhealth 命令查看。
-
如果健康检查结果相同,则主设备成员编号小的IRF 继续工作,其它 IRF迁移到 Recovery 状态。
-
-
IRF 迁移到 Recovery 状态后会关闭该 IRF 中所有成员设备上除保留端口以外的其它所有物理端口(通常为业务接口),以保证该IRF不能再转发业务报文。保留端口可通过 mad exclude interface 命令配置。
-
IRF 链路修复后,系统会自动重启处于Recovery状态的IRF。
-
重启后,原 Recovey状态IRF中所有成员设备以从设备身份加入原正常工作状态的 IRF原 Recoveny 状态 IRF 中被强制关闭的业务接口会自动恢复到真实的物理状态整个IRF 系统恢复
BFD MAD 检测机制是如何实现的
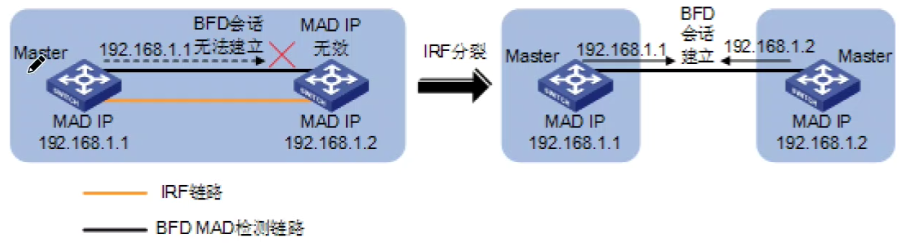
-
BFD MAD 检测是通过BFD 协议来实现的。要使 BFD MAD 检测功能正常运行除在三层接口下开启 BFD MAD 检测功能外,还需要在该接口上配置 MAD IP 地址。MAD IP地址与成员设备是绑定的,且所有成员设备的 MADIP 必须属于同一网段。
-
在配置 BFD MAD 检测时,需要禁用接口的 STP 功能。
-
避免把BFD端口阻塞
-
-
当IRF正常运行时,只有主设备上配置的 MAD IP地址生效,从设备上配置的MADIP地址不生效,BFD 会话处于 down 状态
-
如果只有两个设备的IRF 环境,可以无需使用中间设备,可以直接使用现有设备的互联链路作为 BFD MAD 检测,但是对于同时存在多个成员设备的 IRF 环境、依然需要使用中间设备,但是可以是任意的中间设备。
-
当 IRF 分裂时,同一个域中会出现多个 Master,同时会激活多个 Master 的 MADIP 地址、同时生效的 MAD IP 会导致 BFD 会话被激活,一旦 BFD 会话被激活则判断发生 IRF 分裂
-
检测到分裂后,MAD 的处理机制与 LACP MAD 类似,但是检测速度会略低于LACP 检测。
-
激活到建立时间长
-
LACP的发包频率高(1s和30s)
-
LACP MAD 检测机制是如何实现的
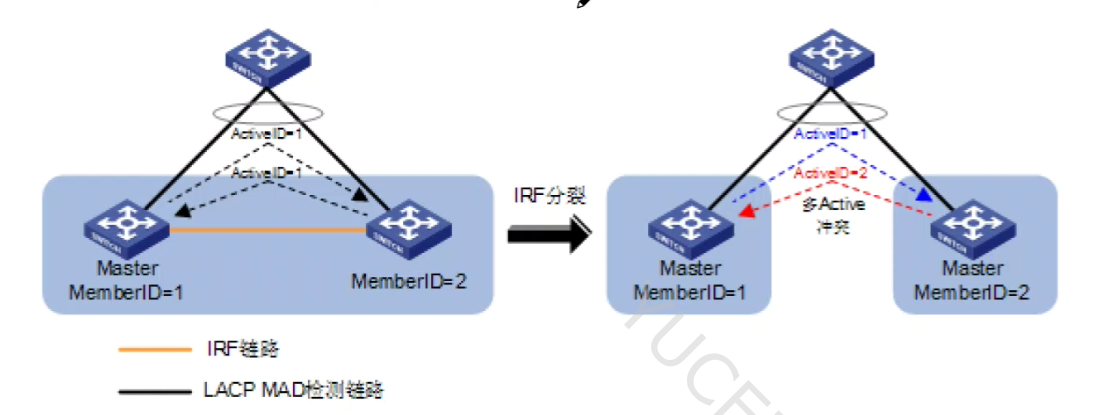
-
LACP MAD 检测是通过扩展 LACP 协议报文内容实现的,即在 LACP 协议报文的扩展字段内定义新的TLV 数据域,用于交互IRF的 Domain ID 和 Active ID.
-
使用 LACP MAD 功能时,要求 IRF 中的每台成员设备都与 H3C 的中间设备进行连接,并将这些链路组成一个动态链路聚合组,但是对于只有两个IRF成员设备的环境,则可以不用连接中间设备。
-
在配置时,可以使用现有的链路聚合组来进行 MAD 检测,配置简单,检测速度快
-
在 IRF 中开启 LACP MAD 功能后,各成员设备会在 LACP 协议报文的扩展字段中加入 IRF 的 Active ID。中间设备在收到带有扩展字段的 LACP 报文后,会将此报文向聚合组中的其他端口进行透传,使IRF中的所有成员设备都能收到其他成员设备发出的 LACP 报文。
-
检测设备连接到每一个IRF的成员设备,并配置动态链路聚合
-
当成员设备收到 LACP 协议报文后,先比较 Domain lD。如果 Domain ID 相同再比较 ActiveID;如果 Domain ID不同,则认为报文来自不同 IRF,不再进行MAD 处理。
-
如果 ActiveID 相同,则表示IRF正常运行,没有发生多 Active 冲突;如果 Acive值ID 值不同、则表示IRF 分裂,检测到多 Active 冲突。
-
检测到分裂后、先检查 IRF成员设备的健康状态,健康状态好的继续工作;在比较两个 IRF 中成员设备的数量,数量大的继续工作;最后比较 IRF成员的设备ID,设备ID号小的继续工作,其他IRF切换到 MAD Recovery 状态,自动关闭所有相关接口
-
因为 IRF 是华三私有的,LACP 检测是在 LACP 协议报文中插入华三私有的IRActive ID 字段,所以 LACP 的 MAD 检测只能使用华三的设备来实现,只有华三的设备才能识别私有的IRF ActivelD 信息。
-
IRF 堆叠正常运行时、MADstatus 状态处于 Normal 状态,IRF 堆叠分裂时,IRF处于 Recovery 状态的设备 MAD status 状态处于 Fauity 状态。
ARP/ND MAD 检测机制是如何实现的
-
ARP MAD 检测是通过扩展ARP 协议报文内容实现的。即使用ARP协议报文中未使用的字段来交互IRF的 Domain ID 和 Active lD
-
开启 ARP MAD 检测后,成员设备可以通过 ARP 协议报文和其它成员设备交互Domain lD 和 Active lD 信息。
-
当成员设备收到 ARP 协议报文后,先比较DomainID。如果 Domain ID相同,再比较 Active ID;如果 Domain 1D 不同,则认为报文来自不同IRF,不再进行 MAD 处理
-
如果 ActivelD 相同,则表示IRF 正常运行,没有发生多 Active 冲突;如果Active ID 值不同,则表示IRF分裂,检测到多 Active 冲突。
-
-
ARP/ND 方式和 LACP方式对组网拓扑存在要求,所以应用场景受到很大限制目前项目上主流采用的是 BFD 检测方式。但要注意一个细节就是用于 BFD 测的接口是需要关闭生成树功能的,因为会有冲突。
-
只有两台设备也可以
几种 MAD 检测机制的对比
| 检测方式 | 优势 | 限制 | 适用组网 |
|---|---|---|---|
| LACP MAD | 检测速度快;利用现有聚合组网即可实现,无需占用额外接口 | 需要使用H3C设备(支持扩展LACP协议报文)作为中间设备 | IRF使用聚合链路和上行设备或下行设备连接 |
| BFD MAD | 检测速度较快;使用中间设备时,不要求中间设备必须为H3C设备 | 需要专用的物理链路和三层接口,这些接口不能再传输普通业务流量 | 对组网没有特殊要求;如果不使用中间设备仅适用于成员设备少,且物理距离较近的环境 |
| ARP MAD | 可以不使用中间设备;使用中间设备时,不要求中间设备必须为H3C设备;无需占用额外接口 | 检测速度慢于LACP MAD和BFD MAD;使用以太网端口实现ARP MAD时必须配合生成树 | 使用以太网实现ARP MAD时,适用于使用生成树,没有使用链路聚合的ipv4组网环境 |
| ND MAD | 可以不使用中间设备;使用中间设备时,不要求中间设备必须为H3C设备;无需占用额外接口 | 检测速度慢于LACP MAD和BFD MAD;使用以太网端口实现ND MAD时必须配合生成树 | 使用以太网端口实现ND MAD时,适用于使用生成树,没有使用链路聚合的ipv6组网环境 |
-
为什么ARP的不需要华三设备呢?
-
ARP广播报文,交换机收到直接转发不用拆包
-
IRF 有哪些报文?
-
IRF-Hello 报文:通告本机的信息,收集整个IRF 的拓扑,维护IRF 的成员关系
-
堆叠中的每台设备都是通过与直接相邻的其它成员设备交互Hello 报文来收集整个堆叠的拓扑关系。Hello 报文携带拓扑信息,包括堆口连接关系、成员设备编号、成员设备优先级、成员设备的成员桥MAC地址等内容
-
当 IRF 分裂后,如果配置了 MAD,可能会使用到ÀRP、ND、BFD、LACP 的报文
IRF 如何进行升级
-
在进行 IRF 设备软件版本升级操作之前,必须进行一些准备操作,以确保设备状态正常,可以进行升级操作。
-
一般的升级步骤如下:
-
1)保存设备的配置并将配置导出进行备份,防止升级过程中所造成的配置丢失,最好要将配置导出到电脑上进行备份。
-
2)上传新镜像到主设备和备设备上,并指定为下一次启动所使用镜像,可以采用任意方式进行镜像上传。
-
3)关闭设备的 MAD 多主检测功能。主要为了防止之后拔掉堆叠线缆时设备检测到多主而自动关闭备设备所有接口。
-
4)将主设备除了堆叠口以外的所有端口 shutdown,测试业务是否正确切换至备设备,在此过程中可能会导致业务产生短暂的中断。
-
5)保存设备配置,重启主设备进行主设备升级,断开堆叠链路使其堆叠分裂,保证主设备在重启之后端口状态依然会处于关闭状态,并与备设备处于不同的堆叠组中。注意,需要使用reboot sot1 来重启主设备。
-
测试主设备已升级完成并能正常工作。
-
7)先将备设备所有接口shutdown,再将主设备所有接口 no shutdown 来使所有流量切换至主设备,并测试业务是否正常。在此过程中可能会导致业务产生短暂的终端,大约一分钟以内。
-
8)重启备设备进行备设备升级,并在备设备重启时连接IRF线缆,备设备不需要保存 shutdown 接口的配置,实现重启完成后接口直接处于 up 状态进行数据的转发,并且能自动与主设备进行堆叠的建立。注意,需要使用reboot slot2 来重启主设备。
-
9)备设备启动完成后测试备设备是否正常运行,堆叠是否成功建立。
-
10)配置 MAD 多主检测,保存配置,升级完成。
-
Domain ID 不配置会有什么后果?
-
Domain ID 用于标识RF设备属于哪一个堆叠组,一般用于分裂检测,所以如果不配置的话,默认 DomainiD 为0,会导致多个IRF域无法区分
IRF的缺点
-
IRF 由于是把设备进行强耦合,要求成员设备的系统版本必须一致,所以当系统升级时一定会造成流量的中断
-
兼容性差
-
配置比较复杂
MDC 虚拟化是什么
-
MDC 类似子IRF的反向操作,是把一台物理设备虚拟成多台逻辑设备来使用是一种 1:N 的虚拟化模式。
IRF 如果有新的设备加入,怎么样使其对原有拓扑没有影响
-
新加入的设备如果本身已经配置好了IRF并已经作为IRF运行的话,加入后新老 IRF会进行竞选,竟选失败的作为Save 设备并自动重启。所以如果是老IRF 竞选失败,设备会自动重启,导致原有拓扑网络中断。
-
为了避免这种情况,一般建议新加入的设备配置好IRF后断电,再连接上老IRF之后再开机,这样的话新 IRF 会被选为 Slave,不会影响原有拓扑。
IRF有什么缺点
-
IRF 是华三私有协议,跟其他厂商无法兼容。
-
IRF 是高耦合的,要求同厂商、同型号以及同版本才可能形成链路聚合,兼容性差
-
IRF 的配置和管理比较复杂。
-
IRF 的系统升级比较繁琐,并且升级过程中会对业务的使用造成一定时间的中断
-
如果产生堆叠分裂的话,会影响网络故障范围扩大。
-
比较复杂的分裂检测机制。
-
要实现支持 IRF 系统的建立,对设备的硬件型号都有一定的要求,会增加网络的建设成本。
如果没有华三设备,在堆叠设备间直接连接链路可以做LACP 检测吗
-
可以
IRF如何进行堆叠的维护
-
堆叠维护的主要功能是监控成员设备的加入和离开,并随时收集新的拓扑,维护堆叠的正常工作。堆叠维护过程中,继续进行拓扑收集工作,当发现有新的成员设备加入时会根据新加入设备的状态采取不同的处理:
-
发现新加入设备
-
新加入的设备本身未形成堆叠,则该设备会被选为 Standby
-
加入的设备本身已经形成了堆叠,此时相当于两个堆叠合并(Merge)。在这种情况下,两个堆叠会进行堆叠竟选,竟选失败的一方所有堆叠成员设备需要重启,然后全部作为 Standby 设备加入竞选获胜的一方。
-
-
设备离开
-
堆叠维护过程中,判断成员设备是否离开:
-
正常情况下,直接相邻的成员设备之间会定期(通常一个周期为 200ms)交换 Hello 报文。如果持续多个周期(通常为10个周期)未收到直接邻居的 Hello 报文,则认为该成员设备已经离开堆叠系统,堆叠会将该成员设备从拓扑中隔离出来。
-
如果发现堆叠口 Down,则拥有该堆叠口的成员设备会紧急广播通知堆叠中其它成员,立即重新计算当前拓扑,而不用等到 Hello 报文超时再处理。
-
-
成员设备离开如果离开的是 Standby 设备,则系统仅仅相当于失去一个备用主控板以及此板上的接口等物理资源。如果离开的是 Master 设备,则堆叠系统会重新进行选举,选举出的新Master 接管原有 Master 的所有功能。
-
IRF 堆叠的物理拓扑有哪些类型
-
链形拓扑:使用堆叠电缆将一台设备的左堆叠口(右堆叠口)和另一台设备的右堆叠口(左堆叠口)连接起来,依次类推,第一台设备的右堆叠口(左堆口)和最后一台设备的左堆叠口(右堆叠口)没有连接堆叠电缆。这种连接方式也称为链形连接。
-
环形拓扑:将链形拓扑第一台设备的右堆叠口(左堆叠口)和最后一台设备的左堆叠口(右堆叠口)连接起来。这种连接方式也称为环形连接。
-
环形拓扑比链形拓扑更可靠,当环形拓扑中出现一条链路故障时,堆叠系统仍能够保持正常工作;当链形拓扑中出现一条链路故障时,会引起堆叠分裂
BFD 有什么作用
-
BFD(双向转发检测)
-
通用的,标准化的,介质无关的,协议无关的快速故障检测机制
-
通过在建立会话的通道上周期性发送检测报文,如果某个系统在足够长的时间未收到对端的检测报文,则认为在这条相邻系统的双向通道的某个部分发生了故障
-
保证设备之间能够快速检测到通信故障,以便能够及时采取措施、保证业务持续运行。
-
BFD 可以为各种上层协议(如路由协议)快速检测两台设备间双向转发路径的故障。上层协议通常采用 Hello 报文机制检测故障,所需时间为秒级,而 BFD可以提供毫秒级检测。
BFD 的检测模式有哪些
-
BFD 可以用来进行单跳和多跳检测
-
单跳检测:是指对两个直连设备进行IP 连通性检测,这里所说的"单跳"是IP 的一跳。
-
多跳检测:BFD 可以检测两个设备间任意路径的链路情况,这些路径可能跨越很多跳。
-
BFD 的 echo 报文和 control 报文有什么区别
-
BFD会话通过echo报文或控制报文实现,BFD报文为UDP报文
-
echo报文
-
封装在UDP中传送,目的端口号3785
-
本端发送echo报文建立BFD会话,对链路进行检测,对端不需要建立BFD会话,只需要把收到的echo报文转发回本端;
-
如果在检测时间内没有收到对端转发回的echo报文,则认为会话down
-
仅在隧道中支持多跳检测,其他应用中只支持单跳检测
-
-
控制报文
-
封装在UDP中传送
-
单跳检测目的端口号3784
-
多跳检测目的端口号4784
-
-
链路两端通过周期性发送控制报文建立BFD会话,对链路进行检测
-
BFD控制报文结构
-
Sta:0-AdminDown;1-Down;2-Init;3-UP
-
-
二层技术和三层技术有哪些可以提高网络的可靠性
-
在二层技术中主要用 STP、Smart-Link、链路聚合、IRF 和 M-LAG 提高网络的可靠性、链路聚合有二层链路结合和三层链路聚合,链路聚合也可以用于三层中提高网络的可靠性
-
在三层技术中主要有 VRRP、BFD 以及路由协议的冗余等来提高网络的可靠性

















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









