




 本文详细介绍如何使用PyTorch从零开始实现YOLOv3目标检测器,涵盖配置文件解析、网络构建及关键层的功能解析,如Convolutional、Upsample、Route和Shortcut层,以及BatchNormalization和YOLO检测层的工作原理。
本文详细介绍如何使用PyTorch从零开始实现YOLOv3目标检测器,涵盖配置文件解析、网络构建及关键层的功能解析,如Convolutional、Upsample、Route和Shortcut层,以及BatchNormalization和YOLO检测层的工作原理。
文章目录
这个笔记,主要是学习 YOLO 入门教程《How to implement a YOLO (v3) object detector from scratch in PyTorch》的笔记,其中包含自己学习过程中遇到的不懂之处的记录,其中一些英文单词并没有翻译,考虑到因为语言的差异,中文很难表达地很形象。与大家分享,以交流共勉。
笔记也会分为5个部分,层层递进,使用 PyTorch实现 YOLO (v3)。 完整的内容可参考原教程,在这里对教程的作者表示感谢。
这一部分介绍如何使用 YOLO,并从头使用 PyTorch 完成 YOLO 网络的搭建。
Getting Start
新建一个文件夹,用于存放 YOLO 代码。新建 darknet.py 和 util.py 文件,分别用于存放 YOLO 网络的架构代码 和 各种helper函数的代码。
Conifguration File 配置文件
在YOLO的官方代码(C实现)中,使用了配置文件来建立网络,这个cfg文件逐块描述网络布局。我们也使用这个官方配置文件来建立网络,下载 这个 cfg 文件,并放到 一个名字为 cfg 的文件夹中
mkdir cfg
cd cfg
wget https://raw.githubusercontent.com/pjreddie/darknet/master/cfg/yolov3.cfg
这个 cfg 文件的内容形式如下:
[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
shortcut layer 代表 skip connection, 如同 ResNet中那样。YOLO 中使用了5中不同的网络层:
-
卷积层(convolutional)
[convolutional] batch_normalize=1 filters=64 size=3 stride=1 pad=1 activation=leaky -
shortcut 层:代表 skip connection, 如上面的 from = -3 代表 这个 shortcut层的输出是 前一层 和向后数第三个层 的feature map 的叠加。
-
unsample:使用stride=k 对上一层进行双线性插值上采样
-
route:route层由一个 layers 参数,可以是一个值也可以是两个值。当只有一个值时,这个route层就会返回向后的第value个层的feature map。如 layers=-4, 该层就返回向后数第4层的feature map。
如果layers 有两个参数,那么就返回这两个值对应的网络层的feature map的连接值(concatenate)。如 layers=-1, 61,该route层就会返回前一层和第61层的feature map 在深度维度(depth dimension)concatenate的结果。
[route] layers = -4 [route] layers = -1, 61 -
yolo层:yolo层为检测层(detection layer)。下面的例子中,参数mask 用来指定将会使用的anchor的索引,所有的anchor会被参数 anchors描述;anchors 描述了9个anchor,但仅使用了由 mask 标记索引的anchor;
[yolo] mask = 0,1,2 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 classes=80 num=9 jitter=.3 ignore_thresh = .5 truth_thresh = 1 random=1
Net
在cfg 文件中,还有一种 net 的块,它用来描述有关网络输入和训练参数的信息,这在 YOLO 的前向传播时不会使用。
[net]
# Testing
batch=1
subdivisions=1
# Training
# batch=64
# subdivisions=16
width= 320
height = 320
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
引入要用到的模块
from __future__ import division
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import numpy as np
Parsing the configuration file 解析配置文件
解析配置文件的思路是 我们将cfg 文件中的每个 block(代表不同的网络层)保存为一个字典,block中的参数和值对应字典中的键值对。
def parse_cfg(cfgfile):
"""
Takes a configuration file
Returns a list of blocks. Each blocks describes a block in the neural
network to be built. Block is represented as a dictionary in the list
"""
file = open(cfgfile, 'r')
lines = file.read().split('\n') # store the lines in a list
lines = [x for x in lines if len(x) > 0] # get read of the empty lines
lines = [x for x in lines if x[0] != '#'] # get rid of comments
lines = [x.rstrip().lstrip() for x in lines] # get rid of fringe whitespaces
block = {}
blocks = []
for line in lines:
if line[0] == "[": # This marks the start of a new block
if len(block) != 0: # If block is not empty, implies it is storing values of previous block.
blocks.append(block) # add it the blocks list
block = {} # re-init the block
block["type"] = line[1:-1].rstrip()
else:
key,value = line.split("=")
block[key.rstrip()] = value.lstrip()
blocks.append(block)
return blocks
创建网络
def create_modules(blocks):
net_info = blocks[0] #Captures the information about the input and pre-processing
module_list = nn.ModuleList()
prev_filters = 3
output_filters = []
for index, x in enumerate(blocks[1:]):
module = nn.Sequential()
#check the type of block
#create a new module for the block
#append to module_list
先写 convolutional 和 upsample 层:
if (x["type"] == "convolutional"):
#Get the info about the layer
activation = x["activation"]
try:
batch_normalize = int(x["batch_normalize"])
bias = False
except:
batch_normalize = 0
bias = True
filters = int(x["filters"])
padding = int(x["pad"])
kernel_size = int(x["size"])
stride = int(x["stride"])
if padding:
pad = (kernel_size - 1) // 2
else:
pad = 0
# Add the convolutional layer
conv = nn.Conv2d(prev_filters, filters, kernel_size, stride, pad, bias=bias)
module.add_module("conv_{0}".format(index), conv)
# Add the Batch Norm Layer
if batch_normalize:
bn = nn.BatchNorm2d(filters)
module.add_module("batch_norm_{0}".format(index), bn)
# Check the activation.
# It is either Linear or a Leaky ReLU for YOLO
if activation == "leaky":
activn = nn.LeakyReLU(0.1, inplace=True)
module.add_module("leaky_{0}".format(index), activn)
# If it's an upsampling layer
# We use Bilinear2dUpsampling
elif (x["type"] == "upsample"):
stride = int(x["stride"])
upsample = nn.Upsample(scale_factor=2, mode="bilinear")
module.add_module("upsample_{}".format(index), upsample)
再写 Route 和 Shortcut 层
#If it is a route layer
elif (x["type"] == "route"):
x["layers"] = x["layers"].split(',')
#Start of a route
start = int(x["layers"][0])
#end, if there exists one.
try:
end = int(x["layers"][1])
except:
end = 0
#Positive anotation
if start > 0:
start = start - index
if end > 0:
end = end - index
route = EmptyLayer()
module.add_module("route_{0}".format(index), route)
if end < 0:
filters = output_filters[index + start] + output_filters[index + end]
else:
filters= output_filters[index + start]
#shortcut corresponds to skip connection
elif x["type"] == "shortcut":
shortcut = EmptyLayer()
module.add_module("shortcut_{}".format(index), shortcut)
在上面的创建route 和 shortcut 层时,我们有一个新的类型的层,叫做 EmptyLayer,是一个空层
route = EmptyLayer()
定义如下
class EmptyLayer(nn.Module):
def __init__(self):
super(EmptyLayer, self).__init__()
那么我们为什么需要定义一个空层呢?
在PyTorch中,当我们定义一个新层时,我们将nn.Module子类化,并写入该层在nn.Module对象的forward函数中执行的操作。
为了设计一个 Route 层,我们将不得不构建一个nn.Module对象,该对象使用属性layers的值作为其成员进行初始化。然后,我们可以编写代码来连接/提出 forward 函数中的feature map。最后,我们在网络的forward 函数中执行该层。
但是鉴于串联代码(code of concatenation)相当简短(在特征映射上调用torch.cat),如上所述设计一个层将导致不必要的抽象,这只会增加冗余代码。 相反,我们可以做的是用虚拟层(dummy layer)代替建议的路由层(route layer),然后直接在代表隐藏层的nn.Module对象的forward函数中执行连接。 (如果没懂这句话的意思,建议阅读如何在PyTorch中使用nn.Module类)
位于路由层(route layer)前面的卷积层将其内核应用于前一层的(可能连接的)feature map。以下代码更新filters变量以保存路由层(route layer)输出的过滤器数。
if end < 0:
#If we are concatenating maps
filters = output_filters[index + start] + output_filters[index + end]
else:
filters= output_filters[index + start]
shortcut layer 也使用空图层,因为它还执行非常简单的操作(添加)。没有必要更新过滤器变量,因为它只是将前一层的要素图添加到后面的图层。
YOLO layer
#Yolo is the detection layer
elif x["type"] == "yolo":
mask = x["mask"].split(",")
mask = [int(x) for x in mask]
anchors = x["anchors"].split(",")
anchors = [int(a) for a in anchors]
anchors = [(anchors[i], anchors[i+1]) for i in range(0, len(anchors),2)]
anchors = [anchors[i] for i in mask]
detection = DetectionLayer(anchors)
module.add_module("Detection_{}".format(index), detection)
module_list.append(module)
prev_filters = filters
output_filters.append(filters)
return (net_info, module_list)
我们这里定义了一个 detection layer,它的实现代码为:
class DetectionLayer(nn.Module):
def __init__(self, anchors):
super(DetectionLayer, self).__init__()
self.anchors = anchors
测试代码
在文件 darknet.py文件的后面写入测试代码:
blocks = parse_cfg("cfg/yolov3.cfg")
print(create_modules(blocks))
补充知识
1. Upsample 上采样
upsampling的主要目的是放大图像,几乎都是采用内插值法,即在原有图像像素的基础上,在像素点值之间采用合适的插值算法插入新的元素。常用插值算法有:
-
线性插值:线性插值法是指使用连接两个已知量的直线来确定在这个两个已知量之间的一个未知量的值的方法。
假设已知两个坐标(x1,y1)和(x2,y2),那么线性插值方法得到的插值点是两个点连线上的某一点,这个点的位置由插值系数(从x1到x的距离与从x2到x的距离的比值)决定。
-
双线性插值:双线性插值是线性插值的扩展,它利用插值目标点四周的四个真实存在的点来共同决定插值目标点,其核心思想是在两个方向分别进行一次线性插值。
2. batch normalize 批量标准化
提出batch normalize的原因
机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。Internal Covariate Shift 问题就是说,在训练过程中,因为各层参数一直在变,所以每个隐层都会面临covariate shift的问题,也就是在训练过程中,隐层的输入分布一直是变来变去。
因为深层神经网络在做非线性变换前的激活输入值,随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致后向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因。
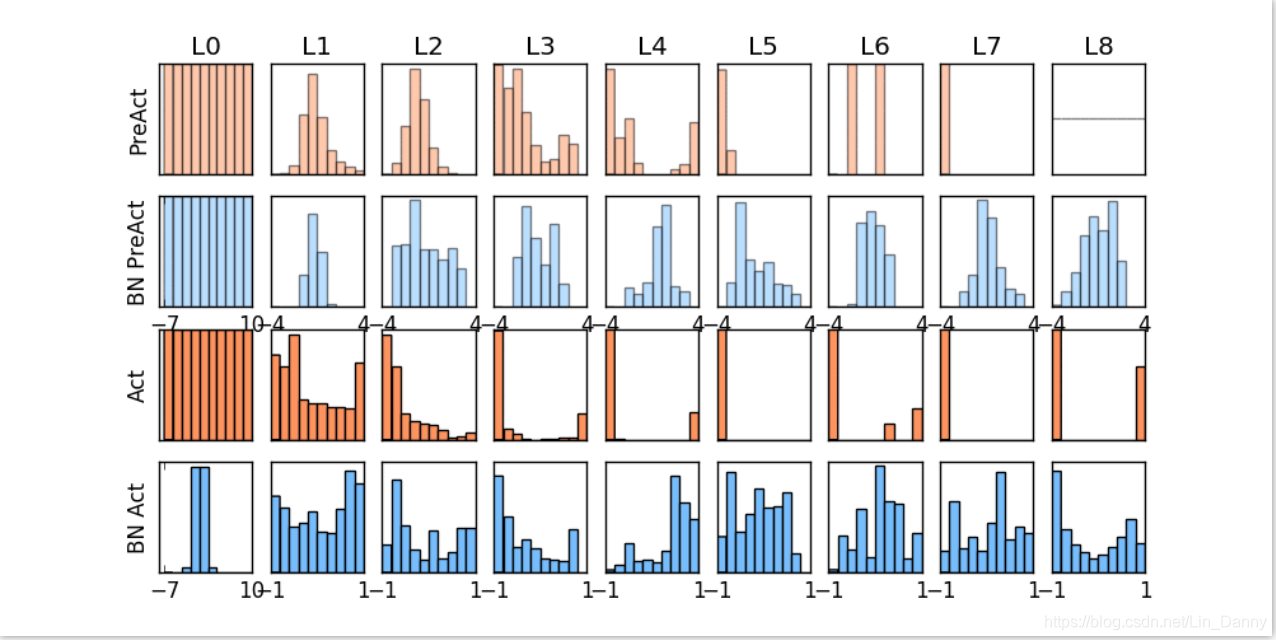
如上图所示,第一行是没有激活函数和BN的网络激活值,可以看出数值分布往两个极端走。加入激活函数之后(第三行)就限制在了激活函数的上下确界(梯度饱和区)。而加入BatchNorm之后,激活值往中间(激活函数敏感区)移动,从而有更大的梯度。
什么是 BN
即在每次SGD时,通过mini-batch来对相应的激活值(即 W X + b WX+b WX+b )做规范化操作,使得结果(输出信号各个维度)的均值为0,方差为1。
Batch Normalization的公式如下,其中
γ
,
β
\gamma, \beta
γ,β 是学习参数,
b
=
x
1
,
.
.
.
,
m
b={x_1, ... , m}
b=x1,...,m 是mini-batch 输入.
μ
b
=
1
m
∑
i
=
1
m
x
i
σ
b
2
=
1
m
∑
i
=
1
m
(
x
i
−
μ
b
)
2
x
^
i
=
x
i
−
μ
b
σ
b
2
+
ϵ
y
i
=
γ
x
^
i
+
β
≡
B
N
γ
,
β
(
x
i
)
\mu_b = \frac{1}{m} \sum_{i=1}^m x_i \\ \sigma^2 _b = \frac{1}{m} \sum_{i=1}^m (x_i - \mu_b)^2 \\ \hat{x}_i = \frac{x_i - \mu_b}{\sqrt{\sigma^2_b + \epsilon }} \\ y_i = \gamma \hat{x}_i + \beta \equiv BN_{\gamma, \beta}(x_i)
μb=m1i=1∑mxiσb2=m1i=1∑m(xi−μb)2x^i=σb2+ϵxi−μbyi=γx^i+β≡BNγ,β(xi)
最后的 y i = γ x ^ i + β ≡ B N γ , β ( x i ) y_i = \gamma \hat{x}_i + \beta \equiv BN_{\gamma, \beta}(x_i) yi=γx^i+β≡BNγ,β(xi) 称为 “scale and shift” 操作,其中 γ \gamma γ 称为 scale, β \beta β 称为 shift,这是为了让因训练所需而“刻意”加入的BN能够有可能还原最初的输入,从而保证整个network的capacity。(有关capacity的解释:实际上BN可以看作是在原模型上加入的“新操作”,这个新操作很大可能会改变某层原来的输入,而scale and shift 操作可以还原输入的分布,如此一来,既可以改变同时也可以保持原输入,那么模型的容纳能力(capacity)就提升了。)
BN的优势
Batch Normalization 可以使得深度神经网络的每一层输入都保持相同分布(高斯分布)。对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。因为梯度一直都能保持比较大的状态,所以很明显对神经网络的参数调整效率比较高,就是变动大,就是说向损失函数最优值迈动的步子大,也就是说收敛地快。
什么时候用 BN
在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
参考文章
初步理解 Batch Normalization
深度学习中 Batch Normalization为什么效果好?


















 738
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









