



 本文介绍了使用Pandas进行数据合并的方法,包括join和merge的区别,并通过实例展示了如何利用groupby进行数据分组及聚合操作,例如统计不同国家的星巴克门店数量。
本文介绍了使用Pandas进行数据合并的方法,包括join和merge的区别,并通过实例展示了如何利用groupby进行数据分组及聚合操作,例如统计不同国家的星巴克门店数量。
文章目录
数据合并之join
**join:**默认情况下他是把行索引相同的数据合并到一起

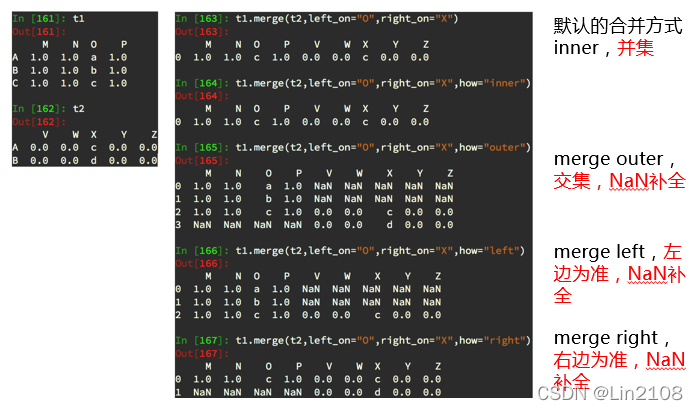
数据合并之merge
**merge:**按照指定的列把数据按照一定的方式合并到一起
#数据分组聚合01
#例1:统计美国的星巴克数量和中国的哪个多
import pandas as pd
import numpy as np
file_path="./starbucks_store_worldwide.csv"
df=pd.read_csv(file_path)
#print(df.head(1))
#print(df.info())
grouped = df.groupby(by="Country") #分组
# print(grouped)
#DataFrameGroupBy
#可以进行遍历
# for i,j in grouped:
# print(i)
# print("-"*100)
# print(j,type(j))
# print("*"*100)
# df[df["Country"]="US"]
#调用聚合方法
country_count=grouped["Brand"].count()
print(country_count["US"])
print(country_count["CN"])

















 2073
2073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









