







 超级会员免费看
超级会员免费看
 本文介绍了Embedding的概念、发展历史及其在大模型中的价值,通过OpenAI Embedding和知识问答实战展示了Embedding的使用。文章讨论了如何生成和存储Embedding,以及未来趋势,强调了其在解决大模型知识不足和输入限制问题中的作用。
本文介绍了Embedding的概念、发展历史及其在大模型中的价值,通过OpenAI Embedding和知识问答实战展示了Embedding的使用。文章讨论了如何生成和存储Embedding,以及未来趋势,强调了其在解决大模型知识不足和输入限制问题中的作用。
大模型基础:Embedding 实战本地知识问答
Embedding 概述
知识在计算机内的表示是人工智能的核心问题。从数据库、互联网到大模型时代,知识的储存方式也发生了变化。在数据库中,知识以结构化的数据形式储存在数据库中,需要机器语言(如SQL)才能调用这些信息。互联网时代,人们调用搜索引擎获取互联网上的非结构化的知识。而对于大语言模型而言,知识以参数的形式储存在模型中,通过自然语言的 Prompt 问答的方式就可以直接调用这些知识。
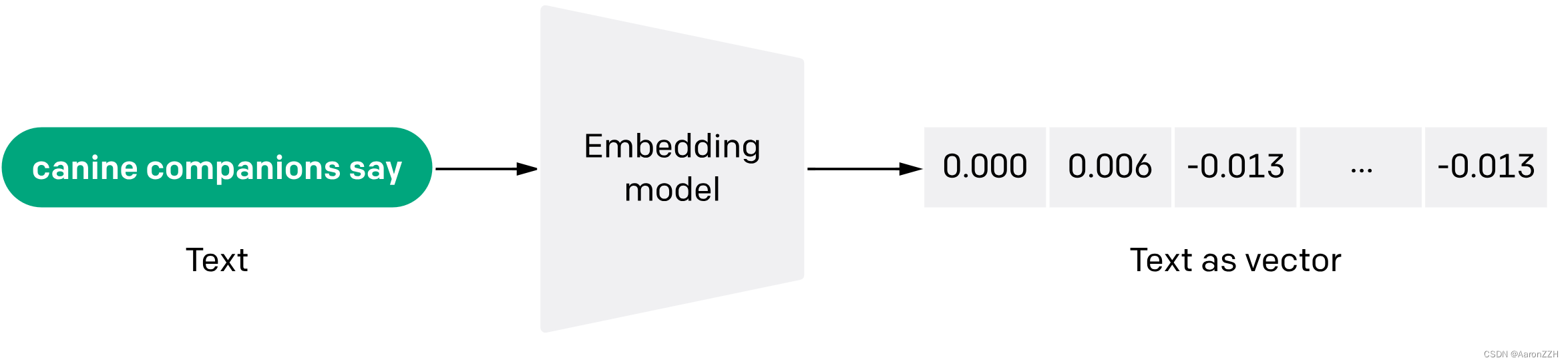
语言是离散的符合,自然语言的表示学习,就是将人类的语言表示成更易于计算机理解的方式,尤其在深度学习兴起后,如何在网络的输入层更好的进行自然语言表示,成了值得关注的问题。在机器学习中,embedding 是指将高维度的数据(例如文字、图片、音频)映射到低维度空间的过程。Embedding 可以将文本数据映射成一个数值向量形式,而且语义相近的词,在向量空间上具有相似的位置,从而方便计算机进行处理和分析。比如用 Cosine 距离计算相似度;句子中多个词的 Embedding

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1087
1087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











