






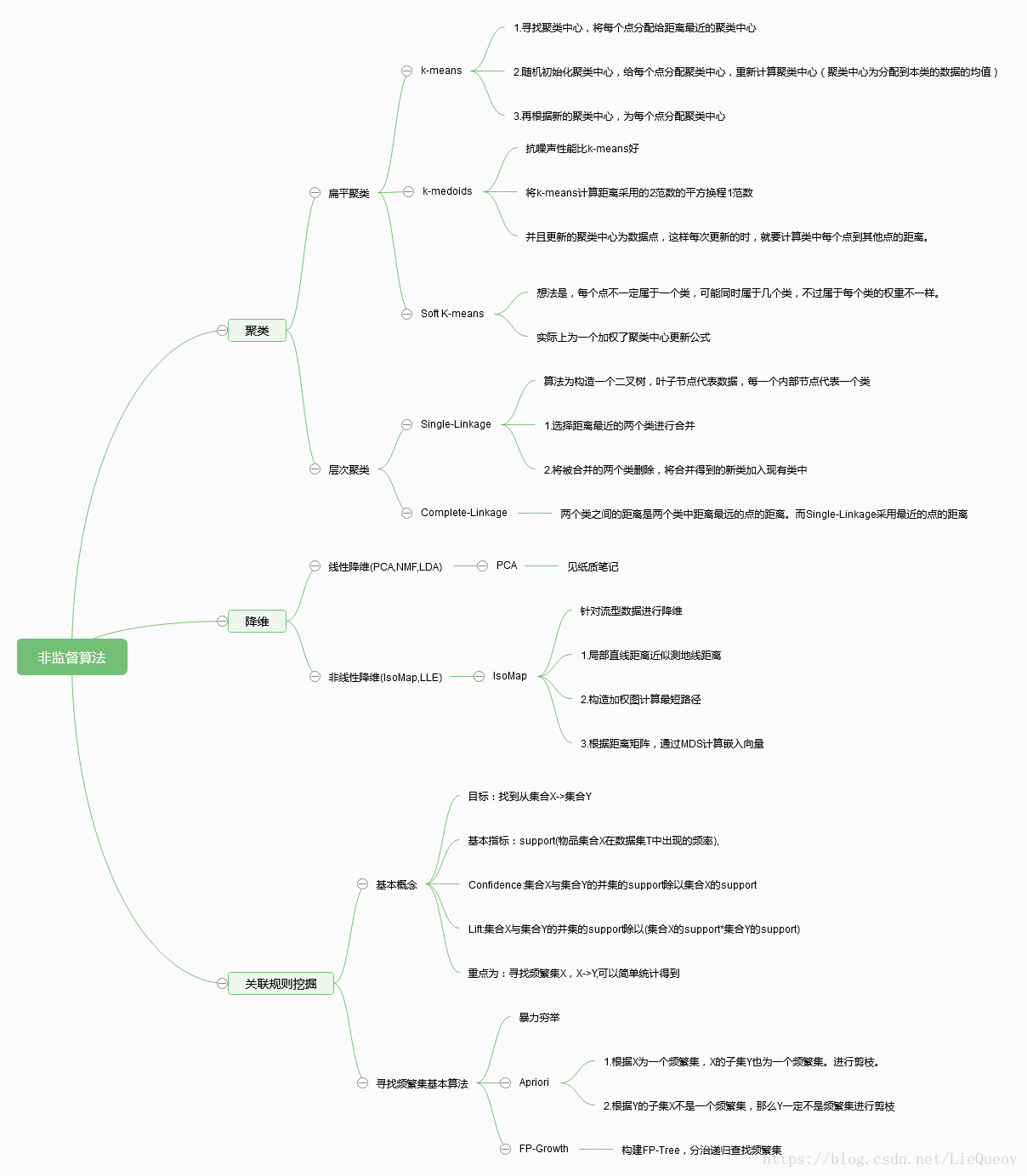
一、思维导图(点击图方法)
二、补充笔记


三、K-means算法的收敛性
说明:
- 当聚类中心μ确定时,求得的各个数据的cluster满足聚类目标函数最小。
- 当数据cluster确定时,求得的聚类中心μ满足聚类目标函数最小。
可以发现,k-means的两个步骤都是在降低聚类目标函数的函数值,并且聚类的目标函数的函数值的下界为0. 所以,可以k-means可以收敛。
 本文探讨了K-means算法的收敛特性。通过分析可知,当聚类中心确定时,算法能求得使聚类目标函数最小的数据簇;反之亦然。因每一步迭代都降低目标函数值且其下限为0,故K-means算法能够收敛。
本文探讨了K-means算法的收敛特性。通过分析可知,当聚类中心确定时,算法能求得使聚类目标函数最小的数据簇;反之亦然。因每一步迭代都降低目标函数值且其下限为0,故K-means算法能够收敛。
说明:
可以发现,k-means的两个步骤都是在降低聚类目标函数的函数值,并且聚类的目标函数的函数值的下界为0. 所以,可以k-means可以收敛。
 2087
797
744
3286
1158
1654
2087
797
744
3286
1158
1654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























