



一、RAG(检索增强生成)
RAG技术的基座是向量数据库。向量数据库不仅可以提供对向量化知识的存储,还支持高效的相似性检索,结合Prompt,可有效提升大模型回答的质量。
我们通过一个实例来理解RAG的大致工作原理,以一个智能聊天机器人为例:
假设您是车企高管,您希望为公司创建一个客户支持聊天机器人以回答用户,关于产品规格、故障排除、保修信息等方面的问题。用户提出了一个有关汽车中控显示屏出现故障的问题,客服机器人借助RAG技术准确回答了用户的问题——其原理是?
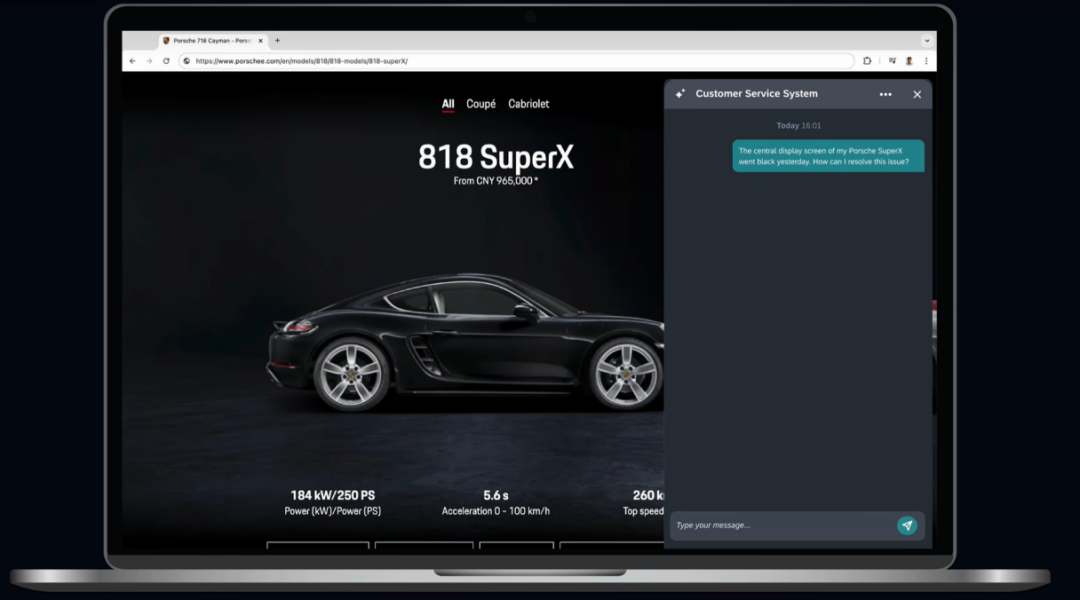
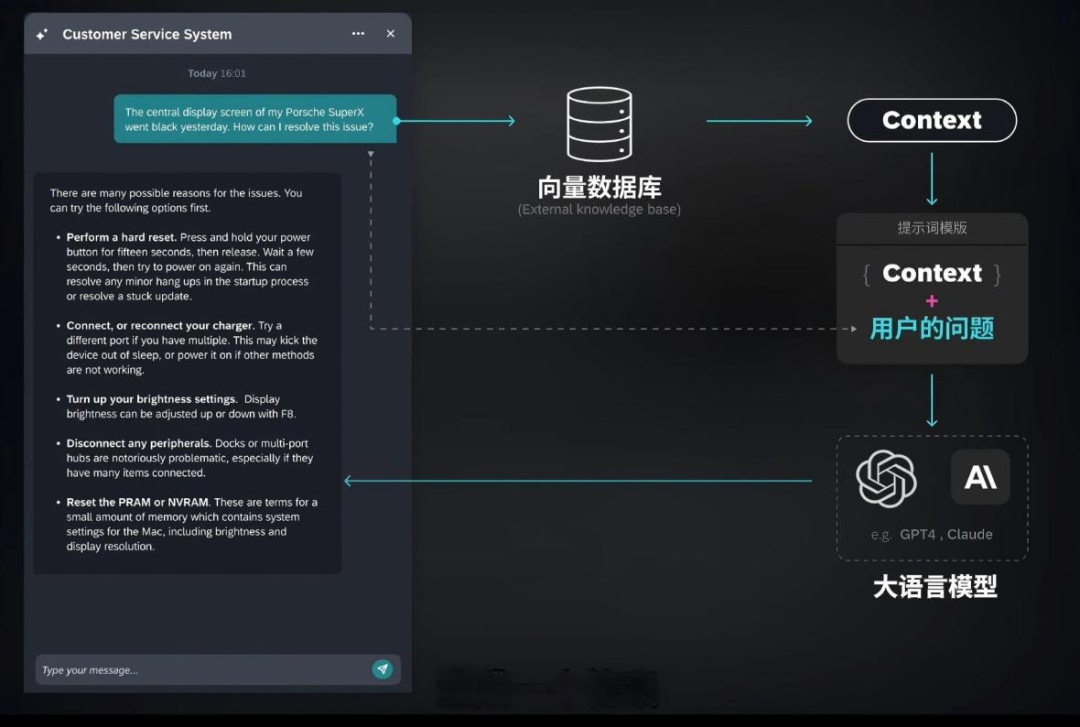
当用户提出问题时,系统先把用户问题转换成计算机能理解的向量。这就像把句子翻译成数学密码,方便后续搜索。随后在向量数据库中进相似性搜索,向量数据库中储存的是外部知识库信息,这些信息往往是大模型原生状态下无法知晓的。例如公司的内部产品信息、特定项目的专属资料等。
当系统检索出相关信息后,接着对这些关联信息进行精细排序,把最相关的排前头,然后对排好序的内容剪裁,组合成提示词,就像把找到的资料编排成参考资料包,大模型根据整理好的资料包,结合自身推理能力给出最终回答。
二、RAG流程
我们上面简述了RAG的基础工作原理,下面详细介绍RAG的工作流程,以下面流程图为例,我们把RAG简述为4个步骤。
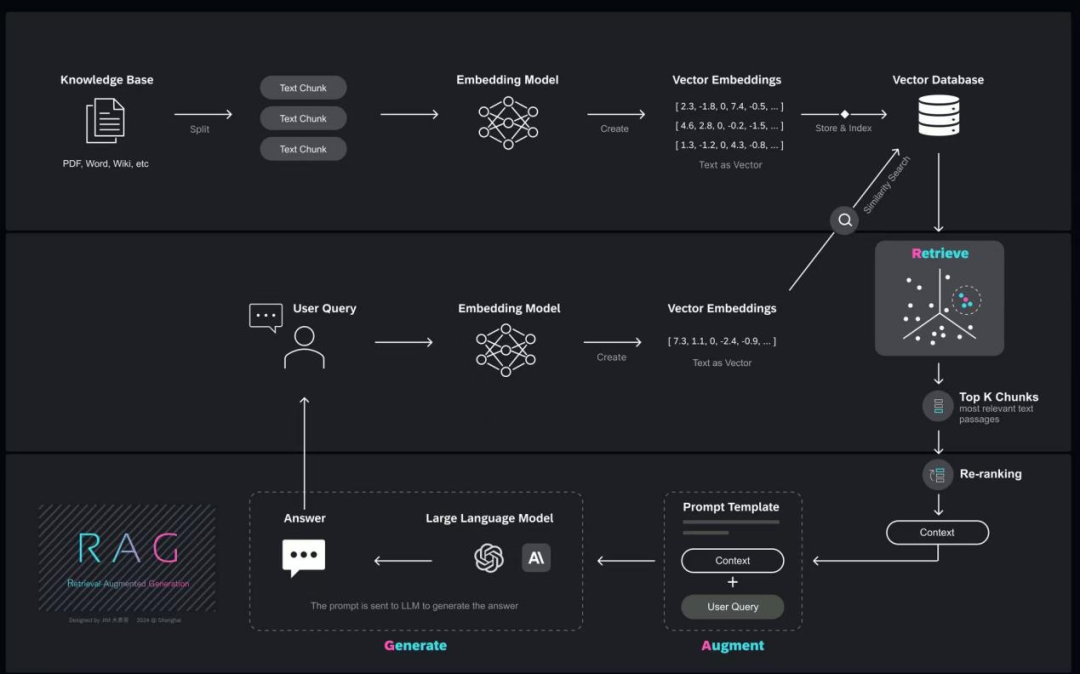
总体流程可分为四步;
● 构建外部知识库:对各类格式(如:PDF、Word等)的文档进行切片处理,将切片后的文本块(Text Chunk)利用嵌入模型转为嵌入向量,存储到向量数据库中。
● 检索(Retrieval): 将用户输入的问题利用嵌入模型转换为向量,到向量数据库中进行相似性搜索。
● 增强(Augment):把知识库中检索到的上下文“注入”提示词。
● 生成(Generation):大模型根据输入的上下文信息,生成连贯、准确且信息丰富的回答或文本。
下面针对以上步骤进行逐一拆解分析。
1、 构建外部知识库
在RAG流程中,对知识库文档进行分割是一个至关重要的步骤,文档分割的质量很大程度上影响了检索的准确性,将文本按照固定规则分割成“块”的过程,叫做切片。它能显著改善信息检索和内容生成效果,提供更精准、相关的结果。这些切片将交由**Embedding Model(嵌入模型)**转换为向量。
向量嵌入
向量嵌入是用一组数值表示的数据对象,在多维空间中捕捉文本、图像或音频的语义和关联,可以让机器学习算法能够更轻松地对其进行处理和解读。
比如:I love Tennis.我们先把I love Tennis.转换为几个token,再用Embeddings Model嵌入模型来生成embeddins。比如:单词I就转换为向量嵌入,所谓向量就是一个数字数组。其中每个数值表示对象在特定维度上的特征或属性,这就是I love Tennis.这句话的Vector Embeddings。

那么这些Embeddings可以用来干嘛?
因为向量嵌入能够以数值形式捕捉对象间的语义关系,所以我们可以通过向量搜索(也称为相似性搜索)。在向量空间中查找相似对象,这是一个查询向量(Query)。我们在向量空间中寻找与之距离最近的邻居,这些邻居便是与查询向量最相似的对象。
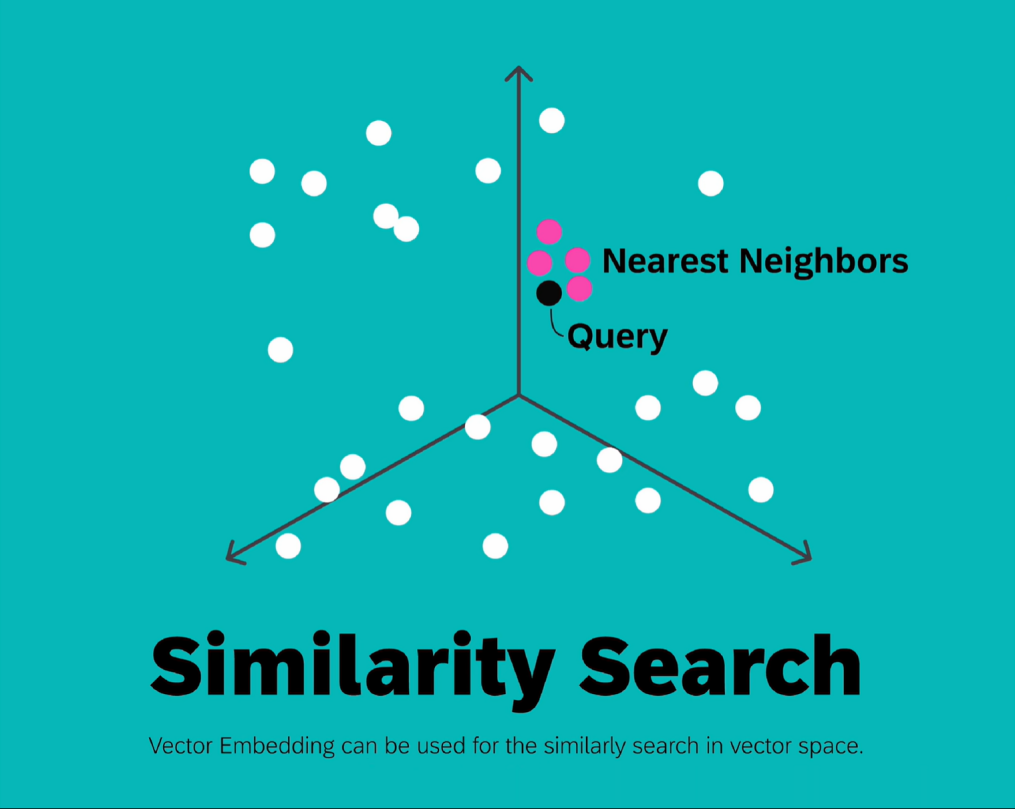
相似性搜索例子:
给定三个词Cat、kitty、Apple,将这三个词转换为向量,可以看到,语义相近的Cat、kitty向量值比较接近,而Apple与其他词值相差较大,体现在向量空间中,语义相近的对象距离更近。
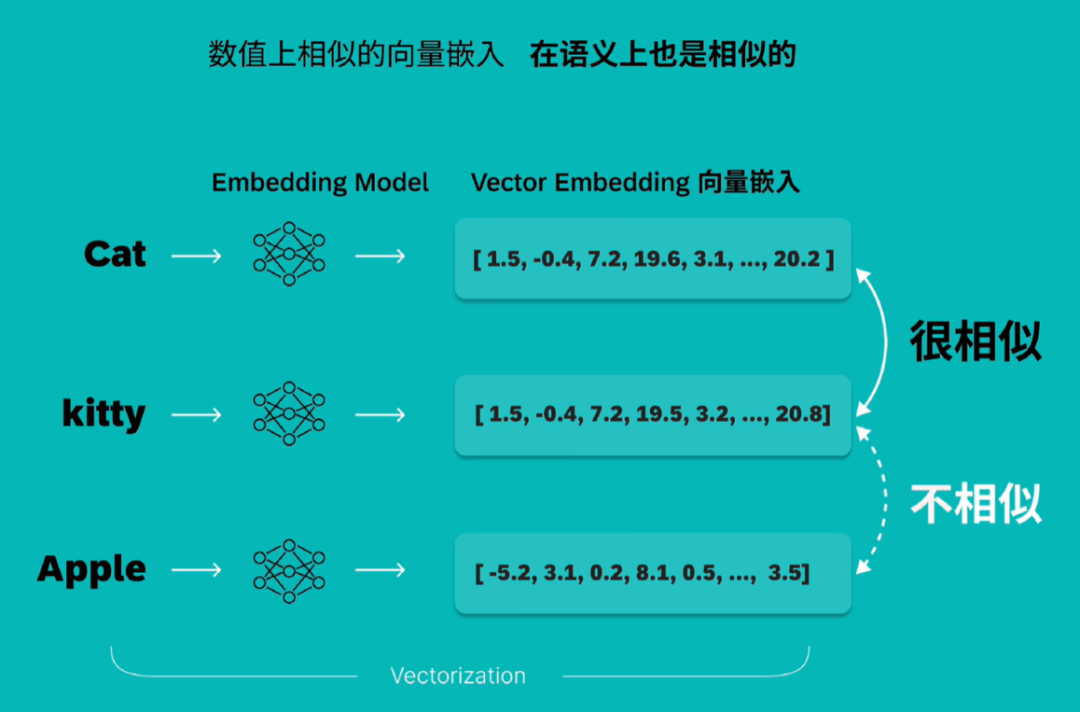
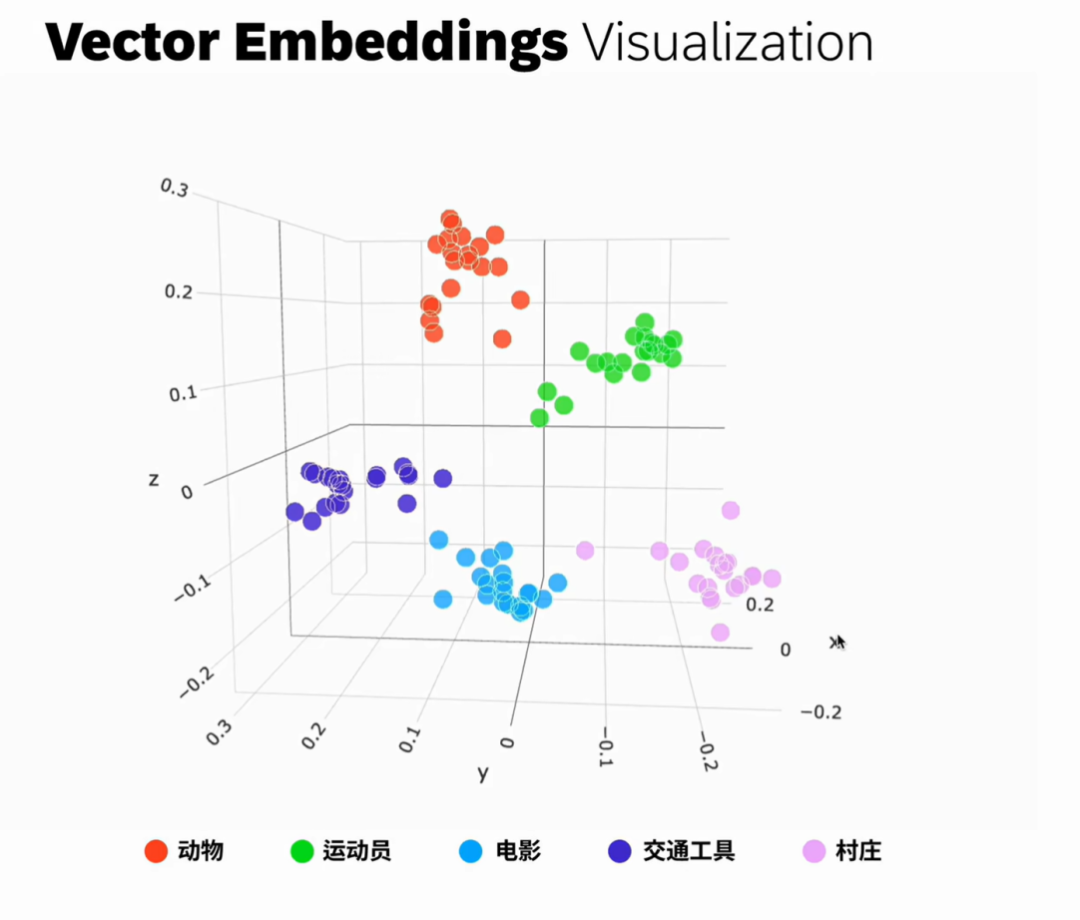
OpenAI三维可视化示例:
在向量空间中包含了动物、运动员、电影、交通工具、村庄等多个类别的向量,这些不同的类别在向量嵌入空间中形成了五个清晰的簇。相似的对象在向量空间中会靠的更近,而不相似的对象则会分散的更远。在这个例子中,与动物相关的数据点聚集在一起,与运动员相关的数据点也形成了一个独立的聚集区域,那么这些Embeddings存储在哪里呢?它们存储在向量数据库中。
什么是向量数据库?
向量数据库是一种专门用于存储和检索高维向量数据的数据库。它们主要用于处理与相似性搜索相关的任务。向量数据库能够存储海量的高维向量,这些向量可以表示数据对象的特征。
向量数据库可以作为AI系统的长期记忆库。向量存储在向量数据库中,这些向量主要是由非结构化数据通过嵌入模型(Embedings Model)转化而来的。非结构化数据,如文本、视频和音频,占全球数据的大约80%,它们通常来源于人类生成的内容,不易以预定义格式存储,这类数据可以通过转换为向量嵌入,有效地存储在向量数据库中。以便进行管理和检索而结构化数据则以表格形式存在,与非结构化数据形成对比,对于这些非结构化数据,可以基于语义相似度进行相似性搜索(Similarity Search)。
向量数据库和传统数据库有什么区别?
传统数据库主要用于存储结构化数据,数据通常以行和列的形式组织,适用于存储明确的数据类型,如整数、字符串、日期等。向量数据库专注于存储和检索高维向量数据,通常用于处理非结构化数据,如图像、文本和声音经过特征提取后的向量表示。向量数据库则重于相似性搜索,它通过语义理解来检索相关结果,不依赖精确匹配来检索相关搜索结果,对拼写错误和同义词有较好的包容性。而传统数据库通过精确匹配关键词来检索数据,适用于结构化数据的高效查询。
| 向量数据库 | 关系数据库 | |
|---|---|---|
| 数据类型 | 存储高维向量数据 | 结构化数据 |
| 查询方式 | 相似性搜索 | 精确匹配和范围查询 |
| 应用场景 | AI相关 | 管理系统等 |
| 代表数据库 | Milvus、Elasticsearch等 | MySQL、Oracle等 |
2、 检索(Retrieval)
检索本质上是在向量空间中寻找与查询向量最相似的邻居。这一过程,通过计算“查询向量”与数据库中其他向量之间的距离,找到距离最近的邻居,从而返回最相关的对象。
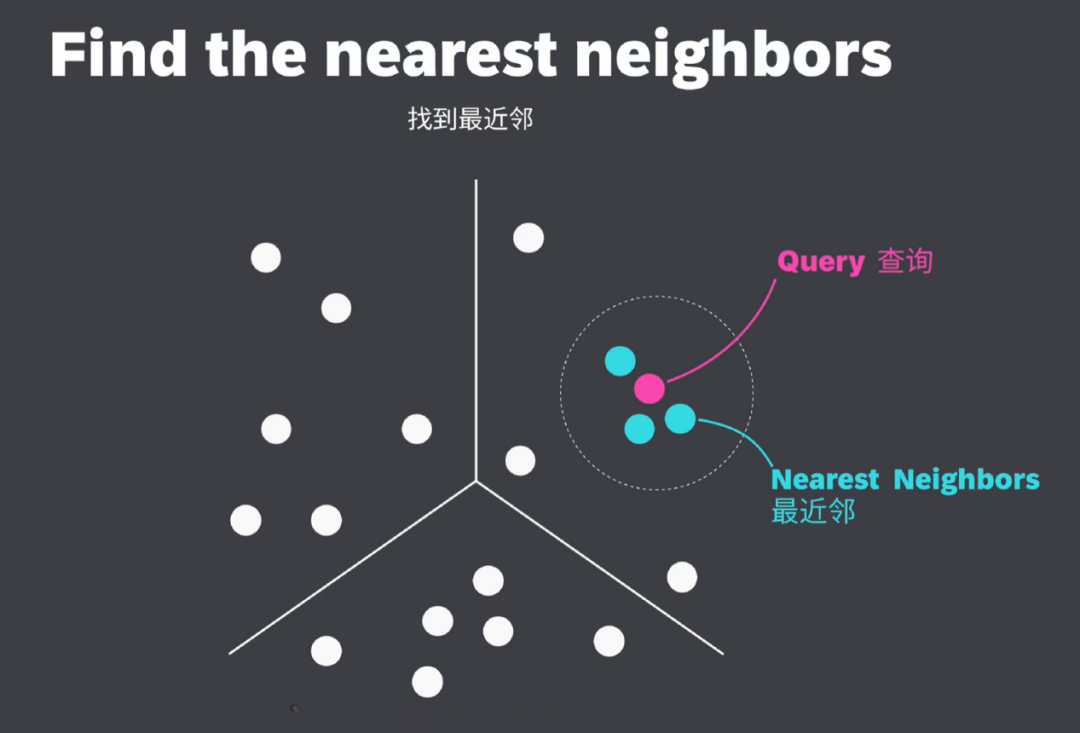
例子:
要找到与“Kitten”(幼猫)这个词相似的词,我们可以为这个查询词生成一个向量嵌入,也称为查询向量,并检索其所有最近邻。显然,它跟Cat和Dog靠的更近,离apple、banana等更远。
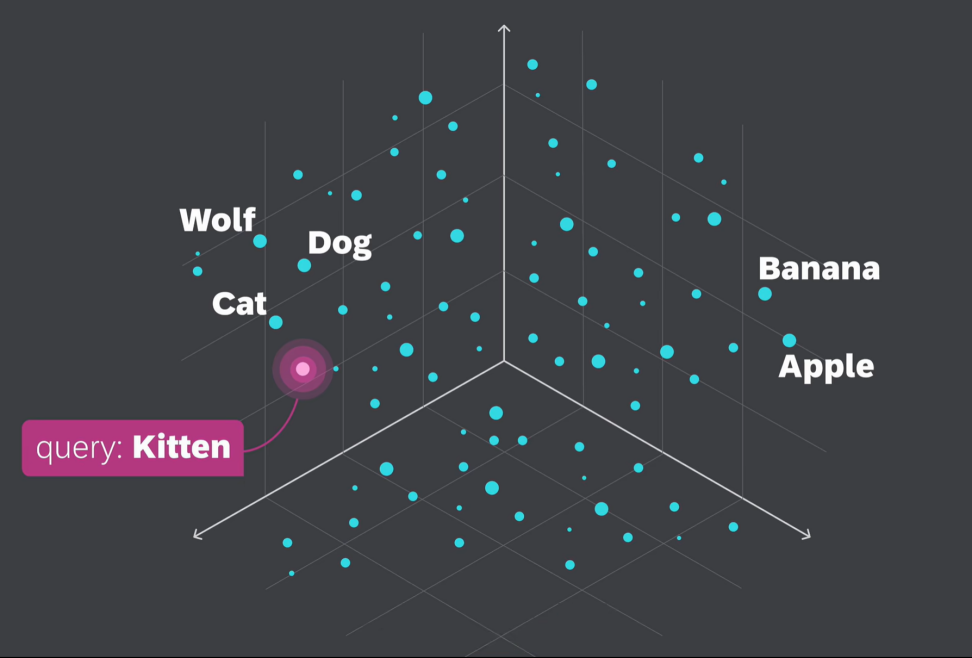
如何衡量向量嵌入的相似性?
怎样计算两个向量之间的距离来确定它们是否相似?
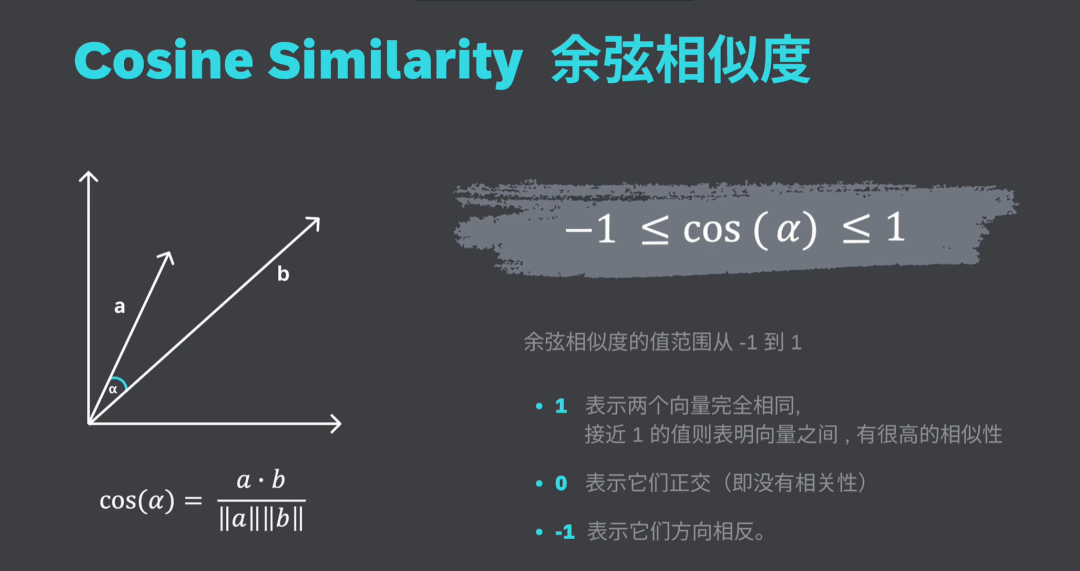
最常用的是余弦相似度
余弦相似度计算的是两个向量在多维空间中投影后夹角的余弦值,这一度量的优势在于,即使两份文档因为长度不同而在欧氏距离上相距甚远,它们之间的夹角可能仍然很小,从而具有较高的余弦相似度。
余弦相似度的值范围从-1到1,1表示两个向量完全相同,0表示它们正交(也就是没有相关性),-1表示它们方向相反,接近1的值,则表明向量之间有很高的相似性。
假设我们有“狼”、“狗”和“鸭子”的“向量嵌入”。“狗”和“狼”向量之间的夹角比“狗”和“鸭子”向量之间的夹角要小。如果我们计算狗和狼向量之间的余弦相似度,可能会得到一个较高的值(这个值接近1),因为它们是相似的。然而,狗和鸭子之间的余弦相似度可能会较低(这个值更接近0),因为它们代表的是具有不同特征的不同动物。

总结一下,夹角越小,余弦值越高,表示相似性越大!
3、增强
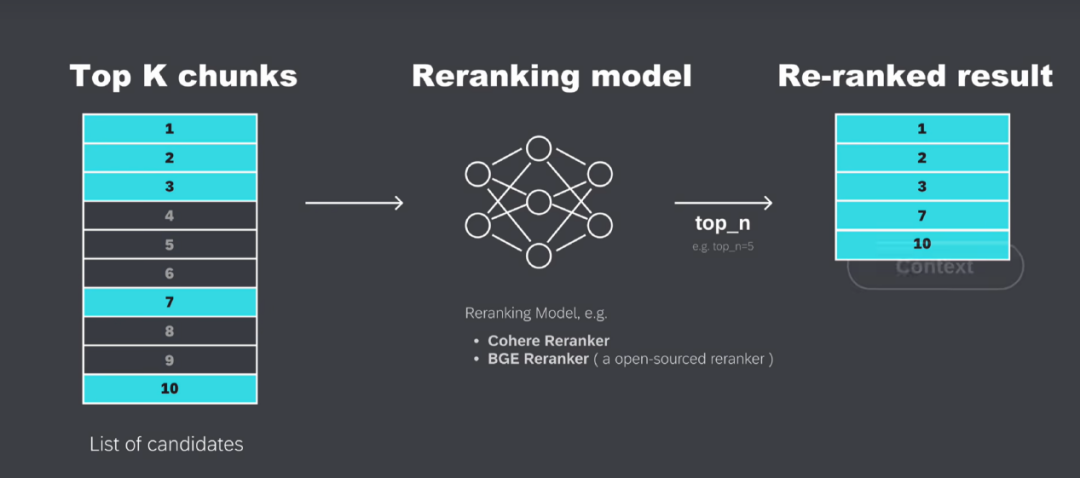
ReRanking(重新排序)
例如,系统从向量数据库中检索到了10个相关的候选文本块,但它们的初始排序可能并不是最优的,这10个文本块会被送入重排序模型(re-rangking model),重新进行排序,进而优化它们与用户查询的相关性适配程度。在已完成重新排序的文本块里,筛选出排名靠前的Top_N个文本。在这个例子中,原先排名第7和第10的文本块,经过重新排序后成功进入了TOP5,这些重新排序过的文本,之后将作为“上下文相关信息”(context)发送给大模型。
通过ReRanking系统可以更准确地挑选最合适的片段,从而提升整体响应质量。
4、生成(Generation)
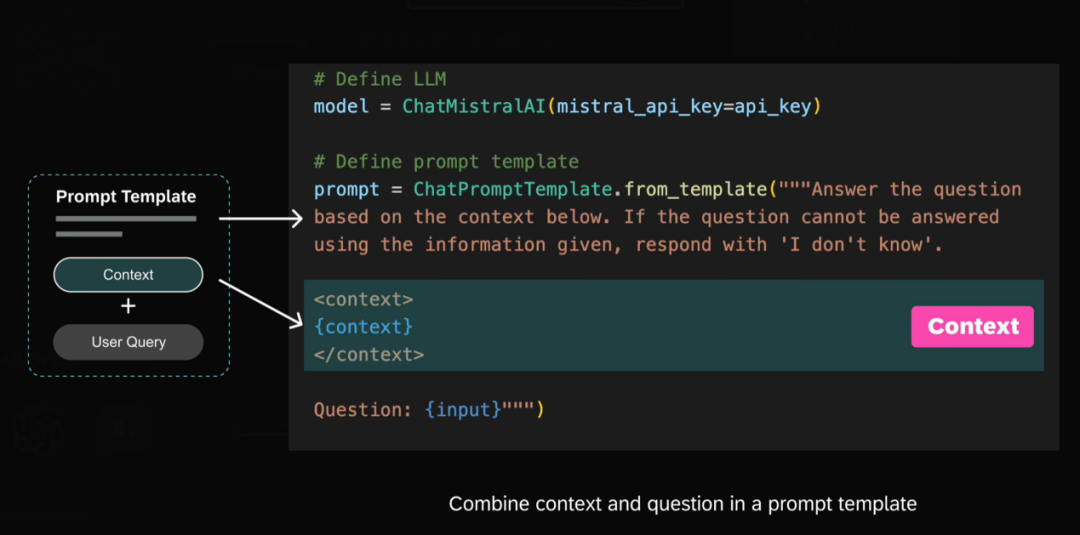
大模型根据提示词(Prompt)将前面检索到的知识作为上下文,生成回答。
提示词模版:
例如:“请参照知识库检索信息回答用户问题,如果没办法依据给出的信息来回答的话,请回复‘我不知道’”。知识库检索信息:{{context}}。
总结
RAG(检索增强生成) 的核心价值在于通过动态知识检索机制显著提升大模型生成质量,其核心优势体现在三个方面:首先,通过实时检索外部知识库为模型提供最新信息源,将生成结果锚定在事实性数据上,有效减少大模型的幻觉现象;其次,对比传统微调方案具备更强的经济性,能以不足20%的成本实现跨领域知识快速迁移;再者,支持即时的知识更新,省去重复训练的算力消耗。
向量化处理技术作为RAG的基石在其中发挥着关键作用:通过语义编码模型将文本转化为高维向量,构建可扩展的向量数据库(如使用FAISS/HNSW索引),使得十亿级文档可实现亚秒级语义检索。该技术突破不仅实现多路召回(MMR)与重排序的高效协同,还能捕捉深层语义关联,如通过余弦相似度匹配准确识别96%的潜在相关段落,从而确保输入大模型的知识片段兼具相关性与多样性。当前典型应用中,RAG+向量化组合方案已在金融分析、医疗诊断等场景实现准确率15-30%的提升,证实其在高实时性、高准确性需求场景的技术优越性。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
2024最新版优快云大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









