







一篇文章“盘”透 Python 爬虫?80% 够用,99% 才够味!
Python“爬虫”秘籍
Python 爬虫技术,那可是数据采集、信息获取的“神器”!本文将带你“盘”透 Python 爬虫的核心知识,助你火速晋升“爬虫”大神!以下内容,我们将“扒”开爬虫的基本概念、常用库、核心技术,再来几个实战案例“练练手”。

一、Python 爬虫“入门须知”
1. 啥是“爬虫”?
爬虫,也叫“网络蜘蛛”或“网络机器人”,说白了,就是一种自动化脚本或程序,专门用来“逛”网站,并把网站上的数据“搬”回来的。爬虫会从一个初始网页出发,顺着网页上的链接,不断“爬”到更多的网页,然后把网页内容存起来,方便以后分析。
2. 爬虫“工作流程”大揭秘
一般来说,爬虫的“工作流程”分这么几步:
-
- 发送请求:用 HTTP 库发送请求,把网页内容“抓”回来。
-
- 解析网页:用解析库解析网页,把需要的数据“抠”出来。
-
- 存储数据:把“抠”出来的数据存到数据库或文件里。
-
- 应对反爬:跟网站的“反爬虫”技术斗智斗勇,比如搞定验证码、绕过 IP 封禁等等。
二、Python 爬虫“工具箱”
1. Requests
Requests 是一个简单好用的 HTTP 请求库,专门用来发送网络请求,获取网页内容。它最大的优点就是 API 简洁明了,支持各种 HTTP 请求方式,简直是“爬虫”必备!
import requests
response = requests.get('https://example.com')
print(response.text) # 打印网页内容
2. BeautifulSoup
BeautifulSoup 是一个专门解析 HTML 和 XML 的库,它提供了一套简单方便的 API,让你能轻松地搜索、导航和修改解析树。
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.title.string) # 打印网页标题
3. Scrapy
Scrapy 是一个功能强大的爬虫框架,特别适合构建和维护大型爬虫项目。它提供了各种“黑科技”,比如自动处理请求、解析、存储数据等等,简直是“爬虫”界的“航空母舰”!
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
start_urls = ['https://example.com']
def parse(self, response):
title = response.css('title::text').get() # 获取网页标题
yield {'title': title}
4. Selenium
Selenium 本来是一个自动化测试工具,但它也能用来爬取动态网页。它可以模拟浏览器的各种操作,比如点击、输入、滚动等等,简直是“爬虫”界的“变形金刚”!
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://example.com')
print(driver.title) # 打印网页标题
driver.quit()
三、“爬虫”核心技术
1. “反反爬”大法
反爬机制是网站为了防止数据被大量抓取而搞出来的“拦路虎”。常见的反爬机制有:
- • User-Agent 伪装:假装自己是真实浏览器,让网站“认不出”你是爬虫。
- • IP 代理:用代理服务器“绕过”IP 封禁,让网站“抓不到”你。
- • 验证码:用打码平台或人工识别来“破解”验证码,让网站“拦不住”你。
- • 动态内容:用 Selenium 等工具来处理 JavaScript 渲染的内容,让网站“藏不住”数据。
2. 数据解析
数据解析就是把 HTML 内容变成结构化数据的过程。除了 BeautifulSoup,lxml 和 XPath 也是常用的解析工具,它们能让你更方便地从 HTML 里“抠”出数据。
3. 数据存储
数据存储就是把“抠”出来的数据保存到本地或数据库里。常用的存储方式有:
- • 文件存储:比如 CSV、JSON、Excel 文件,方便快捷。
- • 数据库存储:比如 SQLite、MySQL、MongoDB,适合存储大量数据。
四、实战案例“练练手”
案例 1:爬取网易新闻标题
下面是一个简单的例子,教你爬取网易新闻网站的标题:
import requests
from bs4 import BeautifulSoup
def fetch_netnews_titles(url):
# 发送 HTTP 请求
response = requests.get(url)
# 使用 BeautifulSoup 解析响应内容
soup = BeautifulSoup(response.text, 'html.parser')
# 找到所有新闻标题的标签(这里假设它们在<h2>标签里)
news_titles = soup.find_all('h2')
# 提取标题文本,并去掉两边的空格
titles = [title.text.strip() for title in news_titles]
return titles
# 网易新闻的 URL
url = 'https://news.163.com'
titles = fetch_netnews_titles(url)
print(titles)
案例 2:用 Scrapy 构建电商爬虫
Scrapy 可以用来构建复杂的电商网站爬虫,下面是一个简单的商品信息爬虫示例:
import scrapy
class EcommerceSpider(scrapy.Spider):
name = 'ecommerce'
start_urls = ['https://example-ecommerce.com/products']
def parse(self, response):
for product in response.css('div.product'):
yield {
'name': product.css('h2::text').get(), # 商品名称
'price': product.css('span.price::text').get(), # 商品价格
}
五、深入“解剖”爬虫原理
1. HTTP 协议与请求头伪装
在爬虫的请求阶段,我们经常需要跟 HTTP 协议打交道。了解 HTTP 协议的请求和响应结构,是爬虫开发的“基本功”。通过伪装请求头里的 User-Agent,我们可以假装自己是不同的浏览器和设备,避免被目标网站识别成爬虫。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get('https://example.com', headers=headers)
2. 使用代理 IP 绕过 IP 封禁
当网站对某个 IP 地址的访问频率进行限制时,我们可以用代理 IP 来“绕过”封禁。通过轮流使用不同的代理 IP,可以提高爬虫的稳定性和数据采集效率。
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
response = requests.get('https://example.com', proxies=proxies)
3. 处理动态网页
对于通过 JavaScript 加载数据的动态网页,传统的静态解析方法就“抓瞎”了。这时候,我们可以用 Selenium 来模拟用户操作,加载完整的网页内容,然后再解析。
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 无头模式,不显示浏览器窗口
driver = webdriver.Chrome(options=options)
driver.get('https://example.com')
content = driver.page_source # 获取网页源码
driver.quit()
soup = BeautifulSoup(content, 'html.parser')
4. 数据清洗与存储优化
爬取到数据后,往往需要对数据进行清洗和格式化,方便后续的分析和使用。Pandas 库是一个强大的数据处理工具,它可以帮助我们高效地进行数据清洗和存储。
import pandas as pd
data = {
'name': ['Product1', 'Product2'],
'price': [10.99, 12.99]
}
df = pd.DataFrame(data)
df.to_csv('products.csv', index=False) # 保存为 CSV 文件,不包含索引
结语
掌握 Python 爬虫的核心技术和工具,能大大提高数据采集的效率和质量。希望通过本文的介绍,你能对 Python 爬虫有一个更全面的了解,并在实践中不断提升自己的“爬虫”技能!
觉得有用的话,希望粉丝朋友帮大白点个**「分享」「收藏」「在看」「赞」**

黑客/网络安全学习包


资料目录
-
成长路线图&学习规划
-
配套视频教程
-
SRC&黑客文籍
-
护网行动资料
-
黑客必读书单
-
面试题合集
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

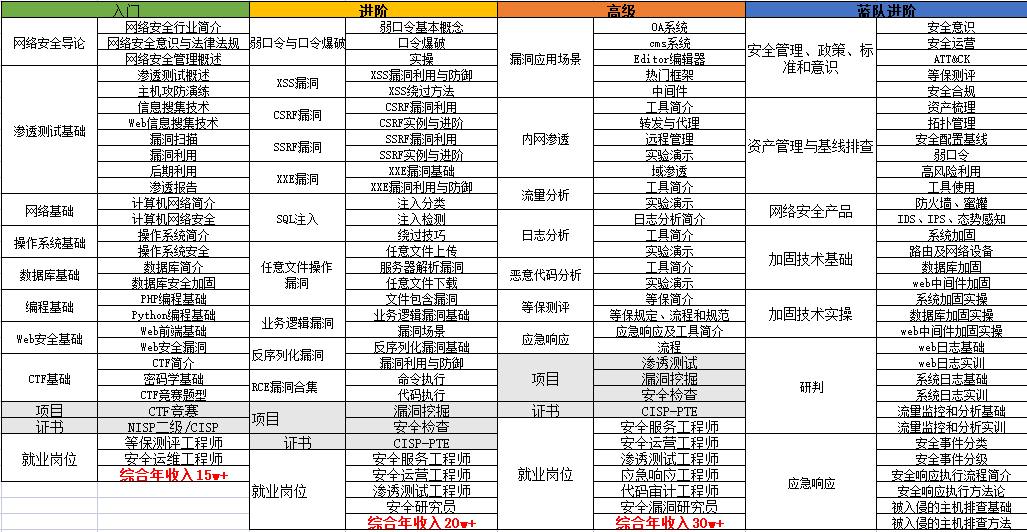
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
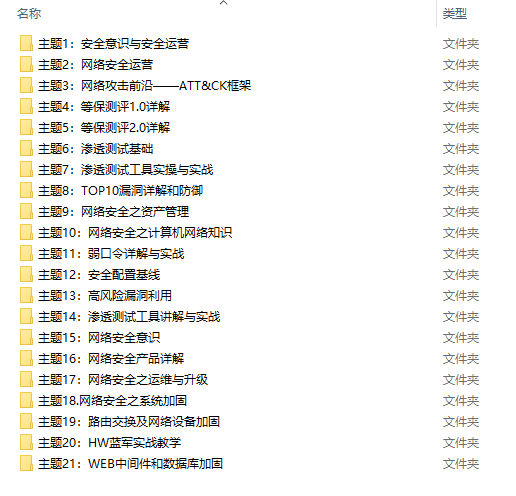
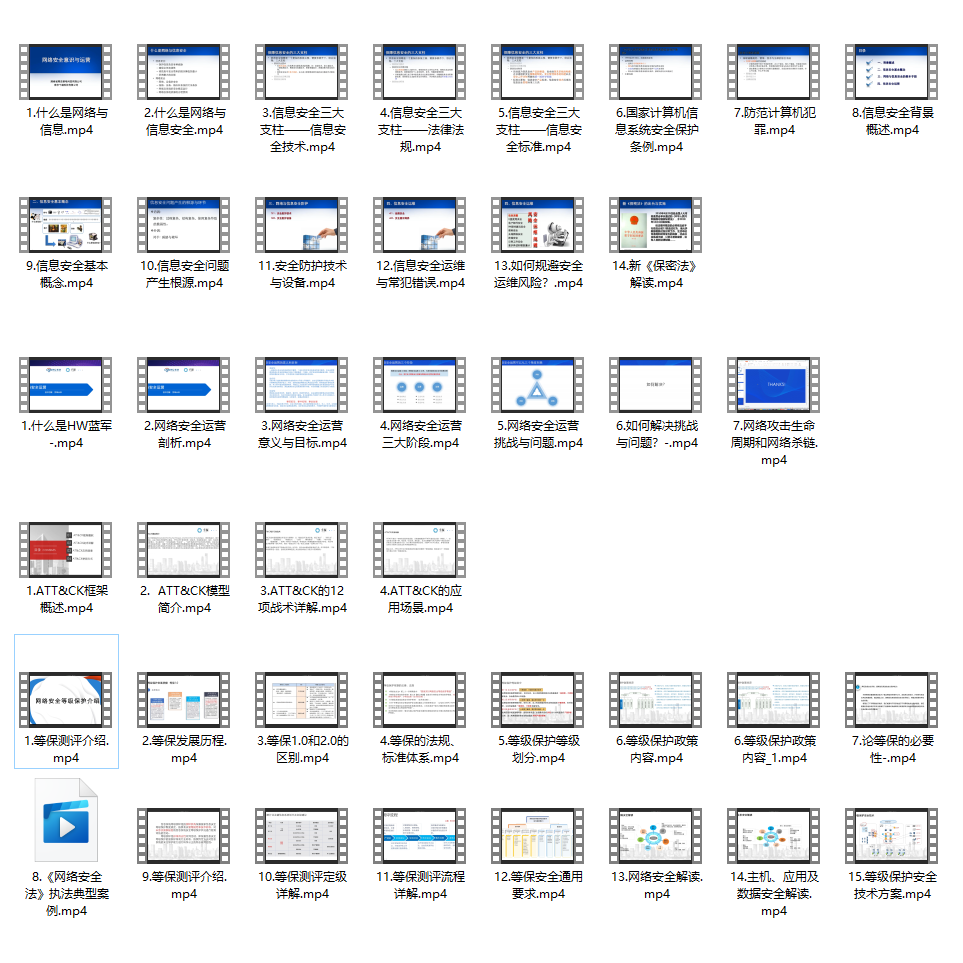
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.SRC&黑客文籍
大家最喜欢也是最关心的SRC技术文籍&黑客技术也有收录
SRC技术文籍:

黑客资料由于是敏感资源,这里不能直接展示哦!
4.护网行动资料
其中关于HW护网行动,也准备了对应的资料,这些内容可相当于比赛的金手指!
5.黑客必读书单
**

**
6.面试题合集
当你自学到这里,你就要开始思考找工作的事情了,而工作绕不开的就是真题和面试题。
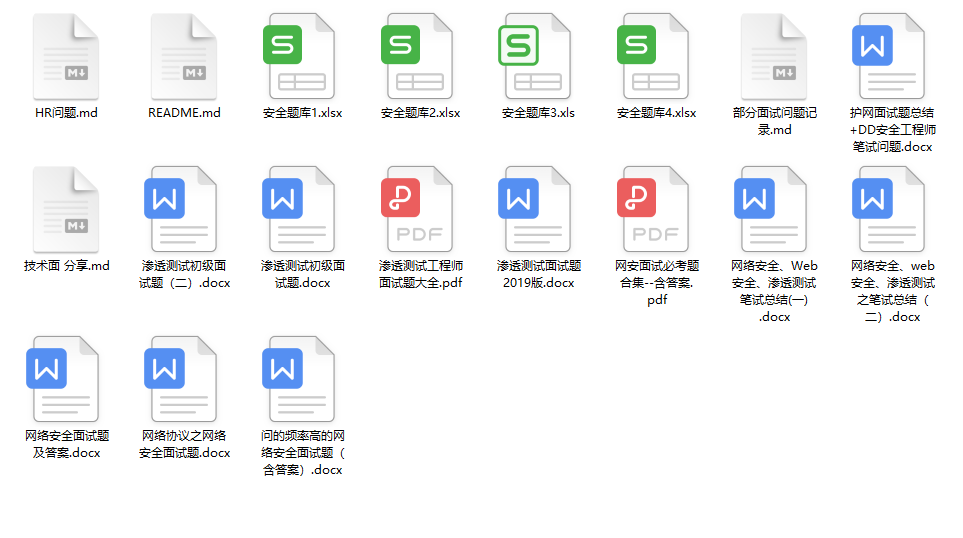
更多内容为防止和谐,可以扫描获取~

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
****************************优快云大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享

















 1927
1927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









