







主要挑战:
KPI 通常是周期性的,取决于应用程序和系统,它们的周期可以从数天到数周。因此, 每个 KPI 通常有数千个点需要完全捕捉才能刻画它在一段时间内的行为。但是因为一些不可避免的因素会导致时间序列有一些显著的形状变化,从而影响时间序列的分类。
噪音和异常:噪音和异常在 KPI 中很常见。噪音通常是指小围绕 KPI 中预期值的随机波动,而异常是显着的波动,通常更大超过 2 个标准差 。噪音和异常可能会误导聚类方法,因为它们会扭曲KPI 之间的相似性。我们通过滑动平均,分段聚合(PAA)以及压缩聚合等一些手段可以有效降低噪音的影响,而对于异常值的处理我们可以通过4分位,3sgima等方式进行解决。
幅度差异:KPI 可以采用不同的尺度。例如,对两个密切相关但又不同的同一服务的模块可能看起来像(下图幅度变化1),但如果我们去除幅度差异这些 KPI 具有相似的模式并且可以作为一个组进行分析(下图幅度变化2)。而通过Z-score等标准化数据的方式可以有效解决这个问题。
相位偏移:相移是指在两个 KPI 之间全局水平的便宜。例如,同一系统上的一组 KPI调用链可能具有相似的形状,但具有时滞性。相位偏移可能使找到类似的 KPI 变得困难。为了解决这个问题,我们从距离度量和算法两个维度上解决这个问题:例如替代传统的欧式距离,改用NCC-SBD,DTW距离度量的方式,使用DBSCAN算法进行聚类等等。
高纬诅咒:高维诅咒是指随着数据维度的提升,很多我们在低纬度认为相当然的现象,在高纬度空间里面都不成立了,例如我们这相邻之间的点全部都变得很远。这在有数千个点的时间序列里是十分常见的问题。我们可以通过设置L1的距离度量替换L3及以上的距离度量解决这个问题。
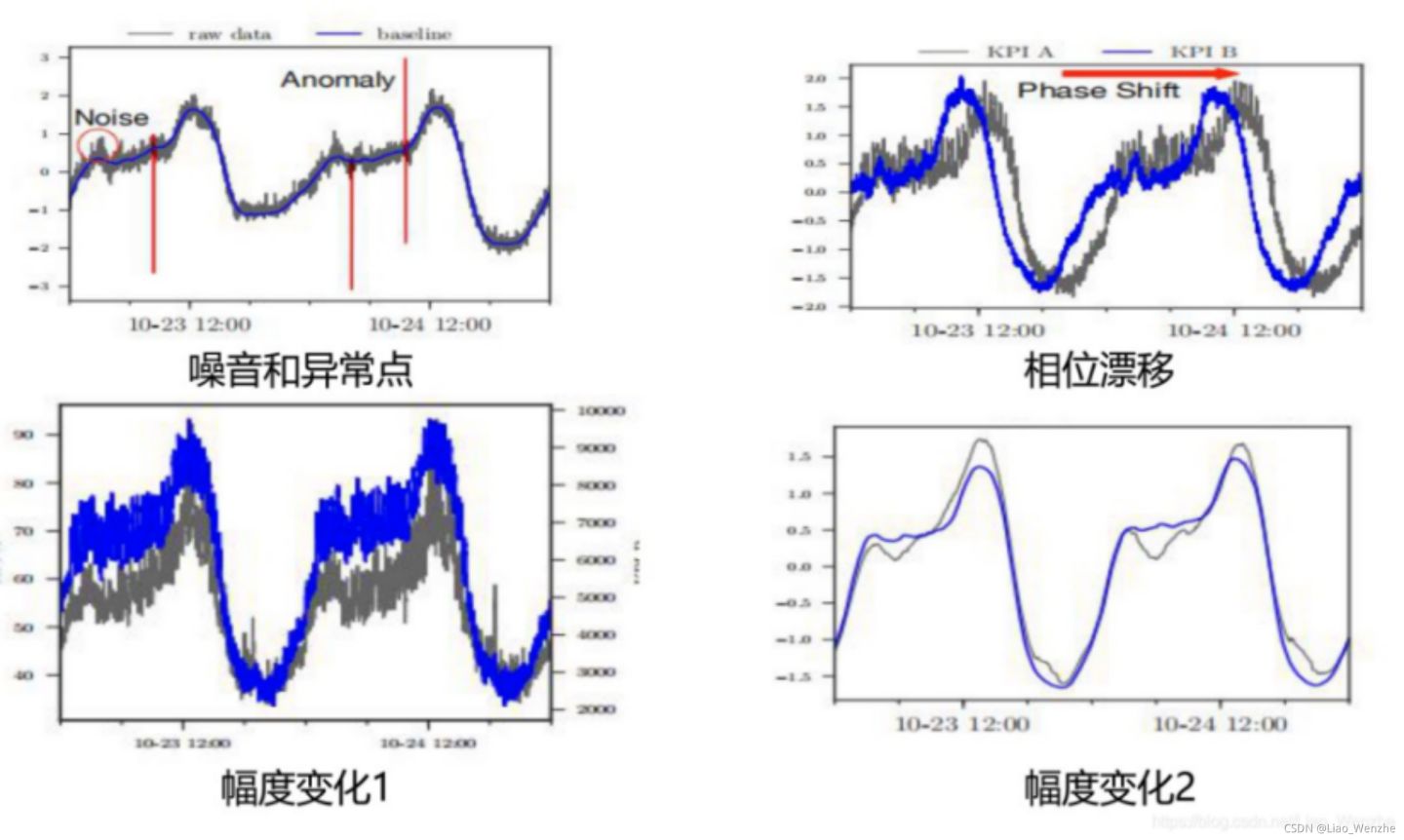
图 1 时序数据分类的挑战
几种方式:
1. 基于统计的时间序列分类:在对数据做一定的时间差分后,如果方差很小,可以判定为有时间周期性。否则为无时间周期性。该方法实现简单,缺点是只能分成2类。
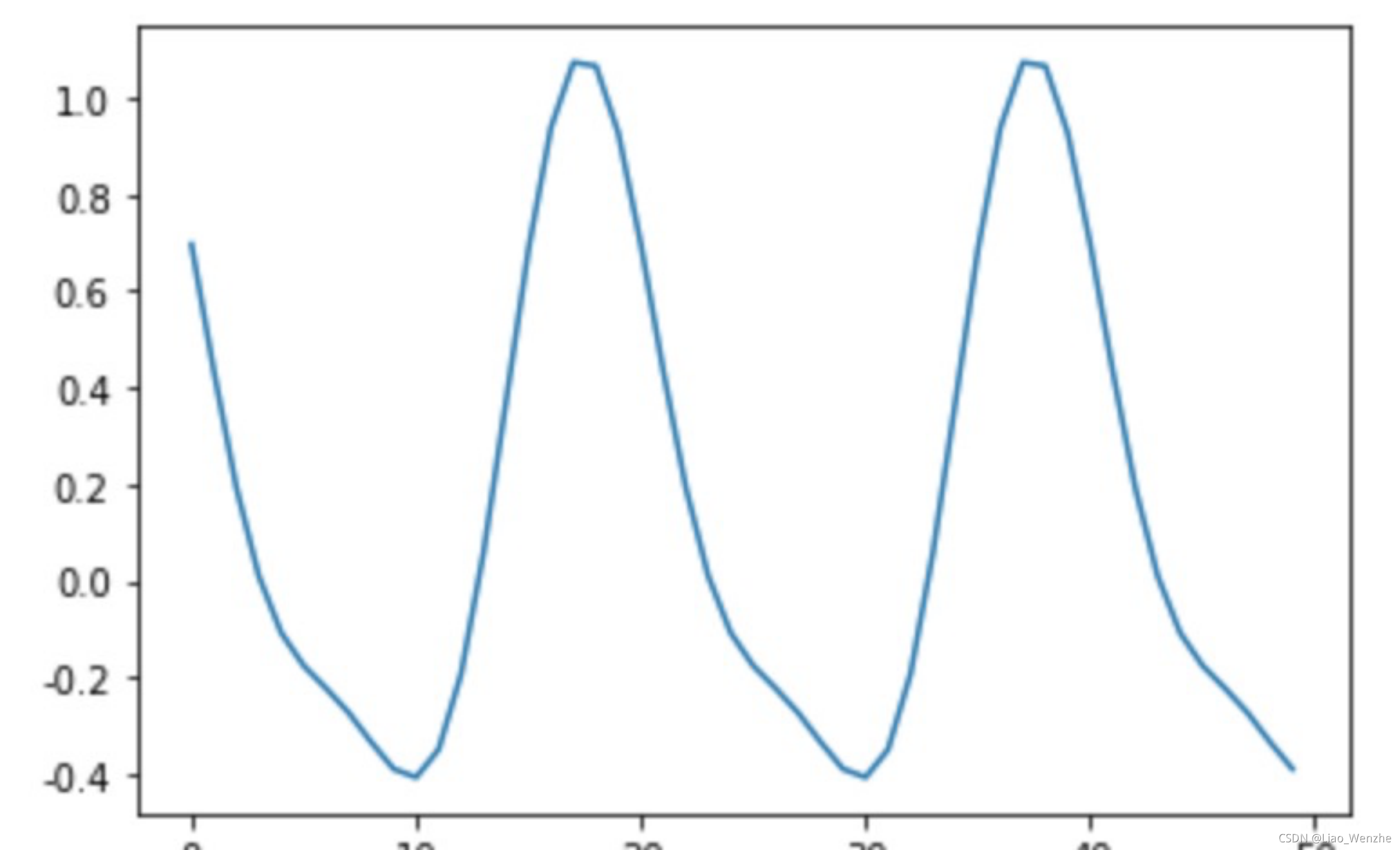
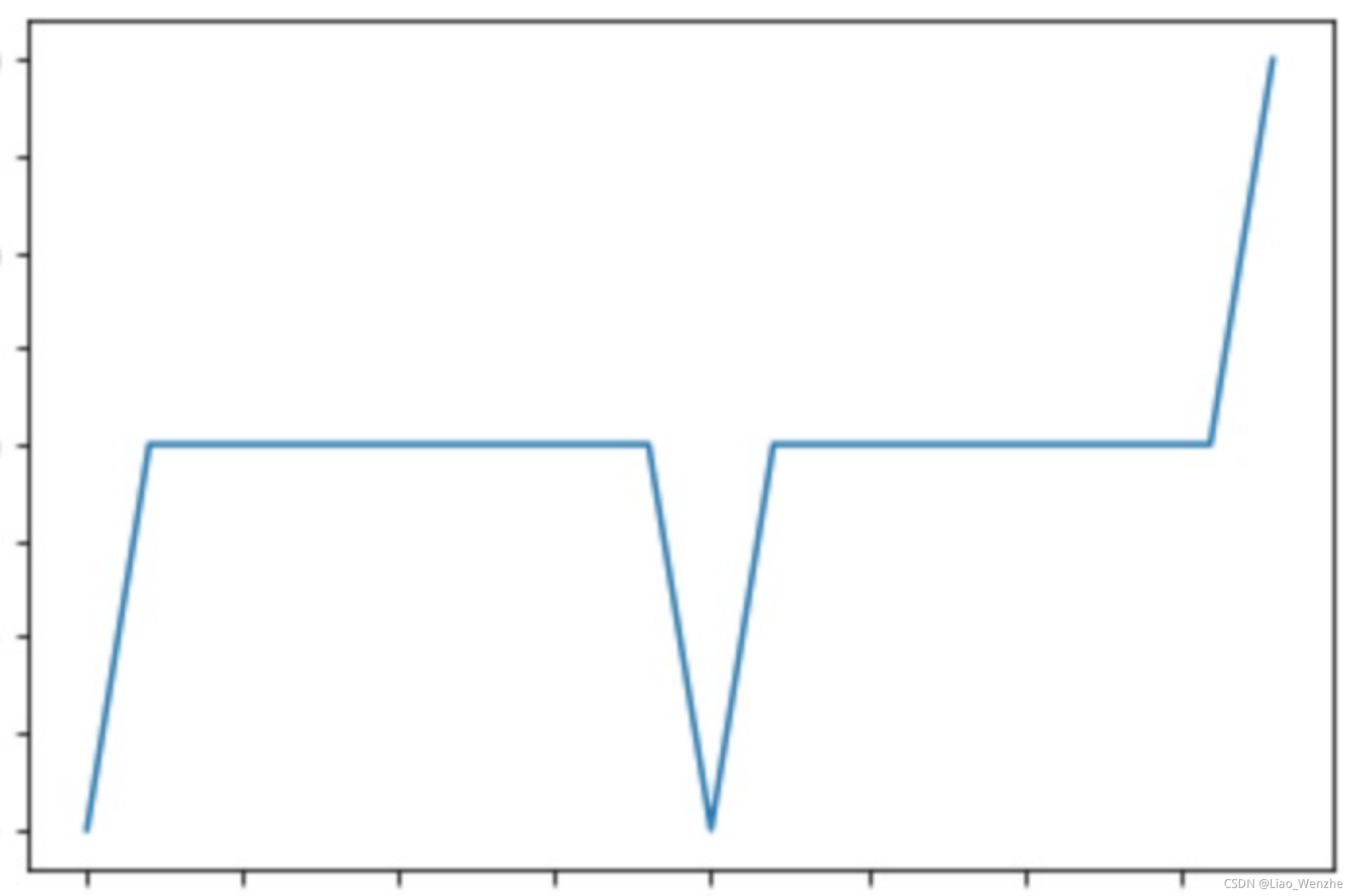
图3.1 时间差分前 图3.2 时间差分后
2. 无监督的聚类:Yading[1]是一种大规模的时序聚类方法,有别于K-Means和K-Shape采用互相关统计方法,它采用PAA降维和基于密度聚类的方法实现快速聚类,且在计算距离时尽量保留了时间序列的形状。Rocka[2]是另一种大规模的时序聚类方法,在Yading的基础上,Rocka提出通过滑动平均+NCC-SBD的方式进行噪声提出和距离度量。无监督的聚类方法无需标签数据即可进行多个类别的分类,但是相对于监督学习准确度会稍低。
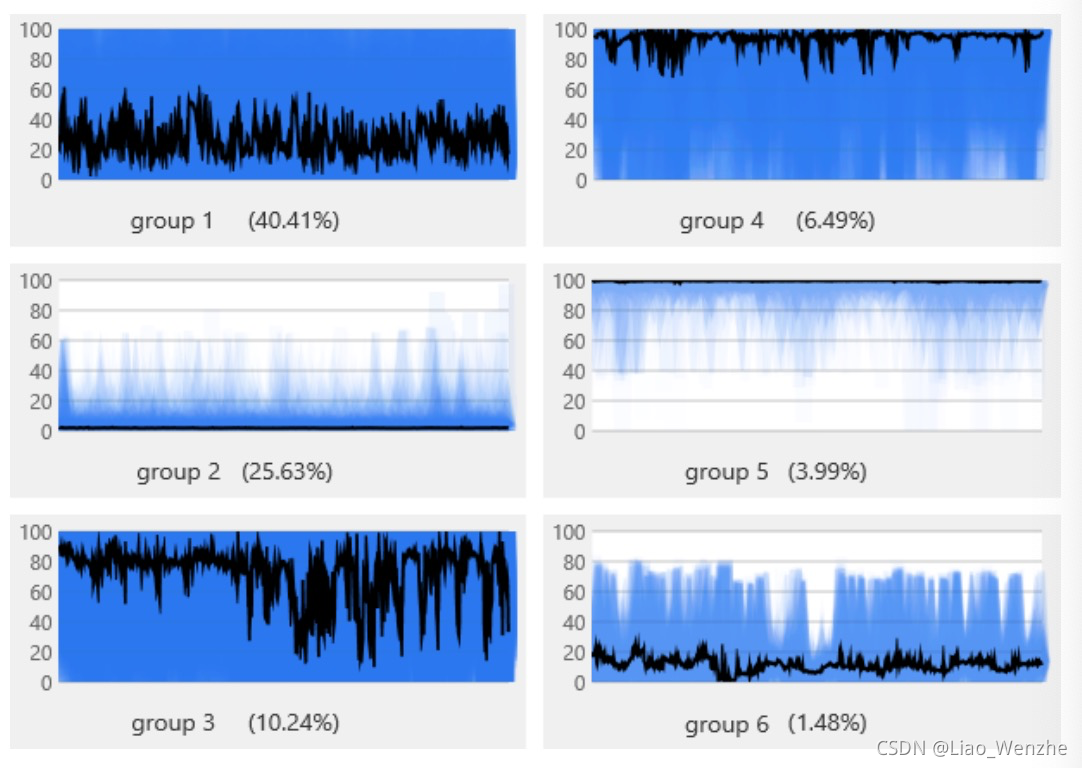
图4: 无监督聚类
3. 监督学习的分类方法:主要包括Logistics、SVM,CNN[3]等。监督学习的分类方法准确度会比无监督的聚类方法跟高,但是需要大量的标签数据。
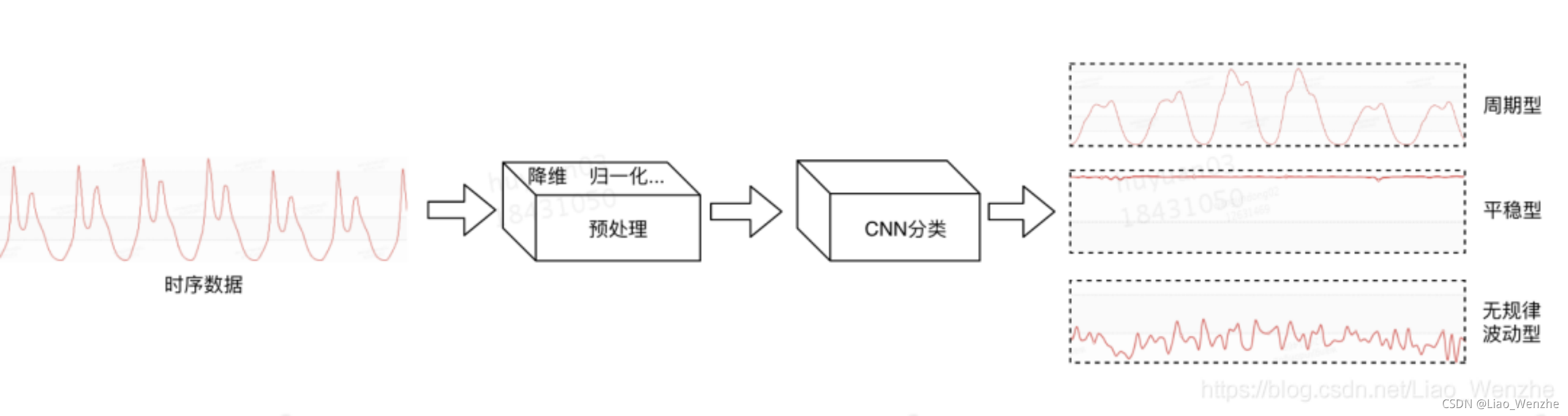
图3: CNN时间序列分类
参考论文:
[1] Ding R, Wang Q, Dang Y, et al. Yading: fast clustering of large-scale time series data[J]. Proceedings of the VLDB Endowment, 2015, 8(5): 473-484.
[2] Robust and rapid clustering of kpis for large-scale anomaly detection. 2018
[3] Tom Brander. Time series classification with Tensorflow[EB/OL]. https://burakhimmetoglu.com/2017/08/22/time-series-classification-with-tensorflow, 2017-08-22.
[4] Metis is a learnware platform in the field of AIOps[EB/OL]. https://github.com/Tencent/Metis, 2018-10-12.


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









