




 文章探讨了样本不均衡问题,尤其是针对少数类别的预测。介绍了SMOTE算法及其改进版Borderline-SMOTE1和Borderline-SMOTE2,这两种方法专注于过采样边界附近的少数样本,以提升分类器对少数类别的性能。实验结果显示,Borderline-SMOTE方法在提高tp率和f值方面表现优秀。
文章探讨了样本不均衡问题,尤其是针对少数类别的预测。介绍了SMOTE算法及其改进版Borderline-SMOTE1和Borderline-SMOTE2,这两种方法专注于过采样边界附近的少数样本,以提升分类器对少数类别的性能。实验结果显示,Borderline-SMOTE方法在提高tp率和f值方面表现优秀。
许多现实领域存在着不平衡的数据集,如发现不可靠的电信客户、卫星雷达图像中的漏油检测、学习单词发音、文本分类、欺诈电话检测、信息检索和过滤任务等。在这些领域中,我们真正感兴趣的是少数类别而不是多数类别。因此,我们需要对少数群体作出相当高的预测。smote合成少数样本过采样技术是解样本不均衡的方法。本文提出了两种新的过采样方法,即Borderline-smote1和Borderline-smote2,对边界线附近的少数样本被过采样。对于少数类别的样本,实验表明,我们的方法比窒息和随机抽样方法获得更好的tp率和f值。
在解决不平衡数据集问题上,前人做了很多,先简单提下,可供研究者深入。
一个数据集中可能存在两种不平衡。一个是类别不平衡,在这种情况下,有些类别比其他类别有更多的例子。另一个是类内不平衡,在这种情况下,一个类的某些子集的示例比同一类的其他子集少很多。按照惯例,在不平衡的数据集中,我们称具有更多示例的类为多数类,具有较少示例的类为少数类。不平衡域的研究大多集中在两类问题上,因为多类问题可以简化为两类问题。按照惯例,少数类别标签是正的,多数类别标签是负的。表1说明了一个两类问题的混淆矩阵。表的第一列是示例的实际类标签,第一行显示了它们的预测类标签。tp和tn分别表示正确分类的正例和负例的数量,而fn和fp分别表示错误分类的正例和负例的数量。
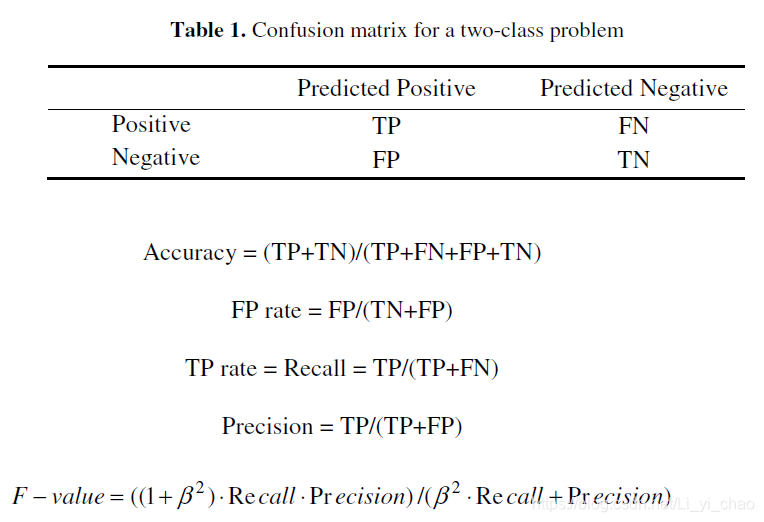
数据极不平衡时,多数类别的样本更容易预测,对少数班级的表现较差。如果数据集极不平衡,即使分类器正确地对大多数示例进行分类,并且对所有少数示例进行了错误分类,分类器的准确性仍然很高,在这种情况下,准确度不能反映少数民族的可靠预测。因此,需要更合理的评估指标。
ROC曲线是评价学习器不平衡数据集的常用指标之一。ROC曲线二维图,y轴上绘制tp rate,x轴上绘制fp rate。fp rate表示错误分类的负样本的百分比,tp rate是正确分类的正样本的百分比。ROC曲线描述了收益(t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









