







目录
825. Friends Of Appropriate Ages
230. Kth Smallest Element in a BST
725. Split Linked List in Parts
1319. Number of Operations to Make Network Connected
990. Satisfiability of Equality Equations
1202. Smallest String With Swaps
78. Subsets
Medium
295470Add to ListShare
Given a set of distinct integers, nums, return all possible subsets (the power set).
Note: The solution set must not contain duplicate subsets.
Example:
Input: nums = [1,2,3]
Output:
[
[3],
[1],
[2],
[1,2,3],
[1,3],
[2,3],
[1,2],
[]
]#include"pch.h"
#include<vector>
#include<iostream>
#include<queue>
using namespace std;
/*78. Subsets
DFS:
Runtime: 4 ms, faster than 97.95% of C++ online submissions for Subsets.
Memory Usage: 8.1 MB, less than 100.00% of C++ online submissions for Subsets.*/
void DFS(vector<int> &out, vector<vector<int> > &res, vector<int>& nums, int tar,int num,int start) {
if (num == tar) {
res.push_back(out);
return;
}
for (int i = start; i < nums.size(); i++) {
out.push_back(nums[i]);
DFS( out, res, nums, tar, num + 1,i+1);
out.pop_back();
}
return;
}
vector<vector<int>> subsets(vector<int>& nums) {
vector<int> out;
vector<vector<int> > res;
for (int i = 0; i <= nums.size(); i++) {//想要组成i长度的子数组
DFS(out, res, nums, i, 0,0);
}
return res;
}
/*2.非递归
Runtime: 4 ms, faster than 97.91% of C++ online submissions for Subsets.
Memory Usage: 8.2 MB, less than 100.00% of C++ online submissions for Subsets.*/
vector<vector<int>> subsets(vector<int>& nums) {
vector<vector<int> > res(1);
sort(nums.begin(),nums.end());
for (int i = 0; i < nums.size(); i++) {
int size=res.size();
for(int j=0;j<size;j++){
res.push_back(res[j]);
res.back().push_back(nums[i]);
}
}
return res;
}
int main() {
vector<int> nums = { 1,2,3 };
vector<vector<int> > res = subsets(nums);
for (int i = 0; i < res.size(); i++) {
for (int j = 0; j < res[i].size(); j++) cout << res[i][j] << " ";
cout << endl;
}
return 0;
}90. Subsets II
Medium
136159Add to ListShare
Given a collection of integers that might contain duplicates, nums, return all possible subsets (the power set).
Note: The solution set must not contain duplicate subsets.
Example:
Input: [1,2,2]
Output:
[
[2],
[1],
[1,2,2],
[2,2],
[1,2],
[]
]#include"pch.h"
#include<vector>
#include<iostream>
#include<queue>
#include<set>
using namespace std;
/*90. Subsets II
1.使用set防止重复
Runtime: 36 ms, faster than 6.80% of C++ online submissions for Subsets II.
Memory Usage: 10.6 MB, less than 27.27% of C++ online submissions for Subsets II.*/
void DFS(vector<int> &out,set<vector<int> > &res,vector<int> nums,int target,int num,int start) {
if (num == target) {
res.insert(out);
return;
}
for (int i = start; i < nums.size(); i++) {
out.push_back(nums[i]);
DFS(out, res, nums, target, num + 1, i + 1);
out.pop_back();
}
return;
}
vector<vector<int>> subsetsWithDup1(vector<int>& nums) {
//先排序,从前往后选择,如果前面的和我一样大,并且前面的没有被选入,那么也不选我
vector<int> out;
set<vector<int> > res;
sort(nums.begin(), nums.end());
for (int i = 0; i <= nums.size(); i++) {
DFS(out, res, nums, i, 0, 0);
}
vector<vector<int> > ress;
for (auto &a : res) {
ress.push_back(a);
}
return ress;
}
/*2.用last记录上一个处理的数字
Runtime: 8 ms, faster than 81.61% of C++ online submissions for Subsets II.
Memory Usage: 8.6 MB, less than 100.00% of C++ online submissions for Subsets II.*/
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
vector<vector<int> > res(1);
sort(nums.begin(), nums.end());
int lastsize = res.size();
for (int i = 0; i < nums.size(); i++) {
int size = res.size();
int start = 0;
if (i > 0 && nums[i] == nums[i - 1]) start = lastsize;
for (int j = start; j < size; j++) {
res.push_back(res[j]);
res.back().push_back(nums[i]);
}
lastsize = size;
}
return res;
}
int main() {
vector<int> nums = {5,5,5,5,5};
vector<vector<int> > res = subsetsWithDup(nums);
for (int i = 0; i < res.size(); i++) {
for (int j = 0; j < res[i].size(); j++) cout << res[i][j] << " ";
cout << endl;
}
return 0;
}825. Friends Of Appropriate Ages
Medium
251542Add to ListShare
Some people will make friend requests. The list of their ages is given and ages[i] is the age of the ith person.
Person A will NOT friend request person B (B != A) if any of the following conditions are true:
age[B] <= 0.5 * age[A] + 7age[B] > age[A]age[B] > 100 && age[A] < 100
Otherwise, A will friend request B.
Note that if A requests B, B does not necessarily request A. Also, people will not friend request themselves.
How many total friend requests are made?
Example 1:
Input: [16,16]
Output: 2
Explanation: 2 people friend request each other.
Example 2:
Input: [16,17,18]
Output: 2
Explanation: Friend requests are made 17 -> 16, 18 -> 17.Example 3:
Input: [20,30,100,110,120]
Output:
Explanation: Friend requests are made 110 -> 100, 120 -> 110, 120 -> 100.
Notes:
1 <= ages.length <= 20000.1 <= ages[i] <= 120.
#include"pch.h"
#include<vector>
#include<iostream>
#include<queue>
#include<set>
using namespace std;
/*825. Friends Of Appropriate Ages
(1)B≤A(2)B>0.5*A+7,即A<2*B-14
如果A想加B,那么B必须在(0.5*A+7,A]区间内,所以A>0.5*A+7,所以A>14
区间求和,建立累加数组
建立一个统计数组,范围是[0,120],统计在各个年龄点上有多少人,然后建立累加和数组
因为不能小于15,所以从15开始遍历,然后统计出(0.5*A+7,A]范围内有多少人,通过累加和数组快速求出
由于当前节点可以和区间内所有人发出申请,而会有很多等于当前节点,所以要乘以当前节点人数
但是由于区间包含了A,包含了当前节点人数,所以还要减去当前节点人数
Runtime: 56 ms, faster than 30.52% of C++ online submissions for Friends Of Appropriate Ages.
Memory Usage: 10.6 MB, less than 100.00% of C++ online submissions for Friends Of Appropriate Ages.*/
int numFriendRequests(vector<int>& ages) {
sort(ages.begin(), ages.end());
vector<int> nums(121);
vector<int> sum(121);
int res = 0;
for (int i = 0; i < ages.size(); i++) {
nums[ages[i]]++;
}
for(int i=1;i<=120;i++){
sum[i] = sum[i - 1] + nums[i];
}
for (int i = 15; i <= 120; i++) {
res += (sum[i] - sum[0.5*i + 7])*nums[i] - nums[i];
}
return res;
}
int main() {
vector<int> ages = { 16,16,120,110,23,120,1,120,90,10,14,15,120 };
cout << numFriendRequests(ages);
return 0;
}
230. Kth Smallest Element in a BST
Medium
184453Add to ListShare
Given a binary search tree, write a function kthSmallest to find the kth smallest element in it.
Note:
You may assume k is always valid, 1 ≤ k ≤ BST's total elements.
Example 1:
Input: root = [3,1,4,null,2], k = 1
3
/ \
1 4
\
2
Output: 1Example 2:
Input: root = [5,3,6,2,4,null,null,1], k = 3
5
/ \
3 6
/ \
2 4
/
1
Output: 3
Follow up:
What if the BST is modified (insert/delete operations) often and you need to find the kth smallest frequently? How would you optimize the kthSmallest routine?
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
/*1.中序遍历第k个输出的数字
Runtime: 20 ms, faster than 83.53% of C++ online submissions for Kth Smallest Element in a BST.
Memory Usage: 20.6 MB, less than 100.00% of C++ online submissions for Kth Smallest Element in a BST.*/
int kthSmallest1(TreeNode* root, int k) {
stack<TreeNode*> s;
int num=0;
while(root || !s.empty()){
while(root){
s.push(root);
root=root->left;
}
if(!s.empty()){
TreeNode *tmp=s.top();
num++;s.pop();
if(num==k) return tmp->val;
if(tmp->right) root=tmp->right;
}
}
return 0;
}
/*2.分治法:计算出左子树节点个数cnt,如果k≤cnt,说明在左子树上,直接对左子树递归
如果k>cnt+1,说明在右子树上,对右子树递归,此时k应该更新为k-cnt-1,
如果k=cnt+1,说明当前节点就是需要求的节点。
Runtime: 20 ms, faster than 83.53% of C++ online submissions for Kth Smallest Element in a BST.
Memory Usage: 21 MB, less than 100.00% of C++ online submissions for Kth Smallest Element in a BST.*/
int count2(TreeNode *root){
if(!root) return 0;
return 1+count2(root->left)+count2(root->right);
}
int kthSmallest2(TreeNode* root, int k) {
int cnt=count2(root->left);
if(k==cnt+1) return root->val;
if(k<=cnt) return kthSmallest(root->left,k);
else return kthSmallest(root->right,k-cnt-1);
}
/*3.follow up:
What if the BST is modified (insert/delete operations) often and you need to find the kth smallest frequently? How would you optimize the kthSmallest routine?
假设这个BST修改很频繁,而且查找第k个元素的操作也很频繁,如何优化?
最好的方法还是像第二种,利用分治法来快速定位,
但是每个递归都遍历左子树所有节点来计算个数,并不高效,
所以需要修改原树结构,使节点保存包括当前节点和其左右子树所有节点的个数,
这样就可以快速得到任何左子树节点总数来快速确定目标值。
定义了新的结构体,需要生成新的树,利用递归生成新树,然后调用递归函数,
在递归函数中,先判断左子树是否存在,如果存在,与2方法相同,
如果不存在,且k=1,则返回当前节点,否则对右子节点进行递归,k-1。
Runtime: 28 ms, faster than 24.17% of C++ online submissions for Kth Smallest Element in a BST.
Memory Usage: 23.8 MB, less than 6.67% of C++ online submissions for Kth Smallest Element in a BST.*/
typedef struct TreeNodee{
int val;
TreeNodee *left;
TreeNodee *right;
int num;
//TreeNodee(int x):val(x),num(1),left(NULL),right(NULL) {}
}TreeNodee;
TreeNodee* createTree(TreeNode *root){
if(root==NULL) return NULL;
//TreeNodee *newroot=new TreeNodee(root->val);
TreeNodee *newroot=(TreeNodee*)malloc(sizeof(TreeNodee));
newroot->num=1;
newroot->val=root->val;
newroot->left=createTree(root->left);
newroot->right=createTree(root->right);
if(newroot->left) newroot->num+=newroot->left->num;
if(newroot->right) newroot->num+=newroot->right->num;
return newroot;
}
int count(TreeNodee *root,int k){
if(root->left){
int cnt=root->left->num;
if(k<=cnt) return count(root->left,k);
else if(k>cnt+1) return count(root->right,k-cnt-1);
else return root->val;
}else{
if(k==1) return root->val;
return count(root->right,k-1);
}
return 0;
}
int kthSmallest(TreeNode* root, int k) {
TreeNodee *newroot=createTree(root);
return count(newroot,k);
}
};48. Rotate Image
Medium
2431205Add to ListShare
You are given an n x n 2D matrix representing an image.
Rotate the image by 90 degrees (clockwise).
Note:
You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and do the rotation.
Example 1:
Given input matrix =
[
[1,2,3],
[4,5,6],
[7,8,9]
],
rotate the input matrix in-place such that it becomes:
[
[7,4,1],
[8,5,2],
[9,6,3]
]
Example 2:
Given input matrix =
[
[ 5, 1, 9,11],
[ 2, 4, 8,10],
[13, 3, 6, 7],
[15,14,12,16]
],
rotate the input matrix in-place such that it becomes:
[
[15,13, 2, 5],
[14, 3, 4, 1],
[12, 6, 8, 9],
[16, 7,10,11]
]class Solution {
public:
/*(i,j)->(j,n-i-1)->(n-i-1,n-j-1)->(n-j-1,i)->(i,j)
Runtime: 0 ms, faster than 100.00% of C++ online submissions for Rotate Image.
Memory Usage: 7.9 MB, less than 100.00% of C++ online submissions for Rotate Image.*/
void rotate(vector<vector<int>>& matrix) {
int n=matrix.size();
for(int i=0;i<n/2;i++){
for(int j=i;j<n-i-1;j++){
int tmp=matrix[i][j];
matrix[i][j]=matrix[n-j-1][i];
matrix[n-j-1][i]=matrix[n-i-1][n-j-1];
matrix[n-i-1][n-j-1]=matrix[j][n-i-1];
matrix[j][n-i-1]=tmp;
}
}
}
};49. Group Anagrams
Medium
2621151Add to ListShare
Given an array of strings, group anagrams together.
Example:
Input: ["eat", "tea", "tan", "ate", "nat", "bat"],
Output:
[
["ate","eat","tea"],
["nat","tan"],
["bat"]
]Note:
- All inputs will be in lowercase.
- The order of your output does not matter.
class Solution {
public:
/*相同字母异序值*/
/*1.排序,使用map映射排序后
Runtime: 40 ms, faster than 78.49% of C++ online submissions for Group Anagrams.
Memory Usage: 16.9 MB, less than 100.00% of C++ online submissions for Group Anagrams.*/
vector<vector<string>> groupAnagrams1(vector<string>& strs) {
unordered_map<string, int> a;
vector<vector<string> > res;
for (int i = 0; i < strs.size(); i++) {
string tmp = strs[i];
sort(tmp.begin(), tmp.end());
if (a.find(tmp) == a.end()) {
int size = a.size();
a[tmp] = size;
res.push_back({ strs[i] });
}
else {
res[a[tmp]].push_back(strs[i]);
}
}
return res;
}
/*2.如果不排序,使用tmp[26],记录每个字母的出现次数,将“字母+出现次数”形成字符串,进行映射
Runtime: 56 ms, faster than 31.26% of C++ online submissions for Group Anagrams.
Memory Usage: 20.8 MB, less than 31.34% of C++ online submissions for Group Anagrams.*/
vector<vector<string>> groupAnagrams2(vector<string>& strs) {
vector<vector<string> > res;
unordered_map<string,int> mp;
for(int i=0;i<strs.size();i++){
vector<int> tmp(26);
for(int j=0;j<strs[i].size();j++){
tmp[strs[i][j]-'a']++;
}
string st="";
for(int j=0;j<26;j++){
if(tmp[j]==0) continue;
st+=string(1,'a'+j)+to_string(tmp[j]);
}
if(mp.find(st)!=mp.end()){
res[mp[st]].push_back(strs[i]);
}else{
int size=mp.size();
mp[st]=size;
res.push_back({strs[i]});
}
}
return res;
}
/*3.改变2中map的对应关系
Runtime: 68 ms, faster than 20.60% of C++ online submissions for Group Anagrams.
Memory Usage: 22.1 MB, less than 23.88% of C++ online submissions for Group Anagrams.*/
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string> > res;
unordered_map<string,vector<string> > mp;
for(int i=0;i<strs.size();i++){
vector<int> tmp(26);
for(int j=0;j<strs[i].size();j++) tmp[strs[i][j]-'a']++;
string st="";
for(int j=0;j<26;j++){
if(tmp[j]==0) continue;
st+=string(1,j+'a')+to_string(tmp[j]);
}
mp[st].push_back(strs[i]);
}
for(auto &a:mp){
res.push_back(a.second);
}
return res;
}
};328. Odd Even Linked List
Medium
1244269Add to ListShare
Given a singly linked list, group all odd nodes together followed by the even nodes. Please note here we are talking about the node number and not the value in the nodes.
You should try to do it in place. The program should run in O(1) space complexity and O(nodes) time complexity.
Example 1:
Input: 1->2->3->4->5->NULL
Output: 1->3->5->2->4->NULLExample 2:
Input: 2->1->3->5->6->4->7->NULL
Output: 2->3->6->7->1->5->4->NULL
Note:
- The relative order inside both the even and odd groups should remain as it was in the input.
- The first node is considered odd, the second node even and so on ...
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
/*奇数位的node,后面接上偶数位的node
1.统一的num,遇到奇数位和偶数位分别处理,设置奇数位头尾、偶数位头尾指针
Runtime: 20 ms, faster than 58.98% of C++ online submissions for Odd Even Linked List.
Memory Usage: 9.9 MB, less than 8.57% of C++ online submissions for Odd Even Linked List.*/
ListNode* oddEvenList1(ListNode* head) {
if(head==NULL || head->next==NULL) return head;
ListNode *oddhead=head,*oddtail=head,*evenhead=head->next,*eventail=head->next;
int num=1;
while(head!=NULL){
if(num%2==1){
if(oddhead!=head){
oddtail->next=head;
oddtail=oddtail->next;
}
}else{
if(evenhead!=head){
eventail->next=head;
eventail=eventail->next;
}
}
head=head->next;
num++;
}
oddtail->next=evenhead;
eventail->next=NULL;
return oddhead;
}
/*2.使用两个指针,pre指向奇节点,cur指向偶节点,
把偶节点cur后面的那个奇节点提前到pre的后面,然后pre和cur各自向前一步,
此时cur又指向偶节点,pre指向当前奇节点的末尾
Runtime: 16 ms, faster than 93.64% of C++ online submissions for Odd Even Linked List.
Memory Usage: 10.1 MB, less than 8.57% of C++ online submissions for Odd Even Linked List.*/
ListNode* oddEvenList(ListNode* head) {
if(head==NULL || head->next==NULL) return head;
ListNode *pre=head,*cur=head->next;
while(cur && cur->next){
ListNode *tmp=pre->next;
pre->next=cur->next;
cur->next=cur->next->next;
pre->next->next=tmp;
cur=cur->next;
pre=pre->next;
}
return head;
}
};725. Split Linked List in Parts
Medium
511102Add to ListShare
Given a (singly) linked list with head node root, write a function to split the linked list into k consecutive linked list "parts".
The length of each part should be as equal as possible: no two parts should have a size differing by more than 1. This may lead to some parts being null.
The parts should be in order of occurrence in the input list, and parts occurring earlier should always have a size greater than or equal parts occurring later.
Return a List of ListNode's representing the linked list parts that are formed.
Examples 1->2->3->4, k = 5 // 5 equal parts [ [1], [2], [3], [4], null ]
Example 1:
Input:
root = [1, 2, 3], k = 5
Output: [[1],[2],[3],[],[]]
Explanation:
The input and each element of the output are ListNodes, not arrays.
For example, the input root has root.val = 1, root.next.val = 2, \root.next.next.val = 3, and root.next.next.next = null.
The first element output[0] has output[0].val = 1, output[0].next = null.
The last element output[4] is null, but it's string representation as a ListNode is [].
Example 2:
Input:
root = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], k = 3
Output: [[1, 2, 3, 4], [5, 6, 7], [8, 9, 10]]
Explanation:
The input has been split into consecutive parts with size difference at most 1, and earlier parts are a larger size than the later parts.
Note:
- The length of
rootwill be in the range[0, 1000]. - Each value of a node in the input will be an integer in the range
[0, 999]. kwill be an integer in the range[1, 50].
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
/*1.使用数组记录每个段的节点长度。
Runtime: 12 ms, faster than 75.13% of C++ online submissions for Split Linked List in Parts.
Memory Usage: 9.3 MB, less than 90.91% of C++ online submissions for Split Linked List in Parts.*/
vector<ListNode*> splitListToParts1(ListNode* root, int k) {
vector<int> lenth(k);
vector<ListNode*> res;
int len=0;
ListNode *tmp=root;
while(tmp){
len++;tmp=tmp->next;
}
int n1=len/k;
int i=0;
if(n1==0){//len<k
while(len){
lenth[i++]=1;len--;
}
}else{
while (k) {
lenth[--k] = n1;len -= n1;
if (k != 0) n1 = len /k;
else n1 = len;
}
}
i=0;
while(root){
res.push_back(root);
while(lenth[i]--){
if(lenth[i]==0){
ListNode *tmp=root->next;
root->next=NULL;root=tmp;
}
else root=root->next;
}
i++;
}
while(i<k){
res.push_back({});i++;
}
return res;
}
/*2.首先统计链表中节点总个数,然后除以k,
得到的商avg就是能分成的部分的个数,余数ext就是包含有多余节点的子链表的个数。
Runtime: 8 ms, faster than 98.07% of C++ online submissions for Split Linked List in Parts.
Memory Usage: 9.2 MB, less than 100.00% of C++ online submissions for Split Linked List in Parts.*/
vector<ListNode*> splitListToParts(ListNode* root, int k) {
vector<ListNode *> res(k);
int len=0;
ListNode *tmp=root;
while(tmp){
len++;tmp=tmp->next;
}
int avg=len/k,ext=len%k;
for(int i=0;i<k && root;i++){
res[i]=root;
for(int j=1;j<avg+(i<ext);j++) root=root->next;
ListNode *tmp=root->next;
root->next=NULL;
root=tmp;
}
return res;
}
};61. Rotate List
Medium
923956Add to ListShare
Given a linked list, rotate the list to the right by k places, where k is non-negative.
Example 1:
Input: 1->2->3->4->5->NULL, k = 2
Output: 4->5->1->2->3->NULL
Explanation:
rotate 1 steps to the right: 5->1->2->3->4->NULL
rotate 2 steps to the right: 4->5->1->2->3->NULL
Example 2:
Input: 0->1->2->NULL, k = 4
Output: 2->0->1->NULL
Explanation:
rotate 1 steps to the right: 2->0->1->NULL
rotate 2 steps to the right: 1->2->0->NULL
rotate 3 steps to the right: 0->1->2->NULL
rotate 4 steps to the right: 2->0->1->NULL/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
/*Runtime: 8 ms, faster than 93.20% of C++ online submissions for Rotate List.
Memory Usage: 8.7 MB, less than 100.00% of C++ online submissions for Rotate List.*/
ListNode* rotateRight(ListNode* head, int k) {
if(k==0) return head;
int len=0;
ListNode *tmp=head;
while(tmp){
len++;tmp=tmp->next;
}
if(len==0) return head;
len=k%len;
if(len==0) return head;
tmp=head;
for(int i=0;i<len;i++) tmp=tmp->next;
ListNode *headd=head,*pre=tmp,*pree=headd;
while(tmp){
pre=tmp;
pree=headd;
tmp=tmp->next;
headd=headd->next;
}
pre->next=head;
pree->next=NULL;
return headd;
}
};24. Swap Nodes in Pairs
Medium
1801154Add to ListShare
Given a linked list, swap every two adjacent nodes and return its head.
You may not modify the values in the list's nodes, only nodes itself may be changed.
Example:
Given 1->2->3->4, you should return the list as 2->1->4->3./**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
/*交换相邻的节点,不能直接交换值
Runtime: 0 ms, faster than 100.00% of C++ online submissions for Swap Nodes in Pairs.
Memory Usage: 8.2 MB, less than 100.00% of C++ online submissions for Swap Nodes in Pairs.*/
ListNode* swapPairs(ListNode* head) {
if(head==NULL || head->next==NULL) return head;
ListNode *p1=head,*p2=head->next,*last=p1;
head=p2;
while(p1 && p2){
ListNode *q=p2->next;
p1->next=q;
p2->next=p1;
if(last!=p1){last->next=p2;last=p1;}
if(q){p1=q;p2=q->next;}
else break;
}
return head;
}
};11. Container With Most Water
Medium
5019524Add to ListShare
Given n non-negative integers a1, a2, ..., an , where each represents a point at coordinate (i, ai). n vertical lines are drawn such that the two endpoints of line i is at (i, ai) and (i, 0). Find two lines, which together with x-axis forms a container, such that the container contains the most water.
Note: You may not slant the container and n is at least 2.

The above vertical lines are represented by array [1,8,6,2,5,4,8,3,7]. In this case, the max area of water (blue section) the container can contain is 49.
Example:
Input: [1,8,6,2,5,4,8,3,7]
Output: 49class Solution {
public:
/*1.维护左右两个指针
if height[i]<height[j] i++;
else j--;
Runtime: 16 ms, faster than 96.33% of C++ online submissions for Container With Most Water.
Memory Usage: 8.8 MB, less than 100.00% of C++ online submissions for Container With Most Water.*/
int maxArea1(vector<int>& height) {
int left=0,right=height.size()-1;
int maxx=0;
while(left<right){
maxx=max(maxx,min(height[left],height[right])*(right-left));
height[left]<height[right]?left++:right--;
}
return maxx;
}
/*2.对于1有小幅优化,如果遇上一个高度相同,直接移动left或right,不用再次计算
Runtime: 16 ms, faster than 96.33% of C++ online submissions for Container With Most Water.
Memory Usage: 9.2 MB, less than 100.00% of C++ online submissions for Container With Most Water.*/
int maxArea(vector<int>& height) {
int left=0,right=height.size()-1;
int maxx=0;
while(left<right){
int minn=min(height[left],height[right]);
maxx=max(maxx,minn*(right-left));
while(left<right && minn==height[left]) left++;
while(left<right && minn==height[right]) right--;
}
return maxx;
}
};36. Valid Sudoku
Medium
1300416Add to ListShare
Determine if a 9x9 Sudoku board is valid. Only the filled cells need to be validated according to the following rules:
- Each row must contain the digits
1-9without repetition. - Each column must contain the digits
1-9without repetition. - Each of the 9
3x3sub-boxes of the grid must contain the digits1-9without repetition.

A partially filled sudoku which is valid.
The Sudoku board could be partially filled, where empty cells are filled with the character '.'.
Example 1:
Input:
[
["5","3",".",".","7",".",".",".","."],
["6",".",".","1","9","5",".",".","."],
[".","9","8",".",".",".",".","6","."],
["8",".",".",".","6",".",".",".","3"],
["4",".",".","8",".","3",".",".","1"],
["7",".",".",".","2",".",".",".","6"],
[".","6",".",".",".",".","2","8","."],
[".",".",".","4","1","9",".",".","5"],
[".",".",".",".","8",".",".","7","9"]
]
Output: true
Example 2:
Input:
[
["8","3",".",".","7",".",".",".","."],
["6",".",".","1","9","5",".",".","."],
[".","9","8",".",".",".",".","6","."],
["8",".",".",".","6",".",".",".","3"],
["4",".",".","8",".","3",".",".","1"],
["7",".",".",".","2",".",".",".","6"],
[".","6",".",".",".",".","2","8","."],
[".",".",".","4","1","9",".",".","5"],
[".",".",".",".","8",".",".","7","9"]
]
Output: false
Explanation: Same as Example 1, except with the 5 in the top left corner being
modified to 8. Since there are two 8's in the top left 3x3 sub-box, it is invalid.
Note:
- A Sudoku board (partially filled) could be valid but is not necessarily solvable.
- Only the filled cells need to be validated according to the mentioned rules.
- The given board contain only digits
1-9and the character'.'. - The given board size is always
9x9.
class Solution {
public:
/*判断数独棋盘是否有效,而不是判断是否有结果
1.3*3、各行、各列,分别判断
Runtime: 12 ms, faster than 90.83% of C++ online submissions for Valid Sudoku.
Memory Usage: 10.1 MB, less than 56.41% of C++ online submissions for Valid Sudoku.*/
bool isValidSudoku1(vector<vector<char>>& board) {
vector<vector<int> > tmp={{0,0},{0,1},{0,2},{1,0},{1,1},{1,2},{2,0},{2,1},{2,2}};
for(int i=0;i<9;i+=3){
for(int j=0;j<9;j+=3){
vector<int> num(10);
/*[i][j],[i][j+1],[i][j+2]
[i+1][j],[i+1][j+1],[i+1][j+2]
[i+2][j],[i+2][j+1],[i+2][j+2]*/
for(int k=0;k<9;k++){
if(board[i+tmp[k][0]][j+tmp[k][1]]!='.'){
num[board[i+tmp[k][0]][j+tmp[k][1]]-'0']++;
if(num[board[i+tmp[k][0]][j+tmp[k][1]]-'0']>1) return false;
}
}
}
}
for(int i=0;i<9;i++){
vector<int> num(10);
for(int j=0;j<9;j++){
if(board[i][j]!='.'){
num[board[i][j]-'0']++;
if(num[board[i][j]-'0']>1) return false;
}
}
}
for(int j=0;j<9;j++){
vector<int> num(10);
for(int i=0;i<9;i++){
if(board[i][j]!='.'){
num[board[i][j]-'0']++;
if(num[board[i][j]-'0']>1) return false;
}
}
}
return true;
}
/*2.三个9*9大小的boolean数组,判断各行、各列、各3*3小矩阵中是否有遍历到的该值
Runtime: 20 ms, faster than 37.18% of C++ online submissions for Valid Sudoku.
Memory Usage: 10 MB, less than 56.41% of C++ online submissions for Valid Sudoku.*/
bool isValidSudoku2(vector<vector<char>>& board) {
vector<vector<bool> > row(9,vector<bool>(9));
vector<vector<bool> > col(9,vector<bool>(9));
vector<vector<bool> > mat(9,vector<bool>(9));//9个3*3小矩阵
for(int i=0;i<9;i++){
for(int j=0;j<9;j++){
if(board[i][j]=='.') continue;
int c=board[i][j]-'1';
if(row[i][c] || col[c][j] || mat[3*(i/3)+(j/3)][c]) return false;
row[i][c]=true;
col[c][j]=true;
mat[3*(i/3)+(j/3)][c]=true;
}
}
return true;
}
/*3.空间优化
只使用一个hashset来记录已经存在过的状态,将每个状态编码成为一个字符串,
对于每个1-9内的数组来说,它在每行、每列、每个小区间内都是唯一的,
每个小区间内的数字就将在小区间内的行列数分别放在括号的左右两边,
这样,每个数字的状态都是独一无二的,就可以在hashset中查找是否有重复存在。
Runtime: 24 ms, faster than 18.03% of C++ online submissions for Valid Sudoku.
Memory Usage: 10.6 MB, less than 51.28% of C++ online submissions for Valid Sudoku.*/
bool isValidSudoku(vector<vector<char>>& board) {
unordered_set<string> st;
for(int i=0;i<9;i++){
for(int j=0;j<9;j++){
if(board[i][j]=='.') continue;
string t="("+to_string(board[i][j]-'1')+")";
string row=to_string(i)+t;
string col=t+to_string(j);
string mat=to_string(i/3)+t+to_string(j/3);
//cout<<t<<" "<<row<<" "<<col<<" "<<mat<<endl;
if(st.count(row) || st.count(col) || st.count(mat)) return false;
st.insert(row);st.insert(col);st.insert(mat);
}
}
return true;
}
};并查集:
547. Friend Circles
Medium
1514118Add to ListShare
There are N students in a class. Some of them are friends, while some are not. Their friendship is transitive in nature. For example, if A is a direct friend of B, and B is a direct friend of C, then A is an indirect friend of C. And we defined a friend circle is a group of students who are direct or indirect friends.
Given a N*N matrix M representing the friend relationship between students in the class. If M[i][j] = 1, then the ith and jth students are direct friends with each other, otherwise not. And you have to output the total number of friend circles among all the students.
Example 1:
Input:
[[1,1,0],
[1,1,0],
[0,0,1]]
Output: 2
Explanation:The 0th and 1st students are direct friends, so they are in a friend circle.
The 2nd student himself is in a friend circle. So return 2.
Example 2:
Input:
[[1,1,0],
[1,1,1],
[0,1,1]]
Output: 1
Explanation:The 0th and 1st students are direct friends, the 1st and 2nd students are direct friends,
so the 0th and 2nd students are indirect friends. All of them are in the same friend circle, so return 1.
Note:
- N is in range [1,200].
- M[i][i] = 1 for all students.
- If M[i][j] = 1, then M[j][i] = 1.
/*1.DFS:对于某个人,将他的所有朋友都遍历一遍,对于没有遍历到的人再找他朋友圈的人。
Runtime: 20 ms, faster than 84.81% of C++ online submissions for Friend Circles.
Memory Usage: 10 MB, less than 100.00% of C++ online submissions for Friend Circles.*/
void DFS(vector<vector<int> > &M, int k, vector<int> &vis) {
vis[k] = 1;
for (int i = 0; i < M.size(); i++) {
if (M[k][i] == 0 || vis[i] == 1) continue;
DFS(M, i, vis);
}
}
int findCircleNum1(vector<vector<int>>& M) {
int n = M.size(), res = 0;
vector<int> vis(n);
for (int i = 0; i < n; i++) {
if (vis[i] == 1) continue;
DFS(M, i, vis);
res++;
}
return res;
}
/*2.BFS
Runtime: 24 ms, faster than 48.86% of C++ online submissions for Friend Circles.
Memory Usage: 10.2 MB, less than 100.00% of C++ online submissions for Friend Circles.*/
int findCircleNum2(vector<vector<int>>& M) {
vector<int> vis(M.size());
queue<int> q;
int res = 0;
for (int i = 0; i < M.size(); i++) {
if (vis[i] == 1) continue;
q.push(i);
while (!q.empty()) {
int t = q.front(); q.pop();
vis[t] = 1;
for (int j = 0; j < n; j++) {
if (M[t][j] == 1 && vis[j] == 0) q.push(j);
}
}
res++;
}
return res;
}
/*3.并查集,Union Find,
再初始时为每一个对象都赋上不同的标签,然后对属于同一类的对象,在root中查找标签,
如果标签不同,则将其中一个对象的标签赋值给另一个对象,root数组中的数字和数字的坐标有很大关系
root存的是属于同一组的另一个对象的坐标,这样,通过getRoot函数就可以使同一组的对象返回相同值
Runtime: 20 ms, faster than 84.81% of C++ online submissions for Friend Circles.
Memory Usage: 9.9 MB, less than 100.00% of C++ online submissions for Friend Circles.*/
int getRoot(vector<int> &root, int i) {
while (i != root[i]) {
root[i] = root[root[i]];
i = root[i];
}
return i;
}
int findCircleNum(vector<vector<int>>& M) {
int n = M.size(), res = n;
vector<int> root(n);
for (int i = 0; i < n; i++) root[i] = i;
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
if (M[i][j] == 1) {
int p1 = getRoot(root, i);
int p2 = getRoot(root, j);
if (p1 != p2) {
res--;
root[p2] = p1;
}
}
}
}
return res;
}P1551 亲戚
题目背景
若某个家族人员过于庞大,要判断两个是否是亲戚,确实还很不容易,现在给出某个亲戚关系图,求任意给出的两个人是否具有亲戚关系。
题目描述
规定:x和y是亲戚,y和z是亲戚,那么x和z也是亲戚。如果x,y是亲戚,那么x的亲戚都是y的亲戚,y的亲戚也都是x的亲戚。
输入格式
第一行:三个整数n,m,p,(n<=5000,m<=5000,p<=5000),分别表示有n个人,m个亲戚关系,询问p对亲戚关系。
以下m行:每行两个数Mi,Mj,1<=Mi,Mj<=N,表示Mi和Mj具有亲戚关系。
接下来p行:每行两个数Pi,Pj,询问Pi和Pj是否具有亲戚关系。
输出格式
P行,每行一个’Yes’或’No’。表示第i个询问的答案为“具有”或“不具有”亲戚关系。
输入输出样例
输入 #1
6 5 3
1 2
1 5
3 4
5 2
1 3
1 4
2 3
5 6输出 #1
Yes
Yes
No#include"pch.h"
#include<iostream>
#include<vector>
using namespace std;
int getRoot(vector<int> &root,int x) {
while (x != root[x]) {
root[x] = root[root[x]];
x = root[x];
}
return x;
}
void makeRoot(int x, int y, vector<int> &root) {
int p1 = getRoot(root, x), p2 = getRoot(root, y);
if ( p1 != p2) root[p1] = p2;
}
int main() {
int n, m, p;
cin >> n >> m >> p;
vector<int> root(n+1);
for (int i = 0; i <= n; i++) root[i] = i;
for (int i = 0; i < m; i++) {
int a, b;
cin >> a >> b;
makeRoot(a, b, root);
}
for (int i = 0; i < p; i++) {
int a, b;
cin >> a >> b;
if (getRoot(root,a) != getRoot(root,b)) cout << "No" << endl;
else cout << "Yes" << endl;
}
return 0;
}684. Redundant Connection
In this problem, a tree is an undirected graph that is connected and has no cycles.
The given input is a graph that started as a tree with N nodes (with distinct values 1, 2, ..., N), with one additional edge added. The added edge has two different vertices chosen from 1 to N, and was not an edge that already existed.
The resulting graph is given as a 2D-array of edges. Each element of edges is a pair [u, v] with u < v, that represents an undirected edge connecting nodes u and v.
Return an edge that can be removed so that the resulting graph is a tree of N nodes. If there are multiple answers, return the answer that occurs last in the given 2D-array. The answer edge [u, v] should be in the same format, with u < v.
Example 1:
Input: [[1,2], [1,3], [2,3]]
Output: [2,3]
Explanation: The given undirected graph will be like this:
1
/ \
2 - 3
Example 2:
Input: [[1,2], [2,3], [3,4], [1,4], [1,5]]
Output: [1,4]
Explanation: The given undirected graph will be like this:
5 - 1 - 2
| |
4 - 3
Note:
- The size of the input 2D-array will be between 3 and 1000.
- Every integer represented in the 2D-array will be between 1 and N, where N is the size of the input array.
Update (2017-09-26):
We have overhauled the problem description + test cases and specified clearly the graph is an undirected graph. For the directed graph follow up please see Redundant Connection II). We apologize for any inconvenience caused.
/*684. Redundant Connection
删掉一个边,使之成为一个树
1.无向图,邻接表,每加入一条边,就判断是否形成环,DFS,超时!!!*/
bool hascycle(int cur, int target, unordered_map<int, unordered_set<int> > mp, int pre) {
if (mp[cur].count(target) != 0) return true;
for (auto a : mp[cur]) {
if (a == pre) continue;
if (hascycle(a, target, mp, cur)) return true;
}
return false;
}
vector<int> findRedundantConnection1(vector<vector<int>>& edges) {
unordered_map<int, unordered_set<int> > mp;
for (auto a : edges) {
if (hascycle(a[0], a[1], mp, -1)) return { a[0],a[1] };
mp[a[0]].insert(a[1]);
mp[a[1]].insert(a[0]);
}
return {};
}
/*2.上述递归能做,迭代也能做,BFS,使用一个集合来记录遍历过的节点
Runtime: 44 ms, faster than 5.86% of C++ online submissions for Redundant Connection.
Memory Usage: 23.9 MB, less than 5.88% of C++ online submissions for Redundant Connection.*/
vector<int> findRedundantConnection2(vector<vector<int>>& edges) {
unordered_map<int, unordered_set<int> > mp;
for (auto a : edges) {
queue<int> q{ {a[0]} };
unordered_set<int> s;
while (!q.empty()) {
int t = q.front(); q.pop();
if (mp[t].count(a[1]) != 0) return a;
for (int num : mp[t]) {
if (s.count(num)) continue;
q.push(num); s.insert(num);
}
}
mp[a[0]].insert(a[1]);
mp[a[1]].insert(a[0]);
}
return {};
}
/*3.并查集,首先建立一个长度为n+1的数组root,
开始每个节点都是一个单独的组,union find就是让节点之间建立关联
如果root[1]=2,就表示节点1和节点2是相连的,
如果root[2]=3,就表示节点2和节点3是相连的,
此时如果新增一条[1,3],我们通过root[1]=2找到2,
再通过root[2]=3找到3,说明节点1有另一条通道能找到3,说明环存在
如果没有这条路径,就要将节点1,3关联起来,即root[1]=3
Runtime: 8 ms, faster than 78.54% of C++ online submissions for Redundant Connection.
Memory Usage: 9.9 MB, less than 76.47% of C++ online submissions for Redundant Connection.*/
int getRoot(vector<int> &root, int i) {
while ( root[i]!=-1) {
i = root[i];
}
return i;
}
vector<int> findRedundantConnection(vector<vector<int>>& edges) {
vector<int> root(2001,-1);
for (auto a : edges) {
int p1 = getRoot(root, a[0]), p2 = getRoot(root, a[1]);
if (p1 == p2) return a;
root[p1] = p2;
}
return {};
}685. Redundant Connection II
Hard
627187Add to ListShare
In this problem, a rooted tree is a directed graph such that, there is exactly one node (the root) for which all other nodes are descendants of this node, plus every node has exactly one parent, except for the root node which has no parents.
The given input is a directed graph that started as a rooted tree with N nodes (with distinct values 1, 2, ..., N), with one additional directed edge added. The added edge has two different vertices chosen from 1 to N, and was not an edge that already existed.
The resulting graph is given as a 2D-array of edges. Each element of edges is a pair [u, v] that represents a directed edge connecting nodes u and v, where u is a parent of child v.
Return an edge that can be removed so that the resulting graph is a rooted tree of N nodes. If there are multiple answers, return the answer that occurs last in the given 2D-array.
Example 1:
Input: [[1,2], [1,3], [2,3]]
Output: [2,3]
Explanation: The given directed graph will be like this:
1
/ \
v v
2-->3
Example 2:
Input: [[1,2], [2,3], [3,4], [4,1], [1,5]]
Output: [4,1]
Explanation: The given directed graph will be like this:
5 <- 1 -> 2
^ |
| v
4 <- 3
Note:
- The size of the input 2D-array will be between 3 and 1000.
- Every integer represented in the 2D-array will be between 1 and N, where N is the size of the input array.
/*1.有向图
(1)无环,但是有入度为2的节点,返回产生入度为2的后加入的那条边
(2)有环,没有入度为2的节点,返回刚好组成环的最后加入的那条边
(3)有环,有入度为2的节点,返回组成环,且组成入度为2的那条边
入度为2:有两个parent
先找入度为2的点,如果有的话,那么,将当前产生入度为2的后加入的那条边,标记为second
前一条边标记为first,然后来找环,找环使用union find方法。
找到环后,如果first不存在,说明是第二种情况,返回刚好组成环的最后加入的那条边。
如果first存在,说明是第三种情况,返回first。
如果没有环,说明是第一种情况,返回second。
Runtime: 4 ms, faster than 98.85% of C++ online submissions for Redundant Connection II.
Memory Usage: 9.2 MB, less than 100.00% of C++ online submissions for Redundant Connection II.*/
int getRoot(vector<int> &root, int i) {
while (i != root[i]) {
root[i] = root[root[i]];
i = root[i];
}
return i;
}
vector<int> findRedundantDirectedConnection(vector<vector<int>>& edges) {
int n = edges.size();
vector<int> root(n + 1, 0), first, second;
for (auto &edge : edges) {
if (root[edge[1]] == 0) root[edge[1]] = edge[0];//更新root
else {//root[edge[1]]!=0,说明edge[1]曾经出现在另一条边尾,入度为2
first = { root[edge[1]],edge[1] };//入度为2的这条边
second = edge;//
edge[1] = 0;
}
}
for (int i = 0; i <= n; i++) root[i] = i;
for (auto &edge : edges) {
if (edge[1] == 0) continue;
int x = getRoot(root, edge[0]), y = getRoot(root, edge[1]);
if (x == y) return first.empty() ? edge : first;
root[x] = y;
}
return second;
}
/*2.有向图,删除一个形成树。一样的思路:
Runtime: 4 ms, faster than 98.85% of C++ online submissions for Redundant Connection II.
Memory Usage: 9.2 MB, less than 100.00% of C++ online submissions for Redundant Connection II.*/
vector<int> findRedundantDirectedConnection(vector<vector<int>>& edges) {
vector<int> parents(edges.size() + 1, 0);//存储每个顶点的parents是谁
vector<int> root(edges.size() + 1, 0);//
vector<int> size(edges.size() + 1, 1);//
vector<int> ans1,ans2;
//如果发现有顶点有两个parent,ans1和ans2分别指向这个顶点的两条边
//最后一定要删除ans1或ans2里面的边,如果不删除就会有有两个parent的边,是不合法的tree
for (auto &edge : edges) {//判断parent个数
int u = edge[0], v = edge[1];
if (parents[v] > 0) {//已经有过parent了
ans1 = { parents[v],v };
//当前节点v有两个parents,其中一个是之前存入的{parents[v],v}
ans2 = edge;//另一个是当前遍历到的边
edge[0] = edge[1] = -1;
//先将这条边删除
}
parents[v] = u;//跟踪一下每个节点的parent分别是谁
}
//查找环
for (auto &edge : edges) {
int u = edge[0], v = edge[1];
if(u < 0 || v < 0) continue;
//先跳过不合法的边,之前被删除了
if (root[u] == 0) root[u] = u;
if (root[v] == 0) root[v] = v;
int p1 = getRoot(root, u), p2 = getRoot(root, v);
if (p1 == p2) {
if (ans1.empty()) return edge;
//ans1为空,说明没有重复的parents,返回这条边
else return ans1;
//否则,返回那条入度为2的边
//因为之前已经把入度为2的顶点的第二条边删除了,
//所以如果构成环,那么一定是由第一条边引起的,所以返回第一条边
}
if (size[p1] < size[p2]) swap(p1, p2);
root[p2] = p1;
size[p1] += size[p2];
}
return ans2;
}261. Graph Valid Tree
Given n nodes labeled from 0 to n - 1 and a list of undirected edges (each edge is a pair of nodes), write a function to check whether these edges make up a valid tree.
For example:
Given n = 5 and edges = [[0, 1], [0, 2], [0, 3], [1, 4]], return true.
Given n = 5 and edges = [[0, 1], [1, 2], [2, 3], [1, 3], [1, 4]], return false.
Hint:
- Given
n = 5andedges = [[0, 1], [1, 2], [3, 4]], what should your return? Is this case a valid tree? - According to the definition of tree on Wikipedia: “a tree is an undirected graph in which any two vertices are connected by exactly one path. In other words, any connected graph without simple cycles is a tree.”
Note: you can assume that no duplicate edges will appear in edges. Since all edges are undirected, [0, 1] is the same as [1, 0] and thus will not appear together in edges.
/*验证一个图是否是一棵树
1.DFS*/
bool hascycle(int cur, int tar, unordered_map<int, unordered_set<int> > mp, int pre) {
if (mp[cur].count(tar) != 0) return true;
for (auto a : mp[cur]) {
if (a == pre) continue;
if(hascycle(a, tar, mp, cur)) return true;
}
return false;
}
bool validTree1(int n, vector<pair<int, int>>& edges) {
unordered_map<int, unordered_set<int> > mp;
for (auto a : edges) {
if (hascycle(a.first, a.second, mp, -1)) return false;
mp[a.first].insert(a.second);
mp[a.second].insert(a.first);
}
return true;
}
/*2.BFS*/
bool validTree2(int n, vector<pair<int, int>>& edges) {
vector<unordered_set<int> > g(n, unordered_set<int>());
unordered_set<int> s{ {0} };
queue<int> q{ {0} };
for (auto a : edges) {
g[a.first].insert(a.second);
g[a.second].insert(a.first);
}
while (!q.empty()) {
int t = q.front(); q.pop();
for (auto a : g[t]) {
if (s.count(a)) return false;
s.insert(a);
q.push(a);
g[a].erase(t);
}
}
return s.size() == n;
}
/*3.并查集*/
int getRoot(vector<int> &root, int i) {
while ( root[i]!=i) {
root[i]=root[root[i]];
i = root[i];
}
return i;
}
vector<int> findRedundantConnection(vector<vector<int>>& edges) {
vector<int> root(2001);
for(int i=0;i<2001;i++) root[i]=i;
for (auto a : edges) {
int p1 = getRoot(root, a[0]), p2 = getRoot(root, a[1]);
if (p1 == p2) return a;
root[p1] = p2;
}
return {};
}721. Accounts Merge
Medium
1044254Add to ListShare
Given a list accounts, each element accounts[i] is a list of strings, where the first element accounts[i][0] is a name, and the rest of the elements are emails representing emails of the account.
Now, we would like to merge these accounts. Two accounts definitely belong to the same person if there is some email that is common to both accounts. Note that even if two accounts have the same name, they may belong to different people as people could have the same name. A person can have any number of accounts initially, but all of their accounts definitely have the same name.
After merging the accounts, return the accounts in the following format: the first element of each account is the name, and the rest of the elements are emails in sorted order. The accounts themselves can be returned in any order.
Example 1:
Input:
accounts = [["John", "johnsmith@mail.com", "john00@mail.com"], ["John", "johnnybravo@mail.com"], ["John", "johnsmith@mail.com", "john_newyork@mail.com"], ["Mary", "mary@mail.com"]]
Output: [["John", 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com'], ["John", "johnnybravo@mail.com"], ["Mary", "mary@mail.com"]]
Explanation:
The first and third John's are the same person as they have the common email "johnsmith@mail.com".
The second John and Mary are different people as none of their email addresses are used by other accounts.
We could return these lists in any order, for example the answer [['Mary', 'mary@mail.com'], ['John', 'johnnybravo@mail.com'],
['John', 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com']] would still be accepted.
Note:
- The length of
accountswill be in the range[1, 1000]. - The length of
accounts[i]will be in the range[1, 10]. - The length of
accounts[i][j]will be in the range[1, 30].
/*721. Accounts Merge
1.并查集
使用root数组,每个点开始初始化为不同的值,如果两个点属于同一个组,
就将其中一个点的root值赋给另一个点的值,这样只要是相同组里的两个点,
通过find函数得到相同的值。由于邮件是字符串,不是数字,所以root可以用hashmap代替,
还需要一个hashmap映射owner,建立每个邮箱和其所有者姓名的映射,
另外一个hashmap建立用户和其所有邮箱的映射
Runtime: 176 ms, faster than 47.52% of C++ online submissions for Accounts Merge.
Memory Usage: 54.6 MB, less than 23.53% of C++ online submissions for Accounts Merge.*/
string getRoot(unordered_map<string, string> &root, string s) {
while (root[s] != s) {
root[s] = root[root[s]];
s = root[s];
}
return s;
}
vector<vector<string>> accountsMerge(vector<vector<string>>& accounts) {
unordered_map<string, string> root;
unordered_map<string, string> owner;
unordered_map<string, set<string> > mp;
vector<vector<string> > res;
for (auto a : accounts) {
string name = a[0];
for (int i = 1; i < a.size(); i++) {
root[a[i]] = a[i];
owner[a[i]] = name;
}
}
for (auto a : accounts) {
string p = getRoot(root, a[1]);
for (int i = 2; i < a.size(); i++) {
root[getRoot(root, a[i])] = p;
}
}
for (auto a : accounts) {
for (int i = 1; i < a.size(); i++) {
mp[getRoot(root, a[i])].insert(a[i]);
}
}
for (auto a : mp) {
vector<string> v(a.second.begin(), a.second.end());
v.insert(v.begin(), owner[a.first]);
res.push_back(v);
}
return res;
}
/*2.BFS
建立每个邮箱和所有出现的账户数组之间的映射
还需要一个visited数组,用来标记某个账户是否已经被遍历过,
建立好hashmap之后,遍历所有账户,如果账户没有被访问过,将其加入队列queue,
新建一个treeset,当队不为空时,取出队首,将该账户标记已访问,
队空后,当前账户的所有合并后的邮箱都保存在treeset中,转化为字符串数组,
在首部加上用户名,最后将结果加入res
Runtime: 120 ms, faster than 78.27% of C++ online submissions for Accounts Merge.
Memory Usage: 39.1 MB, less than 47.06% of C++ online submissions for Accounts Merge.*/
vector<vector<string> > accountsMerge(vector<vector<string> > &accounts) {
vector<vector<string> > res;
int n = accounts.size();
unordered_map<string, vector<int> > mp;
vector<int> vis(n);
for (int i = 0; i < n; i++) {
for (int j = 1; j < accounts[i].size(); j++) {
mp[accounts[i][j]].push_back(i);//邮箱与用户
}
}
for (int i = 0; i < n; i++) {
if (vis[i] != 0) continue;//第i个用户与邮箱的对应数组
queue<int> q{ {i} };
set<string> s;
while (!q.empty()) {
int t = q.front(); q.pop();
vis[i] = 1;
vector<string> mails(accounts[t].begin() + 1, accounts[t].end());
for (string mail : mails) {//第i个数组中的各个邮箱
s.insert(mail);
for (int user : mp[mail]) {//根据邮箱找到对应的用户
if (vis[user] != 0) continue;
q.push(user);
vis[user] = 1;
}
}
}
vector<string> out(s.begin(), s.end());
out.insert(out.begin(), accounts[i][0]);
res.push_back(out);
}
return res;
}1319. Number of Operations to Make Network Connected
Medium
1973Add to ListShare
There are n computers numbered from 0 to n-1 connected by ethernet cables connections forming a network where connections[i] = [a, b] represents a connection between computers a and b. Any computer can reach any other computer directly or indirectly through the network.
Given an initial computer network connections. You can extract certain cables between two directly connected computers, and place them between any pair of disconnected computers to make them directly connected. Return the minimum number of times you need to do this in order to make all the computers connected. If it's not possible, return -1.
Example 1:

Input: n = 4, connections = [[0,1],[0,2],[1,2]]
Output: 1
Explanation: Remove cable between computer 1 and 2 and place between computers 1 and 3.
Example 2:
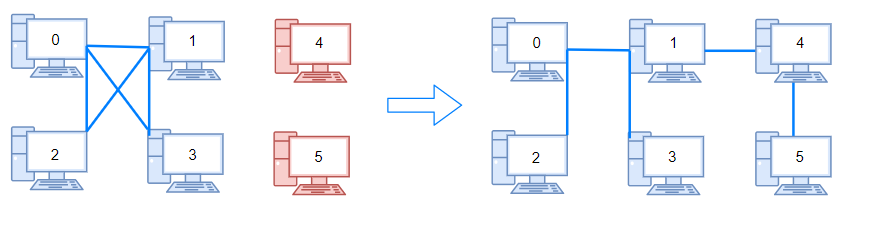
Input: n = 6, connections = [[0,1],[0,2],[0,3],[1,2],[1,3]]
Output: 2
Example 3:
Input: n = 6, connections = [[0,1],[0,2],[0,3],[1,2]]
Output: -1
Explanation: There are not enough cables.
Example 4:
Input: n = 5, connections = [[0,1],[0,2],[3,4],[2,3]]
Output: 0
Constraints:
1 <= n <= 10^51 <= connections.length <= min(n*(n-1)/2, 10^5)connections[i].length == 20 <= connections[i][0], connections[i][1] < nconnections[i][0] != connections[i][1]- There are no repeated connections.
- No two computers are connected by more than one cable.
/*连通分量的个数、多出的线的个数
Runtime: 116 ms, faster than 70.07% of C++ online submissions for Number of Operations to Make Network Connected.
Memory Usage: 34.9 MB, less than 100.00% of C++ online submissions for Number of Operations to Make Network Connected.*/
int getRoot(vector<int> &root, int i) {
while (i != root[i]) {
root[i] = root[root[i]];
i = root[i];
}
return i;
}
int makeConnected(int n, vector<vector<int>>& connections) {
if (connections.size() < n - 1) return -1;
vector<int> root(n);
int lines = 0, set = 0;
for (int i = 0; i < n; i++) root[i] = i;
for (auto a : connections) {
int p1 = getRoot(root, a[0]), p2 = getRoot(root, a[1]);
if (p1 != p2) root[p1] = p2;
else lines++;
}
for (int i = 0; i < n; i++) {
if (root[i] == i) set++;
}
if (lines - set + 1 < 0) return -1;
else return set - 1;
}990. Satisfiability of Equality Equations
Given an array equations of strings that represent relationships between variables, each string equations[i] has length 4 and takes one of two different forms: "a==b" or "a!=b". Here, a and b are lowercase letters (not necessarily different) that represent one-letter variable names.
Return true if and only if it is possible to assign integers to variable names so as to satisfy all the given equations.
Example 1:
Input: ["a==b","b!=a"]
Output: false
Explanation: If we assign say, a = 1 and b = 1, then the first equation is satisfied, but not the second. There is no way to assign the variables to satisfy both equations.
Example 2:
Input: ["b==a","a==b"]
Output: true
Explanation: We could assign a = 1 and b = 1 to satisfy both equations.
Example 3:
Input: ["a==b","b==c","a==c"]
Output: true
Example 4:
Input: ["a==b","b!=c","c==a"]
Output: false
Example 5:
Input: ["c==c","b==d","x!=z"]
Output: true
Note:
1 <= equations.length <= 500equations[i].length == 4equations[i][0]andequations[i][3]are lowercase lettersequations[i][1]is either'='or'!'equations[i][2]is'='
/*Runtime: 8 ms, faster than 65.67% of C++ online submissions for Satisfiability of Equality Equations.
Memory Usage: 8.5 MB, less than 100.00% of C++ online submissions for Satisfiability of Equality Equations.*/
int getRoot(vector<int> &root, int i) {
while (i != root[i]) {
root[i] = root[root[i]];
i = root[root[i]];
}
return i;
}
bool equationsPossible(vector<string>& equations) {
int left = 0, right = equations.size()-1;
while (left < right) {
while (left<right && equations[right][1] == '!') right--;
while (left<right && equations[left][1] == '=') left++;
if(left<right){
swap(equations[right], equations[left]);
right--; left++;
}
}
vector<int> root(26);
for (int i = 0; i < 26; i++) root[i] = i;
for (int i = 0; i < equations.size(); i++) {
if (equations[i][1] == '=') {
int p1 = getRoot(root, equations[i][0] - 'a'), p2 = getRoot(root, equations[i][3] - 'a');
if (p1 != p2) root[p1] = p2;
}
else {
int p1 = getRoot(root, equations[i][0] - 'a'), p2 = getRoot(root, equations[i][3] - 'a');
if (p1 == p2) return false;
}
}
return true;
}1202. Smallest String With Swaps
Medium
34511Add to ListShare
You are given a string s, and an array of pairs of indices in the string pairs where pairs[i] = [a, b] indicates 2 indices(0-indexed) of the string.
You can swap the characters at any pair of indices in the given pairs any number of times.
Return the lexicographically smallest string that s can be changed to after using the swaps.
Example 1:
Input: s = "dcab", pairs = [[0,3],[1,2]]
Output: "bacd"
Explaination:
Swap s[0] and s[3], s = "bcad"
Swap s[1] and s[2], s = "bacd"
Example 2:
Input: s = "dcab", pairs = [[0,3],[1,2],[0,2]]
Output: "abcd"
Explaination:
Swap s[0] and s[3], s = "bcad"
Swap s[0] and s[2], s = "acbd"
Swap s[1] and s[2], s = "abcd"Example 3:
Input: s = "cba", pairs = [[0,1],[1,2]]
Output: "abc"
Explaination:
Swap s[0] and s[1], s = "bca"
Swap s[1] and s[2], s = "bac"
Swap s[0] and s[1], s = "abc"
Constraints:
1 <= s.length <= 10^50 <= pairs.length <= 10^50 <= pairs[i][0], pairs[i][1] < s.lengthsonly contains lower case English letters.
/*1202. Smallest String With Swaps
交换数组的顺序可以变,相当于是形成了若干个朋友圈,
朋友圈内部的各个字母可以随意交换顺序,朋友圈之间不可以,
(并查集,排序) O(m+nlogn)O(m+nlogn)
如果我们将索引看做点,将每个索引对看做一条无向边,则这个图可以有若干个连通块,每个连通块内部可以任意排列组合对应的字符。
所以我们通过并查集的方式来求出每个连通块,然后在各个连通块内从小到大排序字符,然后再将排序好的字符放回。
时间复杂度
遍历数对的时间复杂度为 O(m)O(m)。
并查集的复杂度近似为 O(n)O(n)。
最坏情况下,所有索引在一个连通块内,排序的时间复杂度为 O(nlogn)O(nlogn)。
故时间复杂度为 O(m+nlogn)O(m+nlogn)。
空间复杂度
需要额外 O(n)O(n) 的空间建立并查集,以及构造答案。
故空间复杂度为 O(n)O(n)。
Runtime: 180 ms, faster than 59.41% of C++ online submissions for Smallest String With Swaps.
Memory Usage: 53.2 MB, less than 100.00% of C++ online submissions for Smallest String With Swaps.*/
int getRoot(vector<int> &root, int i) {
while (root[i] != i) {
root[i] = root[root[i]];
i = root[i];
}
return i;
}
string smallestStringWithSwaps(string s, vector<vector<int>>& pairs) {
int n = s.size();
vector<int> root(n);
vector<int> size(n);
for (int i = 0; i < n; i++) {
root[i] = i;
size[i] = 1;
}
for (auto pr : pairs) {
int p1 = getRoot(root, pr[0]), p2 = getRoot(root, pr[1]);
if (p1 != p2) {
if (size[p1] < size[p2]) {
root[p1] = p2;//孩子多的作为根
size[p2] += size[p1];//将p1的孩子数加在p2上
}
else {
root[p2] = p1;
size[p1] += size[p2];
}
}
}
vector<vector<char> > a(n);
vector<vector<int> > pos(n);
for (int i = 0; i < n; i++) {
a[getRoot(root, i)].push_back(s[i]);
pos[getRoot(root, i)].push_back(i);
}
for (int i = 0; i < n; i++) {
sort(a[i].begin(), a[i].end());
}
string ans(n, '0');
for (int i = 0; i < n; i++) {
for (int j = 0; j < a[i].size(); j++) {
ans[pos[i][j]] = a[i][j];
}
}
return ans;
}279. Perfect Squares
Medium
2174169Add to ListShare
Given a positive integer n, find the least number of perfect square numbers (for example, 1, 4, 9, 16, ...) which sum to n.
Example 1:
Input: n = 12
Output: 3
Explanation: 12 = 4 + 4 + 4.Example 2:
Input: n = 13
Output: 2
Explanation: 13 = 4 + 9./*279. Perfect Squares
1.dp,dp[i]=min(dp[i-1],dp[i-4],dp[i-9]...)+1
Runtime: 60 ms, faster than 84.64% of C++ online submissions for Perfect Squares.
Memory Usage: 10.6 MB, less than 88.46% of C++ online submissions for Perfect Squares.*/
int numSquares1(int n) {
int q = sqrt(n);
vector<int> dp(n+1);
for (int i = 1; i <= q; i++) dp[i*i] = 1;
for (int i = 2; i <= n; i++) {
int tmp = sqrt(i);
int minn = dp[i - 1];
for (int j = 1; j <= tmp; j++) {
minn = min(minn, dp[i - j * j]);
}
dp[i] = minn + 1;
}
return dp[n];
}
/*2.四平方和定理:任意一个正整数都可以表示为四个以内整数的平方和
所以该题的返回结果只有1,2,3,4四种可能
下面将数字简化一下,由于一个数如果包含有因子4,那么可以把4都去掉,并不影响结果???
例如,2和8、3和12,返回的结果都相同,2=1+1,8=4+4,3=1+1+1,12=4+4+4
继续简化,如果一个数以8余7,那么一定是由4个完全平方数组成???
接下来尝试将数字拆为两个平方数的和,如果拆成功了就返回1或2,因为其中一个平方数可能是0
注意,!!a表示查看a是否是正整数
Runtime: 0 ms, faster than 100.00% of C++ online submissions for Perfect Squares.
Memory Usage: 7.4 MB, less than 100.00% of C++ online submissions for Perfect Squares.*/
int numSquares(int n) {
while (n % 4 == 0) n /= 4;
if (n % 8 == 7) return 4;
for (int a = 0; a*a <= n; a++) {
int b = sqrt(n - a * a);
if (a*a + b * b == n) return !!a + !!b;
}
return 3;
}264. Ugly Number II
Medium
135982Add to ListShare
Write a program to find the n-th ugly number.
Ugly numbers are positive numbers whose prime factors only include 2, 3, 5.
Example:
Input: n = 10
Output: 12
Explanation: 1, 2, 3, 4, 5, 6, 8, 9, 10, 12is the sequence of the first 10ugly numbers.Note:
1is typically treated as an ugly number.ndoes not exceed 1690.
/*264. Ugly Number II
1.ugly number是指质数因子只有2,3,5的数,
1,2,3,4,5,6,8,9,10,12
(1)我是质数,我不是2,3,5,我不是ugly number
(2)我不是质数,我的质因子中有不是2,3,5,我不是ugly number
超时!!!*/
unordered_set<int> isp(int n) {
unordered_set<int> res;
res.insert(1);
res.insert(2);
res.insert(3);
for (int i = 5; i <= n; i++) {
int flag = 0;
for (int j = 2; j <= sqrt(i) && flag==0; j++) {
if (i%j == 0) flag = 1;
}
if (flag == 0) res.insert(i);
}
return res;
}
int nthUglyNumber1(int n) {
if (n == 1) return 1;
unordered_set<int> isprime = isp(100000);
int i = 2; n--;
for (i = 2; n > 0; i++) {
if (i == 2 || i == 3 || i == 5) { n--; cout << i << endl; continue; }
if (isprime.find(i) != isprime.end() && i != 2 && i != 3 && i != 5) continue;
if (isprime.find(i) == isprime.end()) {//不是质数
int flag = 0;
for (int j = 2; j <= sqrt(i) && flag==0; j++) {
if (i%j == 0) {
if (isprime.find(j) != isprime.end() && j != 2 && j != 3 && j != 5) flag = 1;
if(isprime.find(i/j) != isprime.end() && i/j != 2 && i/j != 3 && i/j != 5) flag = 1;
}
}
if (flag == 0) {
n--; cout << i << endl;
}
}
}
return i-1;
}
/*2.大多数数字不是丑数,所以应该聚焦于形成丑数,而不是依次判断这个数是不是丑数
一个丑数必须是从一个较小的丑数,*2或*3或*5得来
假设有三个有序丑数序列,L1,L2,L3
假设知道第k个丑数,Uk,那么第k+1个丑数应该是min(L1*2,L2*3,L3*5)
所以丑数序列可以分为以下三个子列表:
(1)1*2,2*2,2*2,3*2,3*2,4*2,5*2,。。。
(2)1*3,1*3,2*3,2*3,2*3,3*3,3*3,。。。
(3)1*5,1*5,1*5,1*5,2*5,2*5,2*5,。。。
Runtime: 8 ms, faster than 75.57% of C++ online submissions for Ugly Number II.
Memory Usage: 10.9 MB, less than 73.68% of C++ online submissions for Ugly Number II.*/
int nthUglyNumber2(int n) {
vector<int> res(1, 1);
int i2 = 0, i3 = 0, i5 = 0;
while (res.size() < n) {
int m2 = res[i2] * 2, m3 = res[i3] * 3, m5 = res[i5] * 5;
int mn = min(m2, min(m3, m5));
if (mn == m2) i2++;
if (mn == m3) i3++;
if (mn == m5) i5++;
res.push_back(mn);
}
return res.back();
}
/*3.最小堆
首先放进去一个1,然后从1遍历到n,每次取出堆顶元素,
为了确保没有重复数字,进行一次while循环,将此时和堆顶相同的都取出来,
然后分别将这个取出的数字乘以2,3,5,并分别加入最小堆
这样for循环退出后,堆顶元素就是第n个丑数
Runtime: 132 ms, faster than 21.02% of C++ online submissions for Ugly Number II.
Memory Usage: 12.1 MB, less than 26.32% of C++ online submissions for Ugly Number II.*/
int nthUglyNumber(int n) {
priority_queue<long, vector<long>, greater<long> > q;
q.push(1);
for (int i = 1; i < n; i++) {
long t = q.top();
while (!q.empty() && q.top() == t) q.pop();
q.push(t * 2);
q.push(t * 3);
q.push(t * 5);
}
return q.top();
}1201. Ugly Number III
Medium
143168Add to ListShare
Write a program to find the n-th ugly number.
Ugly numbers are positive integers which are divisible by a or b or c.
Example 1:
Input: n = 3, a = 2, b = 3, c = 5
Output: 4
Explanation: The ugly numbers are 2, 3, 4, 5, 6, 8, 9, 10... The 3rd is 4.Example 2:
Input: n = 4, a = 2, b = 3, c = 4
Output: 6
Explanation: The ugly numbers are 2, 3, 4, 6, 8, 9, 10, 12... The 4th is 6.
Example 3:
Input: n = 5, a = 2, b = 11, c = 13
Output: 10
Explanation: The ugly numbers are 2, 4, 6, 8, 10, 11, 12, 13... The 5th is 10.
Example 4:
Input: n = 1000000000, a = 2, b = 217983653, c = 336916467
Output: 1999999984
Constraints:
1 <= n, a, b, c <= 10^91 <= a * b * c <= 10^18- It's guaranteed that the result will be in range
[1, 2 * 10^9]
#include"pch.h"
#include<vector>
#include<iostream>
#include<queue>
#include<unordered_set>
#include<algorithm>
using namespace std;
/*1201. Ugly Number III
丑数定义为可以被 a 或 b 或 c 整除的数,求第n个丑数
1.从1开始,做加法,挨个判断能否整除 a 或 b 或 c,超时*/
int nthUglyNumber1(int n, int a, int b, int c) {
int i = 1;
for (i = 1; n > 0; i++)
if (i%a == 0 || i % b == 0 || i % c == 0) n--;
return i - 1;
}
/*2.创建丑数序列
测试用例:nthUglyNumber(1000000000, 2, 217983653, 336916467),超时!!!*/
int nthUglyNumber2(int n, int a, int b, int c) {
vector<long long> res;
int i1 = 1, i2 = 1, i3 = 1;
long long mn;
while (n) {
long long m1 = i1 * a, m2 = i2 * b, m3 = i3 * c;
mn = min(m1, min(m2, m3));
if (mn == m1) i1++;
if (mn == m2) i2++;
if (mn == m3) i3++;
n--;
cout << mn << " " << n << endl;
}
return mn;
}
/*3.分两步:数据规模很大,使用二分法,logn,
(1)给定n,1-n中有多少个数是丑数(2)二分查找
例如:≤n 的数字中,2 or 3 or 5 的倍数
2:2,4,6,8,10,。。。,30,。。。c=x/2
3:3,6,9,12,15,。。。,30,。。。c=x/3
5:5,10,15,20,。。。,30,。。。c=x/5
c=x/2+x/3+x/5-x/(2*3)-x/(3*5)-x/(2*5)+x/(2*3*5)
上述c是,在≤x的数字中,a,b,c互质,丑数的个数
例如:≤n 的数字中,2 or 3 or 4 的倍数
2:2,4,6,8,10,。。。,30,。。。c=x/2
3:3,6,9,12,15,。。。,30,。。。c=x/3
4:4,8,12,16,20,24,。。。 c=x/4
lcm(2,3,4)=12,最小公倍数
c=x/2+x/3+x/4-x/(2*3)-x/(3*4)-x/(4)+x/(12)
通式:c=x/a+x/b+x/c-x/lcm(a,b)-x/lcm(a,c)-x/lcm(b,c)+x/lcm(a,b,c)
lcm:最小公倍数=两数乘积/最大公约数
gcd:最大公约数
Runtime: 0 ms, faster than 100.00% of C++ online submissions for Ugly Number III.
Memory Usage: 7.3 MB, less than 100.00% of C++ online submissions for Ugly Number III.*/
long gcd(long a,long b) {
while (a%b != 0) {
long tmp = a;
a = b;
b = tmp % a;
}
return b;
}
long lcm(long a, long b) {
return a * b / gcd(a, b);
}
long nthUglyNumber(int n, long a, long b, long c) {
long l = 1, r = INT_MAX;
long ab = lcm(a, b), ac = lcm(a, c), bc = lcm(b, c), abc = lcm(a, bc);
while (l < r) {
long mid = l + (r - l) / 2;
long k = mid / a + mid / b + mid / c - mid / ab - mid / ac - mid / bc + mid / abc;
if (k >= n) r = mid;
else l = mid + 1;
}
return l;
}
int main() {
cout << nthUglyNumber(1000000000, 2, 217983653, 336916467);
return 0;
}
- https://www.bilibili.com/video/av68819716
- 时间复杂度:O(log(2^32))=O(1) , 空间复杂度:O(1)


















 2464
2464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









