



文章目录
1 变量和基本类型
1.1 类型
占用内存的多少是变量间的关键区别。
| 类型 | 大小 / byte |
|---|---|
| short | 2 |
| int | 4 |
| long | 4 |
| long long | 8 |
| char | 1 |
| float | 4 |
| double | 8 |
| bool | 1 |
// 查看变量类型大小
std::cout << sizeof(int) << std::endl;
float a = 5.5f;
float a = 5.5F;
1.2 带符号和无符号类型
前面可以加unsigned以扩大存储值
unsigned int = unsigned
1.3 字面值常量
向55这样的,只能用它的值来称呼它(字面),并且值不能修改(常量),叫字面值常量。每个字面值都有对应的类型。
1、整型字面值
128U // unsigned int
66L // long
7829UL // unsigned long
2、浮点型字面值
3.14159F // 单精度
12.45L // 拓展精度
3、布尔字面值和字符字面值
bool
','
'2'
4、非打印字符的转义序列
\n // 换行符
\r // 回车符
\' // 单引号
\" // 双引号
\0 // 空字符
// 打印单引号
std::cout << '\'' << std::endl;
5、字符串字面值
字符串字面值用双引号括起来,在末尾自动添加空字符以兼容C语言。
'A' // 单个字符A
"A" // A以及编译器自动在末尾添加的空字符
仅由换行符,空格,制表符分隔开的字符串字面值可以连接。
std::cout << "Hello "
"I am "
"Hi"
<< std::endl;
在一行的末尾添加反斜线可以将此行和下一行当作同一行处理。
std::c\
out << "Hello \
I am \
Hi"<< st\
d::endl;
1.4 变量
1.4.1 左值和右值
左值可以出现在赋值语句的左边或右边;右值只能出现在右边。
变量是左值,数字字面值是右值。
1.4.2 声明和定义
1、定义:definition
为变量分配内存空间,还可以为变量指定初始值,一个程序中,一个变量有且仅有一个定义。
2、声明:declaration
向程序表明变量的类型和名字。定义是一种声明。
3、extern 关键字
int i // declare and define
extern int i // declare but not define
1.5 作用域(scope)
大多数作用域用{ }来界定。
// 1
{
}
// 2 语句作用域
for(int val = 1; ;){
}
// 3 类作用域
class Entity{
}
定义在所有{ }外面,整个程序都可见,也就是定义在所有函数外部的名字具有全局作用域,可以在程序的任何地方访问。
定义在某个函数的作用域内,函数外不能访问,具有局部作用域。
定义在for语句中,只能在for语句中使用,叫语句作用域
类作用域
当成员在类的定义体之外定义时,使用完全限定名,指出该成员是在类作用域中,另外,在其中可以直接使用类里已定义的东西。
void class1::fuc(){
}
命名空间作用域
2 表达式
2.1 算术操作符、关系操作符和逻辑操作符
1、算术操作符
优先级:正负号 > 乘 除 求余 > 加 减
2、关系操作符
!=, ==, >, >=, <, <=
3、逻辑操作符
!逻辑非
&& 逻辑与
|| 逻辑或
4、优先级
逻辑非 ! > 算术操作符 > 关系 > &&, || > 赋值=
2.2 位操作符
2.2.1 位求反
~
2.2.2 左移右移
int a = 8;
// 左移1位
int b = a << 1;
std::cout << b;
// 输出 16
// 右移2位
int c = a >> 2;
std::cout << c;
// 输出 2
3、与、或、异或
int a = 8; // 1000
int b = 13; // 1101
// 异或
int c = a ^ b; // 0101 = 5
std::cout << c;
// 与
int d = a & b; // 1000 = 8
std::cout << d;
// 或
int e = a | b; // 1101 = 13
std::cout << e;
2.2.3 bitset对象的使用
目的:想要第27位为1,其余都为0,用于记录第27个学生通过了考试。
方法1:建立一个容量为30的bitset对象,把第27为设为1
std::bitset<30> b;
b.set(27);
// 设回0:b.reset(27);
方法2:使用位操作
把一个只有第27位为1的无符号长整数(由1和左移生成)与helper做位或操作
unsigned long helper = 0;
helper |= 1UL << 27;
2.2.4 移位操作与cout
移位操作符具有中等优先级,其优先级比算术操作符低,但比关系操作符,赋值操作符,条件操作符高。
std::cout << 10 + 55;
// 输出 65
std::cout << (10 < 8);
// 输出 0
std::cout << 10 < 8;
// error
2.3 赋值操作符
1、右结合性
int i, j;
i = j = 0; // 正确
int* p;
i = p = 0; // 错误,不同类型
2、赋值操作具有低优先级
3、复合赋值操作符
+=, -+, *=, /=, %=
<<=, >>=, &=, ^=, |=
使用复合操作时,左操作数只计算了一次;使用相同作用的长表达式时,则计算两次。
2.4 自增和自减操作符
1、首先,无论是前自增还是后自增,i 变量都首先+1,如果是前自增,那么返回+1后的结果;如果是后自增,则返回未加1之前的值。
int i = 0, j;
j = ++i; // j = 1, i = 1
j = i++; // j = 1, i = 2
2、解引用与自增
std::vector<int> vec= { 2,5,6,80 };
std::vector<int>::iterator iter = vec.begin();
while (iter != vec.end()) {
std::cout << *iter++ << std::endl;
}
// 输出 2 5 6 80
因为后自增的优先级高于解引用,因此:
*iter++ = *(iter++)
2.5 ->操作符
C++为包含点操作符和解引用操作符的表达式提供了一个同义词: ->
解引用p指针来得到一个object,然后得到它的成员foo
(*ptr).foo;
p -> foo;
2.6 条件操作符 (三元操作符)
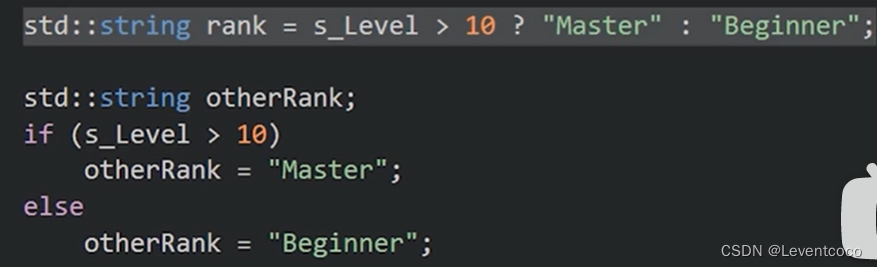
b = a > 5 ? 10 : 5;
if (a > 5)
b = 10;
else
b = 5;
可以提升效率
b = a > 5 ? a > 10 ? 15 : 10 :5;
2.7 类型转换
1、隐式转换
2、显示转换
int main() {
double pi = 3.1415926;
int a = (int)pi; //c语言的旧式类型转换
int b = pi; //隐式类型转换
int c = static_cast<int> (pi); //c++的新式的类型转换运算符
return 0;
}
去掉const属性,转变为int&属性
void func(int & a){
std::cout << "func---a:" << a << std::endl;
a = 100; // 这里改变了引用的值,会起作用吗?需要看传递进来的变量是否是const的
}
int main() {
const int d = 30;
func(const_cast<int &>(d)); // 如果在func中修改了d的值,会起作用吗?不会
std::cout << "d:" << d << std::endl;
return 0;
}
3 指针和引用
3.1 指针
int var = 8;
int* ptr = &var;
*ptr = 10; // var = 10
int var = 8;
int* ptr = new int;
ptr = &var; // var = 8
*ptr = 10; // var = 10
3.1.1 void*指针
void*可以·保存任何类型对象的地址,表明该指针与以抵制有关,但不清楚这个地址上对象的类型,因此void类型指针不支持对所指对象的赋值。
int var = 8;
void * ptr = &var;
3.2 野指针
堆上申请内存,需要手动删除。不用new就不用delete
// 无初始化
int *another = new int[5];
// 有初始化,都初始化为0
int *another = new int[5]();
delete[] another;
此时, another是一个悬垂指针,因为数组已经被删除,但这个指针仍然指向原先数组的地址,最好的方法是:一旦删除了指针所指向的对象,立即将指针置为0。
another = NULL;
没有new却delete将报错。
int i = 0;
int* p = &i;
delete p; // 报错
3.2 引用
int a = 5;
int& ref = a; // 此时ref = 5
ref = 2;
#a = 2
3.3 函数指针
bool (*ptr)(const std::string &, const std::string &);
ptr声明为指向函数的指针,它所指的函数带有两个const std::string &类型的形参和bool类型的返回值。
1、无输入且无返回值的函数指针
void HelloWorld() {
std::cout << "Hello" << std::endl;
}
int main() {
auto function = HelloWorld; // Hello函数的内存地址(指针)
// 也可写作
void (*function)() = HelloWorld;
function();
}
// 输出 Hello
2、有输入且无返回值的函数指针
void HelloWorld(int a) {
std::cout << "Hello and Value = "<< a << std::endl;
}
int main() {
void(*function)(int) = HelloWorld;
function(5);
}
// 输出 Hello and Value = 5
3、函数指针作为形参
void HelloWorld(int value) {
std::cout << "Hello and Value = "<< value << std::endl;
}
void ForEach(const std::vector<int>& values, void(*function)(int)) {
// 向量和函数指针为参数
for (int value : values) {
function(value);
}
}
int main() {
std::vector<int> a = { 5,3,2,6 };
ForEach(a, HelloWorld);
}
lambda写法:
void ForEach(const std::vector<int>& values, void(*function)(int)) {
for (int value : values) {
function(value);
}
}
int main() {
std::vector<int> a = { 5,3,2,6 };
ForEach(a, [](int value) {std::cout << "Hello and Value = " << value << std::endl; });
std::cin.get();
}
3.4 智能指针
3.4.1 unique_ptr
unique_ptr独享被管理对象指针所有权,不能复制
#include <iostream>
#include <string>
#include <memory>
using String = std::string;
class Entity {
private:
int x, y;
public:
Entity() {
std::cout << "Created" << std::endl;
}
~Entity() {
std::cout << "Destroyed" << std::endl;
}
void Print() {}
};
int main() {
{
std::unique_ptr<Entity> entity = std::make_unique<Entity>();
// 等同 std::unique_ptr<Entity> entity(new Entity());
entity->Print();
}
//scope结束之后,entity将被自动销毁
std::cin.get();
}
3.4.2 shared_ptr
shared_ptr使用引用计数,每一个shared_ptr的拷贝都指向相同的内存。每使用他一次,内部的引用计数加1,每析构一次,内部的引用计数减1,减为0时,删除所指向的堆内存。
// 声明
std::shared_ptr<Entity> sharedEntity = std::make_shared<Entity>();
sharedEntity->Print();
{
std::shared_ptr<Entity> e0;
{
std::shared_ptr<Entity> sharedEntity = std::make_shared<Entity>();
e0 = sharedEntity;
} // 此时sharedEntity 没有被destroy,因为仍有一个指针指向它
} // 此时sharedEntity 被destroy
std::cin.get();
3.4.3 weak_ptr
shared_ptr copy给另一个shared_ptr时,增加引用计数器的计数,但shared_ptr copy给weak_ptr,不增加引用计数。
{
std::weak_ptr<Entity> e0;
{
std::shared_ptr<Entity> sharedEntity = std::make_shared<Entity>();
e0 = sharedEntity;
} // 此时sharedEntity 被destroy,此时这个weak_ptr指向一个无效的entity
}
std::cin.get();
3.5 参数传递
3.5.1 引用
引用必须用与该引用同类型的对象初始化。
int num = 10;
int &ref = num;
std::cout << ref << std::endl; // 输出 10
ref = 88;
std::cout << num << std::endl; // 输出 88
引用是别名。
引用很专一,不会换对象。
int num = 10;
int num2 = 5;
int &ref = num;
int &ref = num2; // 报错
只有const引用才能引用const
const int number = 1024;
const int &ref = number; // 正确
int &ref2 = number; // 错误
int num = 3.14;
const int &ref = num; // 正确
const int &ref1 = num + 1; // 正确,const引用可以绑定右值,可以绑定同类型对象(例如num),可以绑定不同但相关类型的对象(例如num+1)
int &ref2 = num; // 正确,非const引用只能绑定到同类型的对象
std::cout << num << std::endl; // 输出3
std::cout << ref << std::endl; // 输出3
std::cout << ref1 << std::endl; // 输出4
std::cout << ref2 << std::endl; // 输出3
const int& ref3 = ref + 1;
std::cout << ref3 << std::endl; // 输出4
3.5.2 传值与传引用
1、
在函数运行之前,形参只是一个符号,函数调用时,需要进行参数传递,也就是用实参初始化对应的形参。
C++中,有三种参数传递方式:传值、传指针、传引用
对于Swap1函数,分别将x, y的值传给了形参a, b;a, b中的值进行了交换,但x, y并未改变,因此输出x=10, y=20
对于Swap2函数,将x的地址传给形参a,则指针a指向变量x,同理指针b指向变量y;执行Swap2函数,将a指向的存储单元中的值与b指向的存储单元中的值交换了,因此输出x=20, y=10
对于Swap3函数,将变量x起了一个别名a,变量y起了一个别名b,执行交换,因此也输出x=20, y=10
#include <iostream>
void Swap1(int a, int b) {
int tmp;
tmp = a;
a = b;
b = tmp;
}
void Swap2(int* a, int* b) {
int tmp;
tmp = *a;
*a = *b;
*b = tmp;
}
void Swap3(int &a, int &b) {
int tmp;
tmp = a;
a = b;
b = tmp;
}
int main() {
int x = 10;
int y = 20;
Swap1(x, y);
//Swap2(&x, &y);
//Swap3(x, y);
std::cout << x << std::endl << y;
std::cin.get();
}
2、更进一步
C++的值传递(pass-by-value),是从调用的地方把值复制一遍传给函数。这样做有两个问题,第一,需要将实参拷贝到形参处,形成实参的副本,有时间和空间的开销,若实参为结构体或者类的话,那么时空开销将会非常大;第二、函数中对实参副本的修改并不会影响到函数调用位置实参的值。
C++的引用传递(pass-by-reference),一方面,参数传递的是把实参的地址拷贝到形参,这样形参和实参对应的是同一块内存地址,那么对形参的修改自然会反映到实参上;另一方面,C++中指针或者引用只占4字节,所以时空开销也能接受。
& 的目的是引用,避免再了复制一个std::string,const 是为了限定它只读。
传参时 const string&(引用传递)比const string(值传递)更节省资源
// 值传参
void Print(int index) {
std::cout << index << std::endl;
}
// 引用传参
void PrintString(const String& index) {
std::cout << index << std::endl;
}
int main() {
int a = 5;
String b = "ahksh";
Print(a);
PrintString(b);
std::cin.get();
}
3.5.3 数组参数的传递
在C++中,数组参数的传递属于特殊情形。
数组作为形参按传值方式声明,但实际传递的是数组的首地址,即数组名,使得形参数组和实参数组共用同一组内存单元,因此对形参做的任何改变相当于在实参数组中进行相应的处理。
两种方式等同:
function(int a[ ]);
function(int *a);
3.6 函数的声明
// 函数声明,最好放在头文件中
void print(int* array, int size);
3.6.1 默认实参
std::string Init(int height = 10, int width = 20, char type = ' ');
int main() {
std::string val = Init(); // 合法,等于 Init(10, 20, ' ')
std::string val = Init(66); // 合法,等于 Init(66, 20, ' ')
}
注意,默认实参只能用于替换函数调用缺少的尾部实参。例如要给type提供实参,那么height和width也需要提供实参。
因此,在排列形参时,要把最少使用默认实参的形参排在前面。
3.7 重载函数
出现在相同作用域的两个函数,名字相同但形参表不同,则称为重载函数。
3.7.1 函数重载和重复声明的区别
1、返回类型和形参表完全相同 -> 重复声明
2、对于非引用形参,仅有const与否的差别也算作重复声明,例如:
void replace(int cnt) {
val = cnt;
}
void replace(const int cnt) {
val = cnt;
} // 报错,重复声明
因为不传引用或指针的情况下,函数无法修改实参,因此既可以将const对象传给const形参也可以传给非const形参,两种形参无差别。
3、仅当形参是引用或指针时,形参是否为const才对函数重载有影响。
这种写法不报错,不是重复声明,而是参数重载,编译器可以根据实参是否为const来决定调用哪一个函数。
如果传入的对象是const,则只能调用下面的;如果传入非const对象,则这两个函数都可行,因为其也可以用来初始化const引用,但最后还是会使用上面的声明,因为这是精确匹配,而下面的存在一步转换。
void replace(int& cnt) {
val = cnt;
}
void replace(const int& cnt) {
val = cnt;
}
4、形参表相同,返回类型不同,则第二个声明是错误的。也就是说不能仅仅基于不同的返回类型实现参数的重载。
3.7.2 重载与作用域
一般的作用域规则同样适用于重载函数名。
如果调用语句在最直接的作用域中找到了符合名字的函数,则停止向更大的作用域查找。如果找到了多个,将匹配类型,找到适合的那个;如果只找到一个,停止查找,并检查类型是否匹配,如果匹配失败,就算报错也不继续查找。
因此应将每一个版本的重载函数都声明在同一个作用域内。
3.7.3 重载确定的步骤
1、寻找候选函数
四个f都是候选函数
void f();
void f(int);
void f(int, int);
void f(double, double = 3.14);
f(5.6);
2、寻找可行函数
第二个和第四个可行,因为存在隐式转换。
3、寻找最佳匹配
第四个为最佳匹配。
如果没有明显的最佳选择,将会报错,因为是ambiguous的,例如:
f(42, 2.56);
4 关键字
4.1 continue, break, return
在循环中使用
1、continue:
只能在循环体中使用,结束本次循环,进入下一轮循环
for(i=0; i<5; i++){
if(i%2==0)
continue
std::cout << "Hello" <<std:: endl;
}
2、break:
(1)、用在switch中,,退出switch语句
(2)、用在循环体中,退出break所在的那层循环(最近的循环)
3、return:最强大,结束整个函数
4.2 static
4.2.1 static与变量
1、
// static.cpp
static int a = 5;
// a对其他的translation unit来说不可见
2、如果一个类的a变量是static的,此类的一个实例改变了a的值,其他所有实例同时改变。
3、静态局部对象
如果一个变量位于一个函数的scope内,但生命周期跨过了这个函数的多次调用,那么应将这个对象定义为static。
这种对象一旦被创建,只有在程序结束时才会被撤销。
// 这个函数计算自己被调用的次数
int count_calls(){
static int cnt = 0;
return cnt++;
}
4.2.2 static与方法
static方法不能访问非静态成员变量。
因为static方法没有类的实例,每一个非static方法都会隐式地得到一个类的实例作为参数。
4.3 const
因为 const 定义后就不能修改,所以定义时必须被初始化。
const int threshold = 5; // 正确
const int y; // 报错
4.3.1 const与extern
1、把一个非const变量定义在一个文件中,做合适的声明,就可以在另外的文件中使用这个变量。
// helper.cpp
int counter = 8;
//main.cpp
extern int counter;
std::cout << counter << std::endl; // 输出 8
2、非const变量默认为extern。要使const变量能在其他文件中访问,必须显式地指定其为extern。如果不特殊说明const变量,那么它不能在其他文件中被访问。
// 正确
// helper.cpp
extern const int counter = 8;
//main.cpp
extern const int counter;
std::cout << counter << std::endl; // 输出 8
// 错误
// helper.cpp
const int counter = 8;
//main.cpp
extern const int counter;
4.3.1 const与指针
正常情况下,可以修改指针指向内存的值,也可以修改指针自己的地址。
const int value = 100;
int *a = new int;
// 1、可以修改指针a指向内存中的数值
*a = 2;
// 2、还可以修改指针a,使其指向value
a = (int*)&value;
std::cout<< *a;
// 输出 100
4.3.1.1 指向const对象的指针
最前面加上const后,不能改变指针指向的内存中的数据。因为这个数据是一个const值。
但可以改变指针本身,例如下面最开始指针a指向value1,可以使其指向value2。
const int value1 = 100;
const int *a = &value1;
// 也可写作 int const* a = &value1;
//*a = 2; 报错,因为不可修改指针指向内存中的数据
std::cout << *a;
// 输出 100
const int value2 = 105;
// 使a指向value2
a = &value2;
std::cout << *a;
// 输出 105
但是,const int*类型的指针也可以指向非const数据。因此,指向const的指针可以理解为“自以为指向const的指针”。
int value = 100;
const int *a = &value;
std::cout << *a;
// 输出 100
value = 105;
std::cout << *a;
// 输出 105
4.3.1.2 const指针
中间加上const后,能改变指针指向的内存中的数据,不能改变指针本身了。
a是指向int类型对象的const指针。不能使a指向其他对象,任何给const指针赋值的操作都会报错,即使是a = a;
int value = 100;
int *const a = &value;
*a = 2;
std::cout << "value = " << value;
// 输出 value = 2
4.3.1.3 指向const对象的const指针
既不能修改ptr所指对象的值,也不允许修改该指针的指向。
描述:ptr首先是一个const指针,指向int类型的const对象。
const int value = 100;
const int *const ptr = &value;
4.3.1.4 与typedef
typedef std::string *pstring;
const pstring cstr;
cstr是一个指向std::string类型对象的const指针,即4.3.1.2的情况。因为const修饰的是pstring类型,这是一个指针。
4.3.2 const与类
1、如果方法不应该或者没有修改class,那么应该把该方法标记为const。
2、mutable关键字允许变量在const方法中被修改。
class Entity {
private:
int X, Y;
mutable int var;
public:
int GetX() const {
var = 2;
return X;
}
void SetX(int x) {
X = x;
}
};
GetX()称为常量成员函数。当调用成员函数时,是使用对象来调用的,也就是一个隐含的形参this指向调用函数的对象的地址 也就是 int GetX() {return this->X;}
加上const之后,this指针变为指向const对象的指针,因此只能读取,不能修改。
4.4 auto
用于变量,自动分配类型。
auto a = 5.0f;
auto b = a;
4.5 this以及->和.
4.5.1 this是指向当前对象实例的指针
#include <iostream>
#include <string>
class Entity {
private:
int x, y;
public:
Entity(int x, int y) {
// 方法一
this->x = x;
this->y = y;
// 方法二 指针用->
// Entity* const ptr = this;
// ptr->x = x;
// ptr->y = y;
// 方法三 实例用.
// (*this).x = x;
// (*this).y = y;
}
int GetX() const
{
return x;
// return (*this).x;
// return this->x;
// 以上三种写法都正确
}
};
int main() {
Entity e(5, 6);
std::cout << e.GetX() << std::endl;
// Entity* ptr1 = &e;
// std::cout << (*ptr1).GetX() << std::endl;
// 输出5
// std::cout << ptr1->GetX() << std::endl;
// 输出5
std::cin.get();
}
4.5.2 ->和.
对象加.
指针加->
#include <iostream>
#include "qxy.h"
#include <string>
#include <memory>
//#include "ClassExtend.cpp"
using String = std::string;
class Entity {
private:
int x, y;
public:
Entity() {}
void Print() {
std::cout << "hello" << std::endl;
}
};
int main() {
//1
Entity e;
e.Print();
//2
Entity* ptr = &e;
ptr->Print();
(*ptr).Print();
//3
Entity& entity = *ptr; // Entity entity = *ptr; 也可以
entity.Print();
//4
Entity* ptr1 = new Entity();
ptr1->Print();
std::cin.get();
}
4.6 namespace
#include <iostream>
namespace apple {
void print(const char* text) {
std::cout << "Apple and " << text << std::endl;
}
}
namespace orange {
void print(const char* text) {
std::cout << "Orange and " << text << std::endl;
}
}
int main() {
apple::print("Hello");
//using namespace apple; // 只在作用域内有效
//print("Hello");
std::cin.get();
}
4.7 inline
在函数的名字前写上inline即可将这个函数定义为内联函数,解决一些频繁调用的小函数大量消耗栈空间(栈内存)的问题。
定义在类中的成员函数默认都是内联的,如果在类中未给出成员函数定义,而又想内联该函数的话,需要在类的头文件.h中定义这个函数,不能在相应的.cpp文件中定义,因为译器必须随处可见内联函数的定义。
4.8 typedef
用来定义类型的同义词。意图是隐藏,强调使用目的,简化等。
typedef int in;
in num = 3;
std::cout << num << std::endl; // 输出3
4.9 explicit
explicit关键字只需用于类内的单参数构造函数前面,防止类构造函数的隐式自动转换。
除非有明显的理由想要定义隐式转换,否则,单形参构造函数应该为explicit。
class CxString{
public:
int _size;
explicit CxString(int size){
_size = size;
}
};
5 类和结构体
5.1 类和结构体的区别
区别在于可见性。
class不写默认为private,struct不写默认为public。
struct还保持了对C的兼容性。
class Player
{
public:
int x, y;
int speed;
void move(int a, int b){
x += a* speed;
y += b* speed;
}
};
5.2 访问控制 ( private, protected, public )
1、private
class内的函数或firend class可以访问private变量。
2、protected
可以在子类中访问protected变量。
保护性强于public,弱于private。
3、public
5.3 构造函数和析构函数
1、构造函数
构造函数不能声明为const
class Entity{
public:
Entity(); // 正确,默认构造函数
Entity() const; // 错误
};
// 如何正确使用默认构造函数
Entity entity;
Entity entity = Entity();
2、析构函数
在类名前面加上“~”即表示析构函数。与构造函数不同的是,一个类中只允许一个析构函数存在。
如果类中无析构函数,则编译系统会默认补上一个空的析构函数。当程序结束时,会自动调用析构函数。
如果在堆上创建实例,也就是Entity* entity = new Entity(“xingyu”); ,参考7.2.2,那么需要手动析构,也就是delete entity;
#include <iostream>
#include "qxy.h"
class Entity {
public:
int x, y;
void Print() {
std::cout << x << " and " << y <<std::endl;
}
//默认构造器
Entity(){
}
//默认析构函数
~Entity(){
}
Entity(int X, int Y) {
x = X;
y = Y;
}
};
int main() {
//Entity e = Entity(5,10);
Entity e(6, 10);
e.Print();
std::cin.get();
}
5.4 构造函数的初始化列表
1、常规写法
class Entity {
private:
int X, Y;
std::string Name;
public:
Entity() {
Name = "Unknown";
}
};
2、成员初始化列表写法
冒号和花括号之间的部分称为构造函数初始化列表,为类的一个或多个数据成员指定初值。
此写法只需要创建一个object,而1中的写法要创建两次,第一个扔掉,用一个新的对象覆盖它。因此为节省性能,应该用成员初始化列表。另外,如果Name是const,则必须用初始化列表初始化。
#include <iostream>
#include <string>
class Entity {
private:
int X, Y;
std::string Name;
public:
Entity()
: X(5), Y(8), Name("Unknown") //按顺序写
{
}
Entity(const std::string& name)
: Name(name)
{
}
};
using namespace std;
class Entity{
public:
string i;
int j;
double k;
Entity(const string &a = "5"): i(a), j(1), k(1.0){}
};
int main()
{
Entity entity("HISAHS");
cout << entity.i << entity.j << entity.k << endl;
// 输出 HISAHS11
Entity another_entity;
cout << another_entity.i << another_entity.j << another_entity.k << endl;
// 输出 511
}
5.5 类成员的显式初始化
对于没有定义构造函数且数据成员都为public的类,可以采用此种方式。要按照数据成员的声明次序来使用初始化式。
using namespace std;
class Entity{
public:
string i;
int j;
};
int main()
{
Entity entity = {"HISAHS", 6};
cout << entity.i << entity.j << endl;
// 输出 HISAHS6
}
5.6 友元
授予指定的函数或类访问其非public成员的权限。
class X{
// 整个类设为友元,Y中的函数可以访问X的所有成员
friend class Y;
// 将某个类的成员函数设为友元,函数名要用所属的类名加以限定
friend Y& Y::func(Y::idx1, Y::idx2, X&);
};
5.5 继承
Player为Entity的子类
class Entity {
public:
int x, y;
void Move(int xa, int ya) {
x += xa;
y += ya;
}
};
class Player : public Entity{
public:
const char* Name;
void PrintName(){
std::cout<< Name <<std::endl;
}
};
Player player;
player.Move(5,6);
5.6 虚析构函数
5.6.1 虚函数和纯虚函数
https://blog.youkuaiyun.com/suren_jun/article/details/128259927
5.6.2 有子类的父类的析构函数应为虚函数
1、只要你允许一个类拥有子类,那么父类的析构函数一定要标记为virtual(虚析构函数)。
2、class Derived : public Base

过程1:调用base的构造和析构
过程2:调用base的构造、derived的构造,derived的析构、base的析构
过程3:当base的析构函数不为虚函数时:调用base的构造、derived的构造,base的析构。可能造成内存泄漏
当base的析构函数是虚函数时,与过程2一样。~Base(){}
6 STL
6.1 标准库string类型
6.1.1 头文件
#include <string>
6.1.2 初始化
// 1
std::string s1("value");
// 2
std::string s1 = "value";
std::cout << s1 << std::endl; // 输出 value
// 3
std::string s2(5, 'a');
std::cout << s2 << std::endl; // 输出 aaaaa
// 4
std::string s3(s2);
std::cout << s3 << std::endl; // 输出 aaaaa
6.1.3 string对象的读写
读取并忽略开头的所有空白字符,读取字符直到再次遇见空白字符。
std::string s;
std::cin >> s; // 输入hello world
std::cout << s << std::endl; // 输出hello
std::string s1, s2;
std::cin >> s1 >> s2; // 输入hello world
std::cout << s1 << s2 << std::endl; // 输出helloworld
更好的方式:
std::string word;
while (std::cin >> word) {
std::cout << word << std::endl;
}
std::cin.get();
使用getline(),这个方法不忽略换行符,也就是说,如果输入换行符,那么line将被置为空string
std::string line;
while (std::getline(std::cin, line)) {
std::cout << line << std::endl;
}
6.1.4 string对象的操作
1、s.empty()
若s为空,返回true;若非空,返回false
2、s.size()
std::string s = "112233";
std::cout << s.size()<< std::endl; // 输出 6
3、s.find()
std::string s = "112233";
std::cout << s.find("1") << std::endl; // 输出 0
4、string对象关系操作符
逐位比较字符,区分大小写,大写要大于小写。
5、string对象的相加
要求+操作符的左右操作数必须至少有一个是std::string类型。
// 错误写法,因为"hello"和"world"为const char*,不能把两个指针()相加
std::string str = "hello" + "world";
// 正确写法1
std::string str = std::string("hello") + "world";
// 正确写法2
std::string s1 = "hello";
s1 += "world";
正确写法3:使用append()方法
std::string a = "wiiuw";
std::cout << a.append("6666q") << std::endl;
更多std::定义的操作符:https://blog.youkuaiyun.com/new9232/article/details/125818067
string s1 = "hello";
string s2 = "world";
string right = s1 + "," + "world"; // 正确
string wrong = "hello" + s2; // 错误
6、substr()
std::string s;
s.substr(i,len);
//从s的i位开始截取长度为len的串
std::string str = "xingyu";
std::cout << str.substr(0, 3) << std::endl;
// 输出 xin
7、string对象中对字符的处理
std::string str = "Hello!";
bool ans = ispunct(str[5]); // 判断字符是否为标点符号,ans为真
char c = toupper(str[1]);
std::cout << c << std::endl; // 输出E
6.2 顺序容器:标准库vector类型(动态数组)
6.2.1 三种顺序容器及头文件
vector, list, deque
#include <vector>
6.2.2 初始化
std::vector<int> vec;
std::vector<int> vec(10, -1); // 10 elements, each set to -1
std::vector<int> vec(10); // 10 elements, each set to 0
std::vector<std::string> vec(10, "hello");
// another_svec是svec的副本
std::vector<std::string> svec = { "hello", "I", "am" };
std::vector<std::string> another_svec(svec);
// 通过迭代器可以初始化其他类型的容器内容初始化本容器
std::list<std::string> slist(svec.begin(), svec.end());
6.2.3 vector对象的操作
1、v.empty()
2、v.size()
3、添加元素
std::vector<int> v;
v.push_back(1);
v.emplace_back(6);
push_back() 向容器尾部添加元素时,首先会创建这个元素,然后再将这个元素拷贝或者移动到容器中(如果是拷贝的话,事后会自行销毁先前创建的这个元素)。
而 emplace_back() 在实现时,则是直接在容器尾部创建这个元素,省去了拷贝或移动元素的过程。
emplace_back() 可以避免创建临时对象,造成性能损失
原文链接:https://blog.youkuaiyun.com/qq_37124218/article/details/127016701
原文链接:https://blog.youkuaiyun.com/weixin_44205193/article/details/121522379
4、处理输入
std::string word;
std::vector<std::string> v;
while (std::cin >> word) {
v.push_back(word);
}
5、打印一个vector
// 方法1
for (int i = 0; i < v.size(); i++) {
std::cout << v[i] << std::endl;
}
// 方法2
for (int a : v) { //会复制数据
std::cout << a << std::endl;
}
// 方法3
for (int& a : v) { //不会复制数据,传的是引用
std::cout << a << std::endl;
}
6、函数传参
void Function(const std::vector<int>& v) {
}
// 调用
Function(v);
7、删除vector内元素
(1)、clear()
// 清空所有
v.clear();
(2)、erase()
// 删除第二个元素
v.erase(v.begin() + 1);
v.erase(b, e) 删除迭代器b, e之间的所有元素。
std::vector<std::string> vec = { "hello", "I", "am", "name" };
vec.erase(vec.begin() + 1, vec.end() - 1);
// vec = {"hello", "name"}
(3)、pop_back();
删除最后一个
8、赋值vector与swap
// 更新v中的元素,将迭代器b和e标记范围内的元素复制到v中
v.assign(b, e);
// 将v重新设置为n个t
v.assign(n, t);
std::vector<std::string> vec1(10);
std::vector<std::string> vec2(15);
vec1.swap(vec2);
// 现在vec1中有15个元素,vec2中有10个元素。
swap操作不增删元素,常量时间完成交换。迭代器也不会失效,只是指向了不同容器的同一位置。例如iter指向vec1[3],swap之后它指向vec2[3],指向的值相同,只是储存在不同容器中。
9、反转vector
reverse(v.begin(), v.end());
10、改变vector大小
(1)、v.resize(n,m),n为resize后容器的大小,m为填充值,可省略。
std::vector<int> v;
v = { 3,4,5 };
v.resize(2);
for (auto a : v) {
std::cout << a << std::endl;
}
// 输出 3 4
v.resize(5, 10);
for (auto a : v) {
std::cout << a << std::endl;
}
// 输出 3 4 10 10 10
(2)、v.reserve(n)
为容器改变开辟的空间,不能往小改
std::vector<int> v;
v = { 3,4,5 };
v.reserve(2);
for (auto a : v) {
std::cout << a << std::endl;
}
// 输出 3 4 5
11、insert()
vec.insert(p, t) —— 参数:迭代器,元素 —— 在迭代器前面插入该元素。
std::vector<std::string> vec = { "hello", "I", "am" };
vec.insert(vec.end(), "name");
vec.insert(p, n, t) —— 在迭代器前面插入n个该元素。
vec.insert(p, b, e) —— 在迭代器p前面插入由迭代器b和e标记的元素。
12、
front();//返回容器第一个数据元素
back();//返回容器中最后一个数据元素
6.2.4 vector容器的自增长
预留容量用来存放新添加的元素,以避免重新分配容器。
std::vector<std::string> vec = { "hello", "I", "am", "name" };
vec.push_back("eh");
std::cout << vec.size() << " ";
std::cout << vec.capacity() << " ";
// 输出 5 6
// 为容器预留50的capacity
vec.reserve(50);
6.2.5 deque双向队列
#include<deque>
push_back(elem);//在容器尾部添加一个数据
push_front(elem);//在容器头部插入一个数据
pop_back();//删除容器最后一个数据
pop_front();//删除容器的第一个数据
front();//返回容器第一个数据元素
back();//返回容器中最后一个数据元素
6.6 顺序容器适配器
6.6.1 三种顺序容器适配器 (adapter)
stack和queue基于deque实现,priority_queue基于vector实现。
6.6.2 stack 栈
s.empty()
s.size()
s.pop()
s.top()
s.push(item)
6.6.3 queue 队列 (FIFO)
1、头文件
#include <queue>
2、声明
std::queue<std::string> words;
队头出队,从队尾入队。
3、方法
q.empty()
q.size()
q.front() // 返回队首元素的值
q.pop() // 删除队首元素的值
q.back() // 返回队尾元素的值
q.push(item) // 在队尾压入一个值;对于优先队列,基于优先级压入
6.6.4 priority_queue 优先队列
priority_queue允许用户为队列中的元素设置优先级。不是将新来的元素放在队列前面,而是放在比它优先级低的元素前面。
标准库默认使用元素类型的 < 操作判断优先级关系。
提供的方法,例如push(),与队列相同。
6.4 关联容器
顺序容器通过元素在容器中的位置存储和访问元素,关联容器通过key存储和读取元素。
6.4.1 关联容器类型
key, map, multimap, multiset
6.4.2 pair 类型
1、定义
在 utility 头文件中定义。
// 创建一个空的pair对象,它的两个元素分别是T1和T2类型,采用值初始化。
pair<T1, T2> p1;
// 创建一个pair对象,其中first成员初始化为v1,second成员初始化为v2。
pair<T1, T2> p1(v1, v2);
// 以v1和v2的值创建一个新的pair对象,其元素类型分别是v1和v2的类型。
p1 = make_pair(v1, v2);
// 两个pair对象间的小于运算,其定义遵循字典次序:如 p1.first < p2.first 或者 !(p2.first < p1.first) && (p1.second < p2.second) 则返回true。
p1 < p2;
// 如果两个对象的first和second依次相等,则这两个对象相等。
p1 == p2;
// 返回对象p1中名为first的公有数据成员
p1.first;
// 返回对象p1中名为second的公有数据成员
p1.second;
2、举例
(1). 初始化
std::pair<std::string, std::string> author3 = std::make_pair("Black", "k");
typedef std::pair<std::string, std::string> Author;
Author author1("James", "p");
Author author2("White", "j");
std::cout << author1.first << ' ' << author2.second << ' ' << author3.second << std::endl;
// 输出 James j k
(2). 与哈希表一起用
pair<char,int> charint;
unordered_map<char,int> unmap;
unmap{charint(' ',0),charint('s',1),charint('d',2),charint('.',4)};
6.4.3 map 类型
1、头文件
#include <map>
#include <unordered_map>
2、map 的声明与初始化
struct CityRecord {
std::string Name;
uint64_t Population;
double Latitude, Longitude;
};
// 声明
std::map<std::string, CityRecord> cityMap;
// std::unordered_map<std::string, CityRecord> cityMap;
// 初始化
cityMap["A"] = CityRecord{ "A", 50000, 2.5, 3.7 };
cityMap["B"] = CityRecord{ "B", 5800, 2.5, 3.7 };
cityMap["C"] = CityRecord{ "C", 5000, 2.5, 3.7 };
// 通过pair类型
cityMap.insert(std::make_pair("D", CityRecord{ "D", 6000, 2.5, 3.7 }));
3、使用下标访问
CityRecord& AData = cityMap["A"];
std::cout << AData.Population << std::endl;
// 输出 50000
当查找的key不存在时,map容器为这个key创建一个新元素,将它插入此map对象中,它的value采用值初始化(类元素使用默认构造函数,内置类型元素初始化为0)
下面这个例子创建map来记录单词出现的次数,注意,最开始map是空的。
map<string, int> word_count;
string word;
while(cin>>word)
++word_count[word];
4、map的迭代
map<string, int>::const_iterator it = word_count.begin();
while(it != word_count.end()){
std::cout << it->first;
++it;
}
4、查找
// 查找key为2的键值对是否存在 ,若没找到则返回m.end()
map.find(2);
// 判断找到了key为2的键值对
if(map.find(2)!=map.end())
// 使用count,返回的是被查找元素的个数。
// 如果有,返回1;否则,返回0。注意,map中不存在相同元素,所以返回值只能是1或0。
map.count(2);
5、判断是否为空
m.empty()
6、删除
// 删除key指向的元素
map.erase(k)
// 删除迭代器指向的元素
map.erase(p)
map.erase(begin, end)
6.4.4 set 类型
map是键值对的集合,set是单纯的键的集合。当只想知道一个值是否存在时,使用set最合适。
1、头文件
#include <set>
#include <unordered_set>
2、声明以及添加元素
std::unordered_set<int> set;
set<string> set1;
set1.insert(""hello);
使用vector初始化:
std::vector<int> v = { 1,2,3 };
std::set<int> set(v.begin(), v.end());
3、查找
与map相似
if(set.find(item) != set.end())
set.count(item)
6.4.5 multimap和multiset
允许一个key对应多个元素。
1、查找
不允许使用下标访问,因为一个key可能对应多个值。
方法一:
使用count求出这个key出现的次数n,find操作获得指向第一个该键元素的迭代器,由于这n个元素一定是相邻存放的,因此for循环n次就行了。
方法二:
iterator beg = multimap.lower_bound(key); // 指向键 >= key 的第一个元素
iterator end = multimap.upper_bound(key); // 指向键 > key 的第一个元素
while(beg != end){
cout << beg.second;
beg++;
}
方法三:
equal_range()返回两个迭代器的pair,分别于方法二中的两个迭代器对应。
pair<iterator, iterator> pos = multimap.equal_range(key);
while(pos.first!= pos.second){
cout << pos.first -> second;
++pos.first;
}
2、删除
erase(key)将消除拥有该key的所有元素。
6.3 迭代器iterator
每种容器都定义了自己的迭代器类型。例如这句话定义了一个名为iter的变量,它的数据类型是由vector< int >定义的iterator类型。
std::vector<int>::iterator iter;
6.3.1 begin和end操作
1、begin()
由begin返回的迭代器指向第一个元素,即v[0]
std::vector<int>::iterator iter = v.begin();
2、end()
由end返回的迭代器指向末端元素的下一个位置,是不存在的元素,起哨兵的作用,表示已经处理完容器。
不要存储end()操作返回的迭代器。因为对容器进行增删之后,将导致存储的内容失效,因为end()已经改变。
6.3.2 自增和解引用运算
// 将iter指向的元素设为0
*iter = 0;
// 将迭代器移动一个位置
iter++;
iter->mem // = (*iter).mem
6.3.3 算术操作
仅适用于vector和deque容器
std::vector<int> values = { 1, 2, 5, 7 };
std::vector<int>::iterator mid = values.begin() + values.size() / 2;
std::cout << *mid << std::endl;
// 输出 5
std::cout << *(mid+1) << std::endl;
// 输出 7
6.3.4 示例: vector的迭代器
std::vector<int> values = { 1, 2, 5, 6 };
for (std::vector<int>::iterator iter = values.begin(); iter != values.end(); iter++) {
std::cout << *iter << std::endl;
}
// 输出 1 2 5 6
6.3.5 const_iterator
对于const_iterator类型的迭代器,*iter是一个const,因此不能对其进行赋值操作,例如 *iter = 0;
因此const_iterator只能用于读取容器。
for (std::vector<int>::const_iterator iter = values.begin(); iter < values.end(); iter++) {
*iter = 0; // 错误用法
}
6.3.6 示例: 哈希表的迭代器
三种方式都输出AA 2 BB 5
#include <iostream>
#include <string>
#include <unordered_map>
int main() {
using Map = std::unordered_map<std::string, int>;
Map map;
map["AA"] = 2;
map["BB"] = 5;
// 1
for (Map::const_iterator it = map.begin(); it != map.end(); it++) {
std::cout << it->first << std::endl;
std::cout << it->second << std::endl;
}
// 2
for (auto keyValue : map) {
std::cout << keyValue.first << std::endl;
std::cout << keyValue.second << std::endl;
}
// 3 结构化绑定 C++17
for (auto [key, value] : map) {
std::cout << key << std::endl;
std::cout << value<< std::endl;
}
std::cin.get();
}
6.4 标准库bitset类型
6.4.1 头文件
#include <bitset>
6.4.2 定义以及初始化
// 定义
std::bitset<5> b;
// 1、用unsigned值初始化
bitset<16> b1(0xffff);
bitset<32> b2(0xffff);
// 2、用string对象初始化
std::string str("1100");
bitset<32> b3(str);
// b3的第二位和第三位为1,其余30位为0,用string初始化bitset是反着的。
6.4.3 bitset对象的操作
1、b.any() 是否存在1的位?
2、b.count() 返回1的个数
3、b.test(i) 第i位是否为1?
4、b.size()
5、b.reset() 都置为0;b.set() 都置为1;b.set(i) 把第i位置为1
6、b.flip() 都取反
7、输出
std::bitset<5> b;
std::cout << b << std::endl; // 输出00000
std::bitset<16> b(1100);
std::cout << b << std::endl;
// 输出1100的二进制表示
unsigned long ans = b.to_ulong();
std::cout << ans << std::endl;
// 输出1100
6.5 标准库array类型(静态数组)
6.5.1 C风格的数组
6.5.1.1 数组的初始化
C++提供了数组和指针,类似于vector和迭代器。
数组的长度是固定的,无法添加元素。
const unsigned array_size = 3;
int a[array_size] = { 1,2,3 };
// 显式初始化不需提供维数
int b[] = { 4,5,6,7 };
6.5.1.2 特殊的字符数组
这样的数组既可以用一系列char初始化,也可以用一个string初始化。
// string初始化时,需要一个额外的空字符用于结束字符串。
// ca1的长度可以初始化为3,ca3的长度至少要初始化为4
char ca1[] = { 'c','+','+' };
char ca2[] = { 'c','+','+','\0' };
char ca3[] = "c++";
std::cout << sizeof(ca1) / sizeof(char) << std::endl; // 输出 3
std::cout << sizeof(ca2) / sizeof(char) << std::endl; // 输出 4
std::cout << sizeof(ca3) / sizeof(char) << std::endl; // 输出 4
6.5.1.3 求数组长度
sizeof(数组名)/ sizeof(元素类型)
6.5.1.4 访问数组元素
通过下标访问
char ca3[5] = "c++";
std::cout << ca3[2] << std::endl;
// 输出 +
for (auto c : ca3) {
std::cout << c;
}
// 输出 c++
6.5.1.5 指针与数组
1、数组名是指向数组第一个元素的指针。
int a[] = { 4,5,6,7 };
int* p = a;
std::cout << *p; // 输出 4
std::cout << *(p + 2); // 输出 6
int* p1 = &a[3];
std::cout << *p1; // 输出 7
2、指针偏移
int a[] = { 4,5,6,7 };
std::cout << *p;
// 输出 4
std::cout << *(p + 2);
// 输出 6,指针偏移了2*4 = 8
std::cout << *(int*) ((char*)p + 8);
//输出 6
3、指针是数组的迭代器
const int size = 4;
int a[] = { 4,5,6,7 };
for (int *ptr = a, *end = ptr + size; ptr != end; ptr++) {
std::cout << *ptr << ' ';
}
// 输出 4 5 6 7
6.5.1.6 栈和堆创建数组
两种方式都能创建数组,但生命周期不同。
1、栈上,scope结束时自动摧毁数组
int another[5];
2、堆上,需要手动删除。不用new就不用delete
// 无初始化
int *another = new int[5];
// 有初始化,都初始化为0
int *another = new int[5]();
delete[] another;
没有new却delete将报错。
int i = 0;
int* p = &i;
delete p; // 报错
6.5.2 C风格字符串
尽量用C++的标准库类型string
6.5.2.1 C风格字符串的使用
1、C风格字符串的定义
C风格字符串是以空字符null结束的字符数组。例如ca2和ca3,而ca1不是C风格字符串,因为它不带结束符null。
char ca1[] = { 'c','+','+' };
char ca2[] = { 'c','+','+','\0' };
char ca3[] = "c++";
2、空终止字符的使用
char Example[7] = { 'x', 'i', 'n', 'g', 'y', 'u', 0 };
//char Example[7] = { 'x', 'i', 'n', 'g', 'y', 'u', '\0'};
std::cout << Example << std::endl; // 输出 xingyu
char Example2[8] = "xi\0ngyu";
std::cout << Example2 << std::endl;
// 输出 xi
std::cout << strlen(Example3) << std::endl;
// 输出2
3、用指针来操控C风格字符串
C++通过(const) char*类型的指针来操控C风格字符串,这个指针变量本身是一个变量,用于存放字符串的首地址。
字符串存放在以该首地址为首的一块连续的内存空间中,并以‘\0’作为串的结束。
const char *example = "xingyu";
// 也可写作 char* Example = "xingyu";
// 如果你知道你自己不会修改此字符串,就加上const
std::cout << example << std::endl;
// 输出 xingyu
// example是一个指针,指向第一个字符,本应输出内存地址,但定义为输出指向内存的内容。
// 查看首字符x的地址
std::cout << (int*) example<< std::endl;
std::cout << *example << std::endl; // 输出x
std::cout << *(example + 1) << std::endl; // 输出 i
4、可以换行的初始化方式
const char* Example2 = "hello\n"
"world\n"
"!\n";
//const char* Example2 = R"(hello
//world
//!)";
std::cout << Example2 << std::endl;
6.5.2.2 C风格字符串的标准库函数
1、头文件
#include <cstring>
它其实是C语言string.h的C++版本。
2、strlen(s)
char *b = { "hello" };
std::cout << strlen(b);
// 输出5,不包含结尾空结束符
3、
strncat(s1, s2, n) 将s2的前n个字符连接到s1后面,并返回s1
strncpy(s1, s2, n) 将s2的前n个字符复制给s1,并返回s1
4、动态数组的使用
const char* str1 = "success";
const char* str2 = "fail";
const char* tmp;
int situation = 2;
if (situation == 1) {
tmp = str1;
}
else {
tmp = str2;
}
int length = strlen(tmp) + 1;
char* output = new char[length];
strncpy(output, tmp, length);
std::cout << output;
6.5.3 标准库数组array
1、头文件
#include <array>
2、声明
长度不能改变,为常数。
std::array<int,5> Example; // 长度不能增长,为常数
3、赋值
Example[0] = 5;
Example[1] = 2;
4、输出元素
for (int index : Example) {
std::cout << index << std::endl;
}
5、排序
std::sort(Example.begin(),Example.end());
6、求长度
std::cout << Example.size() << std::endl;
// 输出 5
6.5.4 多维数组
6.5.4.1 多维数组的初始化
// 只初始化了每行的第一个元素
int a[3][4] = { {0},{4},{8} };
std::cout << a[1][0];
// 输出 4
6.5.4.2 指针和多维数组
1、5*5的二维数组
#include <iostream>
int main() {
//int* array = new int[5];
int** a2d = new int* [5];
// array[0]是一个int,a2d[0]是一个int指针
for (int i = 0; i < 5; i++) {
a2d[i] = new int[5];
}
// 释放内存过程:先删元素,再删保存指针的数组a2d
for (int i = 0; i < 5; i++) {
delete[] a2d[i];
}
delete[] a2d;
std::cin.get();
}
2、5* 5* 5的三维数组
int*** a3d = new int** [5];
for (int i = 0; i < 5; i++) {
a3d[i] = new int*[5];
for (int j = 0; j < 5; j++) {
a3d[i][j] = new int[5];
// 等于
//int** ptr = a3d[i];
//ptr[j] = new int[5];
}
}
//a3d[0][0][0] = 5;
6.8 泛型算法
#include <algorithm>
#include <numeric>
6.8.1 sort
std::vector<int> values = { 3,5,1,4,2 };
// 小到大排序
std::sort(values.begin(), values.end());
// 大到小排序
std::sort(values.begin(), values.end(),std::greater<int>());
6.8.2 stable_sort
sort是不稳定排序,基于指定的排序规则排序之后,具有相同顺序的多个元素的顺序可能是随机的;而stable_sort可以保证这些元素的相对次序与排序前不变。
// 特定排序规则:按字典序为默认规则,此处为按长度由低到高排序
bool isShorter(const std::string& s1, const std::string& s2) {
return s1.size() < s2.size();
}
int main() {
std::vector<std::string> values = { "a","cd","bcd","ab","dfsj" };
std::stable_sort(values.begin(), values.end(), isShorter);
}
7 栈与堆
7.1 作用域 ( scope )
// 1
{
}
// 2
if(){
}
// 3 类作用域
class Entity{
}
7.2 创建并初始化对象
7.2.1 在栈上创建
基于栈存储的变量,作用域(scope)结束之后,栈会自动销毁,变量也就被自动销毁。
栈的空间通常比较小,如果类较大或者类的对象较多,要去堆上创建。
#include <iostream>
#include <string>
using String = std::string;
class Entity {
private:
String Name;
public:
Entity() : Name("Unknown") {}
Entity(const String& name):Name(name) {}
const String& GetName() const
{
return Name;
}
};
int main() {
Entity entity;
std::cout << entity.GetName() << std::endl;
Entity entity2("xingyu");
// 效果等同 Entity entity2 = Entity("xingyu");
std::cout << entity2.GetName() << std::endl;
std::cin.get();
}
7.2.2 在堆上创建(new)
可以显式地控制对象的生存期。需要手动删除。
new关键字的作用:
1、在堆上找到一块足够大的内存,满足需求(例如Entity需要的内存),并返回给我们指向那块内存的指针。
2、调用构造函数。
Entity* entity = new Entity("xingyu");
// 返回这个entity在堆上被分配的内存的地址
std::cout << entity->GetName() << std::endl;
// 手动删除
delete entity;
7.2.3 replacement new
为其指定一块内存,而不需new关键字为我们寻找内存,仅需其起到调用构造函数的作用。
调用构造函数,在特定的地址初始化你的Entity。
int* b = new int[50];
Entity* e = new(b) Entity();
delete e;
delete[] b;
8 模板
例1:
只有在调用Print() 时,它才会被实际创建(用给定的模板参数)。
#include <iostream>
#include <string>
template<typename T>
void Print(T value) {
std::cout << value << std::endl;
}
int main() {
Print(5);
// Print<int>(5);
Print(5.5f);
Print("hello!");
std::cin.get();
}
例2:
template<int N>
class Array {
private:
int m_Array[N];
public:
int GetSize() const { return N; }
};
int main() {
Array<5> array;
std::cout<< array.GetSize()<<std::endl;
std::cin.get();
}
// 实际上:
//class Array {
//private:
// int m_Array[5];
//public:
// int GetSize() const { return 5; }
};
例3:
template<typename T, int N>
class Array {
private:
T m_Array[N];
public:
int GetSize() const { return N; }
};
int main() {
Array<int, 5> array;
//Array<std::string, 5> array;
std::cout<< array.GetSize()<<std::endl; // 输出5
std::cin.get();
}
9 宏
#include <iostream>
#define W std::cin.get()
int main() {
W;
}
1.4 VS 基本操作
1.4.1 格式化全部代码
Ctrl+A+K+F
1.4.2 批量注释代码
注释代码:Ctrl+K+C
反注释代码:Ctrl+K+U

















 4241
4241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









