




 本文探讨了数据存储的发展历程,从数据库、数据仓库到混合数据库和数据湖。介绍了HTAP的概念,以及阿⾥云OSS数据湖的特点和应用场景。同时,提到了现代数据湖的三个主流开源框架,强调了湖仓一体化的趋势。
本文探讨了数据存储的发展历程,从数据库、数据仓库到混合数据库和数据湖。介绍了HTAP的概念,以及阿⾥云OSS数据湖的特点和应用场景。同时,提到了现代数据湖的三个主流开源框架,强调了湖仓一体化的趋势。
一、从数据库到数据仓库再到混合数据库
1.1 数据库vs数据仓库vs混合数据库vs数据湖
| 场景 | 典型代表 | 主要优缺点 | |
| 数据库 | OLTP | 三大数据库(Oracle、MySQL、SQLServer) | OLTP支持的非常好,OLAP支持弱 |
| 数据仓库 | OLAP | Teradata、Greenplum、Hive+HDFS、ClickHouse、Kylin | OLAP支持的非常好,OLTP不支持或者支持弱 |
| 混合数据库 | HTAP=OLTP+OLAP | Kudu(先OLAP在OLTP)、TiDB(先OLTP在OLAP) | OLTP+OLAP都支持但都为支持到极 致,折中方案嘛,毕竟是有所取舍 |
| 数据湖 | HTAP+(增强版) | Hudi、Iceberg、DeltaLake | 除了HTAP的一些场景,还能支持各种格式 |
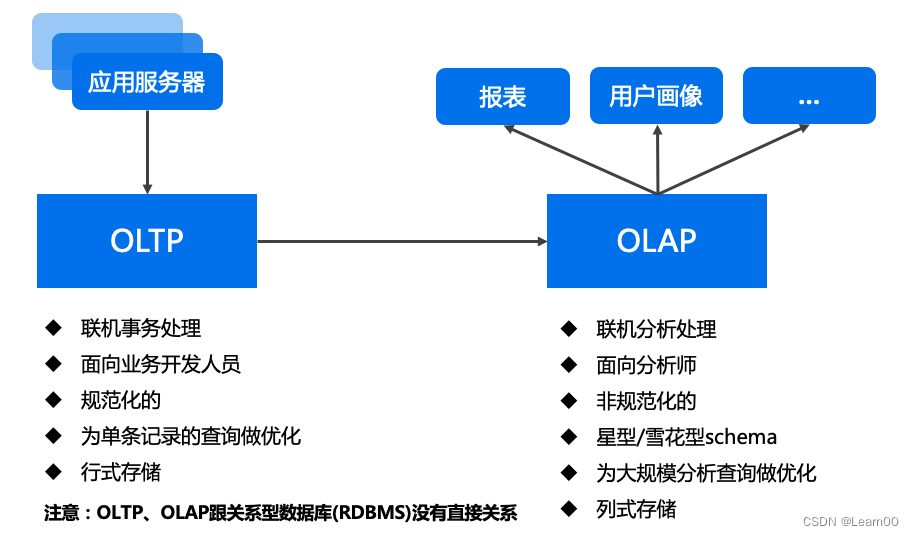
1)、数据库 DataBase,⼀般简称 DB,主要是做 OLTP(online transaction processing),即在线的交易的增删 查改,强调事物和⾼并发。⼀般数据库采⽤⾏存储。
2)、数据仓库 Data Warehouse,简称 DW,主要是来做OLAP(online analytics processing),也就是在线数据 分析,⽤于数据分析场景。⼀般数据仓库采⽤列存储
1.2 HTAP
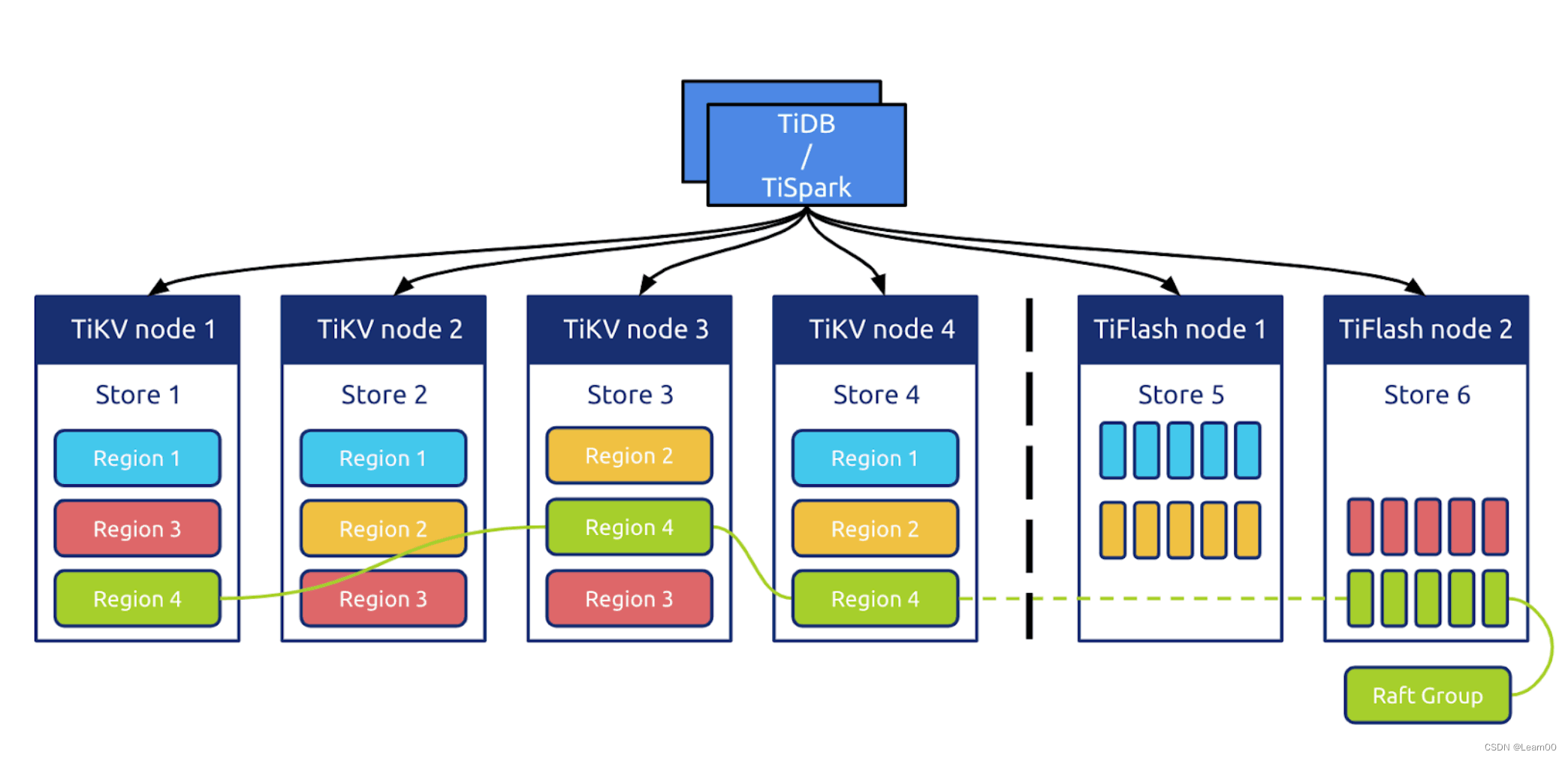
混合数据库以Kudu、TiDB为代表,是为了去掉OLTP到OLAP之间的链路。虽然OLTP+OLAP都⽀持,但都未⽀持到极致,折中⽅案嘛,毕竟是有所取舍。

二、从混合数据库到数据湖
数据湖并不是新概念,最早 2015
年就被提出来了,
数据湖顾名思义就是⼀个巨⼤的原始数据的集中存储站
,也经历了很多年的发展,直到最近⼏年才被重视起来。
维基百科的定义:
数据湖是⼀个以原始格式(通常是对象块或⽂件)存储数据的系统或存储库
。数据湖通常是所 有企业数据的单⼀存储。⽤于报告、可视化、⾼级分析和机器学习等任务。数据湖可以包括来⾃关系数据库的结构 化数据(
⾏和列
)
、半结构化数据
(CSV
、⽇志、
XML
、
JSON)
、⾮结构化数据
(
电⼦邮件、⽂档、
pdf)
和⼆进制数据
(
图 像、⾳频、视频)
。定义中的重点内容我⽤红⾊字体标注出来,简单说明⼀下这⼏点。
原始格式
:数据不做预处理,保存数据的原始状态
单⼀存储
:存储库中会汇总多种数据源,是⼀个单⼀库
用于机器学习
:除了 BI
、报表分析,数据湖更适⽤于机器学习(从
BI
到
AI
)
2.1 早期数据湖
无论是数据库、数据仓库还是混合数据库都只停留在结构化数据的存储,对于半结构化、⾮结构化的数据例如⾳频、视频等都不⽀持或者变相⽀持。早期数据湖的⽬的就是为了存储海量的、不同格式、汇总或者明细的数据,数 据量可以达到 PB 到 EB 级别。
早期数据湖的出现解决了存储海量的、不同格式、汇总或者明细的数据的难题,数据量可以达到 PB
到
EB
级别。 在数据湖上,不仅可以做数据分析(BI
场景),还可以⽤于
AI
场(需要的原始数据存储量是⾮常⼤的,⽽且模式是 不可预知的)。
早期Hadoop
可以当做数据湖来使⽤(没听错,真的),但是早期数据湖主要是⽤于数据的存储,解决的是容量的 ⽔平扩展性、数据的持久性和⾼可⽤性,没有太多考虑数据的更新和删除。例如 HDFS
上通常是将⽂件分块 (block
)存储,⼀个
block
通常⼀两百兆;
S3
同样也是类似,⼤的
block
可以节省管理开销,并且这些⽂件格式 不⼀,通常没有⾼效的索引。如果要修改⽂件中的某⼀⾏记录,对于数据湖来说是⾮常难操作的,因为它不知道要 修改的记录在哪个⽂件的哪个位置,它提供的⽅式仅仅是做批量替换,代价⽐较⼤。
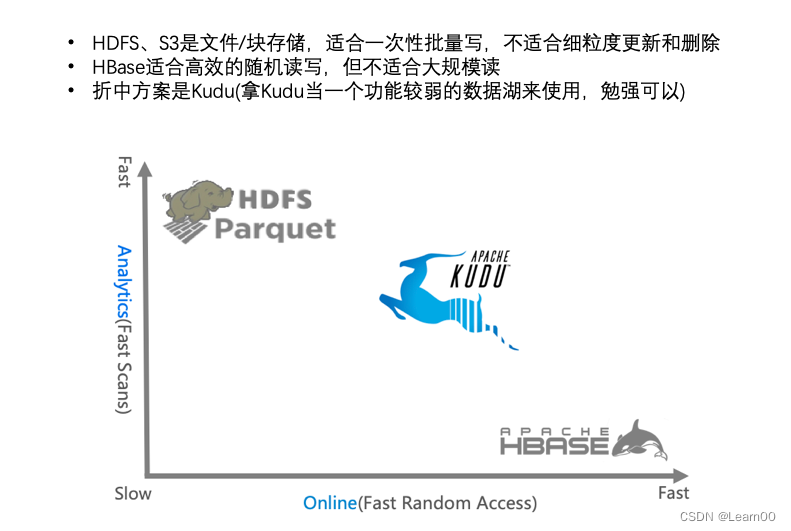
另外⼀个极端的存储则是像 HBase
这样的,提供⾼效的主键索引,基于主键就可以做到⾮常快的插⼊、修改和删 除;但是 HBase
在⼤范围读的效率⽐较低,因为它不是真正的列式存储。对于⽤户来说⾯临这么两个极端:⼀边 是⾮常快的读存储(HDFS/S3
),⼀边是⾮常快速的写存储;如果取中间的均衡⽐较困难。有的时候却需要有⼀种 位于两者之间的⽅案:读的效率要⾼,但写开销不要那么⼤。
2.2 现代数据湖
现在各⼤公有云都有⾃⼰的数据湖产品,例如 Amazon S3
,
Azure Blob store
,阿⾥云
OSS
,以及各家云⼚商都有 ⾃⼰的存储服务。有了数据湖之后,企业⼤数据处理就有了⼀个基础平台,⾮常多的数据从数据源收集后都会先落到数据湖上,基于数据湖再处理和加载到不同的分析库去。
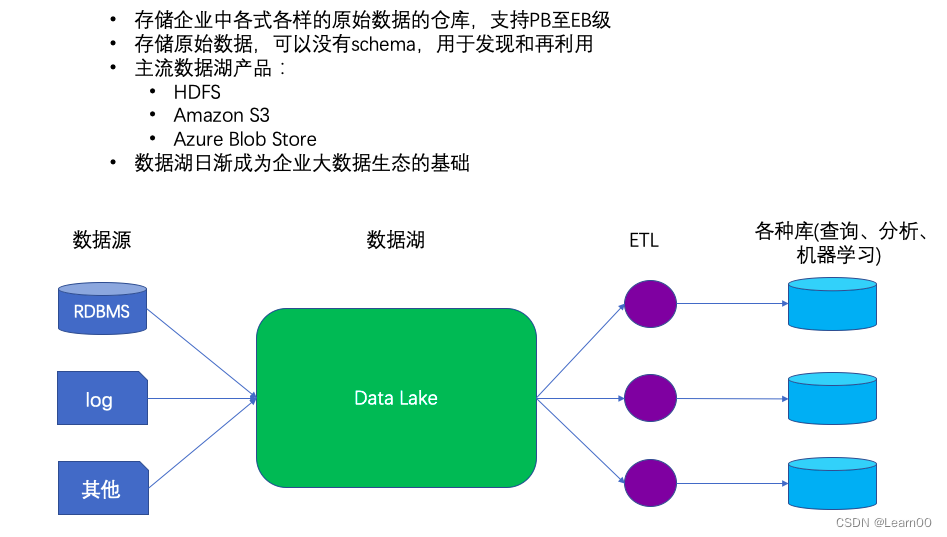
2.3 阿⾥云OSS数据湖简介
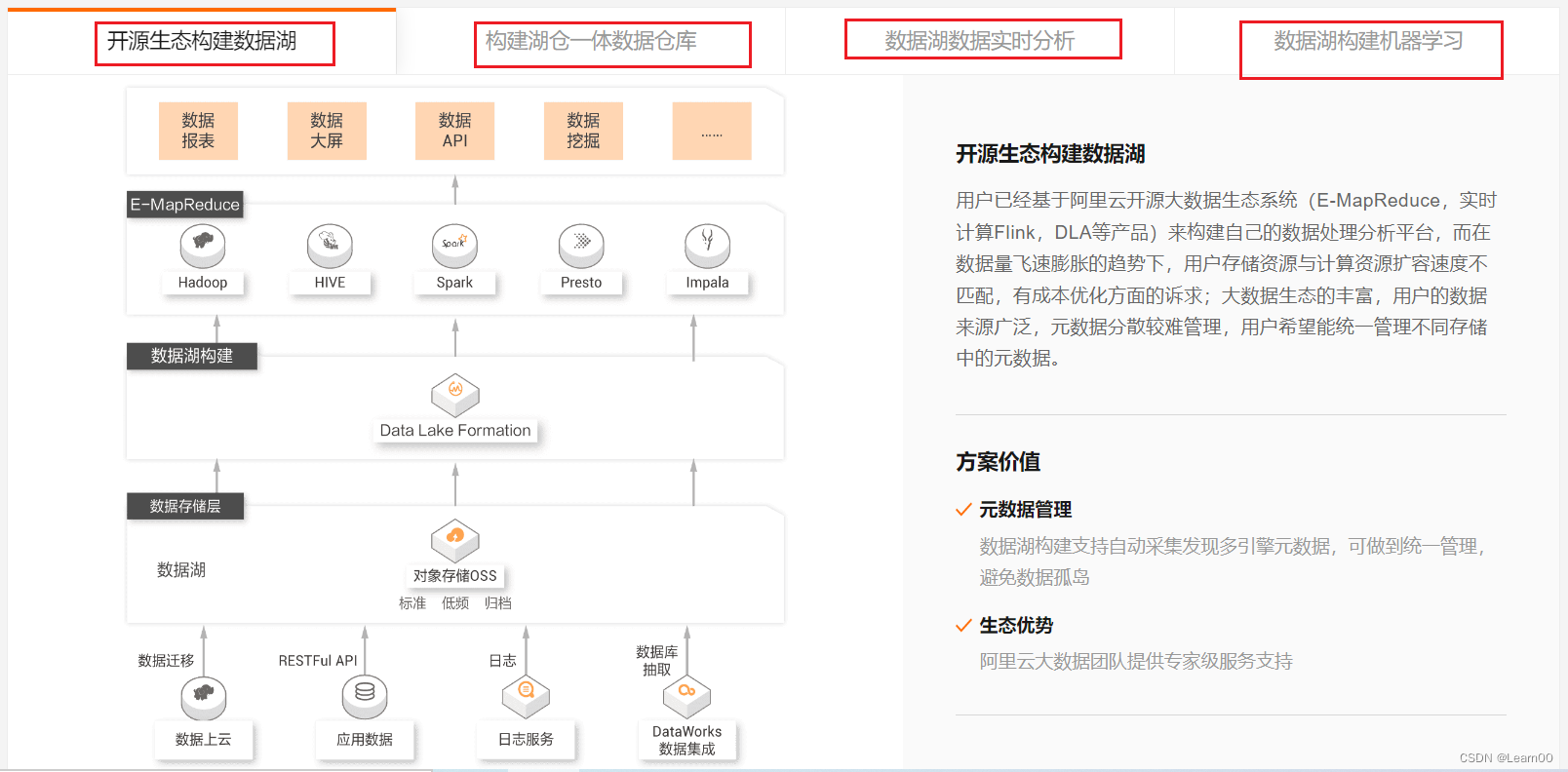
1)、简介

2)、产品优势

3)、丰富的应用场景
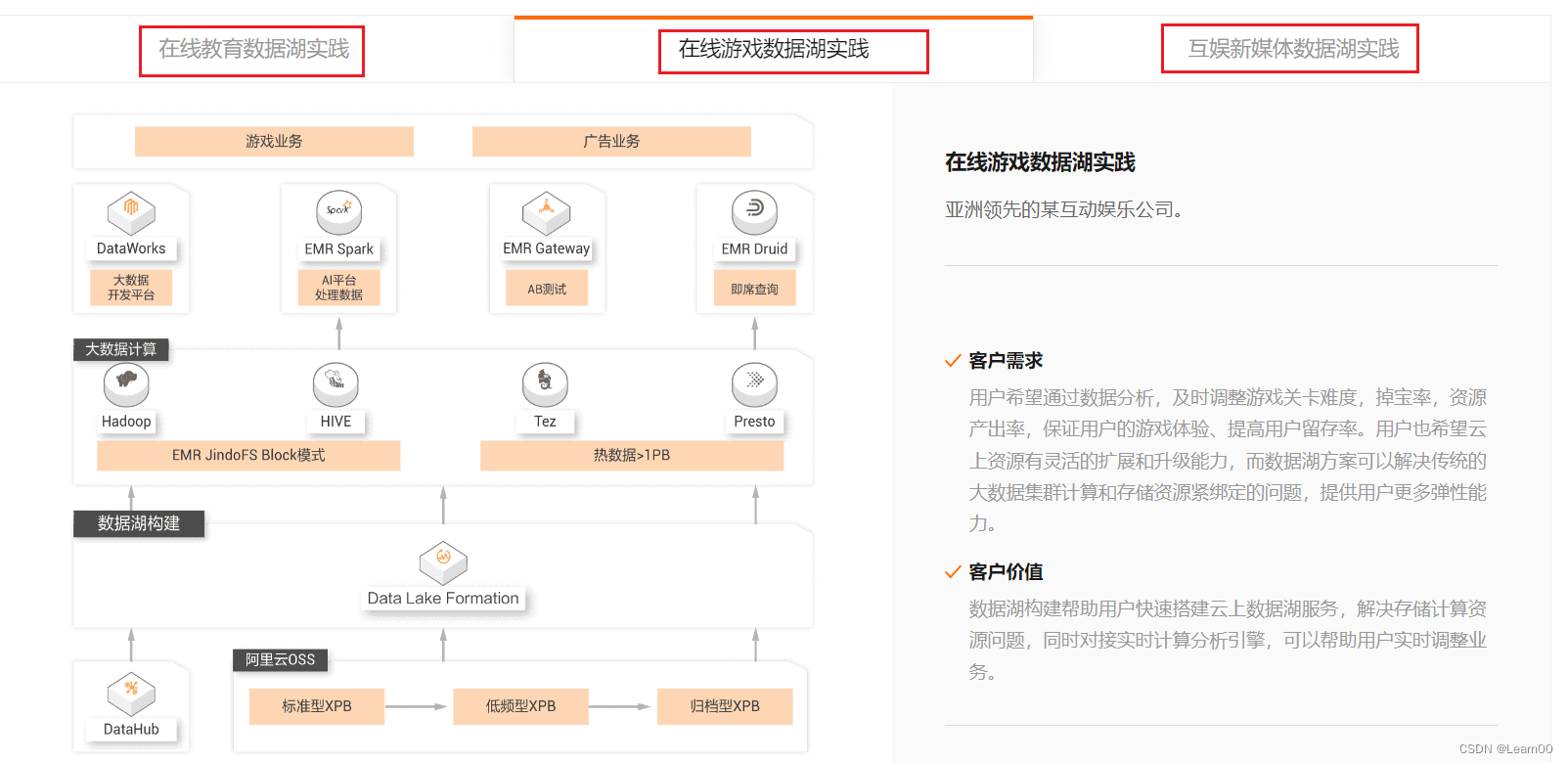
4)、丰富的客户案例
5)、产品与时俱进
 2.4 三⼤开源数据湖框架
2.4 三⼤开源数据湖框架
数据湖是⼀整套解决⽅案,并不仅仅是⼀个存储,业界流⾏的开源数据湖框架有三个:
Hudi 、Iceberg 、DeltaLake
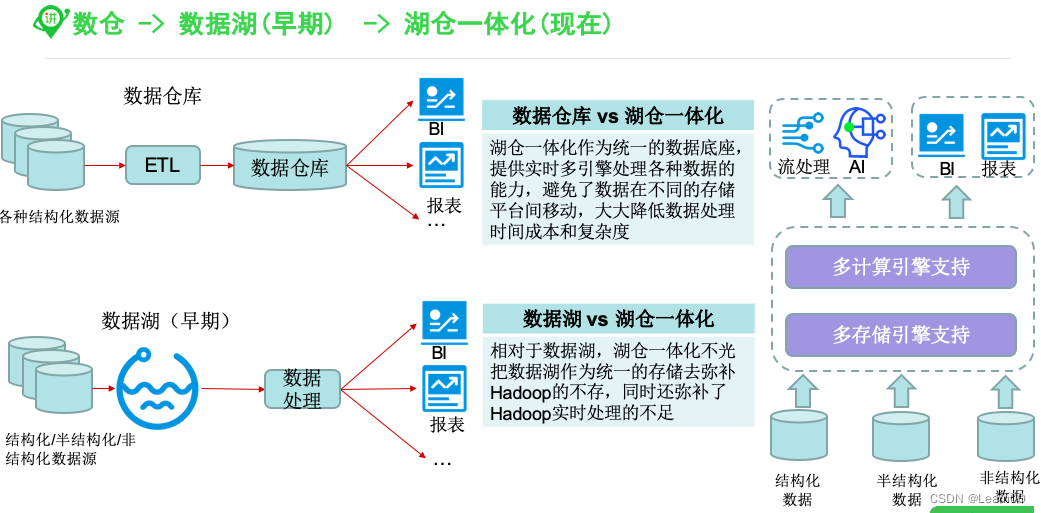
三、湖仓⼀体化
有了数据湖之后,企业⼤数据处理就有了⼀个基础的存储平台,各种类型的数据从源头收集后都会先落到数据湖上,基于数据湖再处理或者加载到不同的特定存储中去。
如果数据采集到数据湖(ODS),以数据湖为中⼼来完成数仓建设就是所谓的湖仓⼀体化。


















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









