




 本文介绍了XPath的基本用法,包括选取XML或HTML文档中的节点和节点集。通过实例展示了如何利用XPath表达式选取特定标签、属性值以及文本内容。还提供了在Python中使用lxml模块进行XPath数据提取的步骤。
本文介绍了XPath的基本用法,包括选取XML或HTML文档中的节点和节点集。通过实例展示了如何利用XPath表达式选取特定标签、属性值以及文本内容。还提供了在Python中使用lxml模块进行XPath数据提取的步骤。
XPath (XML Path Language) 是一门在 HTML\XML 文档中查找信息的 语言,可用来在 HTML\XML 文档中对 元素和属性进行遍历。
xpath基本介绍和使用
-
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
-
使用chrome插件选择标签时候,选中时,选中的标签会添加属性class="xh-highlight"
xpath中常用的获取节点的表达式

- /表示就是 标签和标签之间的过渡
- //表示就是跨标签去定位标签,//a表示将当前页面中所有的a标签选中
- .表示当前路径
- @属性名: 获取到标签中属性的值
- text():获取标签中的文本内容**
栗子:
豆瓣电影top250的页面来练习:https://movie.douban.com/top250
1 选择所有的h1下的文本
//h1/text()

2获取所有的a标签的href
//a/@href

3获取html下的head下的title的文本
//html/head/title/text()

4获取html下的head下的link标签的href
/html/head/link/@href

xpath中常用的获取特定节点的表达式
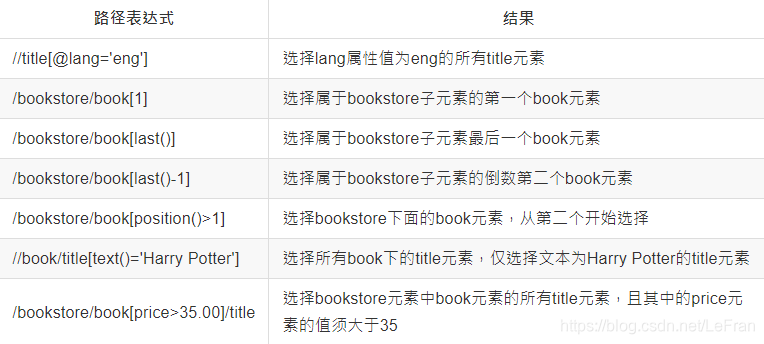
- //标签名[@属性名=值] 根据标签的属性以及属性的值获取特定的标签
- //标签名[num] 获取选取到的所有标签的第几个标签,num从 1 开始。
- //标签名[last()] 获取选取到的所有的标签的最后一个标签,注意:最后一个不是 -1。
- //标签名[text()=值] 根据标签中的文本内容的值,获取到某个标签。。
- //标签名[position()>num] 表示从第num个标签获取
- //标签名[position()<num] 表示从第一个获取到第num个标签
栗子:
豆瓣电影top250的页面来练习:https://movie.douban.com/top250
1 选取所有的电影的名字:
先定位到 class=hd的div标签,再取下面的a标签下面的第一个span标签
//div[@class=‘hd’]/a/span[1]
//span[@class=‘title’][1]


2 选取所有的href:
先定位到 class=hd的div标签,再取下面的a标签中href属性的值
//div[@class=‘hd’]/a/@href


3 选取所有的评分:
//div[@class=‘star’]/span[@class=‘rating_num’]
//span[@class=‘rating_num’]/text()


4 选取所有的评价人数:
//div[@class=‘star’]/span[last()]

- lxml 模块可以让我们在Python代码中去使用 xpath 语法表达式来进行对 html/xml 数据进行提取
- 将转换后的Element对象再转换成html_str, 可以使用 etree.tostring(element).decode()
- 一般使用xpath来提取数据,都是会先对数据进行分组,然后再遍历提取。
使用步骤
导包: from lxml import etree
将html字符串转换成Element对象: element = etree.HTML(html_str)
使用Element对象中的xpath方法书写xpath表达式,来定位或者获取标签中的内容: element.xpath(xpath_str)
使用xpath语法如果定义到标签,返回的就是一个列表,列表中的每个元素是一个Element对象,可以遍历再去使用 Element.xpath() 方法继续提取数据。


















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









