




查看默认的java垃圾回收器
jinfo -flag -XX:+PrintcommandLineFlags 进程ID
根据端口抓包
tcpdump -i eth0 tcp port 4347 -XX -vv >> dump.out
Linux 常用高级命令
序号 命令 命令解释
top 查看内存
df -h 查看磁盘存储情况
iotop 查看磁盘 IO 读写(yum install iotop 安装)
iotop -o 直接查看比较高的磁盘读写程序
netstat -tunlp | grep 端口号 查看端口占用情况
uptime 查看报告系统运行时长及平均负载
ps aux 查看进程
nohup
nohup [command] > /log.txt 2>&1 &
该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。 nohup就是不挂起的意思, 不挂断地运行命令。
说明 2: awk 默认分隔符为空格
说明 3: xargs 表示取出前面命令运行的结果, 作为后面命令的输入参数。
命令行kill
ps -ef | grep xxx | grep -v grep |awk '{print \$2}' | xargs kill
Linux 环境变量
1) 修改/etc/profile 文件: 用来设置系统环境参数, 比如$PATH. 这里面的环境变量是对
系统内所有用户生效。 使用 bash 命令, 需要 source /etc/profile 一下。
2) 修改~/.bashrc 文件: 针对某一个特定的用户, 环境变量的设置只对该用户自己有效。
使用 bash 命令, 只要以该用户身份运行命令行就会读取该文件。
3) 把/etc/profile 里面的环境变量追加到~/.bashrc 目录
[atguigu@hadoop102 ~]$ cat /etc/profile >> ~/.bashrc
4) 说明
登录式 Shell, 采用用户名比如 atguigu 登录, 会自动加载/etc/profile
非登录式 Shell, 采用 ssh 比如 ssh hadoop103 登录, 不会自动加载/etc/profile, 会自动
加载~/.bashrc
扫描jar包是否有某个类
for i in *.jar;do jar -tvf "$i" | grep -Hsi classPathName && echo "$i";done
pwconv
Linux pwconv命令用于开启用户的投影密码。
Linux系统里的用户和群组密码,分别存放在名称为passwd和group的文件中, 这两个文件位于/etc目录下。因系统运作所需,任何人都得以读取它们,造成安全上的破绽。投影密码将文件内的密码改存在/etc目录下的shadow和gshadow文件内,只允许系统管理者读取,同时把原密码置换为"x"字符,有效的强化了系统的安全性。
pwconv
passwd: Authentication token manipulation error
chattr -i /etc/passwd
chattr -i /etc/shadow
# 使用lsattr查看是否这个的结果
lsattr /etc/passwd /etc/shadow
--------------e----- /etc/passwd
--------------e----- /etc/shadow
然后正常修改密码,最后
chattr +i /etc/passwd
chattr +i /etc/shadow
Linux free 详解
https://www.cnblogs.com/ultranms/p/9254160.html
CentOS主机名显示不全的问题
vim .bashrc
PS1="[\u@\H \W]\$"
source .bashrc
Linux查看磁盘占用
cd /
du -ah --max-depth=1 | sort -gr
查找除了挂载分区的其他文件夹,找到大的日志等文件删除即可
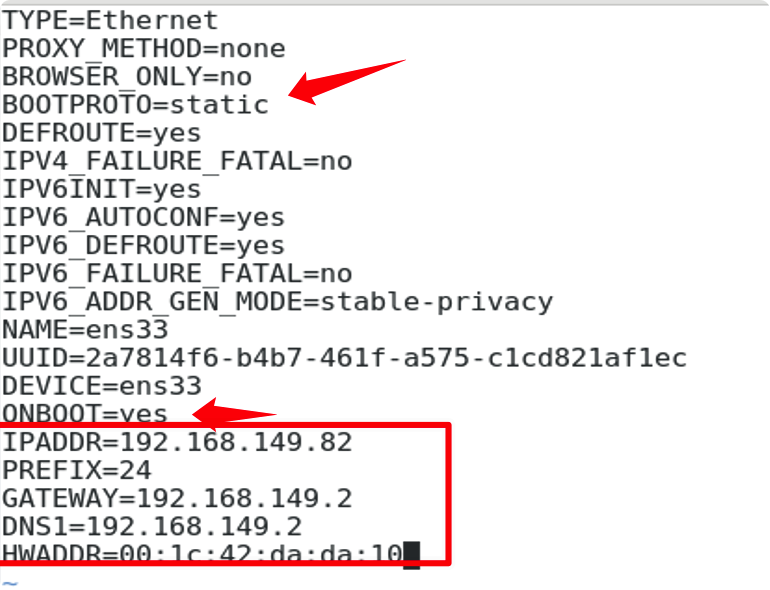
Linux修改网卡
vim /etc/sysconfig/network-script/ifcfg-xxxx
reboot
scp指定端口
scp -P port local_file user@host:/dir
启用、禁用ipv6
# 启用
sudo sh -c 'echo 0 > /proc/sys/net/ipv6/conf/ens33/disable_ipv6'
# 禁用
sudo sh -c 'echo 1 > /proc/sys/net/ipv6/conf/ens33/disable_ipv6'
使用grep、diff比较文件的内容
# 查找文件中相同的数据
grep -f file1 file2
# 对比文件中不同的数据
diff file1 file2
# 如果diff 结果为0 说明俩文件数据相同否则两个文件不相同
两种常用的去重操作
awk '!visited[$0]++ {print $0}' your_file
这个脚本维护一个关联数组,索引(键)为文件中去重后的行,每个索引对应的值为该行出现的次数。对于文件的每一行,如果这行(之前)出现的次数为 0,则值加 1,并打印这行,否则值加 1,不打印这行。
命令解析:
- 这个 awk “脚本” !visited[$0]++ 对输入文件的每一行都执行。
- visited[] 是一个 关联数组 (又名 映射 )类型的变量。awk 会在第一次执行时初始化它,因此我们不需要初始化。
- $0 变量的值是当前正在被处理的行的内容。
- visited[$0] 通过与 $0(正在被处理的行)相等的键来访问该映射中的值,即出现次数(我们在下面设置的)。
- ! 对表示出现次数的值取反:在 awk 中, 任意非零的数或任意非空的字符串的值是 true 。变量默认的初始值为空字符串 ,如果被转换为数字,则为 0。也就是说:如果 visited[$0] 的值是一个比 0 大的数,取反后被解析成 false。如果 visited[$0] 的值为等于 0 的数字或空字符串,取反后被解析成 true 。++ 表示变量 visited[$0] 的值加 1。如果该值为空,awk 自动把它转换为 0(数字) 后加 1。注意:加 1 操作是在我们取到了变量的值之后执行的。
总的来说,整个表达式的意思是:
- true:如果表示出现次数为 0 或空字符串
- false:如果出现的次数大于 0
awk 由 模式或表达式和一个与之关联的动作 组成:
<模式/表达式> { <动作> }
如果匹配到了模式,就会执行后面的动作。如果省略动作,awk 默认会打印(print)输入。省略动作等价于 {print $0}。
我们的脚本由一个 awk 表达式语句组成,省略了动作。因此这样写:
awk '!visited[$0]++' your_file > deduplicated_file
等于这样写:
awk '!visited[$0]++ { print $0 }' your_file > deduplicated_file
对于文件的每一行,如果表达式匹配到了,这行内容被打印到输出。否则,不执行动作,不打印任何东西。
https://www.toutiao.com/i6769411636986905091/
另一种方式:cat data.log | sort | uniq
awk sed sort 结合使用例子
查看sda1占用磁盘大小去掉% -f ":" 以冒号为分隔符
awk是选择第几列,sed是过滤 格式sed 's/要替换的东东/用什么替换(可以为空)/'
df | grep /dev/sda1 | awk '{print $5}' | sed 's/%//'
sort默认是从小到大 -r逆序 -k指第几列 -n为按照数值大小排序
从小到大取最后三行
grep "2014-02-*" gpdata.txt | sort -n -k7 | tail -3
从大到小取头头三行
grep "2014-02-*" gpdata.txt | sort -n -k7 -r | head -3
sort命令详解
1. 获得目录下文件大小的顺序
ls -al | sort -k5 -rn
-k5从第5列开始显示
-k来指定列数
-rn sort默认的排序方式是升序,如果想改成降序,就加个-r就搞定了,就要使用-n选项,来告诉sort,“要以数值来排序”!
2. 获得当前系统中运行的最占内存的前10个程序
ps aux | sort -k6 -rn | head -n10 从第6列显示内存
3. 你最常使用的前十个shell命令
history | sort -k4 | awk '{print $4}' | uniq -c | sort -k1 -nr | head -n10
查看CPU
cat /proc/cpuinfo | grep "physical id" | uniq | wc -l #可以看出物理cpu的总个数。
cat /proc/cpuinfo | grep "cpu core" | uniq #可以看出每个cpu的核数。
cat /proc/cpuinfo | grep "processor" | wc -l #可以看出逻辑cpu的个数。
jvm的一些命令
- jstat
https://www.jianshu.com/p/73dcfb526b3a
--每隔5s监控一次内存回收情况
jstat -gcutil pid 5s
E 代表 Eden 区使用率
O(Old)代表老年代使用率
P(Permanent)代表永久代使用率
CCS 压缩使用比例
M 元空间(MetaspaceSize)已使用的占当前容量百分比
YGC(Young GC)代表Minor GC 次数
YGCT代表Minor GC耗时
FGC(Full GC)代表Full GC次数
FGCT(Full GC)代表Full GC耗时
GCT代表Minor & Full GC共计耗时
或者
jstat -gc pid 5s
S0C、S1C、S0U、S1U:Survivor 0/1区容量(Capacity)和使用量(Used)
EC、EU:Eden区容量和使用量
OC、OU:年老代容量和使用量
PC、PU:永久代容量和使用量
YGC、YGT:年轻代GC次数和GC耗时
FGC、FGCT:Full GC次数和Full GC耗时
GCT:GC总耗时
- jps
--jps主要用来输出JVM中运行的进程状态信息,如果不指定hostid就默认为当前主机或服务器。
jps [options] [hostid]
-q 不输出类名、Jar名和传入main方法的参数
-m 输出传入main方法的参数
-l 输出main类或Jar的全限名
-v 输出传入JVM的参数
- jstack
--jstack主要用来查看某个Java进程内的线程堆栈信息
jstack [option] pid
jstack [option] executable core
jstack [option] [server-id@]remote-hostname-or-ip
-l long listings,会打印出额外的锁信息,在发生死锁时可以用jstack -l pid来观察锁持有情况
-m mixed mode,不仅会输出Java堆栈信息,还会输出C/C++堆栈信息(比如Native方法)
jstack可以定位到线程堆栈,根据堆栈信息我们可以定位到具体代码,所以它在JVM性能调优中使用得非常多。下面我们来一个实例找出某个Java进程中最耗费CPU的Java线程并定位堆栈信息,用到的命令有ps、top、printf、jstack、grep。
eg:
top -Hp pid 找到TIME+ 最长时间的线程id 比如为 110
或者 ps -mp pid -o THREAD,tid,time
printf "%x\n" 110 比如得到 f801
jstack pid |grep f801 -A 30 得到信息
- jmap(Memory Map)和jhat(Java Heap Analysis Tool)
--jmap用来查看堆内存使用状况,一般结合jhat使用。
jmap [option] pid
jmap [option] executable core
jmap [option] [server-id@]remote-hostname-or-ip
eg :
1. jmap -permstat pid
打印进程的类加载器和类加载器加载的持久代对象信息,输出:类加载器名称、对象是否存活(不可靠)、对象地址、父类加载器、已加载的类大小等信息
2. jmap -heap pid
查看进程堆内存使用情况
3. jmap -histo[:live] pid
查看堆内存中的对象数目、大小统计直方图,如果带上live则只统计活对象
class name是对象类型,说明如下:
B byte
C char
D double
F float
I int
J long
Z boolean
[ 数组,如[I表示int[]
[L+类名 其他对象
4. jmap -dump:format=b,file=dumpFileName
用jmap把进程内存使用情况dump到文件中,再用jhat分析查看
eg :jmap -dump:format=b,file=/tmp/dump.dat pid
jhat -port 9998 /tmp/dump.dat 使用jhat查看
linux单引号和双引号的区别
#!/bin/bash
do_date=$1
echo '$do_date'
echo "$do_date"
echo "'$do_date'"
echo '"$do_date"'
echo `date`
结果:
$do_date 2020-03-10
'2020-03-10'
"$do_date"
2020 年 05 月 02 日 星期四 21:02:08 CST
总结:
(1) 单引号不取变量值
(2) 双引号取变量值
(3) 反引号`, 执行引号中命令
(4) 双引号内部嵌套单引号, 取出变量值
(5) 单引号内部嵌套双引号, 不取出变量值
ssh远程执行命令没有成功问题
应该用 ssh -t xxxx -t:虚拟终端
运行shell脚本自动输入密码
1. 管道符
#!/bin/bash
echo mypassword | sudo -S apt-get update
2. 文本输入从定向
#!/bin/bash
sudo -S apt-get update << EOF
mypassword
EOF
java执行
java-classpath 需要在 jar 包后面指定全类名; java -jar 需要查看一下解压的 jar 包 META-INF/MANIFEST.MF 文件中,Main-Class 是否有全类名。如果有可以用 java -jar,如果没有就需要用到 java -classpath
/dev/null 代表 linux 的空设备文件,所有往这个文件里面写入的内容都会丢失,
俗称“黑洞”。
标准输入 0:从键盘获得输入 /proc/self/fd/0
标准输出 1:输出到屏幕(即控制台) /proc/self/fd/1
错误输出 2:输出到屏幕(即控制台) /proc/self/fd/2
Linux前台、后台、挂起、退出、查看命令汇总
command & 直接在后台运行程序
ctrl+c 退出前台的命令,不再执行
ctrl+z挂起前台命令暂停执行,回到shell命令行环境中
bg 将刚挂起的命令放到后台运行
bg %3 将第三个job放到后台运行
kill %3 杀死第三个job,不再执行
fg 将刚挂起的命令返回前台运行
fg %3 将第三个job返回前台运行
jobs 察看当前shell下运行的所有程序;带+表示最新的jobs;带-表示次新的jobs;其他jobs不带符号
nohup=no hang up,不挂断,如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束,那么可以使用nohup命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程.长命令必须写在shell文件中,否则nohup不起作用
nohup command & //该命令的一般形式
nohup command > myout.file 2>&1 & //log输出到myout.file,并将标准错误输出重定向到标准输出,再被重定向到myout.file
Linux查看某个端口的连接数
https://www.cnblogs.com/EasonJim/p/8098532.html
centos 7 重启后发现网卡启动不了
解决方式:禁用NetworkManager
1. systemctl stop NetworkManager
2. systemctl disable NetworkManager
3. systemctl start network
切换yum源
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
centos 6
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
centos 7
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
tailf , tail -F tail -f 的区别
tail -f
等同于--follow=descriptor,根据文件描述符进行追踪,当文件改名或被删除,追踪停止
tail -F
等同于--follow=name --retry
根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪
tailf
等同于tail -f -n 10(貌似tail -f或-F默认也是打印最后10行,然后追踪文件)
与tail -f不同的是,如果文件不增长,它不会去访问磁盘文件
所以tailf特别适合那些便携机上跟踪日志文件,因为它减少了磁盘访问,可以省电
一般使用tail -F
sed 替换文本
!!!如果使用变量,需要用双引号
sed -i -e "s/$1/$2/g" file
清空yum
## 清空yum
#清理/var/cache/yum的headers
yum clean headers
#清理/var/cache/yum下的软件包
yum clean packages
yum clean metadata
查看内存&清除缓存
free -m (MB)
free -h (GB)
echo 3 > /proc/sys/vm/drop_caches
zip & unzip
将 /home/html/ 这个目录下所有文件和文件夹打包为当前目录下的 html.zip:
zip -q -r html.zip /home/html
查看压缩包的文件
unzip -l abc.zip
-v 参数用于查看压缩文件目录信息,但是不解压该文件。
-d<目录> 指定文件解压缩后所要存储的目录。
linux 查看 开机启动项
systemctl list-unit-files | grep enable
python pip 切换源
pip install --no-cache-dir -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com -r /tmp/requirements.txt
strace实时查看进程日志输出
在linux下有的时候程序的运行出现问题了,但是这时如果没有将日志打印到文件,想查看一下日志的输出都看不了,停了程序重新跑又一时不能浮现问题,是一件很纠结的事情。
这个时候就可以利用strace 来变通的看一下日志,strace是一个用来跟踪进程执行时的系统调用和所接收的信号的程序会将程序的系统调用情况打印出来。而我们的日志输出,比如printf到了系统调用这一层,使用的是write,于是我们可以利用这一点动态的查看printf的输出。
strace常用来跟踪进程执行时的系统调用和所接收的信号。
在Linux世界,进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通过系统调用访问硬件设备。strace可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗的时间。
比如如下命令来查看进程pid为1648的printf输出
strace -e trace=write -s 200 -f -p 1648
-e trace=write 的意思是设置一个表达式,用来控制如何跟踪,这里表示只跟踪write的系统调用情况
-s 200 的意思是字符串输出显示时的最大长度,默认是32个字节,对于printf的打印可能不够,这里我们设置为200
-f 的意思是需要跟踪子进程forks,这里对线程同样适用,不加这个参数只能输出main所在的线程的信息。
-p 1648 指定要跟踪的进程号为1648
如需要保存到文件则使用-o 参数
strace -o out.strace -e trace=write -s 200 -f -p 1648
弊端:CPU占用率较高,这里虽然只显示了write的调用,但实际上strace还是在探测所有的系统调用,只是过滤显示了write
wine
https://gitee.com/wszqkzqk/deepin-wine-for-ubuntu
防火墙
#如果打不开Web界面,就需要开启防火墙,一般CentOS系统出现情况最多
#Centos 6系统
- 开放端口
iptables -I INPUT -p tcp --dport 8090 -j ACCEPT
service iptables save
service iptables restart
service iptables stop 关闭防火墙
service iptables start 开启防火墙
service iptables status 查看防火墙状态
# 永久关闭
chkconfig iptables off
#CentOS 7系统
systemctl status firewalld.service
systemctl stop firewalld.service
systemctl disable firewalld.service
环境变量的配置
- 安装Linux的一些软件时,总要修改Linux的配置文件。当时也是一知半解。而且,网上有些安装教程,会说,修改配置文件后要重启Linux。但事实上是不需要重启的。
- Linux安装时可能要修改的配置文件:/etc/profile、/etc/bashrc(ubuntu没有这个文件,对应地,其有/etc/bash.bashrc文件。我用的是ubuntu系统,所以下面将一律使用/etc/bash.bashrc来叙述)、/.bash_profile、/.bash_login、/.profile、/.bashrc
- 要弄清这些问题。首先要知道打开一个终端或者打开一个新shell时(注意,两者是不同的。比如在终端里输入bash,会进入一个新shell。此时并没有打开新终端),会读取到哪些文件。
- 之所以是要配置这些文件,是因为这些软件要在环境变量中添加属于自己的信息,或者新建一个属于自己的环境变量(如安装JDK时要新建一个JAVA_HOME环境变量)。系统会根据环境变量里的值,找到软件的一些文件的路径。
- 而Linux启动登录时会读取/etc/profile和/.profile文件的内容。所以,在测试的时候,重启登录时会读取/etc/profile和/.profile文件的内容(此时并不读取/etc/bash.bashrc和~/.bashrc文件)。然后再打开终端时,会去读取/etc/bash.bashrc和 ~/.bashrc文件。这就出现了那种结果。
- 使用login和non login术语来说,就是使用login 方式是会读取/etc/profile 和 ~/.profile文件。使用non login方式的话,会读取/etc/bash.bashrc 和 ~/.bashrc文件的内容
- 如果为了一完成配置信息就能使用,那么就不用在/etc/profile和~/.profile文件中添加关于软件的配置信息。而是在/etc/bash.bashrc 或者 ~/.bashrc 中添加,这样就能马上使用了。
ubuntu安装搜狗输入法注意事项
将输入法放入英文下面的位置
配置代理
# ss
https://blog.huihut.com/2017/08/25/LinuxInstallConfigShadowsocksClient/
# lanproxy
https://www.moerats.com/archives/727/
jupyter
# 修改密码 远程登录 本地目录
jupyter-notebook password # remote_loing true
# 安装主题
pip install jupyterthemes
# 主题配色
jt -t onedork -cellw 85% -fs 11 -nfs 12 -tfs 11 -ofs 12 -T -N -tf robotosans -f roboto -nf robotosans
# 主题还原
jt -r #还原
# 安装jupyter插件
https://blog.youkuaiyun.com/wiborgite/article/details/87731215
开机自启
# 查看开机自启
systemctl list-unit-files
# 添加或者删除
systemctl enabel xxx
systemctl disable xxx
#==== 自己的脚本开机自启 ====
cd /etc/init.d
#新建一个sslocal自启动脚本,内容如下:
sudo vim ss_local.sh
#添加自启动脚本。在这里90表明一个优先级,越高表示执行的越晚
sudo update-rc.d ss_local.sh defaults 90
# 从开机自启动项里删除自启动项
sudo update-rc.d -f ss_local.sh remove
挂载永久硬盘
1.列出挂接到实例的磁盘,并找到要格式化并装载的磁盘
lsblk
eg:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
loop0 7:0 0 89.1M 1 loop /snap/core/7917
loop2 7:2 0 66.8M 1 loop /snap/google-cloud-sdk/105
loop3 7:3 0 67M 1 loop /snap/google-cloud-sdk/106
sda 8:0 0 10G 0 disk
├─sda1 8:1 0 9.9G 0 part /
├─sda14 8:14 0 4M 0 part
└─sda15 8:15 0 106M 0 part /boot/efi
sdb 8:16 0 10G 0 disk /mnt/disks/sdb
(sdb 是新的地区永久性磁盘的DEVICE_ID)
2.格式化磁盘
mkfs.ext4 -m 0 -F -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/[DEVICE_ID]
3.创建用作新磁盘装载点的目录
mkdir -p /mnt/disks/xxx
4.使用 mount 工具在启用 discard 选项的情况下将磁盘装载到实例
mount -o discard,defaults /dev/[DEVICE_ID] /mnt/disks/xxx
5.配置对设备的读写权限
chmod a+w /mnt/disks/[MNT_DIR]
SFTP
添加用户
# 创建组
groupadd 组名
指定组,家目录和bash
useradd -m -g groupName -s /bin/bash iszhaoy
# 修改密码
passwd iszhaoy
# 修改root权限
vim /etc/sudoers
# 删除用户
userdel -r iszhaoy
# 允许密码登陆
vim /etc/ssh/sshd_config
PasswordAuthentication yes
# 给用户赋予组权限 -a 代表 append, 也就是 将自己添加到 用户组groupA 中,而不必离开 其他用户组; -G 组
usermod -a -G root cumin
# 修改目录的属主和属组
chown -R 组名:用户名 文件的目录
# 赋予iszhaoy用户 对hosts的写权限
sudo /bin/chmod +a 'user:iszhaoy:allow write' /etc/hosts
https://www.cnblogs.com/suyufei/p/11941385.html
linux目录中递归删除同名文件夹
find . -name 'xxxx' -type d | xargs rm -rf
alpine Linux 使用
更新源
sed -i 's/dl-cdn.alpinelinux.org/mirror.tuna.tsinghua.edu.cn/g' /etc/apk/repositories
apk --update
add git
--------
apk add git --repository http://nl.alpinelinux.org/alpine/edge/testing/

















 3668
3668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









