



 本文详细介绍了如何通过npminstallhtml2canvas插件,获取页面元素ref,实现在点击事件中将雷达图转换为图片并处理其DataURL。
本文详细介绍了如何通过npminstallhtml2canvas插件,获取页面元素ref,实现在点击事件中将雷达图转换为图片并处理其DataURL。
首先我们需要安装一个插件 html2canvas 这是一个 JavaScript 库,用于将网页中的 HTML 元素转换为 Canvas 图像。通过使用 html2canvas,你可以截取网页中的特定区域,并将其转换为图像进行保存或展示
npm install --save html2canvas
安装完成之后就是引入该插件,并且获取你需要转换图片区域的 ref
import html2canvas from 'html2canvas' // 引入插件
let contentRef = ref('')//雷达图 ref
下面我将页面中的雷达图转换成图片
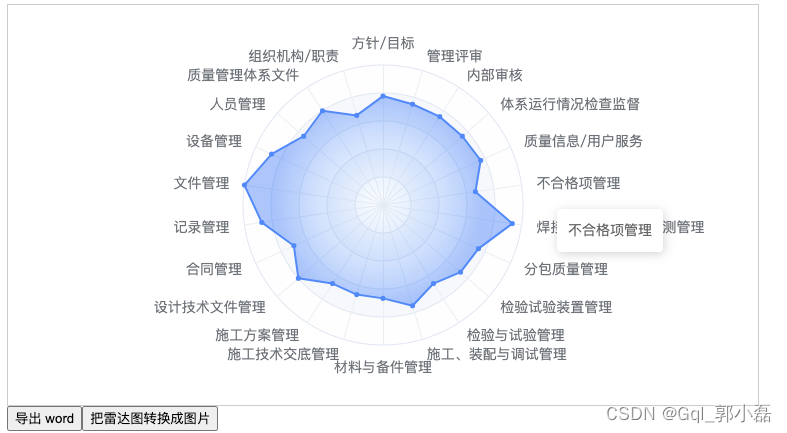
<button @click="convertToImage" >把雷达图转换成图片</button> //点击事件
let image = ref ('') //图片的路径
async function convertToImage() {
try {
const canvas = await html2canvas(contentRef.value);
image.value = canvas.toDataURL();
console.log( image.value) //输出的结果就是页面转换成的图片路径
} catch (e) {
throw new Error(e);
}
};
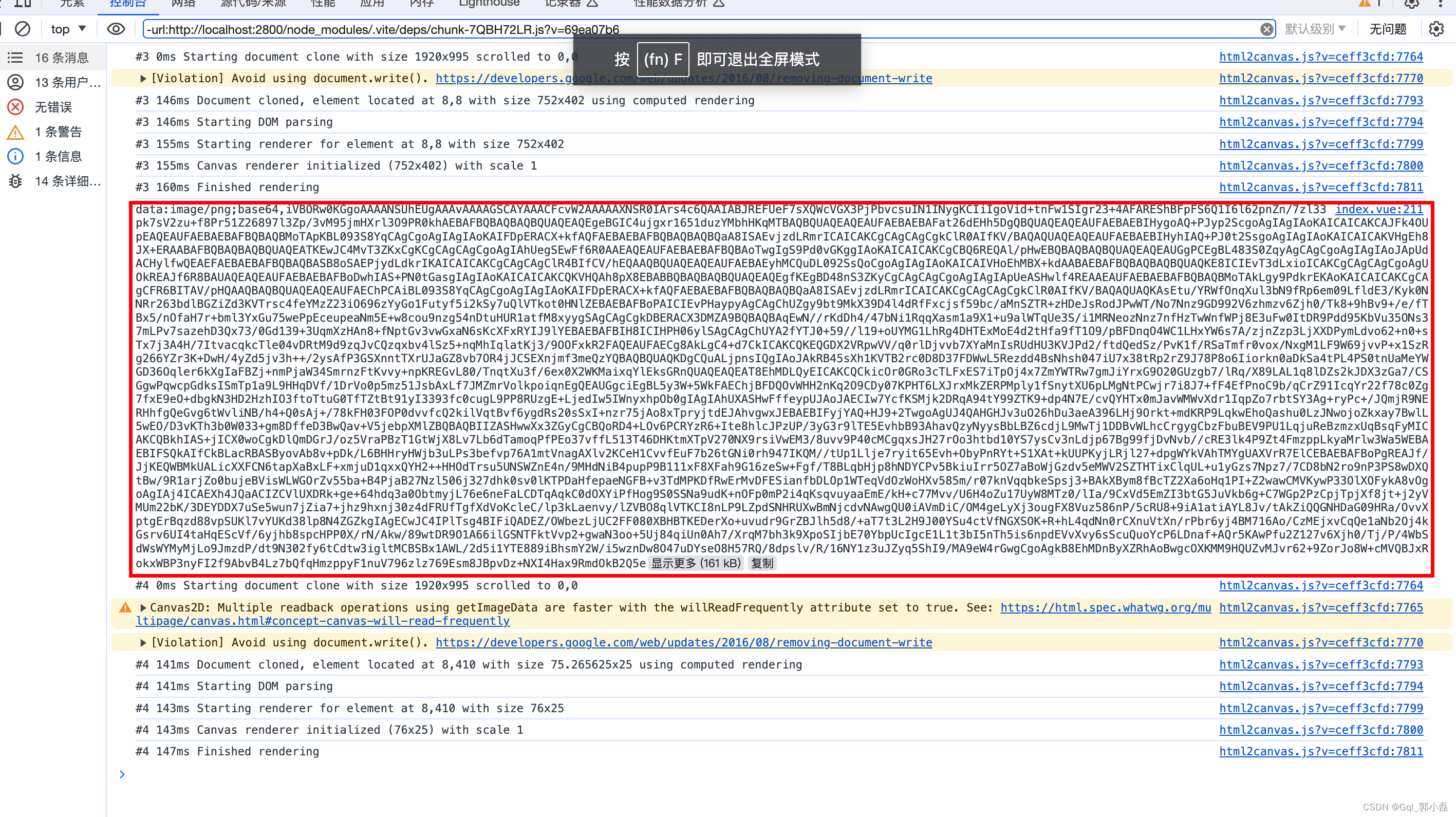 这段就是转换成的图片路径,我们复制改路径将它在浏览器中打开
这段就是转换成的图片路径,我们复制改路径将它在浏览器中打开
 此时页面生成图片成功 ,我们获取到路径就可以做很多处理了,比如:下载图片,展示图片,或者截图展示功能
此时页面生成图片成功 ,我们获取到路径就可以做很多处理了,比如:下载图片,展示图片,或者截图展示功能

















 9603
9603





 到【灌水乐园】发言
到【灌水乐园】发言







