




 本文深入探讨了机器学习中决策树的基本流程,重点解析了划分选择的三种方法:信息增益、增益率和基尼指数,并详细介绍了剪枝处理的预剪枝和后剪枝策略,同时涵盖了连续值、缺失值处理及多变量决策树的应用。
本文深入探讨了机器学习中决策树的基本流程,重点解析了划分选择的三种方法:信息增益、增益率和基尼指数,并详细介绍了剪枝处理的预剪枝和后剪枝策略,同时涵盖了连续值、缺失值处理及多变量决策树的应用。
1.基本流程
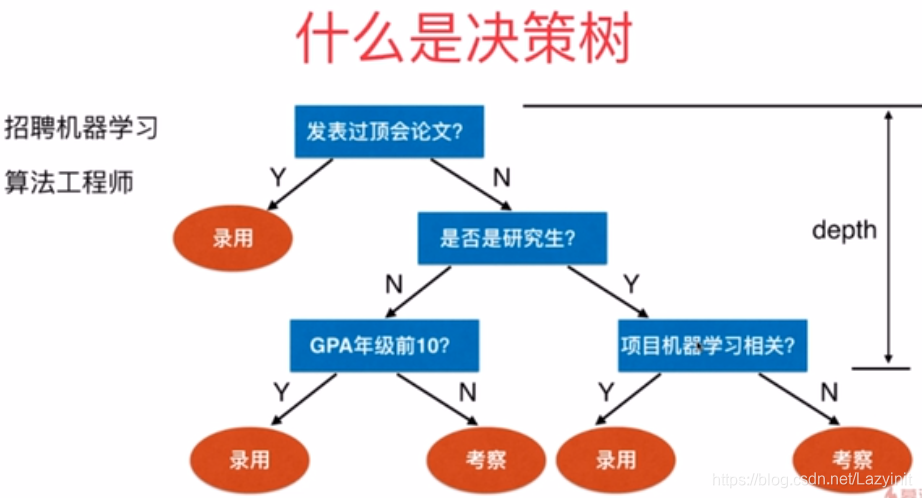
2.划分选择
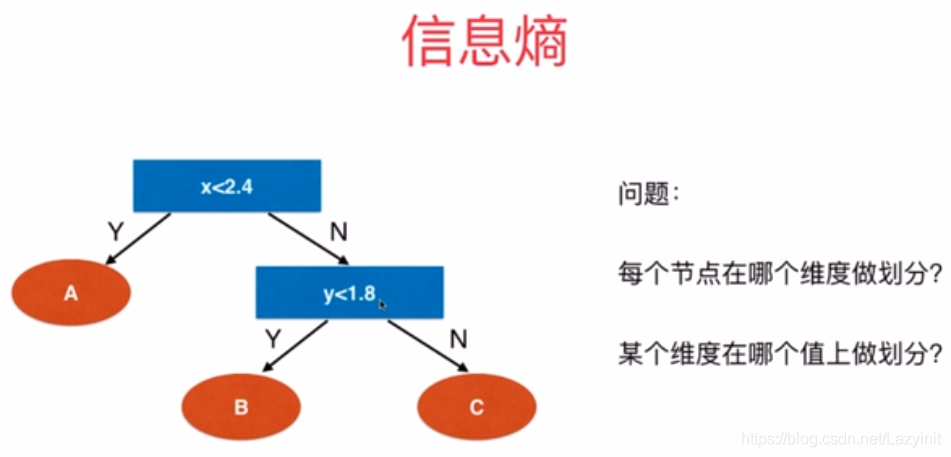
信息熵 是度量样本集合纯度最常用的一种指标;表示随机变量的不确定度的度量。
熵越大,数据的不确定性越高
熵越小,数据的不确定性越低
确定性,是指数的随机性,熵越小越纯
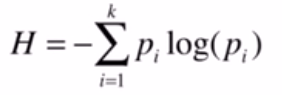
例如:
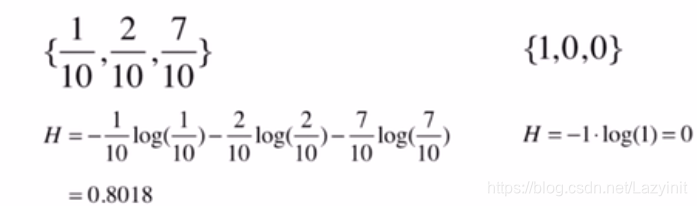
2.1信息增益
例如:

信息增益 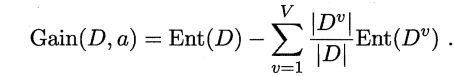
信息增益 越大越好,越大则意味着使用属性 a 来进行划分所获得的 “纯度提升” 越大。
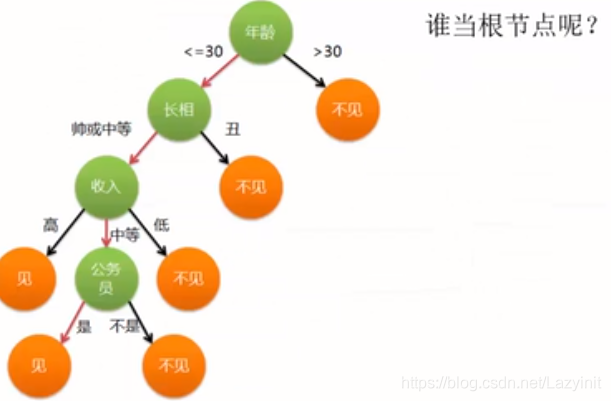
谁当根节点? 谁的 信息增益 值最大,则谁当。
2.2增益率
有时候用 信息增益 不能准确的划分根节点(例如:ID)引入了 增益率
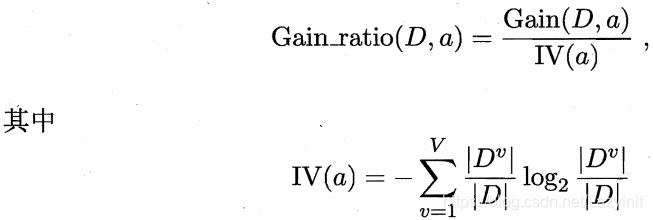
评价函数:
2.3基尼指数
3.剪枝处理
3.1预剪枝
在构建决策树的过程时,提前停止
3.2后剪枝
决策树构建好后,然后才开始裁剪

















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









