




Spatial Transformer Networks
本文了讲述STN的基本架构,空间几何注意力模块的基本原理,冒烟测试以及STN在MNIST数据集用于模型自动调整图片视角的实验,如果大家有不懂或者发现了错误的地方,欢迎讨论。
- 中文名:空间Transformer网络
- 论文链接:Arxiv
我更倾向于叫它为Spatio Geometry Transformer Network, 因为它的注意力同时包括了是旋转,平移,仿射等多种几何变换,而不是单纯地裁剪以注意空间里面的重点。
目录
模型简介
- 作者:Ghassen HAMROUNI
- 发布年:2015
- 为什么这么叫:因为它用使用了空间几何注意力
- 主要成就:第一个使用空间几何注意力的卷积神经网络
STN是对任何空间变化的推广,其允许神经网络学习如何对输入图像进行 空间变换,以增强模型的 几何不变性。例如,其可以对感兴趣的区域进行裁剪,或者缩放和矫正图像的方向。这个机制对CNN很有用,因为其对旋转、缩放、甚至更一般的放射变换并非不变。

提出背景
之前有哪些相同目的的模型/方法?
在STN出现之前,主要是用纯粹的CNN来对图像进行特征图的提取。但是由于CNN对于图像的几何变换的鲁棒性不强,因此研究人员设计了几种方法来改良CNN对于几何变换的鲁棒性:
- 数据增强(Data Augmentation):这是最简单也最常用的方法。通过对训练集中的图片进行随机旋转、缩放、平移或裁剪等操作,来增加数据的多样性。这使得模型在训练时能接触到更多不同几何形态的样本,从而提高其泛化能力
- 多尺度或者多角度训练:直接在多个尺度或角度下对同一图像进行训练,迫使网络学习对这些变换不变的特征。
- 使用手工设计的特征(如SIFT、ORB等): 在传统的计算机视觉任务中,人们会使用这些对几何变换具有一定不变性的特征来处理问题。例如,SIFT特征描述子在一定程度上对尺度和旋转是不变的。
之前的模型/方法有什么不足?
- 数据增强的局限性: 数据增强虽然有效,但它是一种“静态”的、预先定义好的方法。它并不能让网络自适应地学习应该对哪些变换进行处理。换句话说,模型是在被动地接受经过变换的数据,而不是主动地去“寻找”并“矫正”那些重要的区域。
- 计算效率低下:多尺度或多角度训练会显著增加计算量和内存消耗,因为需要为每个变换后的版本都进行一次前向传播。
- 无法处理复杂的、非预期的变换: 数据增强通常只覆盖简单的变换,如旋转和平移。对于更复杂的、特定于任务的“扭曲”或“不规则”变换,效果不佳。
设计思路
这个模型针对不足提出了什么改进方案?解决了什么问题?有什么人类直觉在里面?
鉴于之前方法的缺陷,作者从人类直觉的角度进行了思考,他认为,人类之所以能够从一个偏移,旋转,或者不同视角下的图片中还原原本的图片(比如把一不同视角下的5,无论仰视还是俯视都可以看出来),是因为我们脑袋中 “自带一个用来进行动态几何变换的机制” (可以理解为自带一个“自适应”的几何变换矩阵),我们能根据注意力自动调整这个矩阵的参数,把图像校正到我们大脑中最容易理解和识别的“理想状态”。

以下是几何变换矩阵的原理:

如果对变换矩阵施加如下约束,那么这个矩阵则可以对原图进行旋转,平移,以及仿射变换。

但是实际的代码实现中并不会对其施加以上约束,因为模型可能通过学习学到更加高级的几何变换,而不仅仅局限于以上三种变换。
达到效果及优势

- 性能提升: 相比于其他没有使用STN的模型(如 Cimpoi '15, Simon '15 等),使用了STN的CNN模型在CUB-200-2011鸟类分类数据集上的准确率有了明显的提升。在高分辨率的图片上性能提升更加显著。
- 可解释的空间变换注意力: 这是STN最直观也最令人兴奋的优势。图表右侧的图片展示了2xST-CNN和4xST-CNN模型中STN模块学习到的空间变换。论文作者在图中特别指出,对于2xST-CNN模型,一个STN模块(红色框)学习定位和放大鸟的头部,而另一个STN模块(绿色框)则学习定位和放大鸟的身体。也就是每个STN模块都注意到了不同的,但是对鸟的分类至关重要东西!
- 即插即用的模块:STN最大的优势之一就是他能非常容易地插入任何现有的CNN,并且只需要很小的修改!
对后续模型的影响
-
开创“可学习的变换”思想
STN首次将空间变换的能力作为可学习的模块集成到神经网络中。它证明了网络可以自己决定如何对输入数据进行几何变换,而不是依赖于预先设定好的规则(如数据增强)。 这种思想被广泛应用于各种需要处理非刚性、非线性变换的任务中。例如,在医学图像处理中,STN的思想被用来进行图像配准(Image Registration),自动对齐不同时间或不同设备拍摄的病灶图像。 -
空间注意力机制的先驱
尽管STN的关注点是“几何变换”,但它通过定位并变换最关键的区域,实际上实现了一种形式的注意力。它让网络将“注意力”集中在最关键的像素或特征上,并将其“摆正”以方便后续处理。它的成功启发了后续的注意力机制(Attention Mechanism)研究。虽然STN是“空间注意力”,更严谨一定来说叫“空间几何注意力”,但它证明了让网络“有选择地”关注输入中最重要的部分是提高性能的有效手段。这为后来更广泛的通道注意力(Channel Attention)、自注意力(Self-Attention)以及Transformer模型的兴起奠定了基础。 -
“即插即用”模块化设计的典范
STN模块可以轻松地插入到任何CNN架构中,这极大地降低了其应用门槛,并展示了模块化设计在深度学习中的巨大潜力。* 这种设计理念被广泛采纳。如今,许多深度学习模型都由各种可插拔的模块组成,比如SENet中的“通道注意力”模块、ECA-Net中的“高效通道注意力”模块等等。这些模块都遵循了STN的“即插即用”设计思想,让研究人员可以更容易地进行模型改进和创新。
总而言之,STN的贡献远不止于提高了一点点准确率。它引入的 “可学习变换” 、 “空间注意力” 和 “模块化设计” 等核心思想,深刻地影响了后续的计算机视觉和深度学习研究,成为连接传统CNN和现代Transformer模型的一个重要桥梁。
网络结构
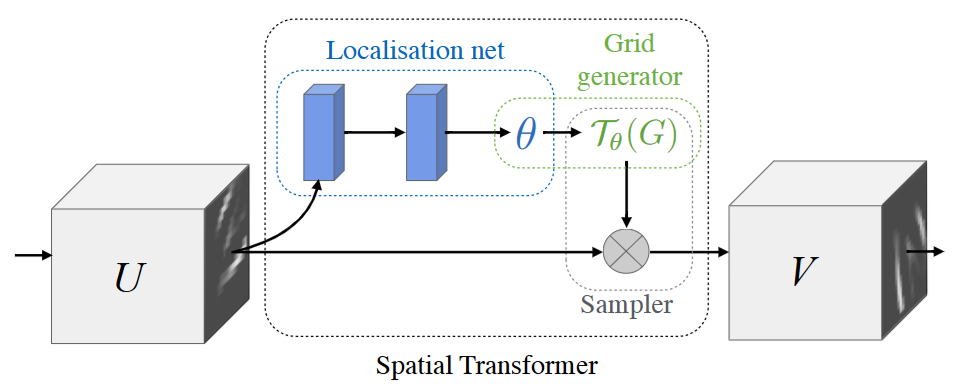
Spatial Transformer 模组可以分解成如下三个关键组成部分:
- 定位网络(localisation net):其中包括两个全连接层,第一个层负责提取图片中的基础几何信息,第二个层负责根据基础几何信息回归出几何变换矩阵
- 网格生成器(grid generator): 负责根据生成的变换矩阵生成变换网格,本质上是定义了图像的变换
- 采样器(Sampler):利用定义好的grid对原图片进行变换
Pytorch模型实现+MNIST数据集视角调整实验
准备库、数据集、数据加载器
首先我们把库和数据集,以及数据加载器准备好:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
plt.ion() # interactive mode
from six.moves import urllib
opener = urllib.request.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/5.0')]
urllib.request.install_opener(opener)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Training dataset
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(root='.', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])), batch_size= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















+ MNIST数据集视角调整实验&spm=1001.2101.3001.5002&articleId=150510635&d=1&t=3&u=7f4169f43dd143db9fe4d8499ad03cea)

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









