






pytorch作为深度学习神经网络的主流框架工具,是所有深度学习研究者必备的技能,今天超级驼鹿将用这一篇文章带您轻松入门pytorch。
主要流程与核心问题
想熟练掌握pytorch框架,首先要知道从0开始搭建pytorch需要走哪几个步骤,我们接下来均以经典的分类问题举例子。
首先,我们的目标是:通过测试数据集训练一个我们自己搭建的神经网络,再用校验数据集测试我们的神经网络。也就是下面这个图:
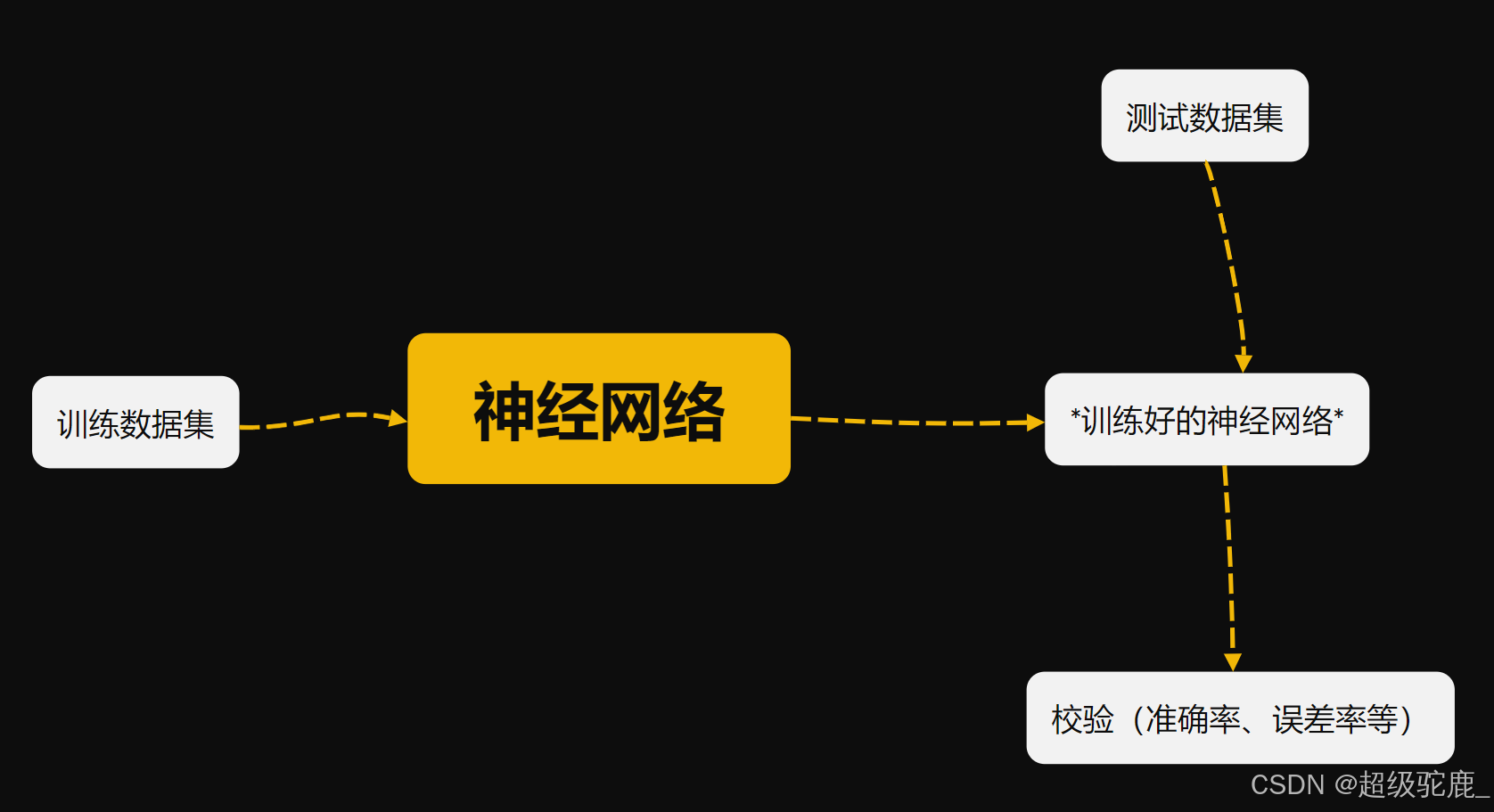
知道了这个图之后,相信各位小伙伴们对接下来的分工也会有些许感觉了,我们先把要做的几件事情给他标一下号:

由此可见,我们需要解决的四个核心问题就是:
1. 如何向神经网络中输入数据?(数据)
2. 如何构建神经网络?(网络)
3. 如何训练神经网络?(训练)
4. 如何应用训练好的神经网络?(应用)
接下来,我会根据这四个大问题,逐一地讲解如何用pytorch来解决这四大问题。
一、数据输入:CIFAR-10数据集封装
1.1 数据集目录结构准备
CIFAR-10数据集需按类别存储为文件夹,目录结构如下(需手动解压转换):
cifar10/
├── train/
│ ├── airplane/ # 飞机类图片(5000张)
│ ├── automobile/ # 汽车类图片
│ └── ...(共10类)
└── test/
├── airplane/ # 测试集图片(1000张)
└── ...(同上)
若使用PyTorch内置数据集,可跳过此步骤(见代码注释)。
1.2 自定义Dataset与DataLoader
最终,我们是要把数据组织成神经网络模型可以接受的数据形式,而DataLoader就是我们的神经网络可以接受的数据形式,但是在我们使用DataLoader前,我们要先把数据整理成Dataset的形式,为什么呢?
Dataset像是一个数据的总集合,一整副扑克牌,我们的所有数据都要存放在Dataset里,而对于模型训练来说,它并不是每一次都需要完整的全部数据集,所以我们会从Dataset里抽出若干张牌,用于训练模型。
相信大家看到DataLoader里要传的参数就知道了:dataset, batch_size, shuffle 分别表示要想创建一个DataLoader你需要告诉他:用哪Dataset创建、每批要取多少个数据去训练,是否随机打乱这些数据。
还有一些知识大家需要知道才能顺利的构建出来Dataset,那就是torchvision里的transforms函数,这些函数的作用就是把图片数据转化为torch里面数据的组织形式:Tensor。其中Compose函数可以实现把若干个transform函数联合起来按顺序使用的效果,ToTensor函数则是会把数据形式转换成Tesnsor,剩下的比如标准化、裁剪也都有对应的函数,大家需要用到的时候shift+Tab查看一下就会啦。
下面是示例代码:
import torch
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
# 定义数据预处理(训练集含数据增强)
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4), # 随机裁剪(32x32)
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 转为Tensor
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) # 标准化
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 加载数据集
# 图片的根部目录 把创建的transform实体放在这就可以实现对应操作了
train_dataset = datasets.ImageFolder(root='cifar10/train', transform=train_transform)
test_dataset = datasets.ImageFolder(root='cifar10/test', transform=test_transform)
# 封装DataLoader
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=100, shuffle=False)二、构建复杂网络:以ResNet-18魔改版为例
2.1 修改ResNet
对于构建神经网络这一块,还需要大家有一些关于神经网络结构的基础知识,在pytorch框架下(类写法)要想实现模型的函数式调用需要覆写的父类方法是forward函数,在init方法里除了完成对父类相关参数的初始化,也要把相关操作的函数写在self里.
torch.nn则代表了neural network,里面有我们构建模型需要的基本函数,比如Conv卷积函数、ReLu激活函数等等.
下面是代码示例:
from torch import nn
import torch.nn.functional as F
class MyModule(nn.Module):
def __init__(self):
super().__init__()
# 128张 * 3个通道 *(64*64)
self.conv1 = nn.Conv2d(3, 64, 3, 2, 0)
# 128 * 64 * (31*31)
self.maxpool = nn.MaxPool2d(2, 2)
# 128 * 64 * (15*15)
self.conv2 = nn.Conv2d(64, 10, 3, 1, 1)
# 128 * 10 * (14*14)
self.maxpool = nn.MaxPool2d(2, 2)
# 128 * 10 * (7*7)
self.line1 = nn.Linear(10*7*7, 1000)
# 128 * 1000
self.line2 = nn.Linear(1000, 10)
# 128 * 10
self.relu = nn.ReLU()
def foward(self, inputs):
_ = self.conv1(inputs)
_ = self.relu(_)
_ = self.maxpool(_)
_ = self.conv2(inputs)
_ = self.relu(_)
_ = self.maxpool(_)
_ = nn.Flatten()(_)
_ = self.line1(_)
_ = self.relu(_)
_ = self.line2(_)
outputs = F.softmax(_)
return outputs
model = MyModule()
print(model)三、训练神经网络
3.1 定义损失函数与优化器
对于神经网络训练来说最不可少的就是损失函数和如何推进优化算法了,所以我们事先要定义好损失函数和优化器。
import torch.optim as optim
loss = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)3.2 训练与验证循环
这部分主要是python编程的小技巧,没有别的问题。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
def test():
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.argmax(dim=1)
correct += pred.eq(target).sum().item()
acc = 100. * correct / len(test_loader.dataset)
return acc
for epoch in range(1, 201):
train(epoch)
acc = test()
scheduler.step()
print(f'Epoch {epoch}: Test Accuracy {acc}')四、应用模型:推理与部署
4.1 单张图片预测
from PIL import Image
def predict(img_path):
img = Image.open(img_path).convert('RGB')
img = test_transform(img).unsqueeze(0).to(device) # 添加batch维度
model.eval()
with torch.no_grad():
output = model(img)
pred = output.argmax().item()
classes = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
print(f'Predicted: {classes[pred]}')
# 示例调用
predict('test_image.jpg')4.2 保存与加载模型
# 保存
torch.save(model.state_dict(), 'cifar10_resnet18.pth')
# 加载
model = CIFAR10_ResNet().to(device)
model.load_state_dict(torch.load('cifar10_resnet18.pth'))五、结语
以上就是使用pytorch的具体流程,当然里面还有很多很多我们没有提及的函数,但是有了大框架和整体思路后,相信大家可以很顺利的通过文档和部分源代码学习那些没有介绍的函数。
我是努力学习AI算法的超级驼鹿,关注我,持续获得更多AI算法知识!

















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









