




一、工作目标与背景
以往系统按“一场会议 = 一条记录”进行问答检索,难以支持用户对细节片段的深度追问。本周目标是将会议语音 逐句转录 → 数据库持久化 → 自动摘要 → 对话注入,让 AI 能基于完整上下文提供实时、细颗粒度答复,彻底摆脱“按场会议”粒度的限制。
二、主要完成任务
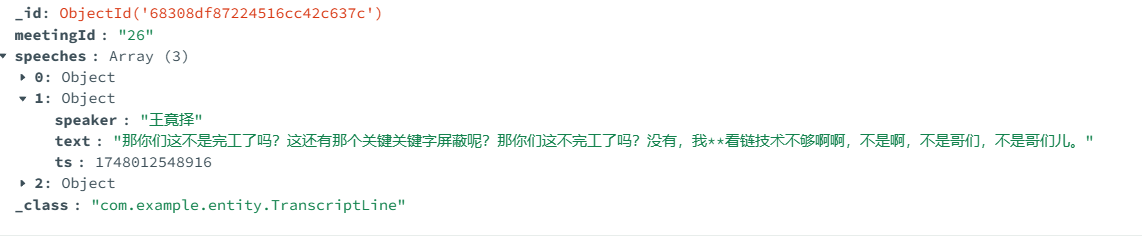
1. 会议转录实时入库
-
新建
transcript_lines表,字段:id、meeting_id、speaker、text、timestamp。
-
前端 WebSocket 实时推送转录,后端批量
insert,句级延迟 ≤500 ms。
2. 系统级 Prompt 生成会议摘要
-
会议结束触发 Cloud Task,调用 deepseek-chat 定制 Prompt,自动汇总所有发言要点。
-
摘要写入
meeting_summary表(summary_id、meeting_id、content、generated_at)。

3. 摘要注入会话
-
后端在生成摘要后,将其包装为系统问答对:

-
通过
/sessions/update写入对应会话,isSummary:true用于前端高亮。
4. 细颗粒度问答
-
检索顺序:
transcript_lines(句级召回)→meeting_summary(段级补充)。 -
对话接口新增
history_all参数,将当前会议全部发言与摘要串联,AI 可跨句、跨议题即时回答,实现“实时会议内容问答”。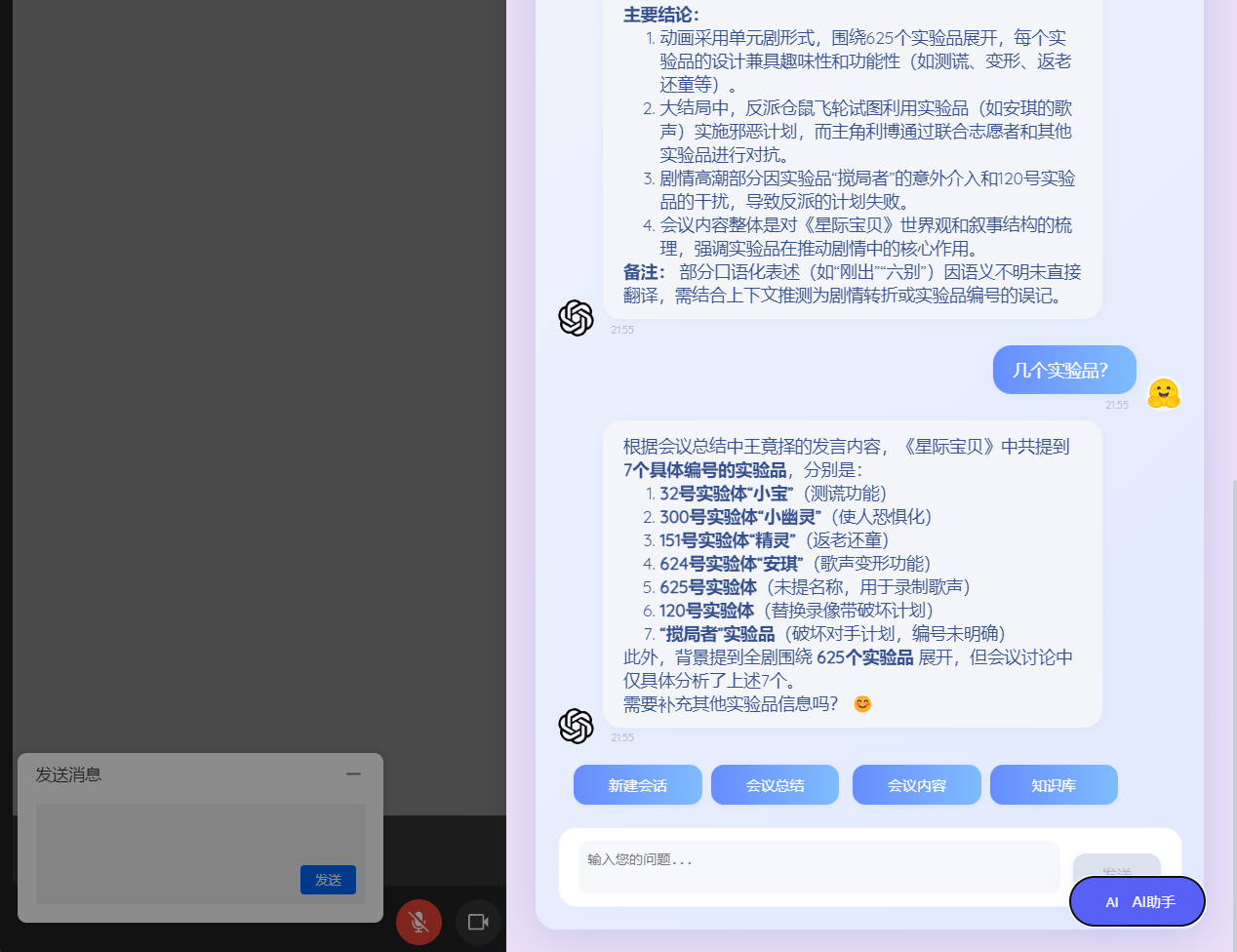
三、遇到的问题与解决办法
-
识别与同步机制不匹配:
updateSessionMessages里只靠m.content.includes('会议总结')来判断,但实际返回的纯文本 summary 并不包含该关键词,导致根本不同步到后端。 -
缺少对 summary 消息的显式标记:没给生成的会议总结消息打任何 flag,无法在同步逻辑中区分它与普通的 AI 回复。
-
会话创建逻辑与消息清空耦合:
createNewSession不仅生成新的sessionId,还会重置messages.value,导致刚生成的总结被覆盖。 -
sessionId未持久化导致重复建会话:在调用summarizeMeeting时如果sessionId.value还是null,就会重新创建会话;之后发问又因同样原因再建一次,看起来像“断开重连”。 -
同步函数缺少对系统 summary 的独立分支:原先的同步逻辑只关注“用户问→AI 答”这样的对话对,对单独的系统生成总结没有专门处理,导致 summary 消息漏写。
四、下周工作计划
1. 实现会议内RAG
2. 会议内图像识别
本周成果:完成“转录-摘要-注入-细粒度问答”全链路,实现了可随时引用整场发言的实时 AI 问答,为多会议跨维度知识挖掘奠定数据基础。

















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









