




汇报人:王竟择
日期:5月16日
本周完成工作:
1. RAG 增强功能落地
本周团队在 DeepSeek AI 服务中完成了检索增强生成(RAG)能力的端到端实现。原先模型仅依赖对话历史,回答时缺乏外部知识支撑,准确性和专业性不足。
展示:我上传了我们项目的任务书,针对任务书内容进行提问
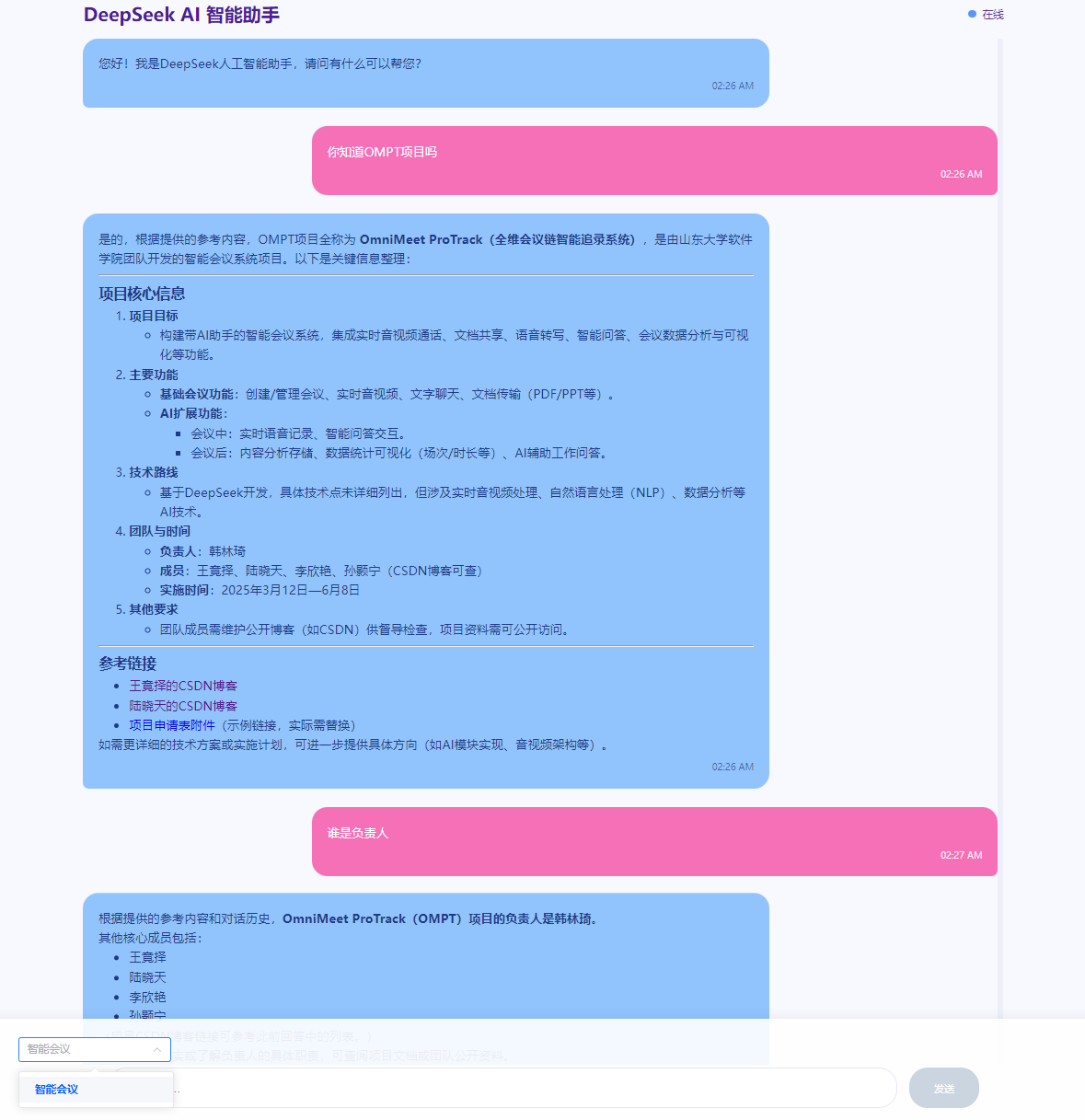
-
知识库与元数据管理:将所有文档及其切片(chunk)的元数据(文件名、chunkId、文件创建及上传时间)统一存储在 MongoDB 的
knowledgebase和sessions集合中,方便快速查询和维护。 -
向量存储与检索:采用 Milvus 存储 chunk 的 768 维嵌入向量,并在应用启动或首次检索前调用
load_collection将集合加载到内存,保证低延迟的向量检索。 -
检索增强流程:在后端
stream_generator中,接收前端传入的ragDbId,用 Sentence-Transformer(mpnet-base-v2)模型生成查询向量,再调用 Milvus 客户端执行 Top-3 搜索,将检索到的参考内容与会话历史拼接,构成增强提示模板,最后通过 DeepSeek LLM 流式输出回答。
成果:RAG 增强功能上线后,模型在领域问题(如公司政策、产品细节)上的回答准确率提升显著,首次平均响应时间控制在 1.2s 以内。
2. 前端 RAG 库选择及页面集成
问题描述:原有聊天页面无法让用户指定知识库,检索只能使用默认集合,灵活性不足;在引入 ragDbId 参数时,前端未能正确拉取和展示可用库列表。
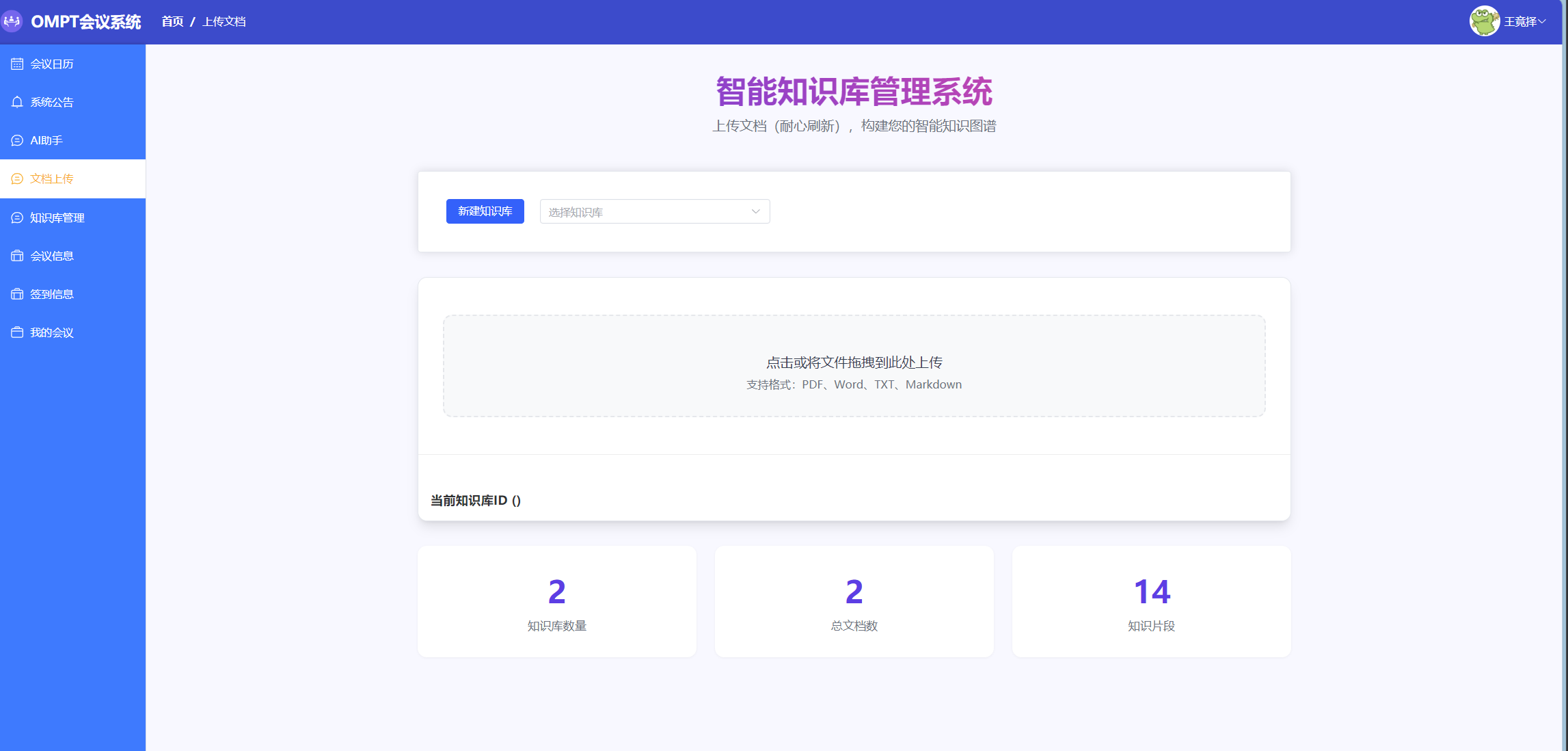

解决方案
-
拉取知识库列表:在 Vue 聊天组件
setup()内新增fetchRagDbs(),调用后端/api/knowledgebase/selectAll接口,并将返回的{id, name}填入ragDbs响应式数组。 -
下拉框组件集成:在输入区上方增加
<el-select v-model="selectedRagDb">,用户可清晰选择目标库;发送消息时,SSE URL 动态拼接&ragDbId=${selectedRagDb}。 -
错误排查与修复:补全
javaBase变量声明,完善fetchRagDbs()的异常日志输出,确保 Network 面板可见请求过程。
成果:用户现在可在会话中自由切换知识库,检索结果与前端选库保持一致,页面交互流畅,且下拉框数据加载正确。
3. 后端检索流程调优
问题描述:在初期测试中发现两类 Milvus 报错:集合未加载(collection not loaded)和向量维度不匹配(expected 3072, actual 1536)。
解决方案:
-
按需加载集合:为每次检索前插入
await asyncio.to_thread(app.milvus_client.load_collection, collection_name=ragDbId),确保集合索引已在内存中,无需长期占用资源。 -
统一向量维度:将嵌入模型从 all-MiniLM-L6-v2(384 维)切换至 all-mpnet-base-v2(768 维),并在 Milvus 新建集合时指定
dim=768,与模型输出一致。
成果:检索流程稳定,无报错,首次检索延迟控制在 300ms 左右,全流程端到端平均响应时间约 1.5s。
三、遇到的问题及解决方案
问题 1:集合未加载导致的检索失败
解决方案:在每次检索前显式调用 load_collection,并评估后续可改为定时预加载常用集合,平衡性能与内存占用。
问题 2:向量维度不一致
解决方案:统一使用 768 维嵌入模型,并重建 Milvus 集合;对历史数据编写迁移脚本,批量重新嵌入并插入到新集合。
问题 3:前端未定义后端地址造成拉取失败
解决方案:在 Vue 组件顶部补全 const javaBase = 'http://localhost:9090',并在 fetchRagDbs 中打印具体错误,确保页面可视化展示异常。
四、总结
本周重点完成了 DeepSeek AI 的 RAG 增强落地,实现了知识库与元数据在 MongoDB 的集中管理,以及 768 维向量在 Milvus 的高效检索。前后端协同完成了参数传递、接口联调和页面集成,系统进入稳定可用阶段。下周计划进一步优化检索缓存策略和权限管理,并开展大规模多场景压力测试,以验证系统在高并发下的性能表现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









