




目录
一、概述
HIP属于显式编程模型,需要在程序中明确写出并行控制语句,包括数据传输、核函数启动等。核函数是运行在DCU上的函数,在CPU端运行的部分称为主机端(主要是执行管理和启动),DCU端运行的部分称为设备端(用于执行计算)。大概的流程如下图:
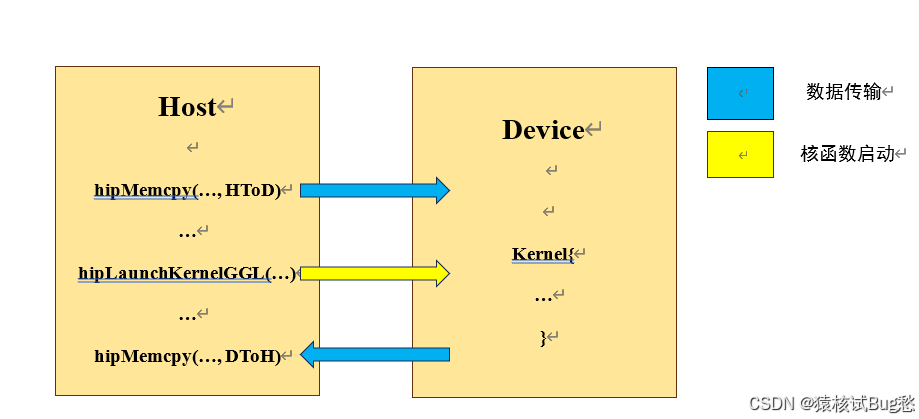
①主机端将需要并行计算的数据通过hipMemcpy()传递给DCU(将CPU存储的内容传递给DCU的显存);
②调用核函数启动函数hipLaunchKernelGGL()启动DCU,开始执行计算;
③设备端将计算好的结果数据通过hipMemcpy()从DCU复制回CPU。
hipMemcpy()是阻塞式的,数据复制完成后才可以执行后续的程序;hipLanuchKernelGGL()是非阻塞式的,执行完后程序继续向后执行,但是在Kernel没有计算完成之前,最后一个hipMemcpy()是不会开始的,这是由于HIP的Stream机制。
二、程序实现
下面是对可迁移内存中系统范围的原子操作的具体实现,systemWideAtomics.cpp:
#include <math.h>
#include <stdint.h>
#include <cstdio>
#include <ctime>
#include <hip/hip_runtime.h>
#include <helper_hip.h>
#define min(a,b) (a) < (b) ? (a) : (b)
#define max(a,b) (a) > (b) ? (a) : (b)
#define LOOP_NUM 50
__global__ void atomicKernel(int *a 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2591
2591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











