







目录
一、概述
HIP属于显式编程模型,需要在程序中明确写出并行控制语句,包括数据传输、核函数启动等。核函数是运行在DCU上的函数,在CPU端运行的部分称为主机端(主要是执行管理和启动),DCU端运行的部分称为设备端(用于执行计算)。大概的流程如下图:
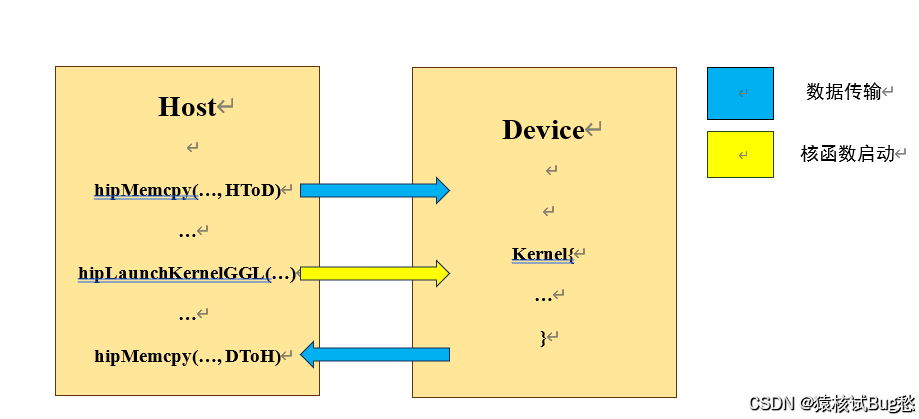
①主机端将需要并行计算的数据通过hipMemcpy()传递给DCU(将CPU存储的内容传递给DCU的显存);
②调用核函数启动函数hipLaunchKernelGGL()启动DCU,开始执行计算;
③设备端将计算好的结果数据通过hipMemcpy()从DCU复制回CPU。
hipMemcpy()是阻塞式的,数据复制完成后才可以执行后续的程序;hipLanuchKernelGGL()是非阻塞式的,执行完后程序继续向后执行,但是在Kernel没有计算完成之前,最后一个hipMemcpy()是不会开始的,这是由于HIP的Stream机制。
二、程序实现
下面是对内核线程块的具体实现,clock.cpp:
#include <stdio.h>
#include <stdint.h>
#include <assert.h>
#include "hip/hip_runtime.h"
#include "helper_functions.h"
#include "helper_hip.h"
__global__ static void timedReduction(const float *input, float *output, clock_t *timer)
{
HIP_DYNAMIC_SHARED(float, shared)
const int tid = threadIdx.x;
const int bid = blockIdx.x;
if(tid == 0) timer[bid] = clock();
shared[tid] = input[tid];
shared[tid + blockDim.x] = input[tid + blockDim.x];
for(int d = blockDim.x; d > 0; d /= 2)
{
__syncthreads();
if(tid < d)
{
float f0 = shared[tid];
float f1 = shared[tid + d];
if(f1 < f0)
{
shared[tid] = f1;
}
}
}
if(tid == 0) output[bid] = shared[0];
__syncthreads();
if(tid == 0) timer[bid + gridDim.x] = clock();
}
#define NUM_BLOCKS 64
#define NUM_THREADS 256
int main(int argc, char **argv)
{
printf("CUDA Clock sample\n");
int dev = findHIPDevice(argc, (const char **)argv);
float *dinput = NULL;
float *doutput = NULL;
clock_t *dtimer = NULL;
clock_t timer[NUM_BLOCKS * 2];
float input[NUM_THREADS * 2];
for(int i = 0; i < NUM_THREADS * 2; i++)
{
input[i] = (float)i;
}
checkHIPErrors(hipMalloc((void **)&dinput, sizeof(float) * NUM_THREADS * 2));
checkHIPErrors(hipMalloc((void **)&doutput, sizeof(float) * NUM_BLOCKS));
checkHIPErrors(hipMalloc((void **)&dtimer, sizeof(clock_t) * NUM_BLOCKS * 2));
checkHIPErrors(hipMemcpy(dinput, input, sizeof(float) * NUM_THREADS * 2, hipMemcpyHostToDevice));
hipLaunchKernelGGL(timedReduction, dim3(NUM_BLOCKS), dim3(NUM_THREADS), sizeof(float) * 2 * NUM_THREADS, 0, dinput, doutput, dtimer);
checkHIPErrors(hipMemcpy(timer, dtimer, sizeof(clock_t) * NUM_BLOCKS * 2, hipMemcpyDeviceToHost));
checkHIPErrors(hipFree(dinput));
checkHIPErrors(hipFree(doutput));
checkHIPErrors(hipFree(dtimer));
long double avgElapsedClocks = 0;
for(int i = 0; i < NUM_BLOCKS; i++)
{
avgElapsedClocks += (long double)(timer[i + NUM_BLOCKS] -timer[i]);
}
avgElapsedClocks = avgElapsedClocks/NUM_BLOCKS;
printf("Average clocks/block = %Lf\n", avgElapsedClocks);
return EXIT_SUCCESS;
}三、编译运行
HIP程序采用hipcc编译:
![]()
运行结果:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











