







目录
一、概述
HIP属于显式编程模型,需要在程序中明确写出并行控制语句,包括数据传输、核函数启动等。核函数是运行在DCU上的函数,在CPU端运行的部分称为主机端(主要是执行管理和启动),DCU端运行的部分称为设备端(用于执行计算)。大概的流程如下图:
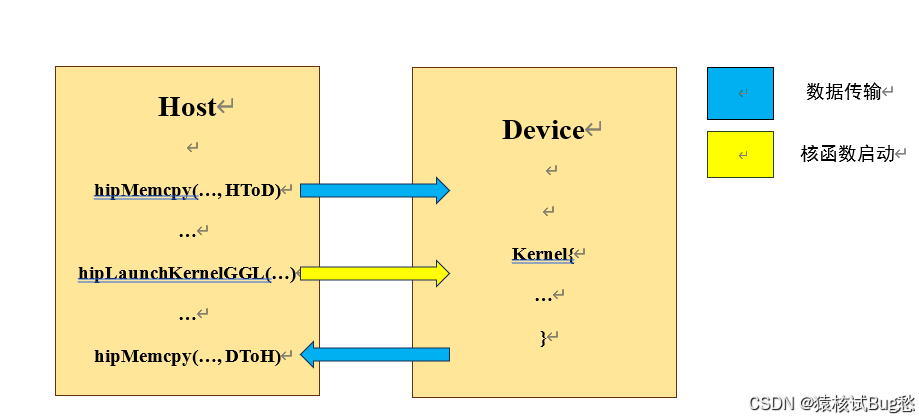
①主机端将需要并行计算的数据通过hipMemcpy()传递给DCU(将CPU存储的内容传递给DCU的显存);
②调用核函数启动函数hipLaunchKernelGGL()启动DCU,开始执行计算;
③设备端将计算好的结果数据通过hipMemcpy()从DCU复制回CPU。
hipMemcpy()是阻塞式的,数据复制完成后才可以执行后续的程序;hipLanuchKernelGGL()是非阻塞式的,执行完后程序继续向后执行,但是在Kernel没有计算完成之前,最后一个hipMemcpy()是不会开始的,这是由于HIP的Stream机制。
二、程序实现
下面是对多流向量相加的具体实现,VectorAdditionWithStream.cpp:
#include <stdio.h>
#include <hip/hip_runtime.h>
#define CHECKERROR() \
{ \
hipError_t __err = hipGetLastError(); \
if(__err != hipSuccess) \
{ \
fprintf(stderr, "Fatal error: %s at %s:%d\n"), hipGetErrorString(__err), __FILE__, __LINE__); \
fprintf(stderr, "*** FAILED - ABORTING\n");\
exit(1); \
} \
}
#define HANDLE_ERROR(cmd) \
{ \
(cmd); \
CHECKERROR(); \
}
#define N (1024 * 1024)
#define FULL_DATA_SIZE (N * 20)
__global__ void kernel(int *a, int *b, int *c)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if(idx < N)
{
int idx1 = (idx + 1) % 256;
int idx2 = (idx + 2) % 256;
float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;
float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;
c[idx] = (as + bs) / 2;
}
}
int main(void)
{
hipDeviceProp_t prop;
int whichDevice;
HANDLE_ERROR(hipGetDevice(&whichDevice));
HANDLE_ERROR(hipGetDeviceProperties(&prop, whichDevice));
hipEvent_t start, stop;
float elapsedTime;
/*启动计时器*/
HANDLE_ERROR(hipEventCreate(&start));
HANDLE_ERROR(hipEventCreate(&stop));
HANDLE_ERROR(hipEventRecord(start, 0));
/*初始化流*/
hipStream_t stream0, stream1;
HANDLE_ERROR(hipStreamCreate(&stream0));
HANDLE_ERROR(hipStreamCreate(&stream1));
int *host_a, *host_b, *host_c;
int *dev_a0, *dev_b0, *dev_c0; /*为第0个流分配的GPU内存*/
int *dev_a1, *dev_b1, *dev_c1; /*为第1个流分配的GPU内存*/
/*在GPU上分配内存*/
HANDLE_ERROR(hipMalloc((void **)&dev_a0, N * sizeof(int)));
HANDLE_ERROR(hipMalloc((void **)&dev_b0, N * sizeof(int)));
HANDLE_ERROR(hipMalloc((void **)&dev_c0, N * sizeof(int)));
HANDLE_ERROR(hipMalloc((void **)&dev_a1, N * sizeof(int)));
HANDLE_ERROR(hipMalloc((void **)&dev_b1, N * sizeof(int)));
HANDLE_ERROR(hipMalloc((void **)&dev_c1, N * sizeof(int)));
/*分配在流中使用的页锁定内存*/
HANDLE_ERROR(hipHostAlloc((void **)&host_a, FULL_DATA_SIZE * sizeof(int), hipHostMallocDefault));
HANDLE_ERROR(hipHostAlloc((void **)&host_b, FULL_DATA_SIZE * sizeof(int), hipHostMallocDefault));
HANDLE_ERROR(hipHostAlloc((void **)&host_c, FULL_DATA_SIZE * sizeof(int), hipHostMallocDefault));
for(int i = 0; i < FULL_DATA_SIZE; i++)
{
host_a[i] = rand();
host_b[i] = rand();
}
/*在整体数据上循环,每个数据块的大小为N*/
for(int i = 0; i < FULL_DATA_SIZE; i += N * 2)
{
/*将锁定内存以异步方式复制到设备上*/
HANDLE_ERROR(hipMemcpyAsync(dev_a0, host_a + i, N * sizeof(int), hipMemcpyHostToDevice, stream0));
HANDLE_ERROR(hipMemcpyAsync(dev_b0, host_b + i, N * sizeof(int), hipMemcpyHostToDevice, stream0));
kernel<<<N / 256, 256, 0, stream0>>>(dev_a0, dev_b0, dev_c0);
/*将数据从设备复制回锁定内存*/
HANDLE_ERROR(hipMemcpyAsync(host_c + i, dev_c0, N * sizeof(int), hipMemcpyDeviceToHost, stream0));
/*将锁定内存以异步方式复制到设备上*/
HANDLE_ERROR(hipMemcpyAsync(dev_a1, host_a + i + N, N * sizeof(int), hipMemcpyHostToDevice, stream1));
HANDLE_ERROR(hipMemcpyAsync(dev_b1, host_b + i + N, N * sizeof(int), hipMemcpyHostToDevice, stream1));
kernel<<<N / 256, 256, 0, stream1>>>(dev_a1, dev_b1, dev_c1);
/*将数据从设备复制回锁定内存*/
HANDLE_ERROR(hipMemcpyAsync(host_c + i + N, dev_c1, N * sizeof(int), hipMemcpyDeviceToHost, stream1));
}
/*在停止应用程序的计时器之前,首先将两个流进行同步*/
HANDLE_ERROR(hipStreamSynchronize(stream0));
HANDLE_ERROR(hipStreamSynchronize(stream1));
HANDLE_ERROR(hipEventRecord(stop, 0));
HANDLE_ERROR(hipEventSynchronize(stop));
HANDLE_ERROR(hipEventElapsedTime(&elapsedTime, start, stop));
printf("Time taken: %3.1f ms\n", elapsedTime);
/*释放流和内存*/
HANDLE_ERROR(hipHostFree(host_a));
HANDLE_ERROR(hipHostFree(host_b));
HANDLE_ERROR(hipHostFree(host_c));
HANDLE_ERROR(hipFree(dev_a0));
HANDLE_ERROR(hipFree(dev_b0));
HANDLE_ERROR(hipFree(dev_c0));
HANDLE_ERROR(hipFree(dev_a1));
HANDLE_ERROR(hipFree(dev_b1));
HANDLE_ERROR(hipFree(dev_c1));
HANDLE_ERROR(hipStreamDestroy(stream0));
HANDLE_ERROR(hipStreamDestroy(stream1));
return 0;
}三、编译运行
HIP程序采用hipcc编译。
![]()
运行结果:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











