




目录
20世纪80年代,异构计算技术就已经诞生了。异构就是CPU、DSP、GPU、ASIC、协处理器、FPGA等各种计算单元、使用不同的类型指令集、不同的体系架构的计算单元,组成一个混合的系统,执行计算的特殊方式,这种计算方式叫做“异构计算”。不同异构计算单元有各自的体系架构,如何利用异构计算单元的算力资源,需要通过对应体系架构的编程来实现。针对目前主流异构计算体系,相应的编程语言有OpenMP、MPI、CUDA/HIP、OpenACC、OpenCL等。下面对代表性异构编程语言进行简单介绍。
一、OpenMP
OpenMP是共享内存型计算架构的多线程并行编程语言,主要由编译制导语句、运行时库函数和环境变量等组成,可提供一个可移植、可扩展的共享内存应用编程模型。OpenMP支持Fortran和C/C++。
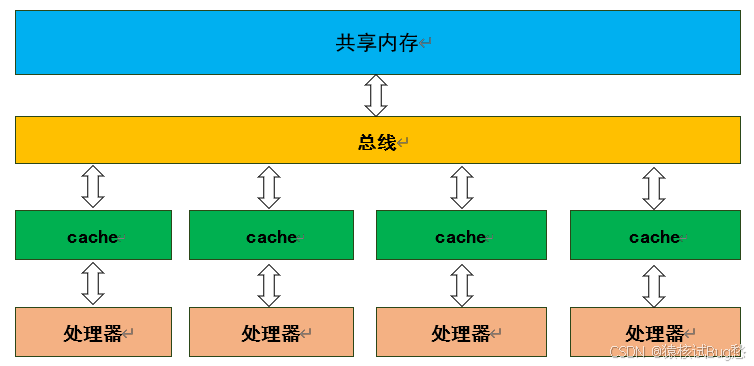
OpenMP共享内存并行编程模型中,所有处理器都可以用访问共享内存并使用多个线程进行计算。OpenMP使用Fork-Join模型来实现并行,主要机制是使用一个线程作为主线程启动程序,主线程进入并行区域,派生多个从线程,与主线程组成一个工作组,共同执行并行代码。离开并行区域后,从线程将被置于睡眠状态,直到程序抵达下一个并行区域。
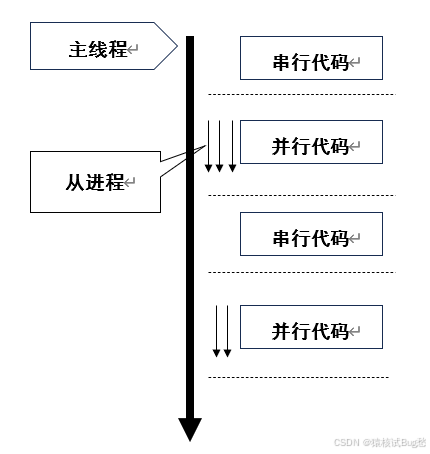
OpenMP使用编译制导语句提供一套对并行算法更高层次的抽象实现,包括指定并行区域、指定循环区域、指定临界区、设置同步等各种指令。OpenMP以#pragma omp作为编译制导语句的标识符,由编译器自动对程序实现并行化,降低并行编程的难度。但是OpenMP不适合处理复杂同步和互斥操作的场景。
二、MPI
目前成规模的计算组织方式以集群形式为主,采用多节点的分布式存储结构,这种结构可扩展计算节点,节点之间并行操作时需要通过通信来完成,主流的方式是消息传递。在这种形式的计算集群中,并行编程主要采用消息传递接口(Message Passing Interface,MPI)。MPI是消息传递库的标准规范,提供了大量消息传递例程,MPI进程可以在分布式环境中实现跨节点数据通信。MPI最大的优点就是可移植性和易用,基于MPI实现的并行程序组件,允许应用程序、软件库和其他工具在不同机器之间方便快速的移植。
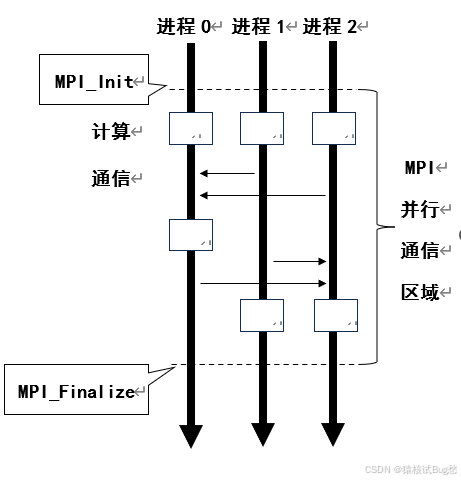
MPI-1协议中提供了多种点对点通信和集体通信的例程。点对点通信包括阻塞和非阻塞两种形式,根据数据管理及发送方、接收方之间的同步方式,可分为标准、就绪、缓冲、同步四种通信模式。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











