




- Embeddings from Language Model(ELMO)
- Bidirectional Encoder Representations from Transformers(BERT)
- Generative Pre-Training(GPT)
二十五、ELMO,BERT,GPT
怎么让机器去读人类的文字。
在BERT之前的方法:
同一个词汇是可能有不同的意思的,举例:

过去在做embedding时每一个word type有一个embedding,不同的token属于同一个type,它所对应的vector就是一模一样的。事实上并不是如此,不同的token就算它们是同样的type,也有可能有不同的语义,我们希望给不同意思的token,即使是同样的type,也要给不同的embedding。过去的做法就是给它们不同的type不同的embedding。这样做是不够的。
现在期待机器可以更进一步做到每一个word token都有一个embedding(即使它有同样的word type),这个word tokens的embedding取决于它的上下文context,上下文越相近的token,它们就有越相近的embedding。这个技术叫做Contextualized Word Embedding(语境化词语嵌入)。
(一)Embeddings from Language Model(ELMO)
怎么给每个word token不同的embedding?
这个技术叫做Embeddings from Language Model(ELMO):
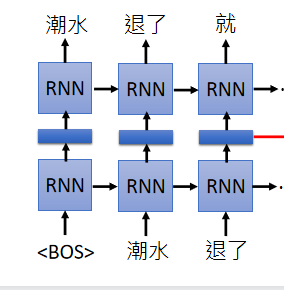
是一个RNN-based language model(trained from lots of sentences),举例现在有一个句子“潮水 退了 就 知道 谁 没穿 裤子”,教你的RNN-based language model如果看到一个begin of sentence的符号,就要输出“潮水”,接下来再给你“潮水”这个符号,你就要输出“退了”,给你“潮水”和“退了”的符号就要输出“就”…即给它很多句子让它去学怎么预测下一个token。
学完以后就有word embedding,我们可以把RNN的hidden layer拿出来说它就是现在输入的那个词汇的word embedding。假设你把“退了”这个词汇输进去,RNN会吐一个embedding出来给你,这个embedding就是“退了”这个词汇的embedding。
同样的词汇,如果上下文不同的话,RNN 出来的embedding就会不一样。
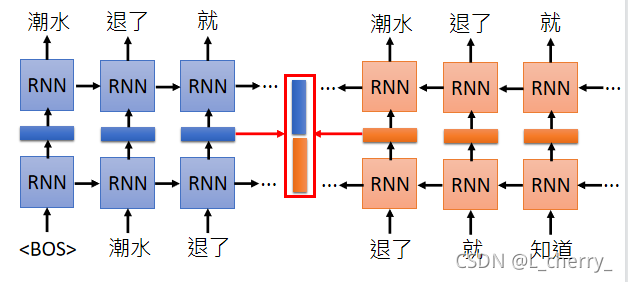
这样好像只考虑到每个词汇的前文,没有考虑到后文,解决方法:再train一个反向的RNN,从句子的尾巴读过来。今天如果要得到“退了”这个词汇的word embedding,就把“退了”这个词汇在正向的RNN的 embedding跟逆向的RNN的embedding接起来:
这个RNN可以是deep的,train的时候会遇到问题,因为它有很多层,每一层都有embedding,那到底应该要用哪一层呢?
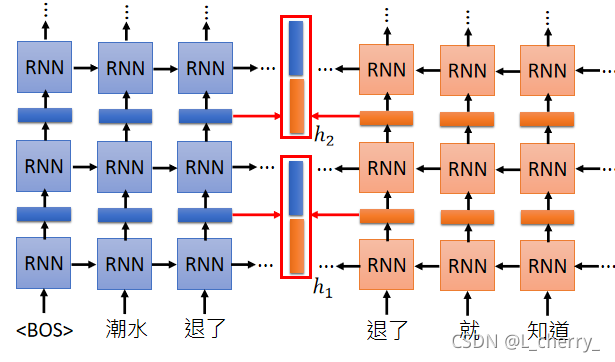
ELMO的做法是:现在每一层都会给我们word embedding,每一层的每个词汇都会有embedding,每个词汇都不止一个embedding,方法就是把这些embedding加起来一起用。但是怎么加起来?
ELMO会做weighted sum,它会把第一层吐出来的embedding乘上α1\alpha_1α1,第二层吐出来的embedding乘上
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1446
1446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









