







Spring Cloud+ Sleuth + Zipkin链路追踪
- 01、Spring Cloud Zipkin链路追踪
- 02、SpringCloud ZipkinServer 搭建过程
- 03、SpringCloud Zipkin Client搭建过程 - http模型
- 04、SpringCloud Zipkin Client搭建过程 - RabbitMQ模型 +Http模型
- 05、ZipKin参数配置官网参考
- 06、SpringCloud Zipkin Client搭建过程 - RabbitMQ模型 +MYSQL模型
- 07、SpringCloud Zipkin Client搭建过程 - RabbitMQ模型 +ES模型
- 08、SpringCloud Zipkin Client搭建过程 - Kafka模型 +Web模型
- 09、SpringCloud Zipkin Client搭建过程 - Kafka模型 +ES/mysql模型
- 10、Zipkin参数分析JSON
01、Spring Cloud Zipkin链路追踪
01、Zipkin的来源和背景
2010年谷歌发表了其内部使用的分布式跟踪系统Dapper的论文(http://static.googleusercontent.com/media/research.google.com/zh-CN/archive/papers/dapper-2010-1.pdf,译文地址:http://bigbully.github.io/Dapper-translation/),讲述了Dapper在谷歌内部两年的演变和设计、运维经验,Twitter也根据该论文开发了自己的分布式跟踪系统Zipkin,并将其开源,但不知为啥没有贡献给Apache。其实还有很多的分布式跟踪系统,比如naver的Pinpoint、Apache的HTrace,阿里的鹰眼Tracing、京东的Hydra、新浪的Watchman等。
谷歌的团队于2010年开发了一个产品叫zipkin,专门用于分布式项目服务链路追踪系统。
02、大型互联网公司为什么需要分布式跟踪系统?
- 1.为了支撑日益增长的庞大业务量
- 2.动态展示服务的链路
- 3.分析服务链路的瓶颈并对其进行调优
- 4.快速进行服务链路的故障发现
这就是服务跟踪系统存在的目的和意义。
我们目前开发程序,及时作为分布式系统的开发者,也很难清楚的说出某个服务的调用链路,况且服务调用链路还是动态变化的,这时候只能咬紧牙关翻代码了。接下来,可以使用zipkin是完成这样事情?
设计初衷
现代的大型应用系统一般是复杂的分布式系统,他们由许多的软件模块构成,这些软件模块可能由不同的团队用不同的编程语言编写而成,因此那些传统的用于理解系统行为,分析性能问题的工具,在这种复杂环境下变得失效。
设计理念
主要有三个设计目标:
-
低负载(low overhead)
-
应用级透明(application-level transparency)
-
大范围部署(ubiquitous deployment)
03、什么是Zipkin?
在spring cloud分布式架构中,系统被拆分成了许多个服务单元,业务复杂性提高。如果出现了异常情况,很难定位到错误位置,所以需要实现分布式链路追踪,跟进每一个请求有哪些服务参与,参与的顺序如何,从拿来到哪里去需要有一个明确的方向,虽然前面sleuth日志分布式链路追踪,但是分析不方便,所有使用zipkin弥补这块展示和收集和持久化的问题。
Zipkin是一款开源的分布式实时数据追踪系统(Distributed Tracking System),其主要功能是聚集来自各个异构系统对的实时数据监控。
什么是Zipkin的核心要素:
- 数据收集 (kafka/rabbitmq/基于内存web)
- 数据存储(es/mysql)
- 数据展示 (webui)
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,主要用于数据的存储、查找和展示。 zipkin 提供了可拔插数据存储方式,生产环境中推荐使用 Elasticsearch,还能结合 kibana 使用。
Zipkin 和 Config 结构类似,分为服务端 Server,客户端Client,客户端就是各个微服务应用。
04、Zipkin的默认搭建方式
官网:https://github.com/openzipkin/zipkin/
github源码地址:https://github.com/openzipkin/zipkin/
模式:sleuth + zipkin +内存
05、传统日志收集的选型
ELK /EFK + kafka
06、微服务的链路追踪 -架构模型
-
sleuth + zipkin +内存
-
sleuth + logstash+es+kibana
-
sleuth +logstash +kafka +es+kibana
-
sleuth +zipkin +kafka/rabbitmq +es/mysql+kibana
-
sleuth +zipkin +kafka/ribbitmq +es/mysql+kibana
07、Zipkin搭建服务端-自搭建(不推荐)
1、创建一个springboot【2.1.13.RELEASE】的项目【ksd-sleuth-zipkin-server】
2、依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.13.RELEASE</version>
<relativePath/>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>ksd-sleuth-zipkin-server</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
<version>2.12.9</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>2.12.9</version>
</dependency>
</dependencies>
</project>
3、配置application.properties
spring.application.name=zipkin-server
server.port=9411
#zipkin启动或访问报错无法访问的解决方法
management.metrics.web.server.auto-time-requests=false
4、启动运行
package com.ksd.pug.cloud;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.builder.SpringApplicationBuilder;
import zipkin2.server.internal.EnableZipkinServer;
import zipkin2.server.internal.RegisterZipkinHealthIndicators;
@SpringBootApplication
@EnableZipkinServer
public class SleuthZipkinServerApplication {
public static void main(String[] args) {
new SpringApplicationBuilder(SleuthZipkinServerApplication.class).listeners(new RegisterZipkinHealthIndicators())
.properties("spring.config.name=zipkin-server")
.run(args);
}
}
5、访问 http://localhost:9411/zipkin/
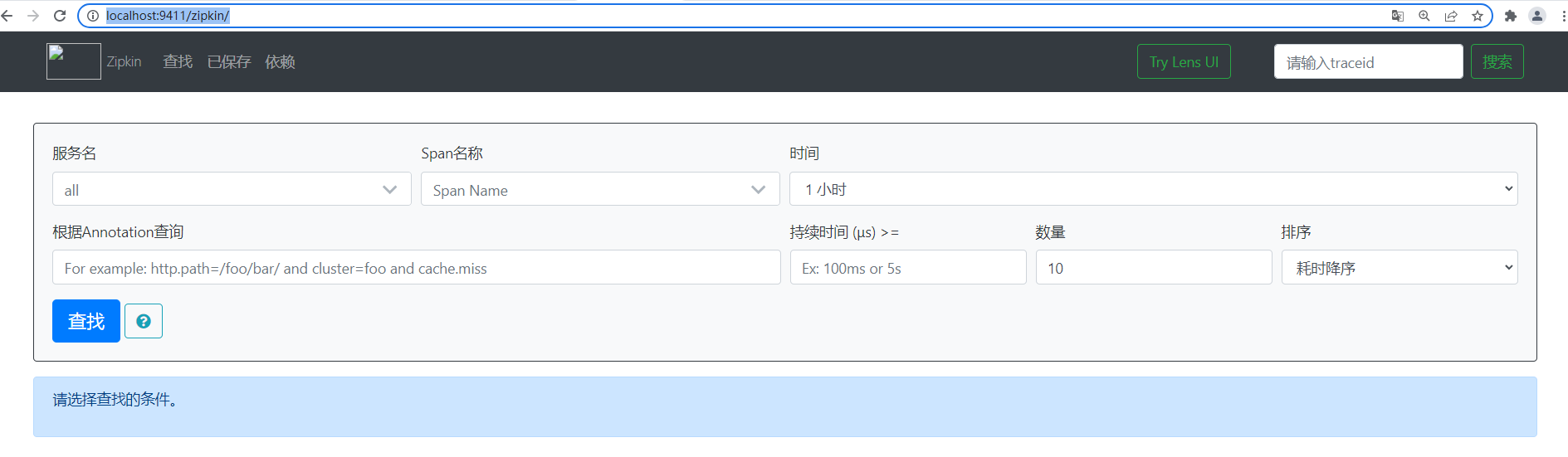
小结:
- 默认端口是:9411
- 新版本不推荐使用自己搭建服务。
02、SpringCloud ZipkinServer 搭建过程
01、Zipkin Server的默认搭建方式
-
官网:https://github.com/openzipkin/zipkin/
-
github源码地址:https://github.com/openzipkin/zipkin/
02、Zipkin Server服务的下载 - 基于jar的方式
下载最新版:https://search.maven.org/remote_content?g=io.zipkin&a=zipkin-server&v=LATEST&c=exec
下载指定版本:下载最新版:https://search.maven.org/remote_content?g=io.zipkin&a=zipkin-server&v=2.17.2&c=exec
03、启动zipkinserver服务
java -jar zipkin-server-2.17.2-exec.jar
备注:必须环境为java8及其以上。
04、启动zipkinserver服务
访问 http://localhost:9411/zipkin/
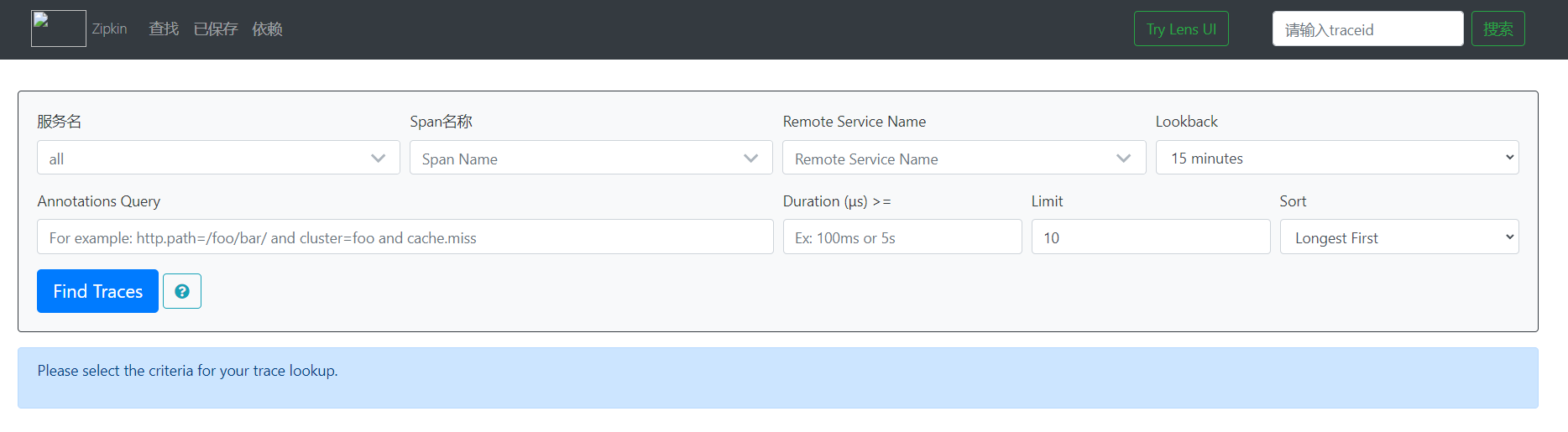
05、如果你想用docker如下:
https://github.com/openzipkin/zipkin
docker run -d -p 9411:9411 openzipkin/zipkin
03、SpringCloud Zipkin Client搭建过程 - http模型
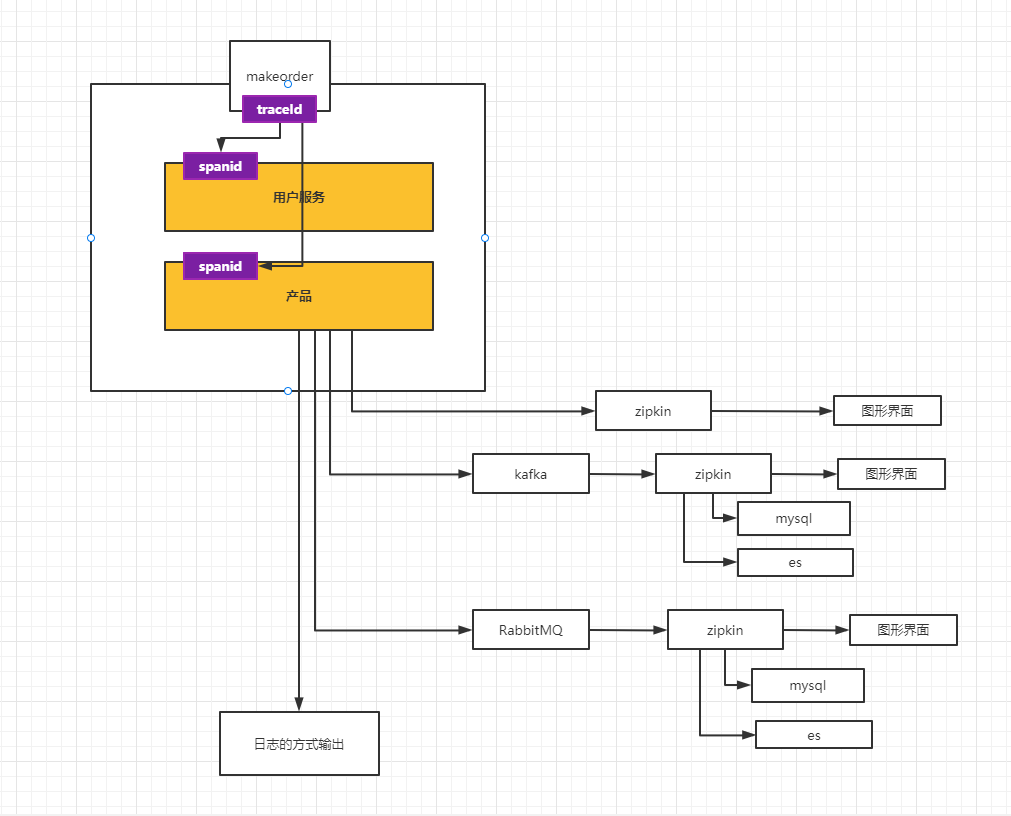
图形结构如下:

具体操作:
-
模式:sleuth + zipkin +http+web+内存
-
Zipkin 可以基于Sleuth进行日志的收集和展示,所有需要完成如下步骤:
1:在所有的需要监控的服务中,进行依赖配置,比如:
- kuangstudy-order-service
- kuangstudy-product-service
- kuangstudy-user-service
2:依赖
- 仅仅使用Spring Cloud Sleuth,不包含Zipkin
<dependency>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7870
7870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









