




 本文介绍了集成学习的概念,重点讲解了Boosting中的AdaBoost算法,包括其工作原理、代码实现及部分结果展示。同时,提到了与AdaBoost相关的Bagging和随机森林方法。
本文介绍了集成学习的概念,重点讲解了Boosting中的AdaBoost算法,包括其工作原理、代码实现及部分结果展示。同时,提到了与AdaBoost相关的Bagging和随机森林方法。
一、集成学习
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)等。
集成学习将多个学习器进行结合,常可获得比单一学习器显著优越的泛化性能。这对“弱学习器”(weak learner)尤为明显,因此,集成学习的很多理论研究都是针对弱学习器进行的,而基学习器有时也被直接称为弱学习器。
集成学习的一般结构:先产生一组“个体学习器”,再用某种策略将它们结合起来。个体学习器通常由一个现有的学习算法从训练数据产生。集成可以只包含同种类型的个体学习器(同质集成中,个体学习器又称基学习器),称为同质集成;也可以包含不同类型的个体学习器(异质集成中,个体学习器又称组件学习器),称为异质集成。
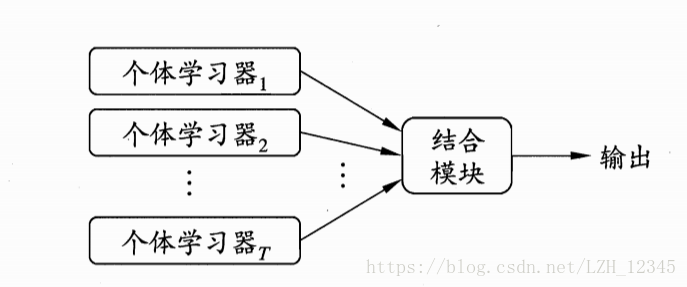
想要获得好的集成,对个体学习器有两个要求:
- 准确性,个体学习器至少不差于弱学习器;
- 多样性,个体学习器之间要有差异。
集成学习方法有两大类:
- 个体学习器间存在强依赖关系、必须串行生成序列化方法,例如:Boosting
- 个体学习器间不存在强依赖关系、可同时生成的并行化方法,例如:Bagging和“随机森林”(Random Forest)
二、Bagging:基于数据随机重抽样的分类器构建方法
自举汇聚法(bootstrap aggregating),也称为bagging方法,是在从原始数据集选择S次后得到S个新数据集的一种技术。新数据集和原数据集的大小相等。每个数据集都是通过在原始数据集中随机选择一个样本来进行替换而得到的。这里的替换就意味着可以多次地选择同一样本。这一性质就允许新数据集中可以有重复的值,而原始数据集的某些值在新集合中则不再出现。
在S个数据集建好之后, 将某个学习算法分别作用于每个数据集就得到了S个分类器。当我们要对新数据进行分类时,就可以应用这S个分类器进行分类。与此同时,选择分类器投票结果中最多的类别作为最后的分类结果。
随机森林(random forest)是一种更先进的bagging方法。


三、Boosting

3.1 AdaBoost算法

3.2 代码实现
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 26 19:01:54 2018
利用AdaBoost算法从疝气病症预测病马死亡率
@author: lizihua
"""
from numpy import matrix,ones,shape,mat,zeros,log,multiply,exp,sign
import matplotlib.pyplot as plt
import numpy as np
#加载简单数据
def loadSimpData():
datMat = matrix([[1,2.1],[2,1.1],[1.3,1],[1,1],[2,1]])
classLabels = [1,1,-1,-1,1]
return datMat, classLabels
#自适应加载数据
def loadDataSet(fileName):
numFeat = len(open(fileName).readline().split('\t'))
dataMat = [];labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat-1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat
#单层决策树生成函数
#dataMatrix:训练数组;dimen列索引;threshVal:阈值;threshIneq:比较符号
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
#初始化返回数组,全部设置为1
retArray = ones((shape(dataMatrix)[0],1))
#比较符号是小于(less than)时:
if threshIneq == 'lt':
#将训练数组中某列值小于等于阈值的对应索引对应的返回数组的元素设置为-1
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
#否则,比较符号是大于gt(great than)时:
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
#遍历stumpClassify()函数所有可能输入值,并找到数据集上最佳的单层决策树
def bulidStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr)
labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
#numSteps:步数;bestStump保存最佳单层决策树的相关信息;bestClasEst:最佳预测结果
numSteps = 10.0;bestStump = {};bestClasEst = mat(zeros((m,1)))
#minError取无穷大
minError = np.inf
#遍历所有特征
for i in range(n):
rangeMin = dataMatrix[:,i].min()
rangeMax = dataMatrix[:,i].max()
stepSize = (rangeMax-rangeMin)/numSteps
#遍历所有步长,步长即阈值,阈值设置为整个取值范围之外也是可以的
for j in range(-1,int(numSteps)+1):
#在大于和小于之间切换
for inequal in ['lt','gt']:
threshVal = (rangeMin + float(j)*stepSize)
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
#计算加权错误率
weightError = D.T*errArr
#print("split:dim %d,thresh %.2f,thresh inequal: %s,the weighted error is %.3f"%(i,threshVal,inequal,weightError))
#找到最小错误率的最佳单层决策树,并保存相关信息
if weightError < minError:
minError = weightError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
#基于单层决策树(DS,decision stump)的AdaBoost训练过程
#输入参数:数据集、类别标签、迭代次数(默认为40)
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m)
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = bulidStump(dataArr,classLabels,D)
print("D:",D.T)
#alpha公式:alpha=1/2*ln((1-error)/error)
#max(error,1e-16)是为了确保在没有错误时不会发生溢出
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
print("classEst:",classEst.T)
#更新D,D是一个概率分布向量,因此,其所有元素之和为1
#D=(D*exp(-alpha*classLabels*classEst))/D.sum()
#其中,classLabels是实际样本标签,classEst是分类器分类后得到的预测分类结果
#multiply是点积,其中,该例中,classLabels:1*m;classEst:m*1
expon = multiply(-1*alpha*mat(classLabels).T,classEst)
D = multiply(D,exp(expon))
D = D/D.sum()
#更新累计类别估计值
#aggClassEst记录每个数据点的类别估计累计值
#最终分类函数H(x)=sign(aggClassEst),而aggClassEst += alpha*classEst
aggClassEst += alpha*classEst
print("aggClassEst:",aggClassEst.T)
#计算错误率
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print("total error:",errorRate,"\n")
#当总错误率为0时,直接终止循环
if errorRate == 0.0:
break
return weakClassArr,aggClassEst
#AdaBoost分类函数
def adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],classifierArr[i]['thresh'],classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha']*classEst
print("aggClassEst:",aggClassEst)
return sign(aggClassEst)
#绘制数据图形
def plot(datMat,classLabels):
xcord0=[];xcord1=[];ycord0=[];ycord1=[]
for i in range(len(classLabels)):
if classLabels[i] == 1:
xcord1.append(datMat[i,0])
ycord1.append(datMat[i,1])
else:
xcord0.append(datMat[i,0])
ycord0.append(datMat[i,1])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord0,ycord0, marker='s', s=50)
ax.scatter(xcord1,ycord1, marker='o', s=50, c='red')
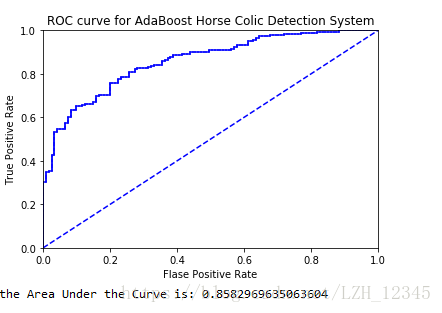
#绘制ROC曲线及AUC的计算
def plotROC(predStrengths, classLabels):
cur = (1.0,1.0)
ySum = 0.0
#numPosClass是真实结果中的所有正例
numPosClass = sum(np.array(classLabels) == 1.0)
yStep = 1/float(numPosClass)
xStep = 1/float(len(classLabels)-numPosClass)
#获得排好序的索引
sortedIndicies = np.argsort(predStrengths)
fig = plt.figure()
ax = fig.add_subplot(111)
for index in sortedIndicies.tolist()[0]:
if classLabels[index] == 1.0:
delX = 0;delY = yStep;
else:
delX = xStep;delY = 0;
ySum += cur[1]
ax.plot([cur[0],cur[0]-delX],[cur[1],cur[1]-delY],c='b')
cur = (cur[0]-delX,cur[1]-delY)
ax.plot([0,1],[0,1],'b--')
plt.xlabel("Flase Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC curve for AdaBoost Horse Colic Detection System")
ax.axis([0,1,0,1])
plt.show()
print("the Area Under the Curve is:",ySum*xStep)
#测试
if __name__ =="__main__":
"""
dataMat,labels = loadSimpData()
classifierArr = adaBoostTrainDS(dataMat,labels,30)
result0 = adaClassify([0,0],classifierArr)
print(result0)
result1 = adaClassify([[5,5],[0,0]],classifierArr)
print(result1)
D = mat(ones((5,1))/5)
weakClassArr = adaBoostTrainDS(dataMat,labels,9)
print(weakClassArr)
bestStump, minError, bestClasEst = bulidStump(dataMat,labels,D)
print(bestStump,minError,bestClasEst)
"""
datArr,labelArr = loadDataSet('horseColicTraining2.txt')
classifierArray,aggClassEst = adaBoostTrainDS(datArr,labelArr,10)
testArr,testLabelArr = loadDataSet('horseColicTest2.txt')
#分类器分类结果
prediction10 = adaClassify(testArr,classifierArray)
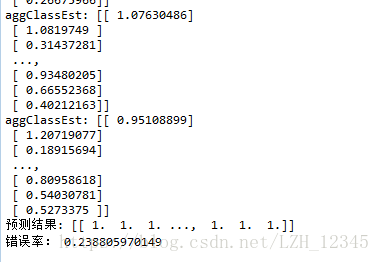
print("预测结果:",prediction10.T)
#计算错误率
errorArr = mat(ones((67,1)))
errorRate = (errorArr[prediction10 !=mat(testLabelArr).T].sum())/67
print("错误率:",errorRate)
plotROC(aggClassEst.T,labelArr)
3.3 部分结果显示

















 606
606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









