






1.Hive的基本概念
在安装Hive之前,我们先来了解一下什么是Hive。
我们知道,hadoop的hdfs可以存海量数据,这些数据可以是普通的文本文件,可以是音频文件,也可以是视频文件等等。如果想要分析处理hdfs上的文件,则不管文件的内容是结构化(如csv文件)的还是非结构化的,都需要写代码开发mapreduce任务。
由于开发mapreduce任务是需要有编程能力的,且需要掌握mapreduce框架的一些知识,是有门槛的,如果只会sql语言的非专业开发人员想要查询、分析一些hdfs上的结构化数据,怎么办呢?这时,hive应运而生。
Hive是一个数据仓库基础工具软件,它可以解析hive sql语句(和sql基本上一致),并将hive sql转成相应的mapreduce任务运行。最初的设计目的就是为了让会SQL但是不会编程MapReduce的人也能使用Hadoop进行数据处理。
2.Hive和关系型数据库(MySql)的一些区别
- 应用场景不同。Hive要将hive sql转成MapReduce任务执行,所以尽管查询数据量很少,查询延时都很大,它只适合做海量离线数据统计分析。
- 默认情况下,hive不支持数据的更新、删除。因为hive一般用做数据仓库,仓库存储的数据是海量且不经常更新的。
- 生产环境往hive表存数据时,不建议直接使用insert语句。因为每执行一次insert语句,等价于执行一次mapreduce任务,如果多次执行insert,那么效率将会非常低。
3.Hive架构
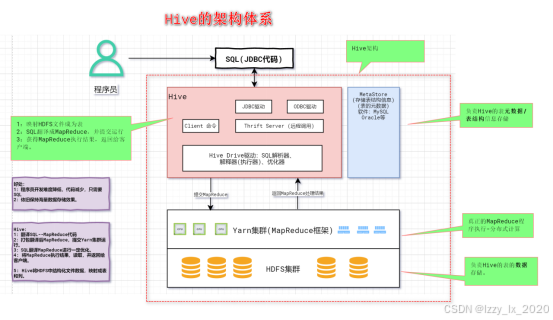
Hive通过将SQL查询转换为MapReduce作业,利用HDFS进行数据存储和YARN进行资源管理,提供了一个高效的大数据处理和分析平台。理解这个架构有助于更好地利用Hive进行大数据处理,并优化查询性能。
4.Hive3.3安装(以安装到master节点为例)
首先到网盘下载hive3.1.3的安装包(apache-hive-3.1.3-bin.tar.gz),然后上传到Centos7。登录到Centos7,将apache-hive-3.1.3-bin.tar.gz解压到/usr/local路径下。解压的代码如:tar -xzvf apache-hive-3.1-3-bin.tar.gz
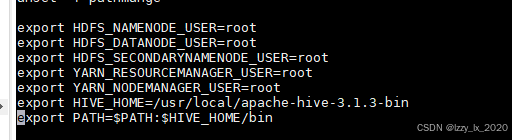
随后设置HIVE_HOME环境变量以及PATH环境变量在最后两行加入
export HIVE_HOME=/usr/local/apache-hive-3.1.3-bin和export PATH=$PATH:$HIVE_HOME/bin.
配置完后执行source /etc/profile重新运行配置文件。
将当前路径切换到hive的配置文件路径:cd $HIVE_HOME/conf,并在该路径下创建一个hive-site.xml文件,该文件内容如下:
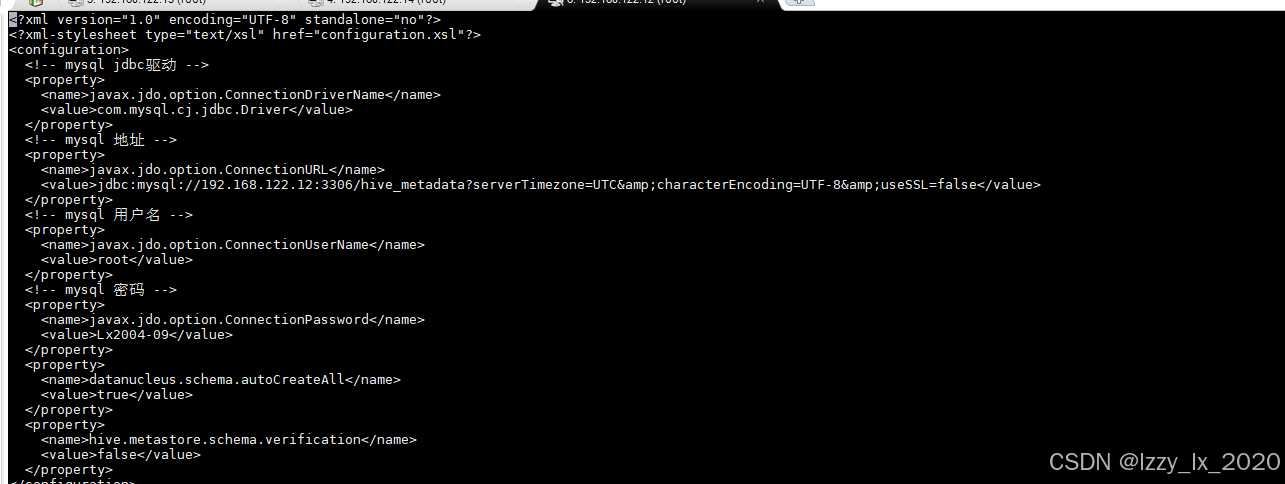
随后再将mysql驱动mysql-connector-java-8.0.15.jar上传到hive安装目录的lib路径下,将$HIVE_HOME/lib的guava-19.0.jar删掉(版本太低了),然后将拷贝一个新的guava版本(拷贝命令:cp $HADOOP_HOME/share/hadoop/common/lib/guava-27.0-jre.jar $HIVE_HOME/lib)。运行完以上命令后打开mysql,在mysql上创建一个数据库,用来存hive的元数据信息(表名、表结构等信息)。mysql数据库建表语句:CREATE DATABASE hive_metadata DEFAULT CHARACTER SET UTF-8:
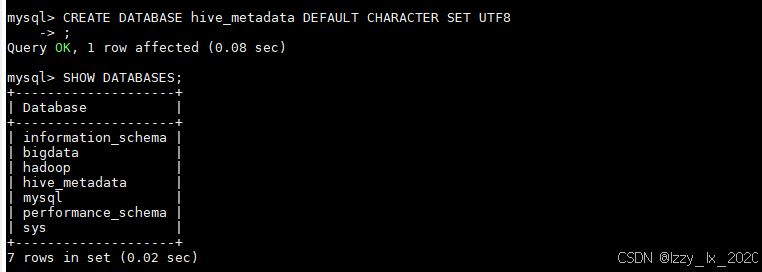
hive初始化(只初始化一次,后续不用再初始化):初始化命令:schematool -initSchema -dbType mysql:

出现这两条说明初始化成功。在执行hive命令,查看是否安装成功。并查看hive的数据库。

最后再hive建立一个数据库:
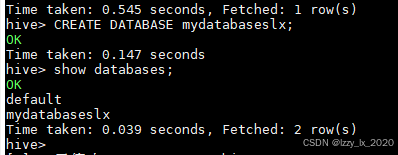
说明,hive安装成功并且能够正常使用!

















 177
177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









