




 本文介绍如何运用爬虫技术抓取豆瓣电影排行榜前250名的电影信息,通过学习和实践爬虫,同时解决观影选择难题。
本文介绍如何运用爬虫技术抓取豆瓣电影排行榜前250名的电影信息,通过学习和实践爬虫,同时解决观影选择难题。
爬取豆瓣电影top250
平时不知道看什么电影,正好最近学习了爬虫,自己试着把电影排行下载下来,边看边学两不误。
下面直接上代码:
import requests
from bs4 import BeautifulSoup
# 爬取网页源码
def download_page(url):
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
req = requests.get(url=url, headers=headers)
return req.content
# 爬取单页电影名返回列表
def get_page_list(html):
soup = BeautifulSoup(html, 'lxml')
# find方法返回的是第一个符合条件的元素
movie_list_soup = soup.find('ol', attrs={'class': 'grid_view'})
movie_name_list = []
# find_all 返回所有符合条件的元素
for movie_li in movie_list_soup.find_all('li'):
movie_name = movie_li.find('span', attrs={'class': 'title'}).getText()
movie_num = movie_li.find('em').getText()
movie_score = movie_li.find('span', attrs={'class': 'rating_num'}).getText()
movie_name_list.append('%s.%s score: %s分' % (movie_num, movie_name, movie_score))
return movie_name_list
# 保存文件
def write_file(url):
with open('douban_top_movies.txt', 'a', encoding='utf-8') as f:
html = download_page(url)
movies = get_page_list(html)
for movie in movies:
f.write(str(movie) + '\n')
def main():
# 通过分析发现每一页地址的'start='后的数字不同,每页递增25正是每一页所含有的电影数,通过遍历即可爬取每一页
for n in range(0, 250, 25):
page_url = 'http://movie.douban.com/top250?start=%d&filter=' % n
write_file(page_url)
if __name__ == '__main__':
main()
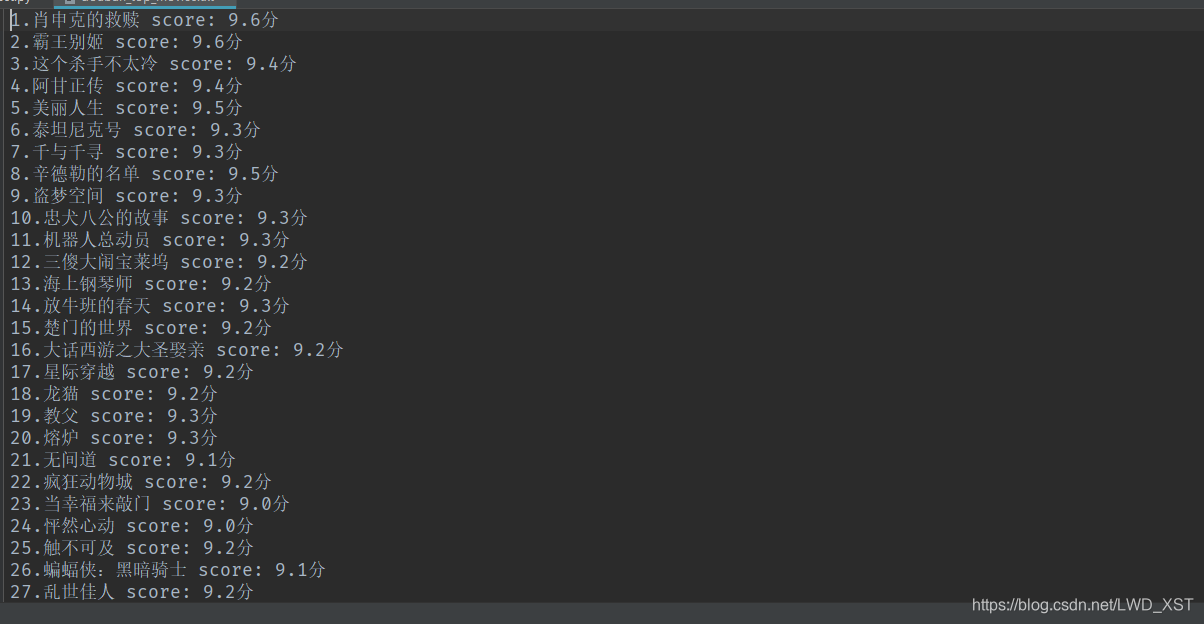
效果如图:

















 565
565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









