




CoMat: Aligning Text-to-Image Diffusion Model with Image-to-Text Concept Matching
图文一致性的原因还是因为文本的 token 的激活注意值不高,导致文本的 token 无法激活图像的区域,从而导致图文不一致。作者将这种现象归因于扩散模型的训练方式对条件的利用不足,所以提出了 CoMat,是一种 端到端的扩散模型微调策略。

1. Introduction
缺陷
其实上图所展现出来的还是很基础的目标丢失问题
补充一下:
这个问题归因于视觉概念的的激活值不够大而被其他物体的注意力淹没,导致了视觉概念的丢失。之前也有一些相关工作,像:Atten-and-Excite,Structur Diffusion 等
这里也有一个关于问题的分析:
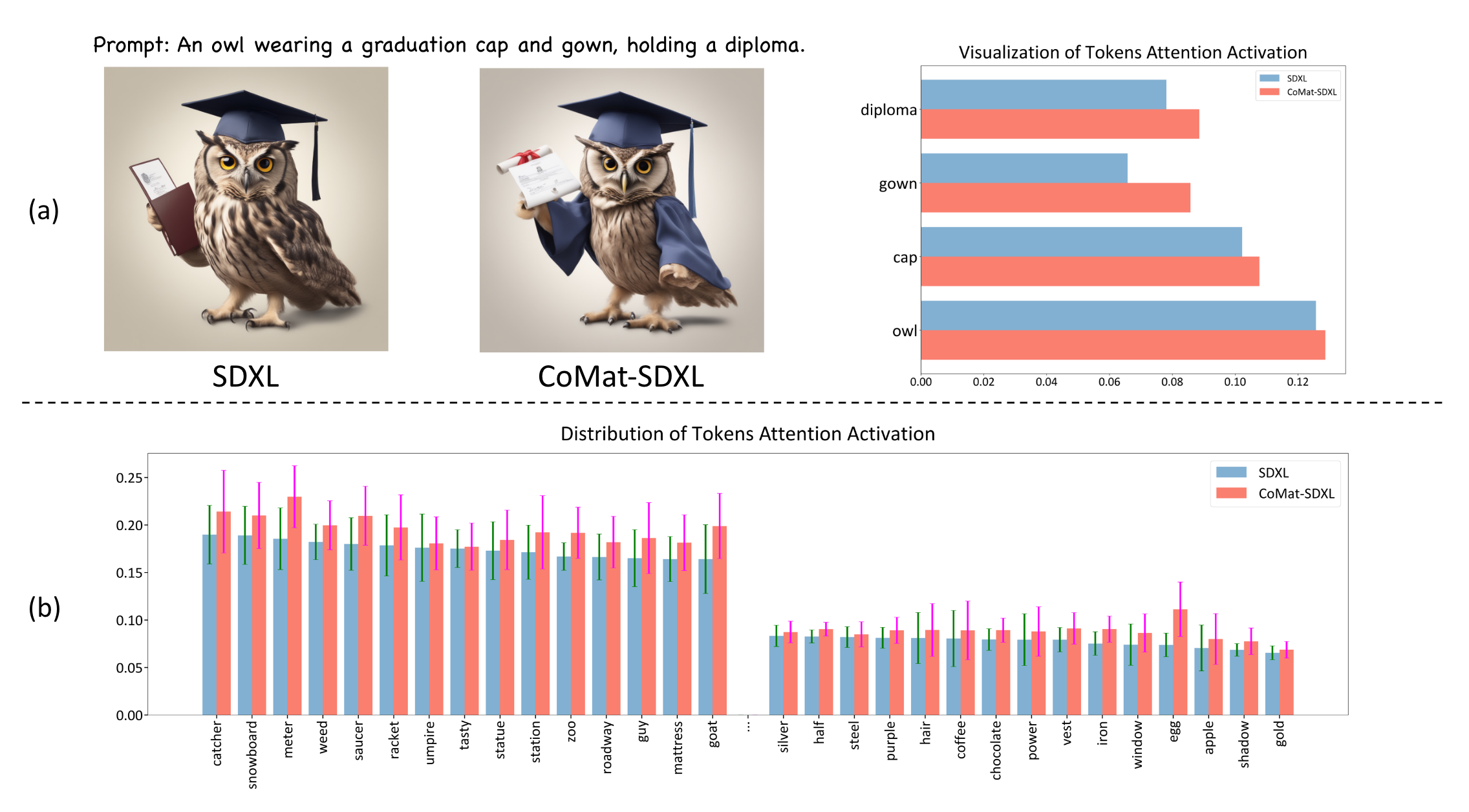
作者将 token 对应的交叉注意图进行了分析,这里采用的做法是:
- 将预训练UNet对带有文本标题的噪声图像进行降噪。然后记录每个文本token的激活值,并在空间维度上取平均值
可以看到带有 Comat 的,里面的所有激活值都有了提高
多说一句🤔
看到这里和之前的工作并没有什么不同,像 Atten-and-Excit 是将主题视觉概念的 token 去最大化响应值,这里貌似最后的结果也是一样的
2. Method
作者一共包括三个模块:
- Concept Matching
- Attribute Concentration
- Fidelity Preservation
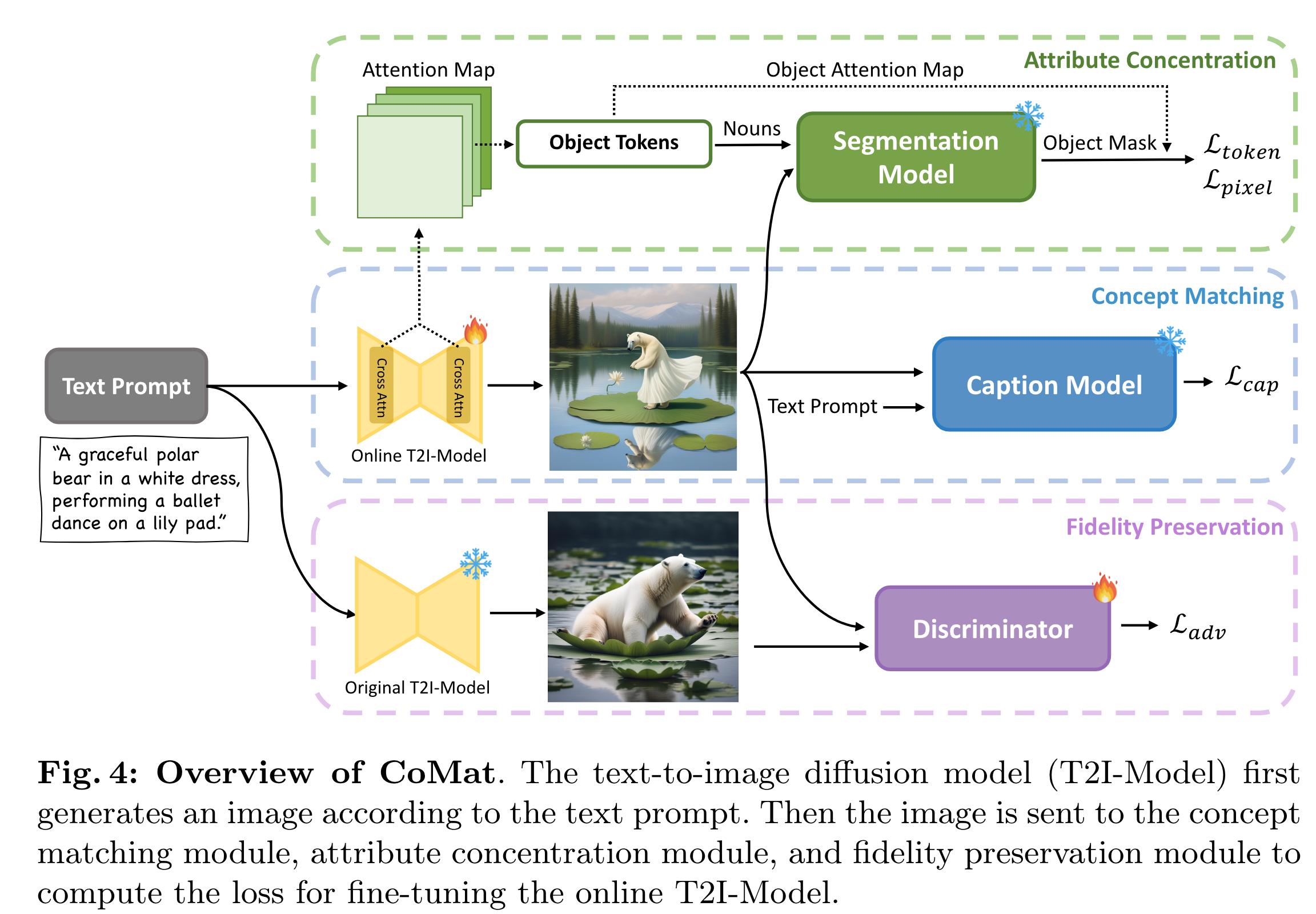
2.1 Concept Matching
这里引入了图像字幕模型,即 Caption Model ,该模型可以根据给定的文本提示准确识别生成图像中不存在的概念。
在 Caption Model 的监督下,扩散模型被迫重新访问文本标记以搜索被忽略的条件信息,并为先前被忽略的文本概念分配重要性,以获得更好的文本-图像对齐。具体来说,做法是:
- 给定文本提示 P \mathcal{P} P, 以及相应的 词tokens { w 1 , w 2 , … , w L } \{w_1, w_2, \dots, w_{L}\} { w1,w2,…,wL};
- 对于一张在经过 T \mathbf{T} T 步去噪厚的图像,这个冻结的
Caption ModelC C C 会以对数似然的形式对图文一致性进行打分,训练目标就是最小化这个分数,标记为 L cap \mathcal{L}_{\text{cap}} Lcap:
L cap = − log ( p C ( P ∣ I ( P ; ϵ θ ) ) ) = − ∑ i = 1 L log ( p C ( w i ∣ I , w 1 : i − 1 ) ) . \begin{aligned}\mathcal{L}_{\text{cap}}&=-\log(p_{\mathcal{C}}(\mathcal{P}|\mathcal{I}(\mathcal{P};\epsilon_{\theta})))=-\sum_{i=1}^{L}\log(p_{\mathcal{C}}(w_{i}|\mathcal{I},w_{1:i-1})).\end{aligned} Lcap=−log(pC(P∣I(P;ϵθ)))=−i=1∑Llog(pC(w
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1272
1272




 到【灌水乐园】发言
到【灌水乐园】发言







