




Python安装(conda环境可忽略)
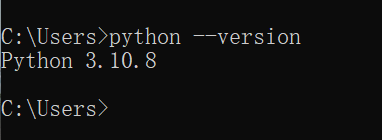
1) 下载3.10.x版本
2) 成功安装后显示
CUDA安装&cuDNN
1)>nvidia-smi,查看CUDA版本,官网下载对应的安装包
2)安装成功后,调用命令>nvcc -V,成功安装后,显示对应的版本信息
3)下载对应版本的cuDNN版本
Conda环境安装Pytorch
1) 本地可安装miniconda,可以直接安装pytorch;
2) 安装成功后,如下显示
3) 查看环境变量
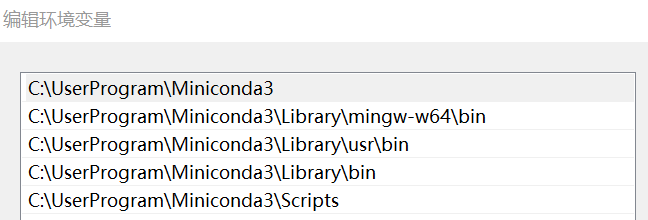
4) 通过pip安装pytorch CUDA版本
打开cmd,输入如下命令,查看CUDA版本
>nvidia-smi
5) 打开Anaconda Prompt,创建一个虚拟环境
这种方式只能在self-env环境下使用torch
(base)>conda create -n self-env python=3.8 //self-env 可以设定为pytorch的版本
(base)>conda activate self-env
(base)>conda env list
# conda environments:
#
base * D:\APPForUser\Miniconda3
self-env D:\APPForUser\Miniconda3\envs\self-env
(self-env)>pip3 install //安装pytorch
(self-env)>conda list //如下显示安装成功
torch 2.7.0+cu118 pypi_0 pypi
torchaudio 2.7.0+cu118 pypi_0 pypi
torchvision 0.22.0+cu118 pypi_0 pypi
(self-env)>conda deactivate //退出self-env用户环境
(base)>
或者,这种方式使用已经安装的python或者其他库版本,self-env 可以设定为pytorch的版本
>conda create --no-default-packages -n self-env
>conda activate self-env
Pytorch 环境部署(非conda环境)
1)确保CUDA和cuDNN已经安装,官网搜索对应的安装版,执行安装操作
2)注意查看CUDA版本
LLM部署一 应用部署之Ollama
1)配置环境变量,设置模型下载路径
OLLAMA_MODELS D:\Ollama_Modules
2)本地部署,可以下载Ollama安装
>.\OllamaSetup.exe /DIR="d:\ollama"
>ollama list //成功安装3)查看GPU ID,指定 Ollama 使用特定的 GPU, CUDA_VISIBLE_DEVICES 环境变量。
>nvidia-smi -L4)执行对应的大语言模型库,注意配置ollama使用GPU
>ollama run deepseek-r1:1.5b5)打开VSCode,安装Cline或者continue插件,并选择ollama,如下
LLM部署二 应用部署之LM Studio
1)下载LM Studio,适合初学者
LLM部署三 源码部署
1)下载transformers、vLLM等源码安装
预训练
通过无监督学习让模型理解数据的底层逻辑,其核心是让模型在海量无标注数据(如互联网文本、开源文档、多模态数据等)中自主学习通用规律、数据特征与基础知识,形成可迁移的“通识能力”。
当前主流大模型的预训练均以Transformer架构为核心,其设计巧妙解决了传统神经网络难以捕捉长距离依赖、并行计算效率低等问题,主要依赖四大核心组件:自注意力机制、多头注意力、位置编码、前馈神经网络。
微调
核心目标是: 用少量任务特定的标注数据,调整预训练模型的参数,使其适配单一下游任务。
SFT: Supervised Fine-Tuning, 监督微调
根据参数更新范围与计算成本的差异,微调可分为全参数微调与参数高效微调(PEFT)
1. 全参数微调(Full Fine-tuning):
2. 参数高效微调(Parameter-Efficient Fine-Tuning PEFT)
1)Adapter微调: 在Transformer的每一层(如自注意力层与前馈神经网络层之间)插入小型子网络(即Adapter模块,通常包含“降维-激活-升维”三个步骤),训练时仅更新Adapter的参数,冻结原模型的其余参数。
2)LoRA(低秩适应): 核心是对模型的关键权重矩阵(如自注意力层的查询矩阵、键矩阵)进行低秩分解——将原权重矩阵的更新量表示为两个低秩矩阵的乘积,训练时仅更新这两个低秩矩阵,原权重矩阵保持冻结。LoRA不仅能减少参数规模,还能避免因插入额外模块导致的推理延迟,目前已广泛应用于对话模型、代码生成模型的微调。
3)Prompt Tuning(提示微调):在输入序列的前端添加一段可训练的“软提示”(Soft Prompt,通常是一组可学习的向量),训练时仅更新软提示的参数,模型的其余参数保持不变;
4) Prefix Tuning: 基本原理是在与训练的基础上,通过添加少量的可训练参数,对模型的输出进行微调。优化策略主要包含两个方面: 一采用前缀提示策略,将提示信息添加到模型的每一层中,提高模型输出的准确性;二采用自适应优化策略,根据模型训练过程中的表现,动态调整微调参数的权重,以提高模型的收敛速度和性能。
5) RLHF:Reinforcement Learning from Human Feedback,基于⼈⼯反馈机制的强化学习⽅法
预训练、微调和蒸馏
预训练为大模型奠定了通用知识的基础,使得模型具备了对数据的基本理解和处理能力。微调则是在预训练的基础上,针对特定任务对模型进行优化,通过少量的标注数据调整模型参数,使模型适应具体的应用场景,提升在特定任务上的性能。蒸馏是将大型模型(通常是经过预训练和可能微调的模型)的知识迁移到小型模型中,实现模型的压缩和在资源受限环境下的高效部署。
可以说,预训练是大模型能力的基石,微调是将大模型适配到具体任务的关键步骤,而蒸馏则是在模型部署和资源利用方面的重要手段。它们相互关联,共同服务于大模型从开发到应用的整个流程。例如,先通过预训练得到一个具有强大通用能力的大型基础模型,然后针对特定任务进行微调,使其在该任务上表现出色,最后如果需要在资源受限的环境中部署,可以通过蒸馏将微调后的大型模型的知识迁移到小型模型中。
RAG
1) 通常使用自带Embedding模型的RAGFlow版本,RAG是Retrieval-Augmented Generation的简称,意为检索增强生成。RAG其实是一种结合信息检索和生成式人工智能的技术。通俗来说就是大模型在生成回答之前,通过信息检索从外部知识库查找与问题相关的知识,增强生成过程中的信息来源,从而提升生成回答的质量和准确性;
2)大模型具体场景的数据样本的训练,可能一本正经的回胡说八道(大模型的幻觉问题),所以在处理这类专有问题的时候效果欠佳。rag技术的正是通过信息检索手段补充缺失的这部分数据,来解决这类问题的。
3) 解释内容如下
检索(Retrieval):当用户提出问题时,系统会从外部的知识库中检索出与用户输入相关的内容;
增强(Augmentation):系统将检索到的信息与用户的输入结合,扩展模型的上下文。这让生成模型可以利用外部知识,使生成的答案更准确和丰富;
生成(Generation):生成模型基于增强后的输入生成最终的回答。它结合用户输入和检索到的信息,生成符合逻辑、准确且可读的文本内容;
4) Embedding Mode(嵌入模型)是一种将词语、句子或文档转换成数字向量的技术。它通过将高维、离散的输入数据(如文本、图像、声音等)映射到低维、连续的向量空间中,使得计算机能够更好地理解和处理这些数据。在RAG技术中,可以简单理解为,embedding 模型是对知识库文件进行解析的。文本是由自然语言组成的,这种格式不利于机器直接计算相似度。embedding 模型要做的,就是将自然语言转化为高维向量,这样就可以很方便的通过向量来计算他们之间的相似度了,然后通过向量来捕捉到单词或句子背后的语义信息。
一些模型
阿里
1) 通义万相Wan2.5-preview, 2025杭州云栖大会上,重磅推出的通义万相Wan2.5-preview,首次采用原生多模态架构,涵盖文生视频、图生视频、文生图和图像编辑四大模型,迈入电影级全感官叙事时代。
2)通义千问Qwen
OpenAI
1)GPT&ChatGPT:
LLaMA
元宇宙平台公司(Meta)发布的生成式文本大语言模型系列
Gemini
1)Gemini是一款由Google DeepMind(谷歌母公司Alphabet下设立的人工智能实验室)于2023年12月6日发布的人工智能模型,可同时识别文本、图像、音频、视频和代码五种类型信息;
2)Gemma,基于Gemini的开源模型;
Claude
由美国人工智能公司Anthropic开发的大型语言模型家族,
一些术语
1)AIGC: Artificial Intelligence Generated Content,人工智能生成内容,利用人工智能技术来生成各种形式的内容,包括文字、音乐、图像、视频等;
2)NLP: Natural Language Proccessing,自然语言处理;
3)LLM: Large Language Model,大模型语言,它基于深度学习,采用海量文本数据和大量算例进行训练;训练后的模型能够理解和生成人类语言文本,执行与语言文本相关的任务,包括文本生成、代码补全、文章总结、翻译和情感分析等。
4)Transformer: 在论文Attentions is All you need 中提出的一种深度学习模型,最大的优点是可以并行计算,Encoder-Decoder 架构。因此中间的 Transformer 可以分为两个部分:编码组件和解码组件;Transformer现在广泛用于训练LLM等应用;
4)Transformers库: Hugging Face的Transformers库是一个非常流行的开源库,专门用于自然语言处理(NLP)任务,支持多种预训练模型(如 BERT、GPT-2等),并且提供了简单易用的 API 和工具; 支持两种深度学习框架tensorflow和Pytorch
5)CNN和RNN: 早期流行的深度学习模型;
6)CUDA: Compute Unified Device Architecture, 是一种编程模型,它通过利用 (GPU) 的处理能力,可大幅提升计算性能。开发环境包括,nvcc C语言编译器和变成手册;CUDA 是 NVIDIA 开发的“翻译器+工具箱”。能把复杂的计算任务(比如矩阵乘法、神经网络运算)翻译成GPU能理解的指令。没有CUDA,GPU只能处理简单的图形渲染,无法参与深度学习的计算。
6)cuDNN: cuDNN 是专门为深度学习优化的“外挂包”,它基于 CUDA 开发,针对神经网络的关键操作(如卷积、池化层)做了极致优化; 如果用原始 CUDA 开发大模型,就像用菜刀切牛排——能切但效率低。cuDNN直接提供预制好的高效函数,比如把图像识别中的卷积运算速度提升2倍以上,还能减少内存占用,让大模型跑得更流畅。CUDA+cuDNN:GPU 直接调用现成的高效算法,像用计算器秒解方程
7)RAG: Retrieval-Augmented Generation,检索增强生成
8) LLaMA: Meta大模型,LLaMA是Meta(Facebook)开发的一系列开源大语言模型(如LLaMA1、LLaMA2、LLaMA3),基于Transformer架构, 原生模型格式通常是PyTorch的.pth或Hugging Face的safetensors。
9) GGUF: GPT-Generated Unified Format专为大型语言模型设计的二进制文件格式,旨在解决存储效率、加载速度、兼容性和扩展性等问题; 是一种模型存储和加载的格式,专为在消费级硬件(如CPU和低显存GPU)上高效运行大模型而设计,由llama.cpp团队开发,原始LLaMA模型(如llama-2-7b)经过量化转换为GGUF格式,可在普通电脑上高效运行,总而言之就是一种模型存储和加载格式,转换后的GGUF文件可通过llama.cpp、Ollama等工具在普通CPU或低显存GPU上运行。ollama也是基于GGUF格式的。
10)Safetensors: 一种专门为机器学习设计的张量存储文件格式,用于安全地存储张量的新格式,支持PyTorch、TensorFlow、MindSpore等多个主流框架的模型互通。
11)MCP(Model Context Protocol) 模型上下文协议,旨在实现大模型语言与外部数据源和工具的集成,用来在大模型和数据源之间建立安全双向的连接。MCP 是一个开放协议,它标准化了应用程序向 LLM 提供上下文的方式。
12)vllm(Very Large Language Model Serving)高性能、低延迟的大语言模型(LLM)推理和服务框架。它专为大规模生产级部署设计,尤其擅长处理超长上下文(如8k+ tokens)和高并发请求,同时显著优化显存利用率,是当前开源社区中吞吐量最高的LLM推理引擎之一。目前只能在linux化境下部署。
待续中……


















 983
983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









