







基本概念
课本概念: 程序的一个执行实例,正在执行的程序等。
内核观点: 担当分配系统资源(CPU时间,内存)的实体。
当你的代码进行编译链接后便会生成一个可执行程序,这个可执行程序本质上是一个文件,是放在磁盘上的。当我们双击这个可执行程序将其运行起来时,本质上是将这个程序加载到内存当中了,因为只有加载到内存后,CPU才能对其进行逐行的语句执行,而一旦将这个程序加载到内存后,我们就不应该将这个程序再叫做程序了,严格意义上将应该将其称之为进程。
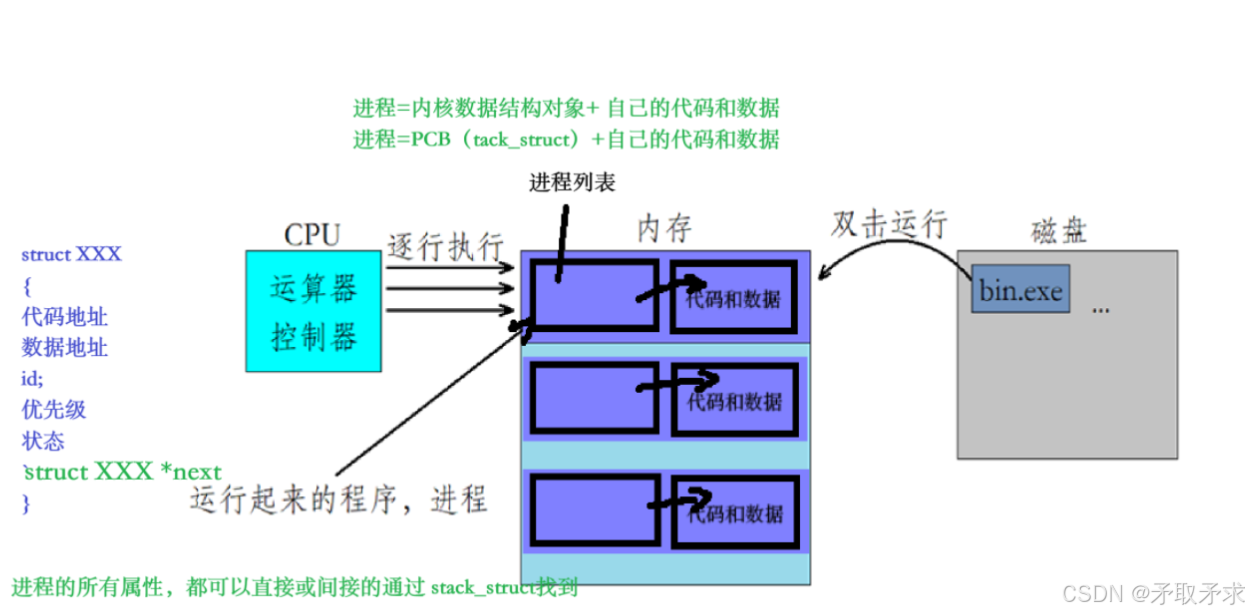 描述进程-PCB
描述进程-PCB
基本概念
- 进程信息被放在⼀个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
- 课本上称之为PCB(processcontrolblock),Linux操作系统下的PCB是:task_struct 为task_struct-PCB的⼀种
- 在Linux中描述进程的结构体叫做task_struct
- task_struct是Linux内核的⼀种数据结构(双链表),它会被装载到RAM(内存)⾥并且包含着进程的信息。
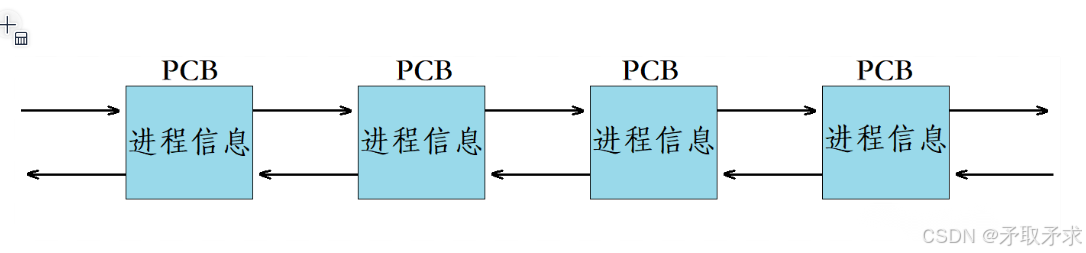
操作系统只要拿到这个双链表的头指针,便可以访问到所有的PCB。此后,操作系统对各个进程的管理就变成了对这条双链表的一系列操作。
task_struct-PCB的一种
进程控制块(PCB)是描述进程的,在C++当中我们称之为面向对象,而在C语言当中我们称之为结构体,既然Linux操作系统是用C语言进行编写的,那么Linux当中的进程控制块必定是用结构体来实现的。
PCB实际上是对进程控制块的统称,在Linux中描述进程的结构体叫做task_struct。
task_struct是Linux内核的一种数据结构,它会被装载到RAM(内存)里并且包含进程的信息。
task_struct内容分类
task_struct就是Linux当中的进程控制块,task_struct当中主要包含以下信息:
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器(pc): 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
- 上下文数据: 进程执行时处理器的寄存器中的数据。
- I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟总和,时间限制,记账号等。
- 其他信息。
组织进程
可 以在内核源代码⾥找到它。所有运⾏在系统⾥的进程都以task_struct链表的形式存在内核⾥。 
查看进程
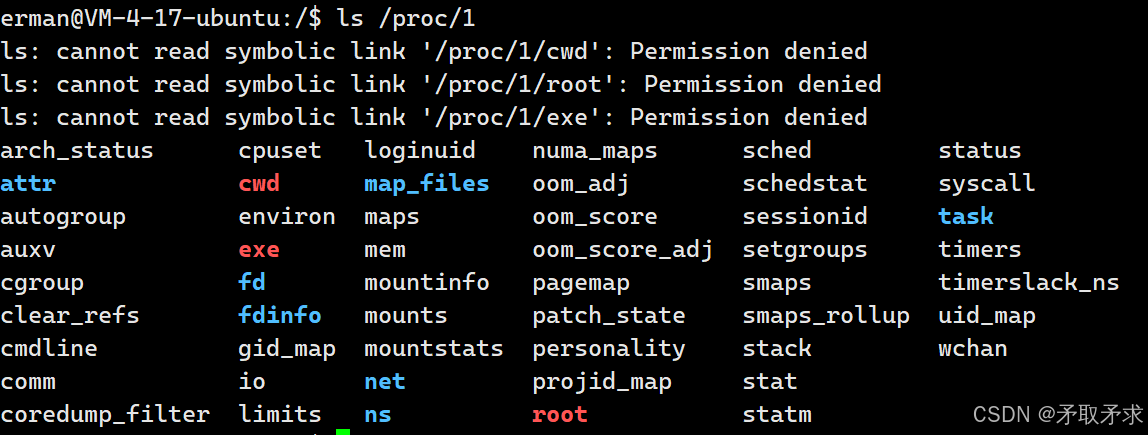
在根目录下有一个名为proc的系统文件夹。

文件夹当中包含大量进程信息,其中有些子目录的目录名为数字。

这些数字其实是某一进程的PID,对应文件夹当中记录着对应进程的各种信息。我们若想查看PID为1的进程的进程信息,则查看名字为1的文件夹即可。
通过ps命令 和grep命令
单独使用ps命令,会显示所有进程信息。
ps aux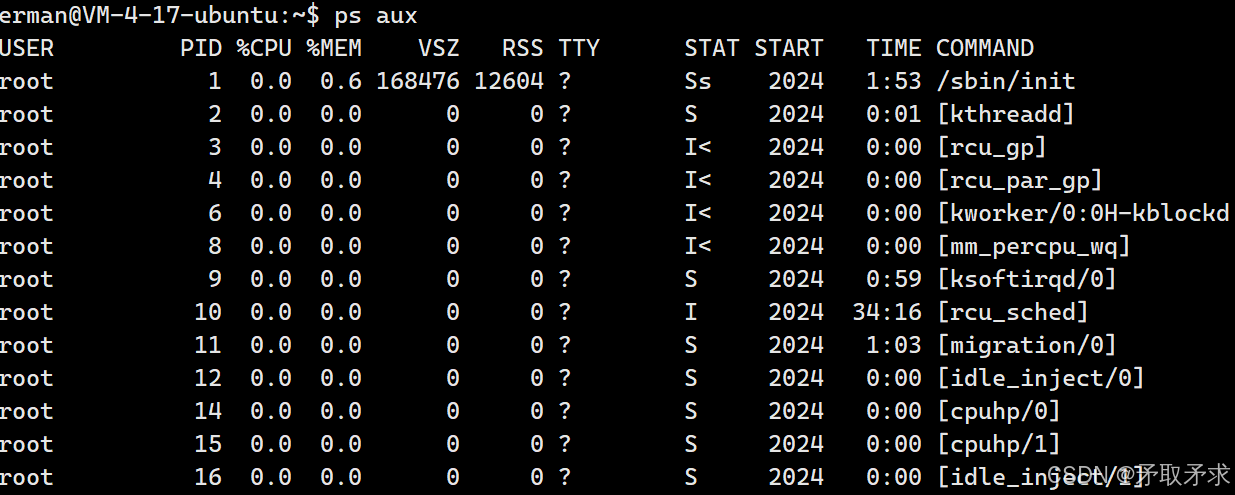
ps命令与grep命令搭配使用,即可只显示某一进程的信息。
ps指令
ps aux | head -1 && ps aux | grep proc
ps aux | head -1 ; ps aux | grep proc 知识点:这两个都可以。
|(管道符):含义:管道符的作用是将前一个命令的输出作为后一个命令的输入
head -1:含义:head 命令用于显示文件的开头部分内容,-1 表示只显示文件的第一行 。
功能:在这个命令组合中,ps aux | head -1 会打印出 ps aux 命令输出结果的第一行,也就是进程信息的表头
&&(逻辑与操作符):含义:只有当 && 前面的命令执行成功(返回状态为 0 )时,才会执行 && 后面的命令 。
grep proc:含义:grep 是 “global regular expression print” 的缩写 ,是一个文本搜索工具,用于在输入内容中查找包含指定模式(这里是通过空格分隔的关键字 )的行。proc 是要搜索的关键字。

grep -v grep:含义:-v 是 grep 命令的选项,表示反向查询,即显示不匹配指定模式的行。这里第二个 grep 是指定要排除的关键字。
ps aux | head -1 && ps aux | grep proc | grep -v grep
功能:由于前面使用了 grep proc(proc可改目标目录) 命令来筛选进程,而 grep 命令本身在执行时也是一个进程,也可能会出现在 ps aux 的输出结果里。为了只获取真正我们要找的包含 “proc” 关键字的目标进程,而不是把 grep proc 这个命令自身的进程也显示出来,就使用 grep -v grep 来过滤掉包含 “grep” 关键字的行,也就是排除 grep 命令自身的进程 。
通过系统调用获取进程的PID(进程ID)和PPID(父ID)
通过使用系统调用函数,getpid和getppid即可分别获取进程的PID(子ID)和PPID(父ID)。
我们可以通过一段代码来进行测试。
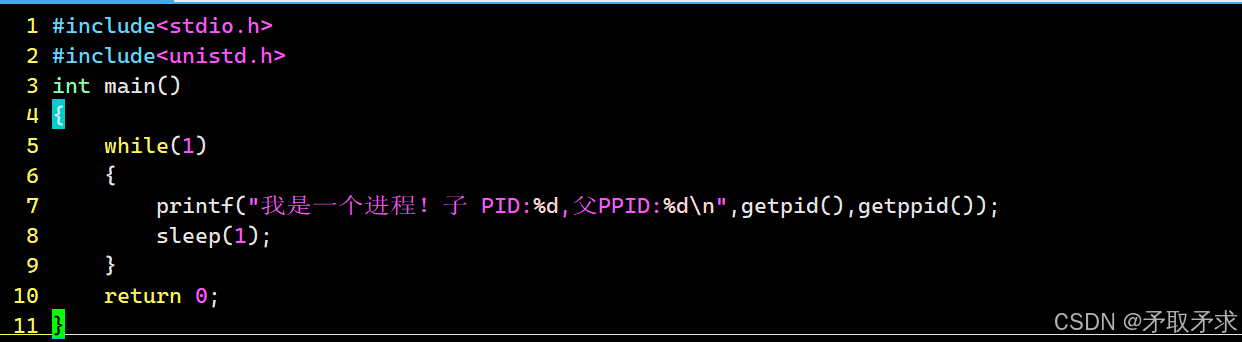
我们可以通过ps命令查看该进程的信息,即可发现通过ps命令得到的进程的PID和PPID与使用系统调用函数getpid和getppid所获取的值相同。(同账户下开两个窗口运行,左边代码,右边是查看进程)

如何关闭进程
1ctrl+c
2.kill -9 指定id

补充 cwd和exe

通过系统调用创建进程- fork初始
fork函数创建子进程
fork是一个系统调用级别的函数,其功能就是创建一个子进程。
例如,运行以下代码:

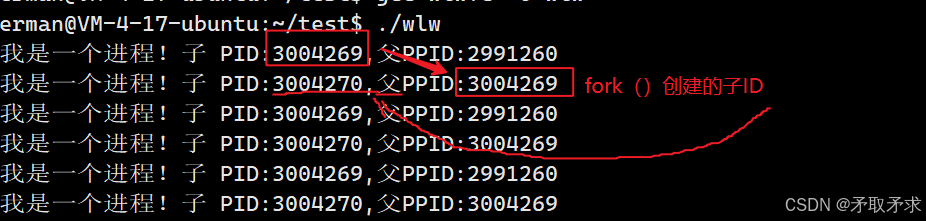 第一行是进程ID,第二行为fork()建立的,其中进程的子ID为fork()的父ID,也就是说wlw进程和fork函数建立的进程是父子关系。
第一行是进程ID,第二行为fork()建立的,其中进程的子ID为fork()的父ID,也就是说wlw进程和fork函数建立的进程是父子关系。
每出现一个进程,操作系统就会建立一个PCB ,fork函数建立的也如此,但是加载的到内存当中的代码和数据是属于父进程的,那么fork函数创建的子进程的代码和数据又从何而来呢?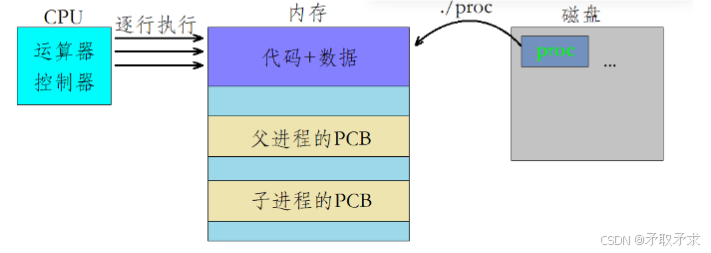
在fork函数创建子进程之间的代码是由父进程执行的,但是在fork之后的代码父子进程都可执行,值得注意的是虽然代码共享,但是父子进程各自开辟空间(写时拷贝)后面会讲
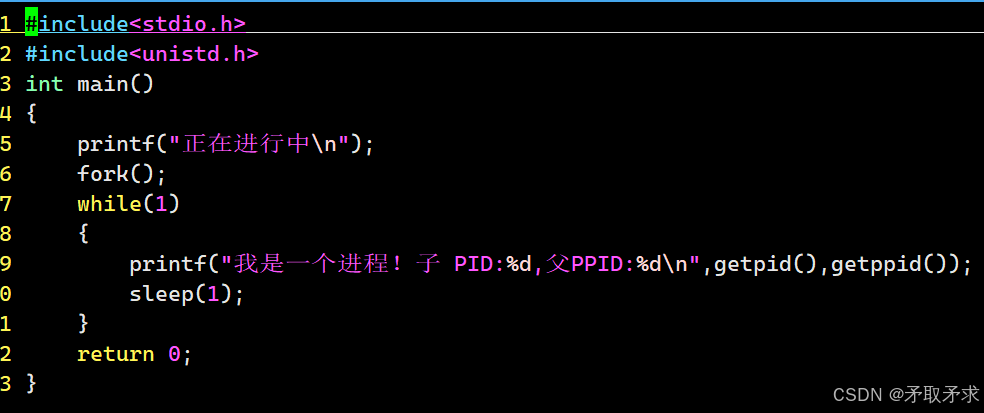
知识点:使用fork函数创建子进程后就有了两个进程,这两个进程被操作系统调度的顺序是不确定的,这取决于操作系统调度算法的具体实现。
父子进程if分流和fork返回值
fork函数创建出来的子进程与其父进程共同使用一份代码,但我们如果真的让父子进程做相同的事情,那么创建子进程就没有什么意义了。目的:让父子进程干不同事
前提我们还需要掌握fork函数的返回值是什么呢。
fork函数的返回值:
1、如果子进程创建成功,在父进程中返回子进程的PID,而在子进程中返回0。
2、如果子进程创建失败,则在父进程中返回 -1。
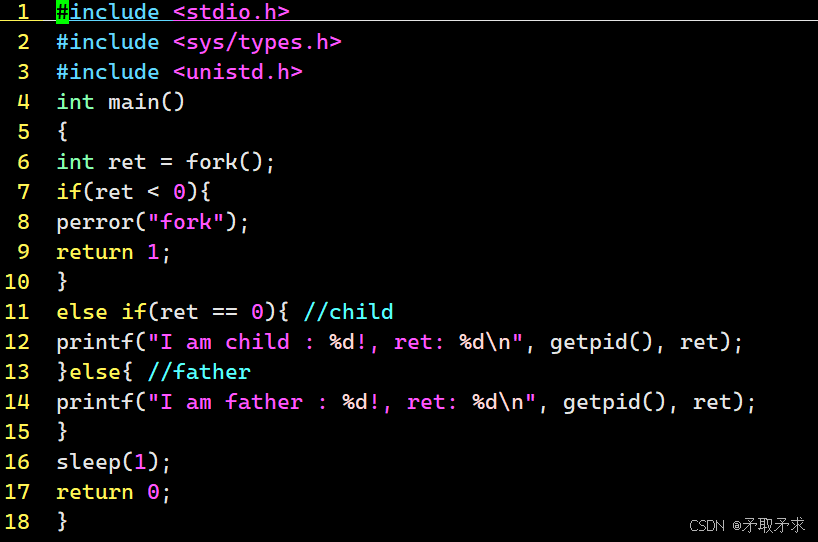

调用一次,返回两次:在父进程中调用 fork 函数后,系统会创建一个子进程。fork 函数会在父进程和子进程中各返回一次 。在父进程中,它返回新创建子进程的进程 ID(大于 0 的整数);在子进程中,它返回 0 。若 fork 函数创建子进程失败,则在父进程中返回 -1 。
linux进程状态
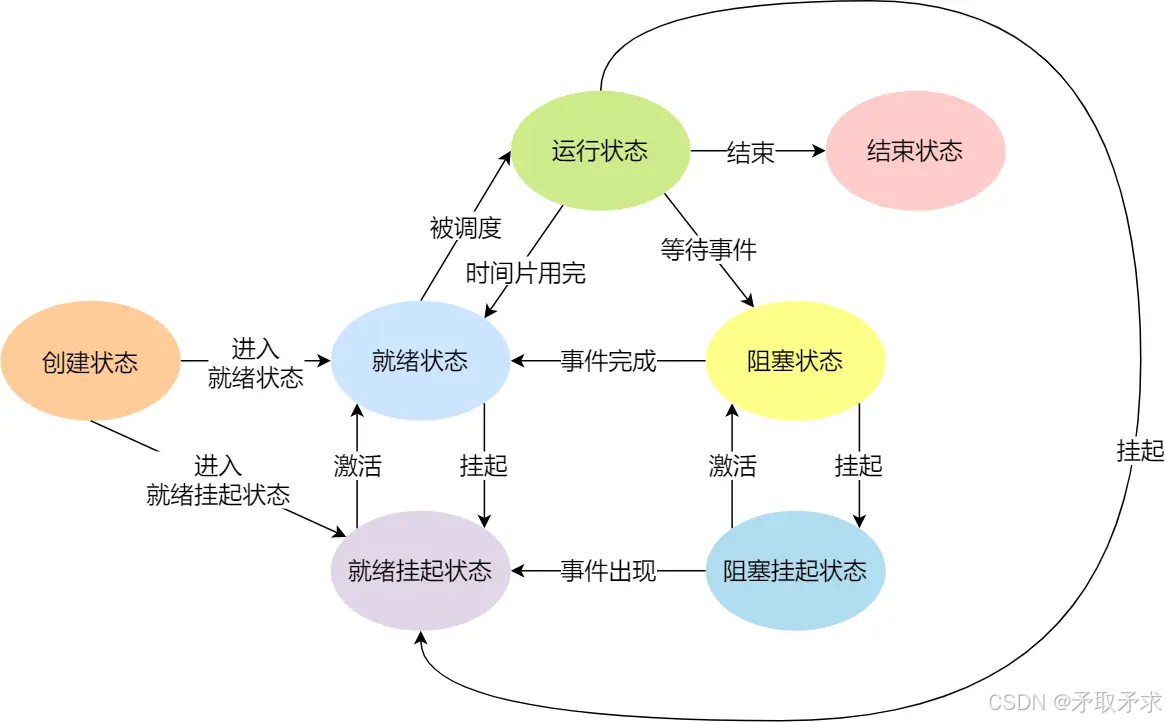
1运行&&阻塞&&挂起
运行:进程在调度队列中保持运行;
阻塞:等待某种设备或资源就绪;
挂起:
1,阻塞挂起:主要因进程处于阻塞态且系统内存资源不足,将运行队列末端的PCB带有的代码和数据放在磁盘
2,运行挂起:保证高优先级进程运行,若系统判断某个运行进程可暂时停止以优化整体性能,也会将其挂起
2状态
为了弄明⽩正在运⾏的进程是什么意思,我们需要知道进程的不同状态。⼀个进程可以有⼏个状
态(在Linux内核⾥,进程有时候也叫做任务)。
在Linux操作系统当中我们可以通过 ps aux 或 ps axj 命令查看进程的状态。
ps aux 或 ps axj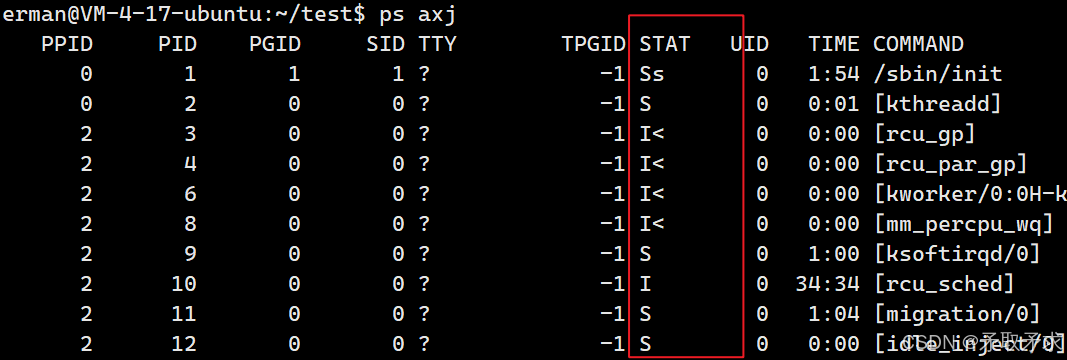
R运⾏状态(running):并不意味着进程⼀定在运⾏中,它表明进程要么是在运⾏中要么在运⾏
队列⾥。
所有处于运行状态,即可被调度的进程,都被放到运行队列当中,当操作系统需要切换进程运行时,就直接在运行队列中选取进程运行。
S睡眠状态(sleeping):意味着进程在等待事件完成,随时可以被唤醒,也可以被杀掉。(这⾥的睡眠有时候也叫做可中断睡眠(interruptible sleep))。
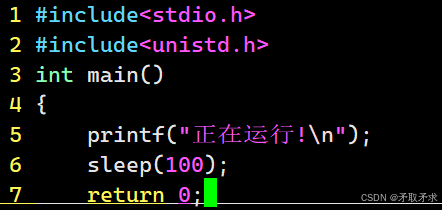
代码当中调用sleep函数进行休眠100秒,在这期间我们若是查看该进程的状态,则会看到该进程处于浅度睡眠状态。
erman@VM-4-17-ubuntu:~/test$ ps aux|head -1;ps aux|grep wlwwlw|grep -v grep

也可以删除
kill -9 ID(对应)
D磁盘休眠状态(Disksleep)有时候也叫不可中断睡眠状态(uninterruptiblesleep),在这个
状态的进程通常会等待IO的结束。表示该进程不会被杀掉,即便是操作系统也不行,只有该进程自动唤醒才可以恢复。
例如,某一进程要求对磁盘进行写入操作,那么在磁盘进行写入期间,该进程就处于深度睡眠状态,是不会被杀掉的,因为该进程需要等待磁盘的回复(是否写入成功)以做出相应的应答。(磁盘休眠状态)
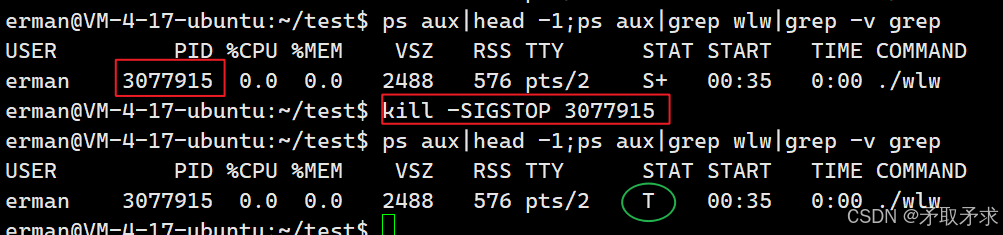
T停⽌状态(stopped):可以通过发送SIGSTOP信号给进程来停⽌(T)进程。这个被暂停的
进程可以通过发送SIGCONT信号让进程继续运⾏。

X死亡状态(dead):这个状态只是⼀个返回状态,你不会在任务列表⾥看到这个状态。
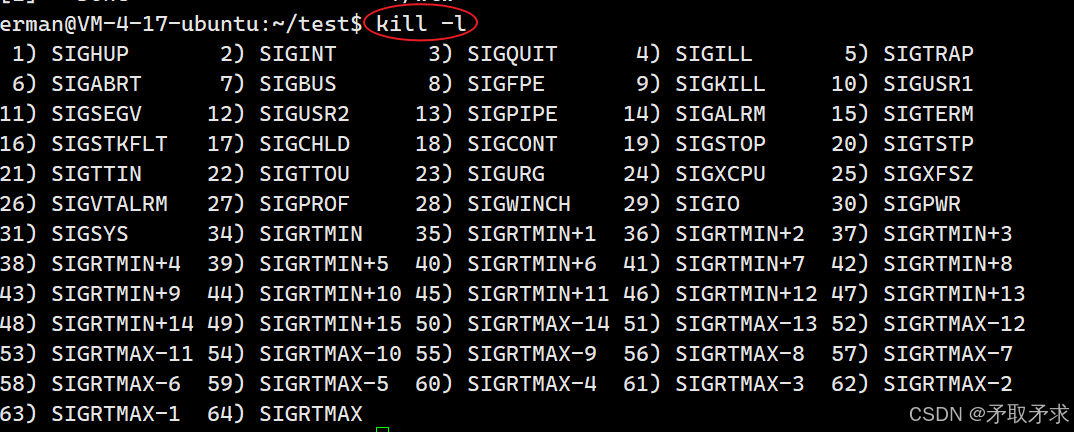
知识点:使用kill命令可以列出当前系统所支持的信号集。
僵尸状态-Z
当一个进程将要退出的时候,在系统层面,该进程曾经申请的资源并不是立即被释放,而是要暂时存储一段时间,以供操作系统或是其父进程进行读取,如果退出信息一直未被读取,则相关数据是不会被释放掉的,一个进程若是正在等待其退出信息被读取,那么我们称该进程处于僵尸状态(zombie)。
首先,僵尸状态的存在是必要的,因为进程被创建的目的就是完成某项任务,那么当任务完成的时候,调用方是应该知道任务的完成情况的,所以必须存在僵尸状态,使得调用方得知任务的完成情况,以便进行相应的后续操作。
例如,我们写代码时都在主函数最后返回0。就是为了告诉OS(操作系统),代码完成任务,

小知识:获取Linux最近一次的退出码
erman@VM-4-17-ubuntu:~/test$ echo $?
僵尸进程
前面说到,一个进程若是正在等待其退出信息被读取,那么我们称该进程处于僵尸状态。而处于僵尸状态的进程,我们就称之为僵尸进程。
例如,对于以下代码,fork函数创建的子进程在打印5次信息后会退出,而父进程会一直打印信息。也就是说,子进程退出了,父进程还在运行,但父进程没有读取子进程的退出信息(一直是S+和Z+没有改变),那么此时子进程就进入了僵尸状态。
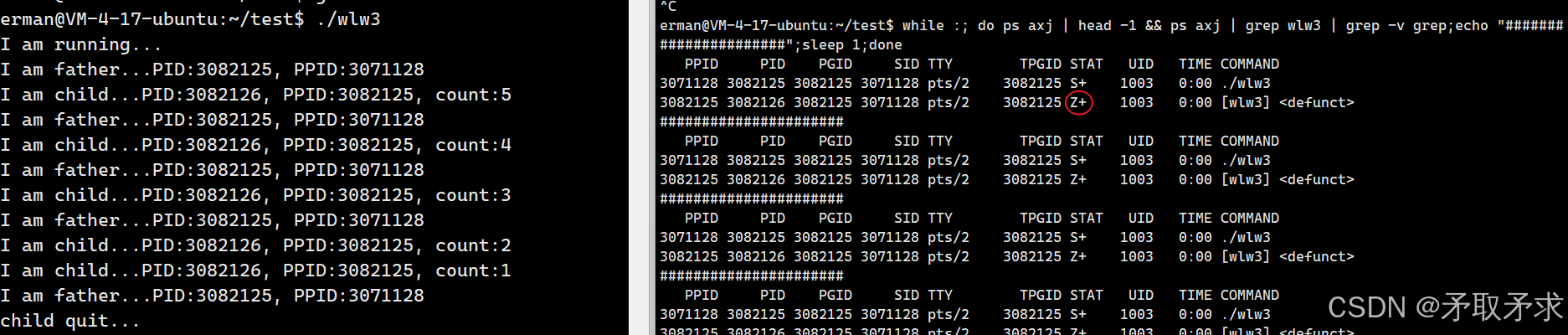 僵尸进程的危害
僵尸进程的危害
- 僵尸进程的退出状态必须一直维持下去,因为它要告诉其父进程相应的退出信息。可是父进程一直不读取,那么子进程也就一直处于僵尸状态。
- 僵尸进程的退出信息被保存在task_struct(PCB)中,僵尸状态一直不退出,那么PCB就一直需要进行维护。
- 若是一个父进程创建了很多子进程,但都不进行回收,那么就会造成资源浪费,因为数据结构对象本身就要占用内存。
- 僵尸进程申请的资源无法进行回收,那么僵尸进程越多,实际可用的资源就越少,也就是说,僵尸进程会导致内存泄漏。
孤儿进程
在Linux当中的进程关系大多数是父子关系,若子进程先退出而父进程没有对子进程的退出信息进行读取,那么我们称该进程为僵尸进程。但若是父进程先退出,那么将来子进程进入僵尸状态时就没有父进程对其进行处理,此时该子进程就称之为孤儿进程。
若是一直不处理孤儿进程的退出信息,那么孤儿进程就会一直占用资源,此时就会造成内存泄漏。因此,当出现孤儿进程的时候,孤儿进程会被1号init(可理解政府)进程领养,此后当孤儿进程进入僵尸状态时就由int进程进行处理回收。
例如,对于以下代码,fork函数创建的子进程会一直打印信息,而父进程在打印5次信息后会退出,此时该子进程就变成了孤儿进程。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
printf("I am running...\n");
pid_t id = fork();
if(id == 0){ //child
int count = 5;
while(1){
printf("I am child...PID:%d, PPID:%d\n", getpid(), getppid());
sleep(1);
}
}
else if(id > 0){ //father
int count = 5;
while(count){
printf("I am father...PID:%d, PPID:%d, count:%d\n", getpid(), getppid(), count);
sleep(1);
count--;
}
printf("father quit...\n");
exit(0);
}
else{ //fork error
}
return 0;
}



















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









