




 NSDictionary基于哈希表实现,通过哈希函数快速访问键值对。哈希冲突可能降低查找效率,可通过优化函数和使用拉链法解决。内部使用NSMapTable,结合哈希和链表,插入删除操作时间为O(1)+O(m),其中m为链表长度。键值对遍历顺序与hash函数相关。
NSDictionary基于哈希表实现,通过哈希函数快速访问键值对。哈希冲突可能降低查找效率,可通过优化函数和使用拉链法解决。内部使用NSMapTable,结合哈希和链表,插入删除操作时间为O(1)+O(m),其中m为链表长度。键值对遍历顺序与hash函数相关。
NSDictionary介绍
NSDictionary(字典)是使用 hash表来实现key和value之间的映射和存储的, hash函数设计的好坏影响着数据的查找访问效率。数据在hash表中分布的越均匀,其访问效率越高。而在Objective-C中,通常都是利用NSString 来作为键值,其内部使用的hash函数也是通过使用 NSString对象作为键值来保证数据的各个节点在hash表中均匀分布。
实现原理
NSDictionary(字典)是使用哈希表 Hash table(也叫散列表)来实现的。哈希表是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键(key)值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做哈希表。也就是说哈希表的本质是一个数组,数组中每一个元素其实就是NSDictionary键值对。
若关键字为k,则其值存放在f(k)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为哈希函数。
哈希冲突:如果关键字k不同,但是通过哈希函数f(k)得到的结果是一样的,这样就会出现哈希冲突,也就是说,得到的这个地址有可能已经存在键值对了。
解决冲突:可以通过优化哈希函数来减少冲突的几率,如果冲突已经发生,可以通过开放寻址法或者拉链法解决冲突。
拉链法解决冲突:大概原理就是将同一个存储位置的所有元素保存在一个链表中。
哈希表的查找效率
影响哈希表的查找效率主要问题是冲突问题,如果冲突较多,查找效率就会低。
冲突原因主要是以下三个
哈希函数是否均匀;
哈希冲突处理的方法;
哈希表的负载因子 。
哈希表的负载因子 = 填入表中的元素个数 / 哈希表的长度
也就是说,哈希表越满,负载因子越大。
Example:
问:当用一个不存在的key来查找两个不同长度的字典,那么哪个效率会高?
答:表面上看可能是一样快,因为字典底层都用了哈希表,查找的时间复杂度为 O(1),(最差的时候是O(n))都是一样的,但是可能会由于两个哈希表的负载因子不同,倒是查找的时间也是不同的。
NSDictionary内部结构
NSDictionary使用NSMapTable实现,NSMapTable同样是一个key-value的容器。
typedef struct {
NSMapTable *table;
NSInteger i;
struct _NSMapNode *j;
} NSMapEnumerator;
上述结构体描述了遍历一个NSMapTable时的一个指针对象,其中包含table对象自身的指针,计数值,和节点指针。
typedef struct {
NSUInteger (*hash)(NSMapTable *table,const void *);
BOOL (*isEqual)(NSMapTable *table,const void *,const void *);
void (*retain)(NSMapTable *table,const void *);
void (*release)(NSMapTable *table,void *);
NSString *(*describe)(NSMapTable *table,const void *);
const void *notAKeyMarker;
} NSMapTableKeyCallBacks;
上述结构体中存放的是几个函数指针,用于计算key的hash值,判断key是否相等,retain,release操作。
typedef struct {
void (*retain)(NSMapTable *table,const void *);
void (*release)(NSMapTable *table,void *);
NSString *(*describe)(NSMapTable *table, const void *);
} NSMapTableValueCallBacks;
上述存放的三个函数指针,定义在对NSMapTable插入一对key-value时,对value对象的操作。
@interface NSMapTable : NSObject {
NSMapTableKeyCallBacks *keyCallBacks;
NSMapTableValueCallBacks *valueCallBacks;
NSUInteger count;
NSUInteger nBuckets;
struct _NSMapNode **buckets;
}
可以看出来NSMapTable是一个哈希+链表的数据结构,因此在NSMapTable中插入或者删除一对对象时,
寻找的时间是O(1)+O(m),m最坏时可能为n。
- O(1):为对key进行hash得到bucket的位置
- O(m):遍历该bucket后面冲突的value,通过链表连接起来。
因此NSDictionary中的Key-Value遍历时是无序的,至如按照什么样的顺序,跟hash函数相关。NSMapTable使用NSObject的哈希函数。
- (NSUInteger)hash {
return (NSUInteger)self>>4;
}
上述是NSObject的哈希值的计算方式,简单通过移位实现。右移4位,左边补0。因为对象大多存于堆中,地址相差4位应该很正常。
注意
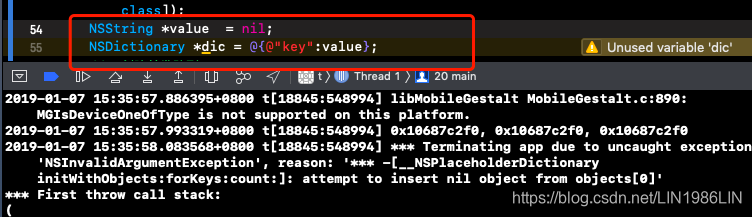
(1) setValue: ForKey:的value是可以为nil的(但是当value为nil且key存在的时候,会自动调用removeObject:forKey方法);
setObject: ForKey:的value则不可以为nil。
(2) setValue: ForKey:的key必须是不为nil的字符串类型;
setObject: ForKey:的key可以是不为nil的所有继承NSCopying的类型。
NSDictionary初始化时候Value不能为nil

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









