






集合体系概述
可以分为单列集合和双列集合
Collection代表单例集合,每个元素只包含一个值
Map代表双列集合,每个元素包含两个值(键值对)
Collection集合体系
基本框架
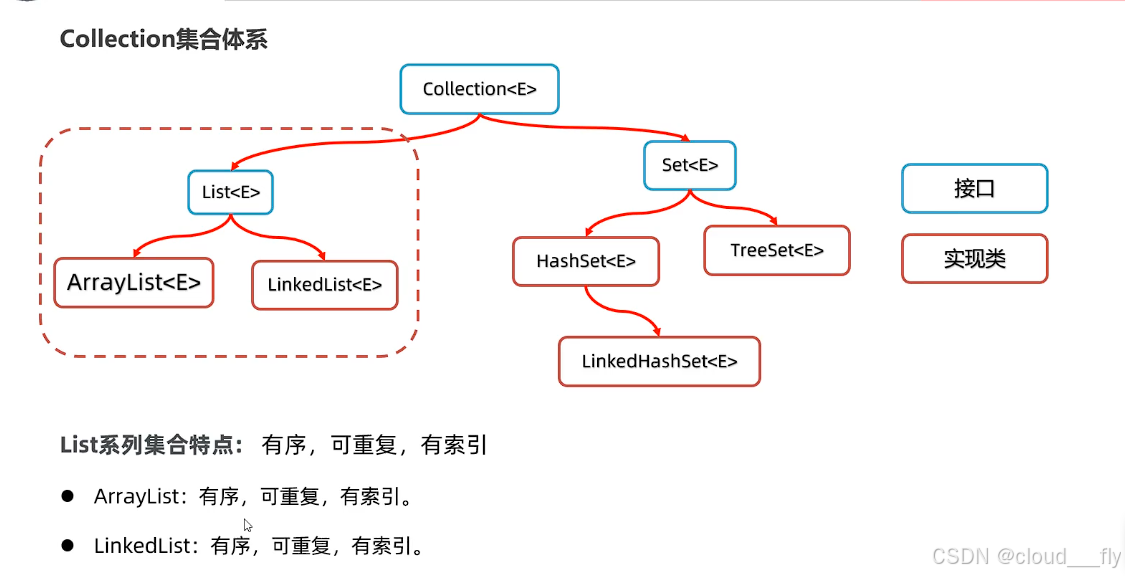
Collection集合
常用方法
add、clear、remove、addAll、isEmpty、size、contains
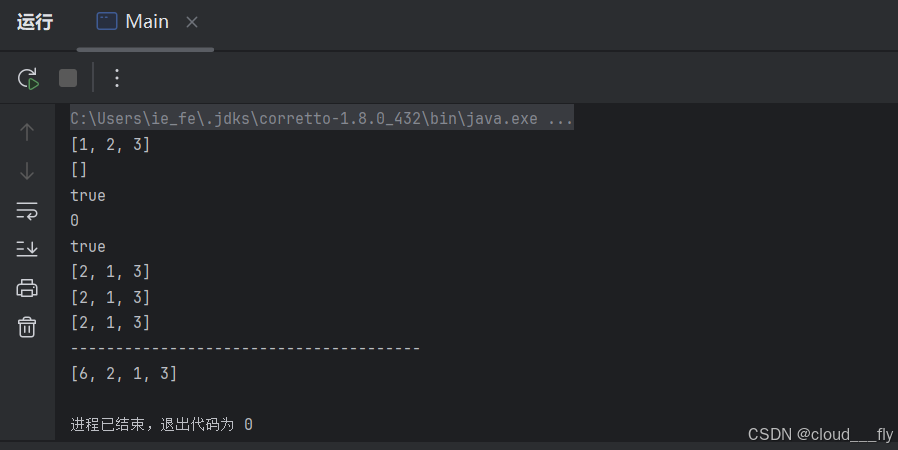
package org.example;
import java.util.*;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.ReentrantLock;
public class Main {
public static void main(String[] args) {
Collection<String> c = new ArrayList<>();
c.add("1");
c.add("2");
c.add("3");
System.out.println(c);
c.clear();
System.out.println(c);
System.out.println(c.isEmpty());
System.out.println(c.size());
c.add("1");
c.add("2");
c.add("1");
c.add("3");
System.out.println(c.contains("1"));
c.remove("1");
System.out.println(c);
Object[] arr = c.toArray();
System.out.println(Arrays.toString(arr));
Object[] arr2 = c.toArray(new String[c.size()]);
System.out.println(Arrays.toString(arr2));
System.out.println("---------------------------------------");
Collection<String> c2 = new ArrayList<>();
c2.add("6");
c2.addAll(c);
System.out.println(c2);
}
}
补充一点,关于打印:
public void println(Object x) {
String s = String.valueOf(x);
synchronized (this) {
print(s);
newLine();
}
}
遍历方式
1. 迭代器
迭代器是用来专门遍历集合的(数组没有迭代器),在Java中迭代器的代表是Iterator
public interface Iterator<E> {
// 询问当前位置是否有元素存在,存在返回true,否则返回false
boolean hasNext();
// 获取当前位置的元素,并同时将迭代器对象指向下一个元素处
E next();
/*
next不是下一个,是表示当前位置的元素
*/
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
// 返回集合中的迭代器对象,该迭代器对象默认指向集合中的第一个元素
Iterator<E> iterator();演示:
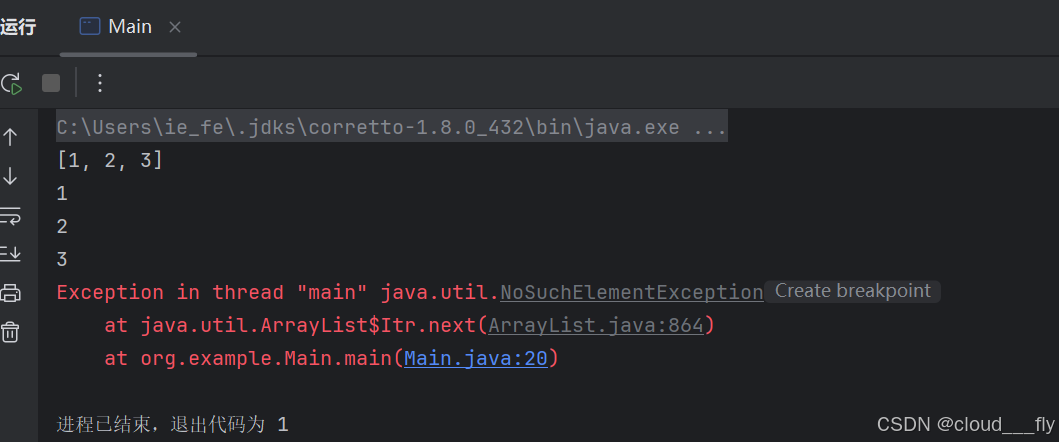
package org.example;
import java.util.*;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.ReentrantLock;
public class Main {
public static void main(String[] args) {
Collection<String> c = new ArrayList<>();
c.add("1");
c.add("2");
c.add("3");
System.out.println(c);
Iterator<String> it = c.iterator();
System.out.println(it.next());
System.out.println(it.next());
System.out.println(it.next());
System.out.println(it.next());
}
}
结合循环:
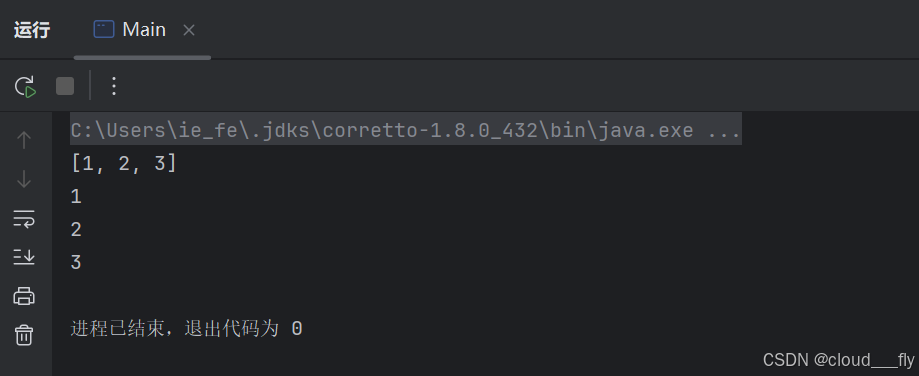
package org.example;
import java.util.*;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.ReentrantLock;
public class Main {
public static void main(String[] args) {
Collection<String> c = new ArrayList<>();
c.add("1");
c.add("2");
c.add("3");
System.out.println(c);
Iterator<String> it = c.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
2. 增强for

package org.example;
import java.util.*;
public class Main {
public static void main(String[] args) {
Collection<String> c = new ArrayList<>();
c.add("1");
c.add("2");
c.add("3");
System.out.println(c);
for (String str: c) {
System.out.println(str);
}
}
}3. lambda表达式
原始写法:
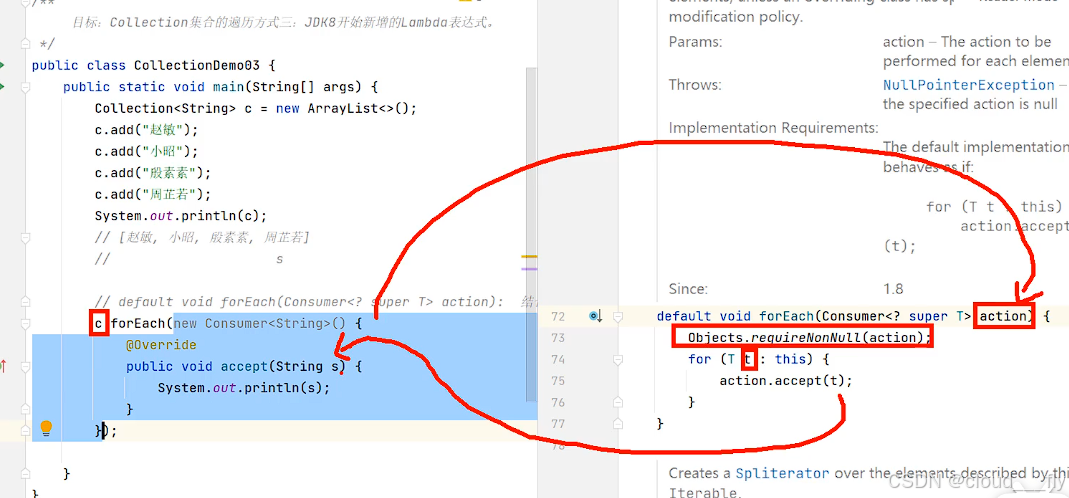
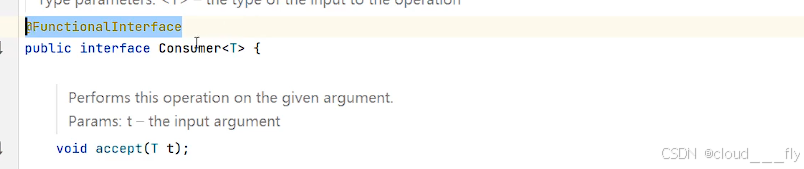
函数式注解标记,因此它的匿名类部类可以用lamada表达式简化:
演示,不断简化:
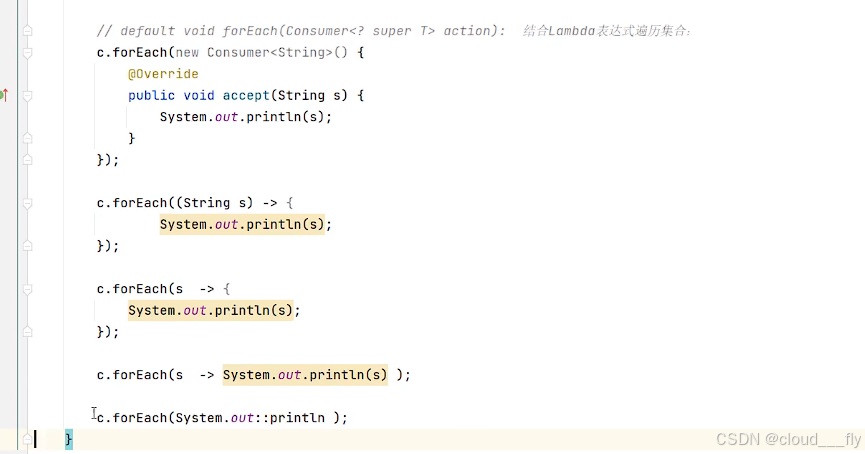
最后一个是方法引用
List集合
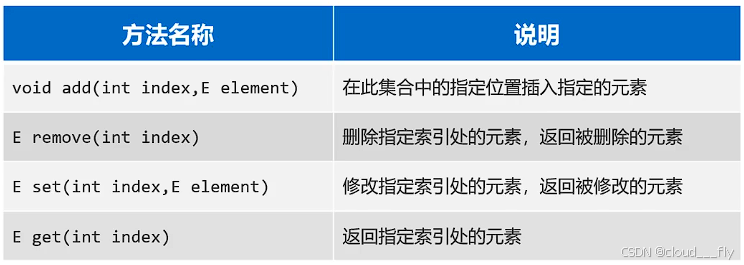
特点、特有方法
因为支持索引,所以多了很多与索引相关的方法
package org.example;
import java.util.*;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("1");
list.add("2");
list.add("3");
System.out.println(list);
list.add(2, "33"); //在插入后为2的位置插入33
System.out.println(list);
System.out.println(list.remove(2));
System.out.println(list);
System.out.println(list.get(2));
System.out.println(list.set(2, "4")); //修改索引数据,并且返回原来的数据
}
}遍历方式
1. for循环(因为list集合有索引)
package org.example;
import java.util.*;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("1");
list.add("2");
list.add("3");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
}2. 迭代器
3. 增强for循环
4. lamada表达式

ArrayyList的底层原理
ArrayList和LinkedList底层采用的数据结构不同
先说ArrayList
基于数组实现:
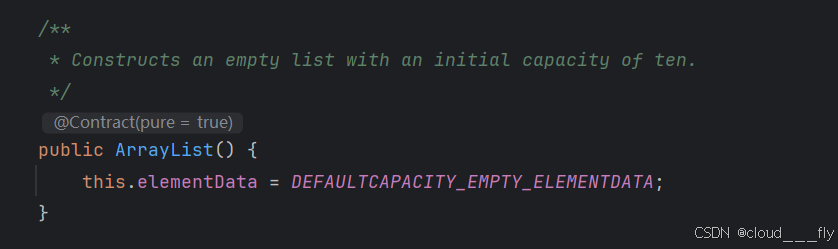
(1)利用无参构造器,初始化创建一个默认长度为0的数组。
(2)添加第一个元素时,底层会创建一个新的长度为10的数组
(3)扩容时会扩容1.5倍,比如添加第11个元素时,数组大小将变成15。会重新生成一个数组,将原来的数组元素逐个迁移过来再新增元素
(4)如果一次添加多个元素,1.5倍还放不下,则新建数组长度以实际为准
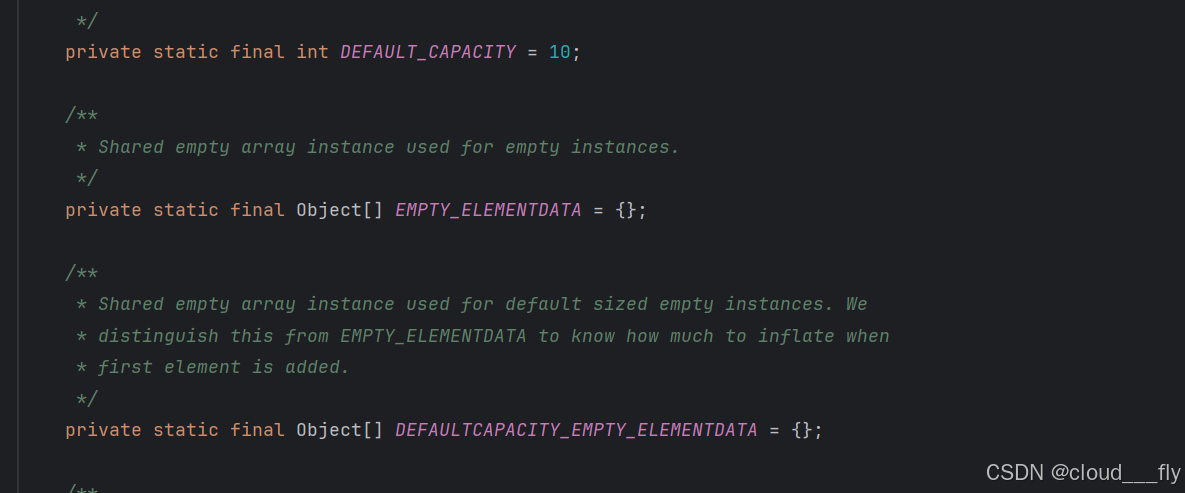
部分源码:
特点:查询快,增删慢
LinkedList的底层原理
底层基于双链表实现
特点:
1. 查询慢(因为链表节点在内存中不连续,所以不能通过索引来查询)
2. 增删查找快
常用方法:
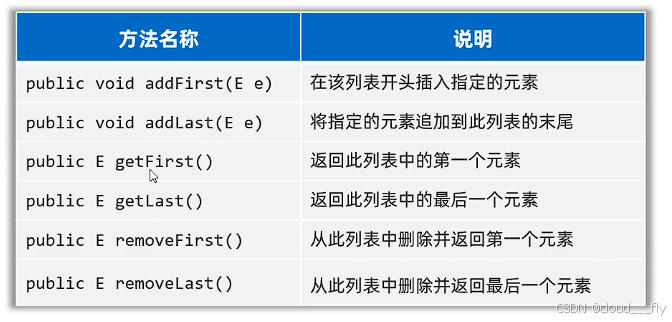
LinkedList可以用来作为队列和栈
Set集合
特点、特有方法

package org.example;
import java.util.*;
public class Main {
public static void main(String[] args) {
// Set<Integer> set = new HashSet<>();
// set.add(666);
// set.add(666);
// set.add(444);
// set.add(555);
// set.add(333);
// System.out.println(set); // [666, 555, 444, 333]
// Set<Integer> set = new LinkedHashSet<>();
// set.add(666);
// set.add(666);
// set.add(444);
// set.add(555);
// set.add(333);
// System.out.println(set); // [666, 444, 555, 333]
// Set<Integer> set = new TreeSet<>();
// set.add(666);
// set.add(666);
// set.add(444);
// set.add(555);
// set.add(333);
// System.out.println(set); // [333, 444, 555, 666]
}
}HashSet的底层原理
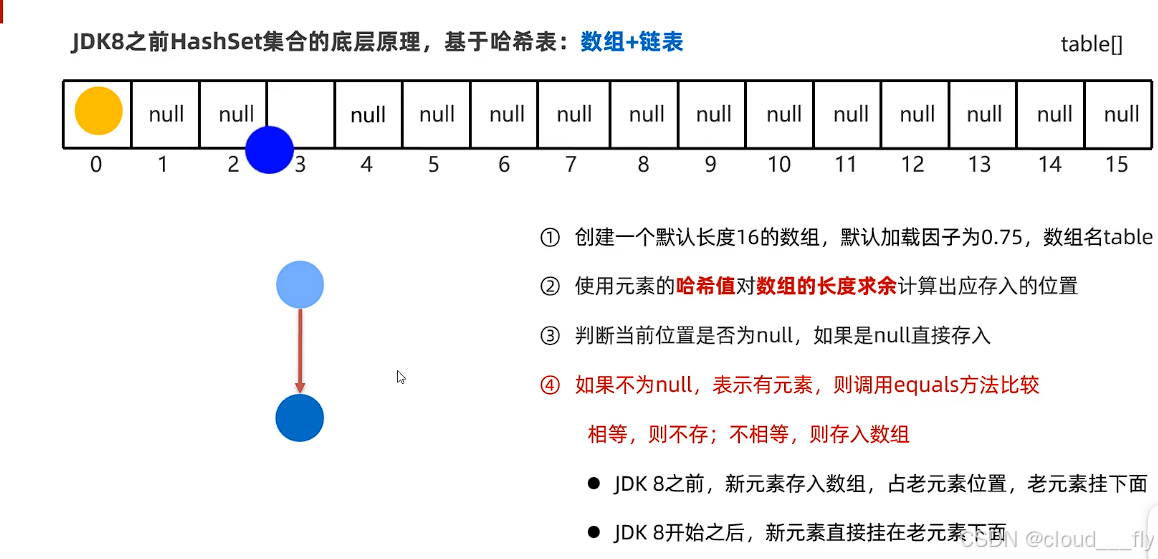
JDK8之前,基于哈希表:数组 + 链表:
1. 初始时创建一个默认长度为16的数组,默认加载因子是0.75,数组名为table
2. 使用数组元素的哈希值对数组的长度求余取mod,计算出应存入的位置
3. 判断当前位置是否是null,如果是null直接存入
4. 如果不为null,表示有元素,则调用equals方法进行比较。如果相等则不存入,如果不相等则存入。 因此添加的元素不重复。
jdk8之前,新元素存入数组,老元素挂下面
jdk8开始之后,新元素直接挂在老元素下面
基于这种算法,添加的元素无序也无索引
哈希表的增删改查性能都很好
如果数组快占满了,会有什么问题,如何解决?
链表会过长,导致查询性能降低,因此需要扩容
扩容:
由默认加载因子得,16 * 0.75 = 12
数组元素被占用了12个,开始扩容,会将数组容量变成原来的2倍,再重新根据哈希算法将元素放入数组中。
但是还是会出现,某个位置的链表过长,因此JDK8开始之后,进行了优化
JDK8开始之后,基于哈希表:数组 + 链表 + 红黑树:

HashSet去重的机制
首先需要明确的是,HashSet不能对两个内容一样的对象去重
如何让HashSet集合实现对内容一样的对象去重?
根据上面的算法,应该重写HashSet存入对象的hashCode和equals方法
package org.example;
import java.util.Objects;
public class Demo {
int a, b, c;
public Demo (int a, int b, int c) {
this.a = a;
this.b = b;
this.c = c;
}
@Override
public boolean equals(Object o) {
if (o == null || getClass() != o.getClass()) return false;
Demo demo = (Demo) o;
return a == demo.a && b == demo.b && c == demo.c;
}
@Override
public int hashCode() {
return Objects.hash(a, b, c);
}
@Override
public String toString() {
return "Demo{" +
"a=" + a +
", b=" + b +
", c=" + c +
'}';
}
}
package org.example;
import java.util.*;
public class Main {
public static void main(String[] args) {
Set<Demo> set = new HashSet<>();
Demo demo1 = new Demo(1, 2, 3);
Demo demo2 = new Demo(1, 2, 3);
set.add(demo1);
set.add(demo2);
System.out.println(demo1.hashCode());
System.out.println(demo2.hashCode());
set.forEach((Demo demo) -> {
System.out.println(demo.toString());
});
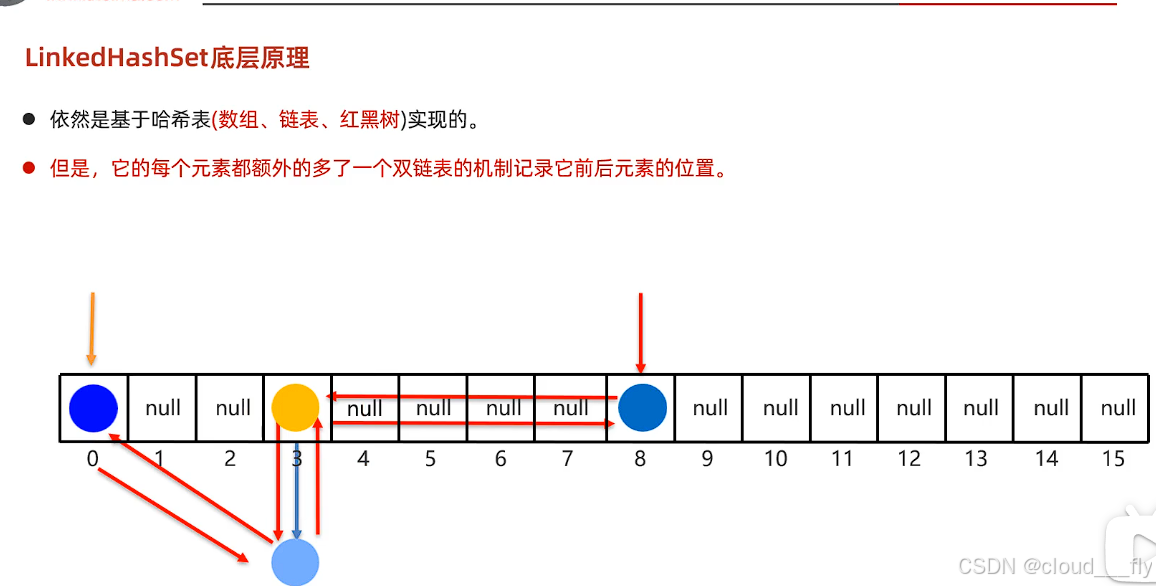
}LinkedHashSet的底层原理
依然是基于哈希表(数组+链表+红黑树)
但是它的每个元素都多了一个双链表机制来记录它前后元素的位置
TreeSet的底层原理
最重要的特点是可排序,基于红黑树实现
但是对于自定义的类需要自己定义排序规则:
1. 让自定义的类实现Comparable接口,重新compareTo方法来指定比较规则
package org.example;
import java.util.Objects;
public class Demo implements Comparable<Demo>{
int a, b, c;
public Demo (int a, int b, int c) {
this.a = a;
this.b = b;
this.c = c;
}
@Override
public boolean equals(Object o) {
if (o == null || getClass() != o.getClass()) return false;
Demo demo = (Demo) o;
return a == demo.a && b == demo.b && c == demo.c;
}
@Override
public int hashCode() {
return Objects.hash(a, b, c);
}
@Override
public String toString() {
return "Demo{" +
"a=" + a +
", b=" + b +
", c=" + c +
'}';
}
@Override
public int compareTo(Demo o) {
if (a != o.a) return a - o.a;
if (b != o.b) return b - o.b;
if (c != o.c) return c - o.c;
return 0;
}
}
package org.example;
import java.util.*;
public class Main {
public static void main(String[] args) {
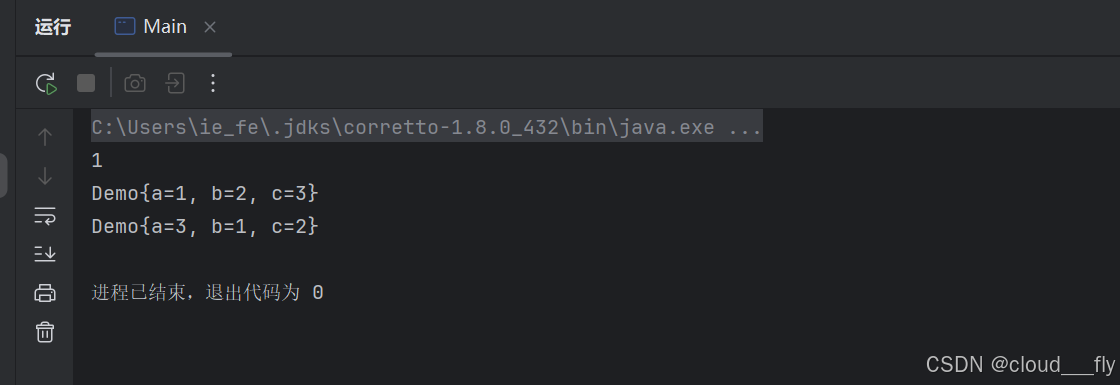
Set<Demo> set = new TreeSet<>();
Demo demo1 = new Demo(1, 2, 3);
Demo demo2 = new Demo(3, 1, 2);
set.add(demo1);
set.add(demo2);
set.forEach(System.out::println);
}
}2. 调用TreeSet集合有参构造器对象,可以设置Comparator对象(比较器对象,用于指定比较规则)
package org.example;
import java.util.*;
public class Main {
public static void main(String[] args) {
//TreeSet会就近选择自带的比较器对象进行排序, 可以被替换为lambda
Set<Demo> set = new TreeSet<>(new Comparator<Demo>() {
@Override
public int compare(Demo o1, Demo o2) {
if (o1.a != o2.a) return o1.a - o2.a;
if (o1.b != o2.b) return o1.b - o2.b;
if (o1.c != o2.c) return o1.c - o2.c;
System.out.println(1); //会打印1
return 0;
}
});
Demo demo1 = new Demo(1, 2, 3);
Demo demo2 = new Demo(3, 1, 2);
set.add(demo1);
set.add(demo2);
set.forEach(System.out::println);
}
}
Collection各种集合的应用场景

集合的并发修改问题
package org.example;
import java.util.*;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.clear();
list.add("李白");
list.add("李信");
list.add("王五");
/*
抛出异常,因为java底层做了一些并发安全检查
*/
// Iterator<String> it = list.iterator();
// while (it.hasNext()) {
// String name = it.next();
// if (name.contains("李")) list.remove(name);
// }
/*
使用for循环并没有抛出异常,因为java并没有设计这点, 但是由于删除后会整理数组,会出现bug
*/
list.clear();
list.add("李白");
list.add("李信");
list.add("王五");
for (int i = 0; i < list.size(); i++) {
String name = list.get(i);
if (name.contains("李")) list.remove(name);
}
list.forEach(System.out::println);
/*
李信
王五
*/
System.out.println("----------------i--解决-----------------------");
list.clear();
list.add("李白");
list.add("李信");
list.add("王五");
for (int i = 0; i < list.size(); i++) {
String name = list.get(i);
if (name.contains("李")) {
list.remove(name);
i--;
}
}
list.forEach(System.out::println); // 打印王五
System.out.println("----------------倒着删除解决--------------------");
// 以及可以倒着去删除
list.clear();
list.add("李白");
list.add("李信");
list.add("王五");
for (int i = list.size() - 1; i >= 0; i--) {
String name = list.get(i);
if (name.contains("李")) {
list.remove(name);
}
}
list.forEach(System.out::println); // 打印王五
System.out.println("-----------------迭代器解决---------------------");
list.clear();
list.add("李白");
list.add("李信");
list.add("王五");
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String name = it.next();
if (name.contains("李")) {
// list.remove(name);
it.remove(); //删除当前迭代器遍历到的对象,每删除一个数据,相当于在底层做i--的操作
}
}
list.forEach(System.out::println);
}
}需要注意的是,使用增强for循环和lambda表达式删除元素也会出现并发异常,并且也解决不了
1. 增强for循环本质是迭代器遍历集合的简单写法,并且拿不到迭代器也无法解决
2. lambda表达式底层也使用了增强for循环,同理也无法解决并发异常问题.
lambda表达式底层源码:
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) { //增强for循环
action.accept(t);
}
}可变参数

package org.example;
import java.util.*;
public class Main {
public static void main(String[] args) {
test(1);
test(1, 2, 3);
test(new int[]{4, 5, 6, 7});
}
// 注意,只能有一个可变参数。
// 并且可变参数只能放在所有参数的最后面
public static void test(int... nums) {
//可变参数本质是一个数组
System.out.println(nums.length);
System.out.println(Arrays.toString(nums));
System.out.println("---------------------------");
}
}Collections工具类

为什么shuffle和sort只支持对List集合?
因为Set集合要求无序或者TreeSet自己实现了排序
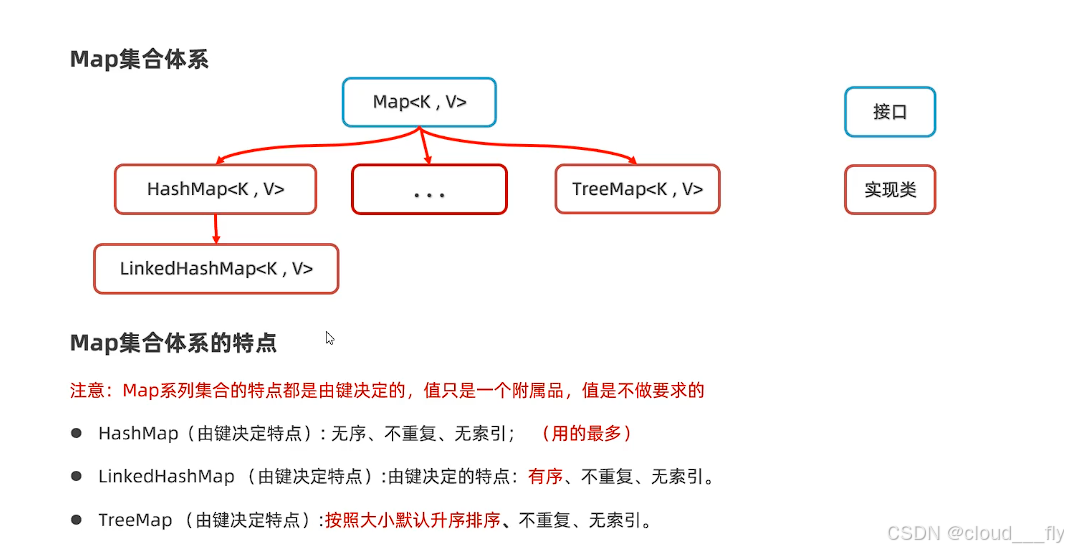
Map集合体系
基本框架
Map集合
常用方法

package org.example;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
/*
1. map集合赋值:put方法
*/
map.put("1", 10);
map.put("2", 20);
map.put("1", 100);
map.put(null, null);
System.out.println(map);
System.out.println("----------------------------");
/*
2. 获取map集合大小
*/
System.out.println(map.size());
System.out.println("----------------------------");
/*
3. 清空map集合
*/
map.clear();
System.out.println(map.size());
System.out.println("----------------------------");
/*
4. isEmpty判断是否为空
*/
System.out.println(map.isEmpty());
System.out.println("----------------------------");
/*
5. public V get(Object key) 根据key获取对应的value
*/
map.put("1", 10);
map.put("2", 20);
map.put("1", 100);
map.put(null, null);
System.out.println(map.get("1"));
System.out.println("----------------------------");
/*
6. public V remove(Object key) 根据key删除元素(返回删除前的value)
*/
System.out.println(map.remove("1"));
System.out.println(map);
System.out.println("----------------------------");
/*
7. public boolean containsKey(Object key) 判断是否有某个键
*/
System.out.println(map.containsKey("1"));
System.out.println("----------------------------");
/*
8. public boolean containsValue(Object value) 判断是否有某个值
*/
System.out.println(map.containsValue(20));
System.out.println("----------------------------");
/*
9. public Set<K> keySet() 获取map集合的全部键
*/
Set<String> set = map.keySet();
System.out.println(set);
/*
10. public Collection<V> values() 获取map集合的全部键
*/
Collection<Integer> values = map.values();
System.out.println(values);
/*
11. putAll: 把其他集合放入到自己的集合
*/
Map<String, Integer> map2 = new HashMap<>();
map2.putAll(map);
System.out.println(map2);
}
}遍历方式

package org.example;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import java.util.function.BiConsumer;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("1", 10);
map.put("2", 20);
map.put("3", 30);
map.put("4", 40);
/*
1. 键找值
*/
Set<String> set = map.keySet();
for (String key: set) {
System.out.println(key + " -> " + map.get(key));
}
System.out.println("------------------------------");
/*
2. 键值对
*/
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry: entries) {
System.out.println(entry.getKey() + " -> " + entry.getValue());
}
System.out.println("------------------------------");
/*
3. lambda表达式
*/
map.forEach((k, v)-> {
System.out.println(k + " -> " + v);
});
System.out.println("------------------------------");
// 原始写法
map.forEach(new BiConsumer<String, Integer>() {
@Override
public void accept(String k, Integer v) {
System.out.println(k + " -> " + v);
}
});
System.out.println("------------------------------");
}
}lambda表达式底层源码:
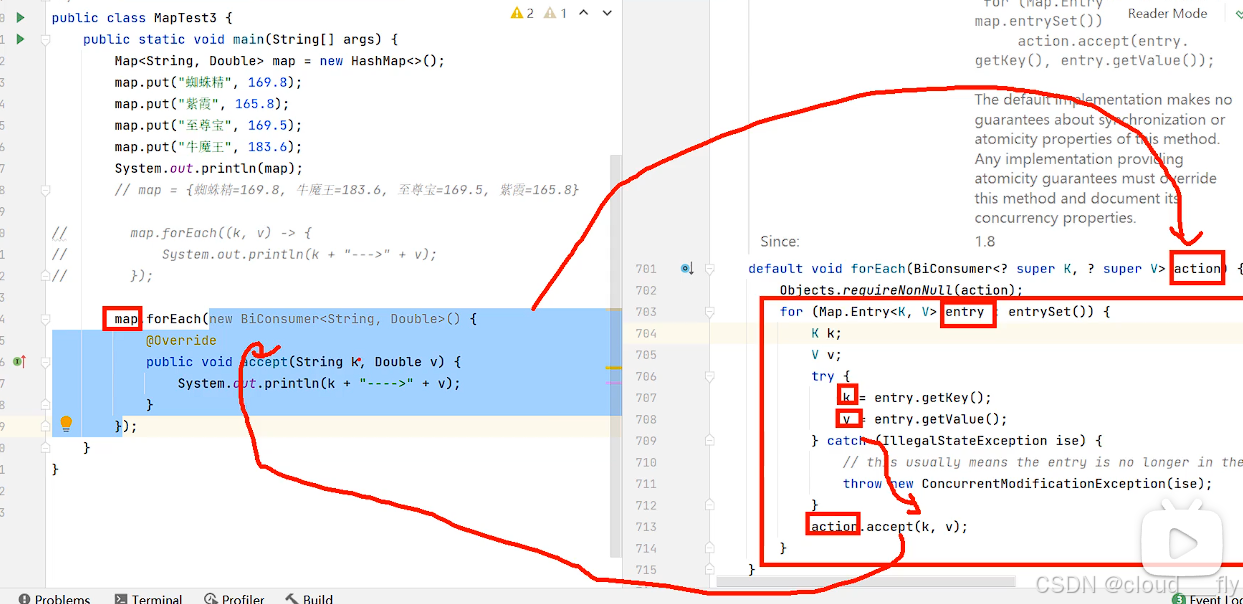
HashMap
HashMap和HashSet底层原理一样,都是基于哈希表实现
并且HashSet是基于HashMap实现


LinkedHashMap


集合的嵌套



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









