




目录
前言:从“菜鸟”到“大神”,中级软件设计师考试的“通关秘籍”
2. 算术逻辑单元(Arithmetic Logic Unit, ALU)
1. RISC(Reduced Instruction Set Computer)
2. CISC(Complex Instruction Set Computer)
1. DRAM(Dynamic Random Access Memory)
2. SRAM(Static Random Access Memory)
2. 全相联映射(Fully Associative Mapping)
3. 组相联映射(Set Associative Mapping)
补码转原码(从左向右数1,到第一个1及以后的位数全取反,之间不变)
2.3 移动设备病毒(Mobile Device Virus)
7. 安全身份验证协议(Kerberos 和 RADIUS)
6. 目标代码优化(Target-Dependent Optimization)
前言:从“菜鸟”到“大神”,中级软件设计师考试的“通关秘籍”
各位读者朋友们,大家好!今天我们要聊一个既让人兴奋又让人头大的话题——中级软件设计师考试!作为一个曾经经历过这场“血雨腥风”的过来人,我深知这不仅仅是一场考试,更是一场自我挑战的旅程。它就像一座巍峨的大山,站在山脚下时会觉得遥不可及,但只要你肯一步一步往上爬,终有一天你会站在山顶,俯瞰整个世界。
话不多说直接开始干货放送!!!(以下是我在考软设时做的笔记--以供大家参考学习哦--偏向上午题的部分)
考试大纲深度解读
(表格对比近三年考点分布)
| 知识领域 | 2021分值 | 2022分值 | 2023变化趋势 |
|---|---|---|---|
| 数据结构与算法 | 18% | 20%↑ | 动态规划权重增加 |
| 软件工程 | 22% | 25%↑ | 敏捷开发成新重点 |
| 数据库系统 | 15% | 14% | 新增NoSQL考点 |
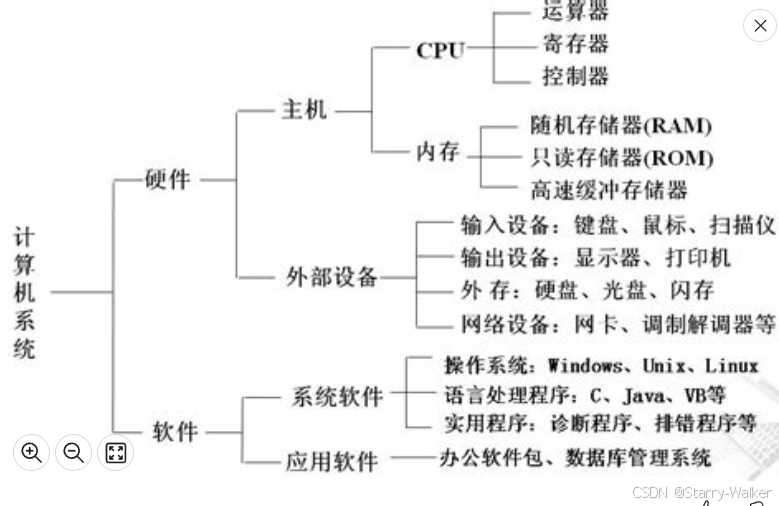
第一章:计算机组成与体系结构
校验码与校验方法:
1. 奇偶校验码
-
特点:简单易实现,只能检测出奇数个位发生错误的情况,无法检测偶数个位错误,也不能纠正错误。
-
构造:对于一个给定的数据位序列,可以通过增加一个校验位来使得整个序列中1的个数为奇数(奇校验)或偶数(偶校验)。例如,在一串8位数据后加一位奇校验位,如果这8位中有偶数个1,则校验位设为1,否则设为0。
2. 海明码
-
特点:不仅可以检测错误,还能纠正单比特错误。海明距离至少为3*(2n+1),意味着任意两个合法编码之间至少有3位不同。
-
构造:在数据位中插入足够的校验位,每个校验位负责检查一组数据位。校验位的位置是2的幂次方(如第1位、第2位、第4位、第8位等),其余位置放置数据位。通过计算各组数据位的奇偶性来确定校验位的值。--仍然是用奇偶性来检错和纠错
3. 循环冗余校验码(CRC)
-
特点:通过数学运算生成一个固定长度的校验码,能够检测多种类型的错误,如突发错误。CRC比简单的奇偶校验更可靠,但实现起来稍微复杂一些。不能纠错
-
构造:基于二进制除法原理,选择一个合适的多项式作为生成多项式(也称为除数)。发送方将数据位看作一个大的二进制数,然后用这个数除以生成多项式得到一个余数,这个余数就是CRC校验码。接收方收到数据后同样进行相同的计算,如果结果为零则认为没有传输错误。
校验位数
1. 奇偶校验码
对于奇偶校验码来说,校验位的数量始终是1。无论数据位有多少,只需要添加一个校验位即可。
2. 海明码
海明码的校验位数取决于数据位的数量。校验位被安排在所有2的幂次方的位置上,如第1位、第2位、第4位、第8位等。为了覆盖所有的数据位,必须有足够的校验位使得所有数据位都被至少一个校验位所覆盖。因此,校验位数 r

3. 循环冗余校验码(CRC)
CRC校验码的长度是由生成多项式的位数决定的。生成多项式的位数决定了校验码的长度,通常比生成多项式少一位。例如,如果使用的是一个16位的生成多项式,那么CRC校验码将是15位长。
CRC校验码的长度是固定的,不受数据长度的影响,而是由所选的生成多项式决定。常见的CRC标准有CRC-8、CRC-16(如CCITT或X.25)、CRC-32等,它们分别对应8位、16位、32位的生成多项式。
浮点数的运算
IEEE 754标准定义了浮点数的两种主要格式:单精度(32位)和双精度(64位)。
-
单精度浮点数:32位,分为三个部分:
-
符号位(1位):表示正负。
-
指数位(8位):表示指数部分。
-
尾数位(23位):表示小数部分。
-
单精度浮点数由三部分组成:
-
符号位(Sign bit, S):1位,用于表示数的正负,0表示正数,1表示负数。
-
指数位(阶码!=移码)(Exponent, E):8位,表示浮点数的指数部分。实际使用的指数值需要从E中减去一个偏置值(Bias),对于单精度而言,偏置值为127。这意味着实际指数值 = E - 127。
-
尾数(Mantissa/Fraction, M):23位,表示小数部分。在IEEE 754中,尾数前面隐含了一个“1”(除非数值是0或特殊值),因此实际上代表的是1.M的形式。
一个单精度浮点数的值可以用下面的公式表示:(规范化)


-
双精度浮点数:64位,同样分为三部分:
-
符号位(1位)。
-
指数位(11位)。
-
尾数位(52位)
-
浮点数运算过程
加减法
-
对阶:将两数的指数调整到相同,通常是指较大的指数。(小对大阶数)
-
尾数相加/减:将对齐后的尾数进行加减操作。
-
规格化:如果尾数运算结果不是规格化形式,则进行左移或右移使其成为规格化形式,并相应调整指数。
-
舍入:根据IEEE 754标准规定的舍入规则对结果进行舍入处理。
-
溢出判断:检查结果是否超出表示范围,如果是,则设置为无穷大或最大值。
CPU
补充点:
1.cpu是依据指令周期的阶段不同去区分在内存中指令和数据
2.CPU对部件的访问速度:通用寄存器>cache>内存>硬盘
3.Cache与主存的地址映射是由硬件自动完成的
4.cpu内外设置多级高速缓存的目的是提高cpu访问主存数据或指令的效率
CPU(中央处理单元,Central Processing Unit)是计算机的核心部件之一,负责执行指令集中的各种操作。CPU的结构主要包括以下几个关键组件:
1. 控制单元(Control Unit, CU)
控制单元负责管理和协调CPU内的所有活动,包括从内存读取指令、解码指令、管理指令执行流程等。具体职责包括:
-
指令获取:从主存中按序读取指令。
-
指令解码:将读取到的机器指令转换为控制信号。
-
时序控制:控制指令执行的时间顺序。
-
微操作生成:生成具体的微操作信号来控制其他部件工作。
-
状态监控:监控CPU的状态,如中断状态等。
2. 算术逻辑单元(Arithmetic Logic Unit, ALU)
算术逻辑单元负责执行所有的算术运算(如加、减、乘、除)和逻辑运算(如与、或、非、移位等)。ALU是CPU执行计算任务的核心部分。
3. 寄存器组(Register File)
寄存器组是一组小型的高速存储单元,位于CPU内部,用于临时存放数据和指令。常见的寄存器类型包括:
-
通用寄存器:用于保存操作数或中间结果。
-
程序计数器(PC):指示当前要执行的指令地址。
-
地址寄存器(AR):用来存储CPU当前访问的内容单元地址,和PC区别
-
指令寄存器(IR):暂存当前正在执行的指令(操作码+地址码)。-位数取决于字长(完全透明,其他可由汇编访问)
-
状态寄存器(PSW):保存CPU的状态信息,如标志位(进位、零、符号等)。
-
累加器:用于存储运算结果。
-
基址寄存器和索引寄存器:用于计算有效地址。
4. 缓存(Cache Memory)
缓存是一种高速存储器,用于暂时存储频繁访问的数据和指令,以便快速访问。缓存可以分为多个层次,如L1、L2和L3缓存。缓存的存在减少了CPU访问主存的时间,提高了整体性能。
5. 数据通路(Data Pathways)
数据通路是指CPU内部用于传递数据的各种线路和总线。它们连接CPU的各个部件,使得数据可以在这些部件之间流动。
CPU的工作流程
CPU的工作流程通常包括以下几个步骤:
-
取指(Fetch):从内存中读取下一条指令到指令寄存器。
-
解码(Decode):将指令解析成一系列控制信号。
-
执行(Execute):根据解码结果执行相应的操作,如读取操作数、执行ALU操作等。
-
写回(Write Back):将执行结果写回到寄存器或内存中。
-
更新状态(Update Status):根据执行结果更新状态寄存器中的标志位。
指令系统
1. RISC(Reduced Instruction Set Computer)
定义
RISC是一种精简指令集计算机体系结构,其设计理念是通过减少指令的数量和复杂度,来简化硬件设计,提高指令执行速度。(硬布线逻辑执行指令)
特点
-
精简的指令集:指令集相对较少,每条指令的功能简单,易于实现。
-
固定长度的指令:大多数RISC架构使用固定长度的指令格式。
-
寄存器到寄存器的操作:大多数指令操作在寄存器之间进行,减少了访存操作。
-
简单的寻址模式:通常使用简单的寻址模式,如寄存器直接寻址。
-
流水线执行:支持高效的流水线执行,提高指令执行速度。
-
编译器优化:编译器可以更好地优化代码,生成更高效的机器码。
2. CISC(Complex Instruction Set Computer)
定义
CISC是一种复杂指令集计算机体系结构,其设计理念是通过提供丰富的指令集来支持更复杂的操作,从而减少程序中的指令数量。
特点
-
丰富的指令集:指令集相对较多,每条指令可以完成较为复杂的操作。
-
变长的指令:指令长度不固定,可以根据需要使用不同长度的指令。
-
多种寻址模式:支持多种寻址模式,如立即数寻址、寄存器寻址、间接寻址等。
-
复杂的硬件设计:硬件设计较为复杂,以支持丰富的指令集。
-
微代码:通常使用微代码(Microcode)来实现复杂的指令。
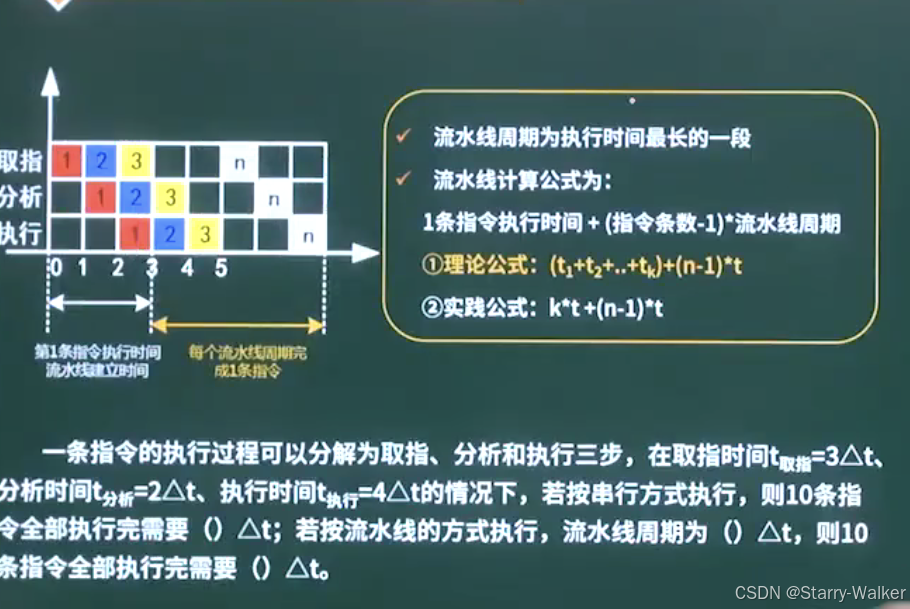
流水线技术
注释:
k:一个完整指令的步骤数(实际公式)
极限吞吐量:流水线周期的倒数
流水线采用异步的方式会导致阻塞


三种寻址方式
1. 立即寻址(Immediate Addressing)
定义
立即寻址是指操作数直接包含在指令中,而不是存储在内存或寄存器中。操作数作为一个立即数(Immediate Value)出现在指令中。
优点
-
简单:操作数直接给出,不需要额外的寻址操作。
-
高效:不需要访问内存或寄存器,执行速度快。
缺点
-
限制:操作数的大小受限于指令的长度。
-
不灵活:只能处理固定大小的操作数。
应用
-
常量操作:用于常量值的赋值或比较。
-
简单计算:用于简单的算术或逻辑操作,如加法、减法等。
示例
假设一条指令 ADD #5, R1,表示将立即数 5 加到寄存器 R1 中。
2. 寄存器寻址(Register Addressing)
定义
寄存器寻址是指操作数存储在寄存器中。指令中直接指定寄存器的编号。
优点
-
高效:寄存器访问速度快,不需要访问内存。
-
灵活:可以处理任意大小的操作数。
缺点
-
寄存器数量有限:寄存器的数量通常有限,需要合理分配。
应用
-
频繁访问的数据:用于频繁访问的数据或临时变量。
-
中间结果存储:用于存储中间计算结果。
示例
假设一条指令 ADD R1, R2,表示将寄存器 R1 中的值加到寄存器 R2 中。
3. 存储器寻址(Memory Addressing)
定义
存储器寻址是指操作数存储在内存中。指令中指定内存地址。
优点
-
大范围存储:可以访问大范围的存储空间。
-
灵活:可以处理任意大小的操作数。
缺点
-
访问速度慢:需要访问内存,速度比寄存器慢。
-
地址计算:需要进行地址计算,增加指令复杂度。
应用
-
数据存储:用于存储和访问数据。
-
数组操作:用于数组元素的访问。
示例
假设一条指令 LOAD R1, [100],表示将内存地址 100 中的数据加载到寄存器 R1 中。
存储系统
1. DRAM(Dynamic Random Access Memory)
定义
DRAM 是一种随机存取存储器,它主要用于计算机的主内存(RAM)。DRAM 中的数据存储在一个电容器中,电容器会随着时间逐渐放电,因此需要定期刷新(Refresh)来维持数据的完整性。
特点
-
成本较低:相比 SRAM,DRAM 成本更低,因此更适合大量生产。
-
密度较高:能够以较高的密度集成更多的存储单元。
-
速度较慢:由于需要定期刷新,访问速度相对较慢。
-
易失性:断电后数据会丢失。
应用
-
主要用于计算机的主内存,提供大量的存储空间供程序运行时使用。
2. SRAM(Static Random Access Memory)
定义
SRAM 也是一种随机存取存储器,但它使用静态触发器来存储数据,不需要定期刷新。
特点
-
速度快:访问速度较快,因为不需要刷新。
-
功耗较高:相比 DRAM,功耗较大。
-
成本较高:制造成本较高,因此通常用于需要高速度的小规模存储。
-
易失性:断电后数据会丢失。
应用
-
通常用于 CPU 内部的寄存器文件(Register File)或高速缓存(Cache)。
3. Cache(高速缓存)
定义
Cache 是一种高速的临时存储器,位于 CPU 和主内存之间,用于存储最近频繁访问的数据和指令,以减少 CPU 访问主内存的次数。
特点
-
访问速度快:Cache 的访问速度接近于 CPU 的速度。
-
容量较小:由于成本和物理空间限制,Cache 的容量相对较小。
-
层次结构:通常分为 L1、L2 和 L3 多级缓存,越靠近 CPU 的缓存速度越快,容量越小。
-
命中率:Cache 的性能取决于命中率(Hit Rate),即 CPU 请求的数据在 Cache 中找到的概率。
应用
-
提高 CPU 的访问速度,减少访问主内存的延迟。
-
通过多级缓存来平衡速度和容量的需求。
它们之间的联系
-
层次结构:在现代计算机体系结构中,Cache、SRAM 和 DRAM 形成了一个层次结构,从高速缓存到主内存依次降低速度但增加容量。
-
Cache:最靠近 CPU,速度最快,容量最小。
-
SRAM:用于实现 Cache 和 CPU 内部寄存器。
-
DRAM:作为主内存,容量最大,速度较慢。
-
-
数据流动:当 CPU 需要访问数据时,首先尝试从 Cache 中读取,如果 Cache 中没有,则从主内存(DRAM)中读取,并将这部分数据加载到 Cache 中。
-
协调机制:为了保证数据的一致性,Cache 通常采用某种一致性协议(如 MESI 协议)来协调多核处理器之间的数据共享。
三种映射方式
1. 直接映射(Direct Mapping)
工作原理
在直接映射中,主内存中的每一个块(Block)只能映射到Cache中的一个特定位置。具体来说,主内存地址被分为三部分:
-
标记(Tag):用于标识主内存中的具体块。
-
索引(Index):用于确定Cache中的行(Line)。
-
偏移(Offset):用于定位Cache行中的具体字节。
每个Cache行包含一个标记字段和数据字段。标记字段存储主内存块的标记,数据字段存储该块的数据。
优点
-
简单:实现简单,硬件开销小。
-
速度快:由于每个内存块只有一个映射位置,查找速度快。
缺点
-
冲突概率高:如果多个经常访问的内存块映射到同一个Cache行,则会发生冲突,导致Cache命中率下降。
2. 全相联映射(Fully Associative Mapping)
工作原理
在全相联映射中,主内存中的每一个块可以映射到Cache中的任何一个位置。每个Cache行包含一个完整的标记字段和数据字段。当访问一个内存地址时,所有Cache行的标记都会被检查,以确定该地址的数据是否存在于Cache中。
优点
-
冲突概率低:每个内存块可以映射到任何Cache行,冲突概率低。
-
灵活性高:可以更好地适应不同的数据访问模式。
缺点
-
复杂:实现复杂,硬件开销大。
-
成本高:需要更多的硬件资源来实现,导致成本增加。
3. 组相联映射(Set Associative Mapping)
工作原理
组相联映射结合了直接映射和全相联映射的优点。它将Cache分为多个组(Set),每个组包含多个行(Way)。主内存中的每个块可以映射到某个组中的任何一个行。具体来说,主内存地址被分为三部分:
-
标记(Tag):用于标识主内存中的具体块。
-
组索引(Set Index):用于确定Cache中的组。
-
偏移(Offset):用于定位组中的具体行。
每个组内的行形成一个关联集合,当访问一个内存地址时,会在该组内的所有行中查找匹配的标记。
优点
-
灵活性和效率:相比于直接映射,冲突概率较低;相比于全相联映射,实现相对简单。
-
成本适中:在成本和性能之间取得较好的平衡。
缺点
-
实现复杂度:相对于直接映射,实现稍显复杂。
-
硬件开销:需要一定的硬件资源来实现组内的关联查找。
总结
-
直接映射:简单、速度快,但冲突概率高。
-
全相联映射:冲突概率低,灵活性高,但实现复杂且成本高。
-
组相联映射:在冲突概率和实现复杂度之间取得平衡,是现代Cache设计中最常用的方式
主存编址
编址位数指的是地址总线的宽度,即用于表示内存地址的位数。 、
例如,一个32位的地址表示可以用32位的二进制数来表示一个内存地址,这意味着可以寻址的内存单元数量是 2^32个


磁盘寻址
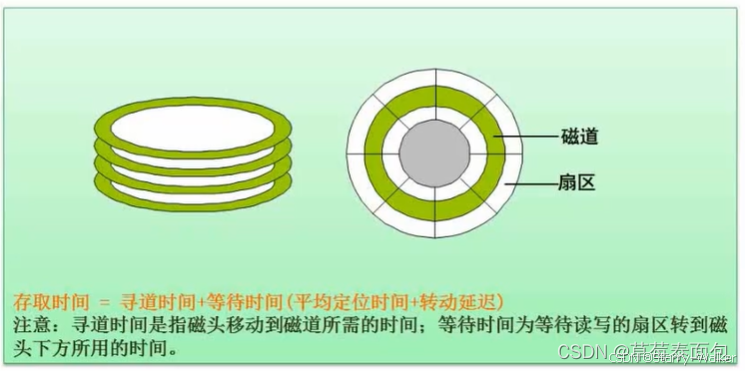
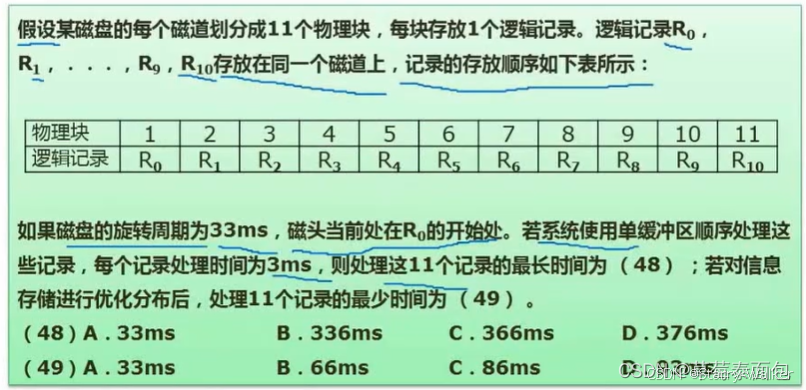
(1)
33ms一圈,有11个块,一个块的旋转时间是3ms,读取时间是3ms
磁头开始旋转就不会停,磁头从R0开始转,经过3ms读取R0转到R1,这时缓存区正在处理记录,不能读取,磁头继续旋转1圈转到R1处读取R1,以此类推,每次记录的读取+处理时间为3ms+33ms,R0-R9都是这样处理。R10不需要旋转,只计算读取+处理时间3ms+3ms,总共是(33+3)*10+(3+3)=366ms
(2)
(3ms+3ms)*11=66ms
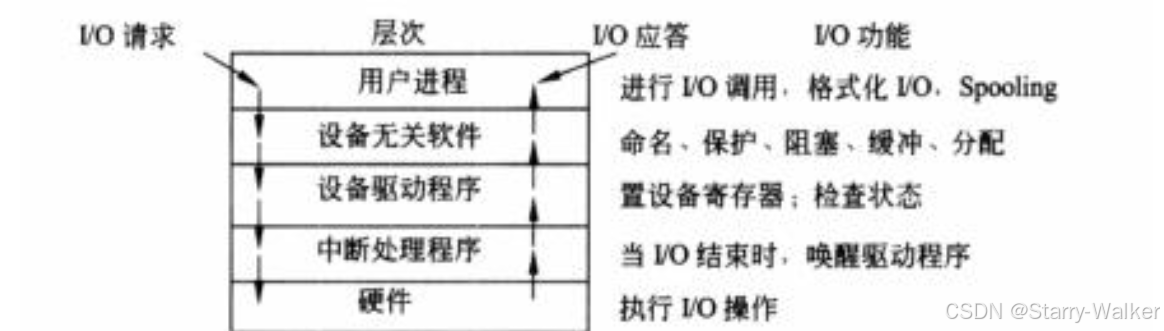
输入输出系统
补充:
1.实现多级中断嵌套:使用堆栈来保护断点和现场最有效
计算机中主机与外设间进行数据传输的输入输出的控制方法有程序控制方式、中断方式、DMA等,输入输出系统是一组固化到计算机内主板上一个ROM芯片上的程序
1.程序控制方式:由CPU执行程序控制数据的输入输出过程
2.中断方式:外设准备好输入数据或接受数据时向CPU发出中断请求信号,若CPU决定响应该请求,则暂停正在执行的任务,转而执行中断服务程序进行数据的输入输出处理,之后再回去执行原来的被中断的任务,中断时根据中断服务程序的入口地址进行中断
3.DMA(直接存储器控制):CPU只需向DMA控制器下达指令,让DMA控制器来处理数据的传送,数据传送完毕再把信息反馈给CPU,这样就很大程度上减轻了CPU的负担
注:CPU是在一个总线周期结束时响应DMA请求的,
1. DMA(Direct Memory Access)
定义
DMA(直接存储器访问)是一种允许外部设备直接与主内存交换数据而不经过CPU的机制。通过DMA,外部设备可以直接读取或写入主内存中的数据,从而减轻CPU的负担,提高数据传输效率。(主存-外设建立通路)
工作原理
DMA控制器负责管理DMA操作,其主要工作步骤如下:(一个总线周期)
-
初始化:CPU向DMA控制器发送命令,指定DMA操作的参数,如源地址、目标地址、数据长度等。
-
请求:DMA控制器向CPU请求总线控制权。
-
控制权转移:CPU将总线控制权交给DMA控制器。
-
数据传输:DMA控制器直接控制数据在外部设备和主内存之间的传输。
-
完成通知:DMA操作完成后,DMA控制器释放总线控制权,并通知CPU操作完成
2. ROM(Read-Only Memory)
定义
ROM(只读存储器)是一种非易失性存储器,用于存储固定的程序和数据,即使断电后数据也不会丢失。ROM通常用于存储启动代码、固件等。
应用
-
启动程序:存储BIOS或UEFI固件。
-
固件:存储设备的控制程序
原码反码补码
注意符号位计算,符号位
1. 原码(Sign-Magnitude)
原码是最直观的一种表示方法,它直接用最高位表示符号,剩下的位表示数值的绝对值。
-
正数:符号位为0,后面跟着数值的二进制表示。
-
负数:符号位为1,后面跟着数值绝对值的二进制表示。
2. 反码(One's Complement)
反码是对原码的一种改进,旨在解决原码中存在两个零(+0和-0)的问题。
-
正数:反码与原码相同。
-
负数:符号位仍为1,数值位取反(即每一位都变成其相反数,0变1,1变0)。
3. 补码(Two's Complement)
补码是为了进一步优化反码的不足之处(只存在一个零),特别是为了简化加法和减法操作。补码是目前计算机中最常用的带符号整数表示方法。
-
正数:补码与原码相同。
-
负数:符号位为1,数值位先取反(得到反码),然后再加1。
转换方法
原码转反码
-
正数:原码与反码相同。
-
负数:将原码中数值位的每一位取反。
原码转补码
-
正数:原码与补码相同。
-
负数:将原码中数值位的每一位取反(得到反码),然后加1。
反码转原码
-
正数:反码与原码相同。
-
负数:将反码中数值位的每一位取反。
反码转补码
-
正数:反码与补码相同。
-
负数:将反码加1。
补码转原码(从左向右数1,到第一个1及以后的位数全取反,之间不变)
-
正数:补码与原码相同。
-
负数:将补码减1,然后取反。
补码转反码
-
正数:补码与反码相同。
-
负数:将补码减1
总线系统
1. 总线的概念
总线(Bus)是一组共享的通信线路,用于连接计算机系统中的各个组件。通过总线,这些组件可以相互传递数据、地址和控制信息。总线系统的设计直接影响到系统的性能和可靠性。
2. 总线的分类
根据传输的信息类型和功能,总线可以分为以下几类:
-
数据总线(Data Bus, DB):用于传输数据。数据总线的宽度决定了每次可以传输的数据量,通常以位(bits)为单位。==字长位数
-
地址总线(Address Bus, AB):用于传输地址信息,指示数据的目的地或来源。地址总线的宽度决定了系统可以寻址的最大内存空间。
-
控制总线(Control Bus, CB):用于传输控制信号,如读/写信号、中断请求、复位信号等,控制数据和地址总线的操作。
3. 总线的标准和接口
总线系统通常遵循一定的标准和接口规范,以确保不同厂商生产的硬件设备能够兼容和互连。常见的总线标准包括:
-
ISA(Industry Standard Architecture):早期的个人计算机总线标准,现已过时。
-
PCI(Peripheral Component Interconnect):广泛应用于个人计算机,用于连接高速外围设备。
-
PCI Express(PCIe):新一代的高速串行总线标准,取代了传统的并行PCI总线。
-
USB(Universal Serial Bus):用于连接外部设备,如键盘、鼠标、打印机等。
-
SATA(Serial Advanced Technology Attachment):用于连接硬盘驱动器和其他存储设备。
-
AGP(Accelerated Graphics Port):专为图形卡设计的总线标准,现已逐渐被PCI Express取代。
4. 总线的拓扑结构
总线系统的拓扑结构描述了各个组件如何连接在一起。常见的拓扑结构包括:
-
单总线结构:所有组件共享同一根总线。简单,但容易产生瓶颈。(串型-长距离传输)
-
多总线结构:多个总线并行工作,每个总线负责不同的功能或连接不同的组件。可以提高系统的性能和扩展性。(并行-近距离高速传输)
-
桥接结构:通过桥接器将不同的总线连接起来,实现数据和控制信号的转发。
5. 总线仲裁
在多总线系统中,多个组件可能同时请求使用总线。总线仲裁机制用于决定哪个组件可以在某一时刻使用总线。常见的仲裁策略包括:
-
集中式仲裁:由一个中心控制器决定总线使用权。
-
分布式仲裁:各组件通过协商决定总线使用权。
-
优先级仲裁:根据组件的优先级高低分配总线使用权。
6. 总线带宽
总线带宽是指单位时间内总线可以传输的数据量。带宽受到总线宽度、频率和传输协议等因素的影响。提高带宽可以提升系统的整体性能。

7. 总线周期
总线周期是指一次完整的数据传输过程,包括请求总线、传输地址、传输数据和释放总线等步骤。优化总线周期可以提高系统的吞吐量和响应速度。
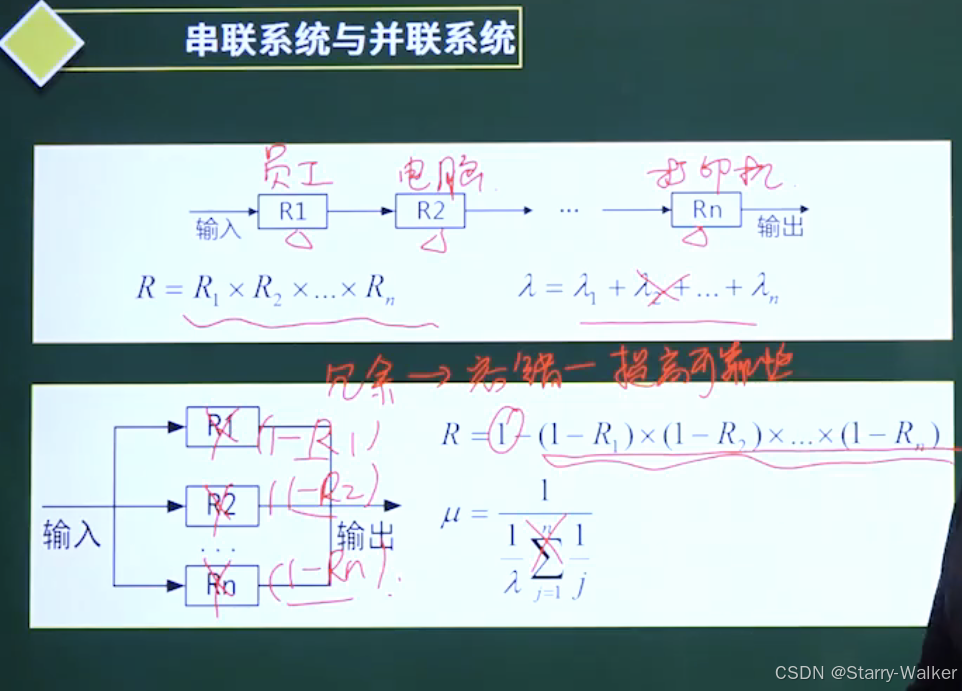
系统可靠性
常用:可靠性:MTTF/(1+MTTF)-不取决于软件的开发方式
可用性:MTBF/(1+MTBF)
可维护性:MTTR/(1+MTTR)
R:单个部件的可靠性

第二章-信息安全和病毒防护
1. 信息安全的基本概念
1.1 信息安全的三个基本属性
-
机密性(Confidentiality):确保只有授权用户可以访问敏感信息。
-
完整性(Integrity):确保信息不被未经授权的修改。
-
可用性(Availability):确保信息和服务始终可用
信息安全威胁分类
信息安全威胁可以按照不同的方式进行分类。以下是一些常见的分类方式及其具体内容:
1. 按照威胁的来源分类
-
内部威胁(Internal Threats):
-
员工失误:误操作导致的数据泄露或系统故障。
-
恶意内部人员:有意破坏系统或窃取敏感信息。
-
软件缺陷:内部使用的软件存在漏洞。
-
-
外部威胁(External Threats):
-
黑客攻击:未经授权的访问尝试,如SQL注入、跨站脚本攻击(XSS)等。
-
网络钓鱼:通过伪造网站或邮件诱导用户泄露敏感信息。
-
恶意软件:病毒、木马、蠕虫等恶意程序。
-
2. 按照威胁的目标分类
-
数据威胁(Data Threats):
-
数据泄露:未经授权的数据访问或传输。
-
数据篡改:未经授权的数据修改。
-
数据丢失:数据损坏或删除。
-
-
系统威胁(System Threats):
-
拒绝服务攻击(DoS, Denial of Service):通过大量无效请求使系统无法正常服务。
-
分布式拒绝服务攻击(DDoS, Distributed Denial of Service):利用多台计算机协同发起拒绝服务攻击。
-
系统崩溃:通过漏洞利用导致系统崩溃或重启。
-
-
应用程序威胁(Application Threats):
-
SQL注入:通过恶意输入破坏数据库查询语句。
-
跨站脚本攻击(XSS, Cross-Site Scripting):在网页上插入恶意脚本。
-
跨站请求伪造(CSRF, Cross-Site Request Forgery):利用用户的登录状态执行恶意操作。
-
3. 按照威胁的行为分类
-
主动威胁(Active Threats):
-
篡改数据:未经授权修改数据。
-
拒绝服务:通过攻击使系统无法正常服务。
-
数据泄露:未经授权获取数据。
-
-
被动威胁(Passive Threats):
-
监听(Eavesdropping):未经授权监听通信内容。
-
数据嗅探(Data Sniffing):通过网络嗅探获取敏感信息。
-
信息收集:未经授权收集系统或网络信息。
-
4. 按照威胁的手段分类
-
物理威胁(Physical Threats):
-
盗窃:偷盗硬件设备或存储介质。
-
破坏:故意破坏硬件设施,如剪断电缆、破坏服务器等。
-
自然灾害:地震、火灾等自然灾害导致的损失。
-
-
逻辑威胁(Logical Threats):
-
软件漏洞:利用软件中的漏洞进行攻击。
-
恶意代码:病毒、木马、蠕虫等恶意程序。
-
社会工程学:利用人的心理弱点进行欺诈或操纵
-
1. 加密算法
1.1 对称加密算法(共享加密)
-
定义:使用相同的密钥进行加密和解密。
-
优点:加密和解密速度快。
-
缺点:密钥分发困难。
-
常用算法:
-
DES(Data Encryption Standard):使用56位密钥,已不再被认为是安全的。
-
3DES(Triple DES):使用168位密钥,增强了安全性。
-
AES(Advanced Encryption Standard):使用128位、192位或256位密钥,目前广泛使用。
-
1.2 非对称加密算法(公开加密)
-
定义:使用一对密钥,公钥加密私钥解密,反之亦然。
-
优点:密钥分发安全。
-
缺点:加密和解密速度相对较慢。
-
常用算法:
-
RSA(Rivest-Shamir-Adleman):广泛使用的非对称加密算法。
-
ECC(Elliptic Curve Cryptography):更高效,适合移动设备。
-
ElGamal:基于离散对数问题的加密算法。
-
Diffie-Hellman:主要用于密钥交换。
-
2. 数字签名
2.1 定义(防止抵赖技术)
数字签名是一种使用非对称加密技术来验证信息真实性和完整性的方式。发送方使用自己的私钥对信息进行签名,接收方使用发送方的公钥验证签名。
2.2 工作原理
-
生成签名:发送方使用私钥对信息进行签名(在非对称技术中用来解密)。
-
验证签名:接收方使用发送方的公钥验证签名的真实性(在非对称技术中用来加密)。
2.3 应用场景
-
电子邮件:确保邮件的真实性和完整性。
-
软件发布:确保软件包未被篡改。
-
金融交易:确保交易的真实性。
3. 证书
3.1 定义
证书是一种数字文档,用于证明公钥的所有者身份。证书通常由证书颁发机构(CA, Certificate Authority)签发。
3.2 组成部分
-
公钥:用于加密和验证签名。
-
所有者信息:证书持有者的名称、组织等信息。
-
有效期:证书的有效时间范围。
-
签发机构:证书颁发机构的名称。
-
数字签名:由证书颁发机构对证书进行签名,以证明证书的有效性。
3.3 应用场景
-
网站安全:HTTPS协议使用证书来确保网站的身份和通信的安全性。
-
电子邮件:证书可用于验证发送方的身份。
-
软件发布:证书可用于验证软件发行商的身份
4.数字信封

1. 按照感染方式分类
1.1 引导区病毒(Boot Sector Virus)
-
定义:感染计算机的引导扇区,通常是在硬盘或软盘的引导扇区。
-
特点:
-
在系统启动时加载。
-
通常隐藏在操作系统之外,难以检测。
-
通过感染其他可引导媒体(如软盘)进行传播。
-
1.2 文件病毒(File Virus)
-
定义:感染可执行文件(如.EXE、.COM文件)。
-
特点:
-
在执行受感染的文件时加载。
-
可以通过感染其他可执行文件进行传播。
-
通常在文件头或文件尾附加自身代码。
-
1.3 宏病毒(Macro Virus)
-
定义:感染文档中的宏(如Word、Excel文档中的宏)。
-
特点:
-
利用Office应用程序中的宏语言编写。
-
通过打开受感染的文档时激活。
-
可以通过电子邮件附件、共享文档等方式传播。
-
1.4 脚本病毒(Script Virus)
-
定义:利用脚本语言(如VBScript、JavaScript)编写。
-
特点:
-
通常通过Web页面或电子邮件附件传播。
-
可以利用浏览器或邮件客户端的漏洞进行攻击。
-
2. 按照传播方式分类
2.1 电子邮件病毒(Email Virus)
-
定义:通过电子邮件附件或链接进行传播。
-
特点:
-
利用社会工程学手法诱骗用户打开附件或点击链接。
-
通常伪装成合法的邮件,如发票、通知等。
-
可以自动发送邮件给通讯录中的联系人。
-
2.2 网络病毒(Network Virus)
-
定义:通过网络进行传播。
-
特点:
-
可以通过局域网内的共享文件进行传播。
-
利用网络漏洞进行攻击。
-
通过P2P(点对点)网络或即时通讯工具传播。
-
2.3 移动设备病毒(Mobile Device Virus)
-
定义:针对移动设备(如智能手机、平板电脑)的病毒。
-
特点:
-
通过恶意应用程序或短信进行传播。
-
可以利用移动设备的操作系统漏洞。
-
通过社交网络、即时通讯工具等途径传播。
-
3. 按照行为方式分类
3.1 木马病毒(Trojan Virus)
-
定义:伪装成合法程序的恶意软件。
-
特点:
-
通常通过诱骗用户下载并执行。
-
可以窃取个人信息、密码等敏感数据。
-
不会自我复制,但可以通过其他方式传播。
-
3.2 蠕虫病毒(Worm Virus)
-
定义:能够自我复制并通过网络进行传播的病毒。
-
特点:
-
不需要宿主文件,可以直接在系统中运行。
-
可以利用网络漏洞进行攻击。
-
通过邮件、即时通讯工具等方式快速传播。
-
3.3 混合型病毒(Polymorphic Virus)
-
定义:具有多种特性的病毒。
-
特点:
-
可以改变自身的代码,使防病毒软件难以检测。
-
可以感染多种类型的文件和系统。
-
可以通过多种方式进行传播。
-
3.4 多态病毒(Poly-morphic Virus)
-
定义:每次感染时都会改变自身代码的病毒。
-
特点:
-
通过改变代码来逃避检测。
-
需要专门的解码器来还原原始代码。
-
可以通过多种方式进行传播
-


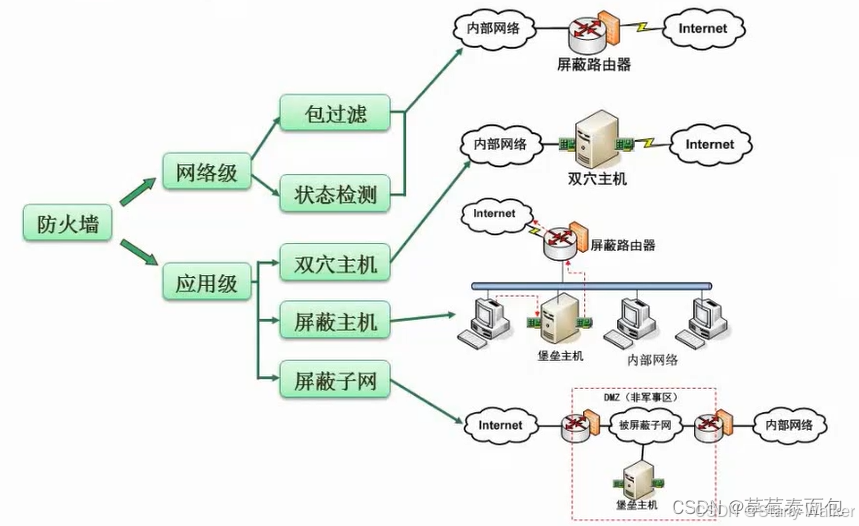
防火墙
1.1 定义
防火墙是一种网络安全设备或软件,用于监视和控制进出网络的流量,防止未经授权的访问,并保护网络免受恶意攻击。(防外不防内)
1.2 作用
-
访问控制:限制哪些流量可以进入或离开网络。
-
日志记录:记录通过防火墙的所有流量信息。
-
入侵检测:检测并阻止潜在的恶意流量。
-
应用控制:控制特定应用程序的流量。
-
地址转换:隐藏内部网络的真实地址。
2. 防火墙的类型
2.1 包过滤防火墙(Packet Filtering Firewall)
-
定义:基于IP地址、端口号等信息过滤数据包。
-
工作原理:检查每个数据包的头部信息,并根据预设的规则决定是否放行。
-
优点:简单、高效。
-
缺点:无法识别应用层协议,容易受到IP欺骗攻击。
2.2 应用级网关(Application-Level Gateway, ALG)
-
定义:代理客户端与服务器之间的通信。
-
工作原理:在应用层上检查数据包,并根据应用层协议进行过滤。
-
优点:
-
缺点:性能较低,需要为每种应用单独配置。
2.3 状态检查防火墙(Stateful Inspection Firewall)
-
定义:跟踪连接状态并过滤数据包。
-
工作原理:维护连接状态表,并根据连接状态决定是否放行数据包。
-
优点:兼顾安全性和性能。
-
缺点:配置复杂,需要定期维护连接状态表。
2.4 下一代防火墙(Next Generation Firewall, NGFW)
-
定义:结合传统防火墙功能与高级威胁防御技术。
-
工作原理:除了基本的包过滤功能外,还包括入侵检测、应用识别、恶意软件防护等功能。
-
优点:综合防护能力强。
-
缺点:成本较高,需要高级配置。
4. 防火墙的功能
4.1 访问控制
-
定义:限制哪些流量可以进入或离开网络。
-
优点:防止未经授权的访问。
-
缺点:需要定期更新规则。
4.2 日志记录
-
定义:记录通过防火墙的所有流量信息。
-
优点:便于事后审计和分析。
-
缺点:需要定期清理日志文件。
4.3 入侵检测
-
定义:检测并阻止潜在的恶意流量。
-
优点:提高安全性。
-
缺点:可能误报或漏报。
4.4 应用控制
-
定义:控制特定应用程序的流量。
-
优点:防止恶意应用程序滥用带宽。
-
缺点:需要定期更新应用规则。
4.5 地址转换(NAT, Network Address Translation)
-
定义:隐藏内部网络的真实地址。
-
优点:提高安全性。
-
缺点:可能影响某些应用的正常工作
安全协议
1. 安全传输层协议(TLS/SSL)
1.1 定义
TLS(Transport Layer Security)是SSL(Secure Sockets Layer)的后续版本,用于在客户端和服务器之间建立加密连接,确保数据传输的安全性。
1.2 应用场景
-
Web 安全:HTTPS(HTTP over TLS)用于加密 Web 通信。
-
电子邮件安全:SMTPS(SMTP over TLS)用于加密电子邮件传输。
-
即时通讯:XMPP(Extensible Messaging and Presence Protocol)使用 TLS 进行加密。
2. 安全外壳协议(SSH)
2.1 定义
SSH(Secure Shell)是一种加密的网络协议,用于远程登录和管理网络上的计算机。
2.2 应用场景
-
远程登录:通过 SSH 登录远程服务器进行管理。
-
文件传输:SFTP(SSH File Transfer Protocol)用于安全地传输文件。
-
端口转发:SSH 可以用于安全地转发网络端口。
3. 安全套接字层(SSL)
3.1 定义
SSL 是 TLS 的前身,同样用于在客户端和服务器之间建立加密连接。
3.2 应用场景
-
Web 安全:早期版本的 HTTPS 使用 SSL 协议。
-
电子邮件安全:早期版本的 SMTPS 使用 SSL 协议。
4. 安全电子邮件协议(S/MIME 和 PGP)
4.1 定义
S/MIME(Secure/Multipurpose Internet Mail Extensions)和 PGP(Pretty Good Privacy)都是用于加密电子邮件的协议。
4.2 应用场景
-
电子邮件加密:加密电子邮件内容,确保只有收件人才能阅读。
-
数字签名:验证发送者的身份,确保电子邮件未被篡改。
5. 安全文件传输协议(SFTP 和 FTPS)
5.1 定义
SFTP(SSH File Transfer Protocol)和 FTPS(FTP over SSL/TLS)都是用于安全传输文件的协议。
5.2 应用场景
-
文件上传和下载:安全地上传和下载文件到服务器。
-
数据备份:安全地备份数据到远程服务器。
6. 安全网络协议(IPSec)
6.1 定义
IPSec(Internet Protocol Security)是一套用于保护 IP 通信安全的协议。
6.2 应用场景
-
虚拟专用网络(VPN):通过 IPSec 创建安全的虚拟专用网络。
-
数据加密:加密网络通信,保护数据安全。
-
身份验证:确保通信双方的身份。
7. 安全身份验证协议(Kerberos 和 RADIUS)
7.1 定义
Kerberos 和 RADIUS 是用于身份验证的协议。
7.2 应用场景
-
网络身份验证:确保用户身份的真实性和合法性。
-
访问控制:基于身份验证结果控制用户访问权限。
8. 安全数据交换协议(HTTPS 和 FTPS)
8.1 定义
HTTPS(HTTP over TLS)和 FTPS(FTP over SSL/TLS)都是用于安全传输数据的协议。
8.2 应用场景
-
Web 安全:HTTPS 用于加密 Web 通信。
-
文件传输:FTPS 用于加密 FTP 通信。
9. 安全电子邮件协议(SMTPS 和 IMAPS)
9.1 定义
SMTPS(SMTP over SSL/TLS)和 IMAPS(IMAP over SSL/TLS)都是用于安全传输电子邮件的协议。
9.2 应用场景
-
电子邮件发送:SMTPS 用于加密电子邮件发送过程。
-
电子邮件接收:IMAPS 用于加密电子邮件接收过程。
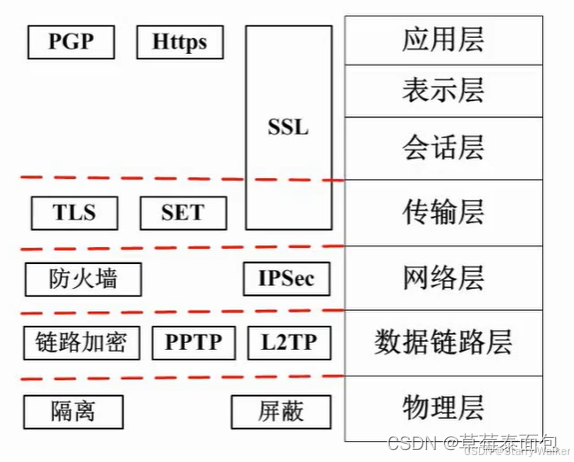
从第二层开始实行协议保障安全,IPSec是对IP包进行加密的协议
SSH:是建立在应用层基础上的安全协议,SSH是目前较为可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用SSH协议可以有效防止远程管理过程中的信息泄露问题
SSL:SSL是为网络通信提供安全及数据完整性的一种安全协议,在传输层对网络连接进行加密,目前被广泛地用于Web浏览器与服务器之间的身份认证和加密数据传输。
第三章:程序语言
补充:
1.静态语义错误是指那些在编译阶段就可以被检测出来的错误。这些错误通常涉及到程序的语言规范,包括语法错误、类型错误等。
2.动态语义错误是指那些在程序运行时才会被检测出来的错误。这类错误通常涉及到程序的实际执行情况,包括数组越界、空指针引用等。
3.全局变量一般存在静态数据区,堆栈存储动态数据。
4.程序中的数据都具有类型的作用不包括:便于定义动态数据类型。
5.在传值的方式下实参可以是数组,并且可以对制作变量进行算术运算(移动数组)
6.Lisp是一种函数式编程

编译原理
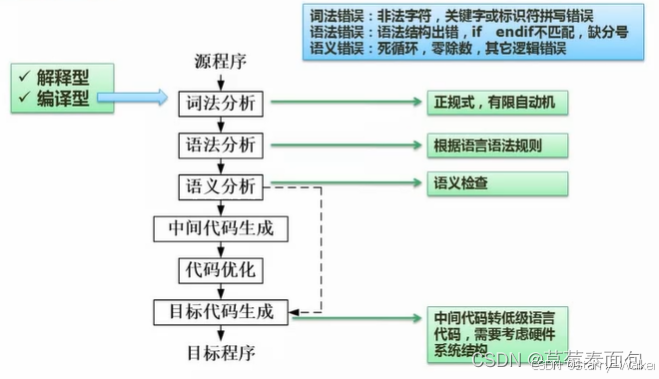
编译程序(Compiler)是将一种编程语言(源代码)转换为另一种编程语言(通常是机器语言或中间语言)的程序。编译过程通常可以分为以下几个主要阶段,每个阶段都有其特定的任务和技术:(中间代码生成和代码优化不是必须的)
1. 词法分析(Lexical Analysis)
任务
-
识别源代码中的词汇单位(Token):将源代码分解成一系列有意义的词汇单位,如关键字、标识符、运算符、常量等。
技术
-
正则表达式:用于定义词汇单位的模式。
-
有限状态自动机(Finite State Automata, FSA):用于识别词汇单位。
2. 语法分析(Syntax Analysis)(结构)
任务
-
识别源代码的语法结构:将词汇单位序列转换为语法树(Parse Tree),以反映源代码的语法结构。
技术
-
上下文无关文法(Context-Free Grammar, CFG):用于描述源代码的语法结构。
-
递归下降解析器(Recursive Descent Parser):一种自顶向下的解析方法。
-
LL(1) 解析器:一种简单的自顶向下解析器。
-
LR(k) 解析器:一种自底向上的解析器,如 LR(0), SLR(1), LR(1), LALR(1) 等。
-
预测解析器(Predictive Parser):一种特殊的递归下降解析器。
3. 语义分析(Semantic Analysis)
任务
-
验证源代码的语义正确性:确保源代码符合语言的语义规则,如类型检查、作用域管理、符号表构建等。
-
生成中间代码:在某些编译器中,语义分析阶段还会生成中间代码。(可移植性)
技术
-
符号表(Symbol Table):用于记录源代码中的符号(如变量、函数等)及其属性。
-
类型检查:确保类型的一致性和正确性。
-
作用域分析:确保变量和函数的作用域正确。
4. 优化(Optimization)
任务
-
改进中间代码:通过优化技术改进中间代码,提高生成的目标代码的质量,如减少执行时间、减小代码大小等。
技术
-
循环优化:例如循环展开、循环不变代码外提。
-
常量传播:将常量值传播到所有可能的位置。
-
死代码消除:删除永远不会被执行的代码。
-
公共子表达式消除(Common Subexpression Elimination, CSE):删除重复的计算。
-
局部优化:如重排序、内联展开等。
-
全局优化:如循环优化、内联展开等。
-
后缀式和三地址码,三元式,树都是常用的中间代码
5. 代码生成(Code Generation)
任务
-
生成目标代码:将中间代码转换为目标机器语言或汇编语言。
技术
-
寄存器分配:为变量分配寄存器,减少内存访问。
-
调度(Scheduling):优化指令顺序,减少流水线停顿。
-
寻址模式选择:选择最优的寻址模式。
-
目标代码格式:生成符合目标平台要求的代码格式。
6. 目标代码优化(Target-Dependent Optimization)
任务
-
针对特定平台的优化:对生成的目标代码进行进一步优化,以适应特定的硬件平台。
技术
-
硬件特性利用:如SIMD指令集、特定的CPU架构特性等。
-
延迟分支优化:处理延迟分支指令
7. 出错处理
任务
出错处理的任务是在编译过程中检测并报告错误,并尽可能地恢复编译流程,以便可以继续检测后续代码中的错误。
主要任务
-
检测错误:识别源代码中的语法错误、语义错误等。
-
报告错误:向用户提供清晰的错误信息,包括错误位置、错误类型等。
-
恢复编译:尝试恢复编译流程,以便可以继续检测后续代码中的错误。
8. 符号表管理
任务
符号表管理的任务是在编译过程中维护一个符号表,记录源代码中所有的标识符(如变量、函数、类型等)及其属性(如类型、作用域、偏移量等)。
主要任务
-
符号声明:记录每个标识符的声明信息。
-
符号使用:在使用标识符时查找相应的记录,并验证其使用是否符合语言规范。
-
作用域管理:维护不同作用域内的符号,并确保作用域正确性。
技术与方法
-
符号表数据结构:通常使用哈希表、树或其他数据结构来实现符号表。
-
作用域栈:使用栈来管理作用域,每当进入一个新的作用域时,就在栈顶添加一个新的作用域表;退出作用域时,就从栈顶弹出该作用域表。
-
符号表条目:每个条目包含标识符的名字、类型、作用域等信息。
-
符号表操作:实现插入、查找、删除等操作,以维护符号表的正确性。
文法分析
补充:
1.大多数文法都可以用上下文无关文法描述
2.NFA输入一个字符可以转移到多个不同的状态,DFA只能转移到一种状态
3.选择运算符 | 表示“或”,即在正规式中表示两个或多个选项中的任意一个。
(a(b | c):表示一个字符串,该字符串以 a 开始,紧接着是一个 b 或者 c。)
4.闭包运算符 * 表示“零次或多次重复”,即在正规式中表示前面的元素可以重复零次或多次。
((ab)*:表示一个字符串,该字符串由 ab 的零次或多次重复组成。)
5.正规式是一种用来表示正规语言的形式化方法。正规式由一组基本元素和运算符组成,用来描述一组字符串集合。
6.正规集是由正规式所表示的语言。也就是说,正规集是一个可以用正规式描述的字符串集合。
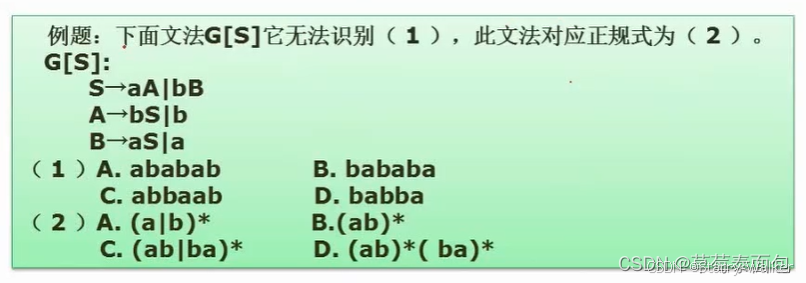
第四章-操作系统
补充点:
1.windowXP系统支持FAT,FAT32或NTFS文件系统。
2.只有在对磁盘进行清理或者碎片整理的时候不会损坏数据
3.Linux系统的根目录用/表示。
4.Linux系统中更改文件权限用chmod指令
进程管理
补充点:
1.最小不发生死锁问题:n(i-1)+1,n为进程个数,i为每个进程需要的资源数
2.如何根据前趋图写出对应的PV操作:箭头表示执行完当前进程要释放的资源(Sn),某进程执行前需要进行P操作检查资源是否上锁,执行完后释放资源。
3.根据逻辑地址->物理地址:逻辑大小/页面大小-物理块号,块内地址=逻辑大小/页面大小的余数,物理地址=物理块号+块内地址(+代表拼接)。
4.信号量的含义:信号量是一个整型变量,它可以用来控制多个进程对共享资源的访问。信号量的值大于等于0表示可用资源的数量,小于0则表示有多少个进程正在等待该资源。 初始值根据题目的含义而定。
5.根据资源图判定是否是阻塞节点:注意R资源的总量,P->R是向R请求资源,P<-R表示进程从R处获取了资源,往往是请求失败导致阻塞。
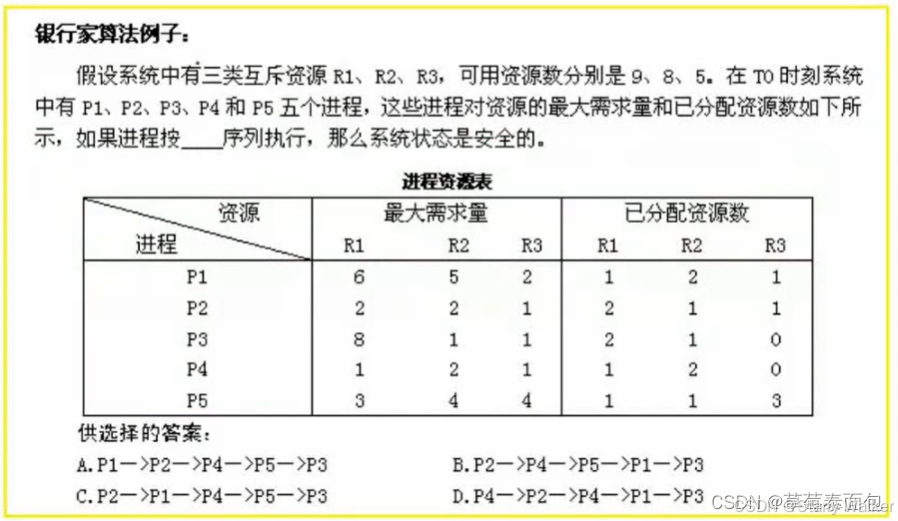
银行家算法
解决该类问题,首先将系统所剩资源数计算出来,然后将每个进程还差的资源数计算出来,进行比较之后,将系统资源分配给差的最少的进程,进而让其释放资源,然后进行下一个所需资源较少的进程的分配,由此将进程执行的顺序计算出来
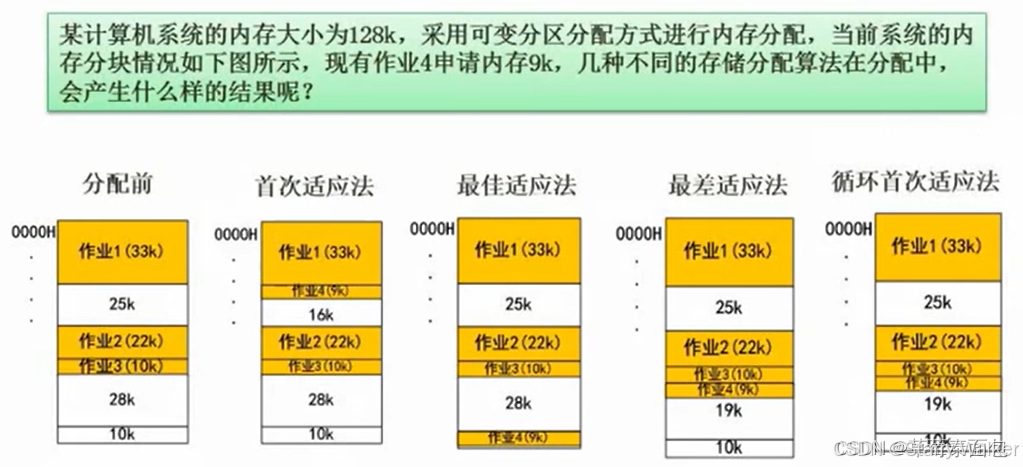
存储管理
首次适应法
首次适应法会把即将执行的作业安排在第一个能够容纳它的空间
最佳适应法
该算法会把即将执行的作业安排在内存空间与它最接近的空间进行存放,如该例子中,作业4占据空间9k,通过该算法,计算机就将其存放在了空间为10的地址中;由于在每次存放作业以后内存空间剩余量极低,长期以后该算法会造成内存空间碎片化,降低内存地址的利用率
最差适应法
该算法能够解决内存空间碎片化的问题,如图所示:该算法优先将作业存放至内存空间最大的地址.
循环首次适应法
该算法是将空闲的区域连成环状,将作业在环状区域内顺次进行分配(从第二个空闲区域开始分配)
页式存储:
2.概念:把用户程序分成等分大小的n个“页”(并将其编号),再在地址空间中以nk为基数划分等大小的块(同样将其编号,块号又称页帧号),运行用户程序时不再将整个程序进行运行,而是根据需要分批次将页调入到块中运行,而页和块之间的对应关系用页表来记录
3.页式存储组织的优缺点:优点:利用率高,碎片小,分配及管理简单
缺点:增加了系统开销(系统每次读取程序都需要先读取页表将其定位,再进行程序的读取,所以至少两次访问内存);可能产生抖动现象
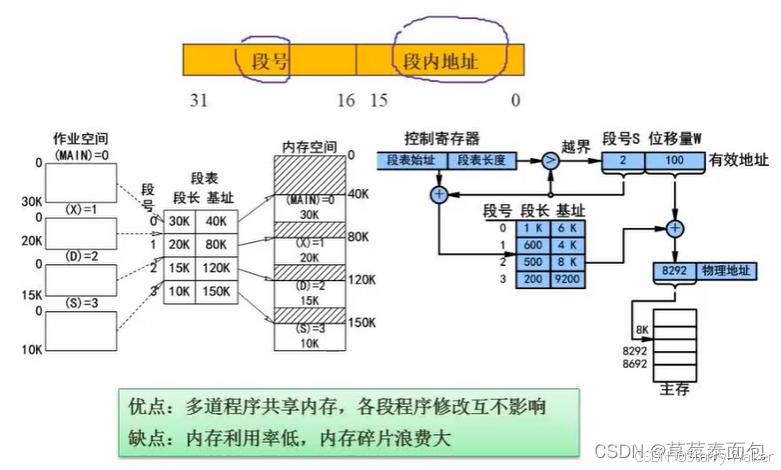
段式存储
1.概念:按逻辑结构进行内存的划分,划分为n个段,每一个段的大小无要求,可以相等也可以不等,包括段号和段内地址,例如:可以将main主函数作为一个段,然后将第一个子函数作为一个段,然后将第二个子函数作为一个段…
段页存储
段页式存储是结合了段式和页式的一种存储组织,将内存先分段,再分页;
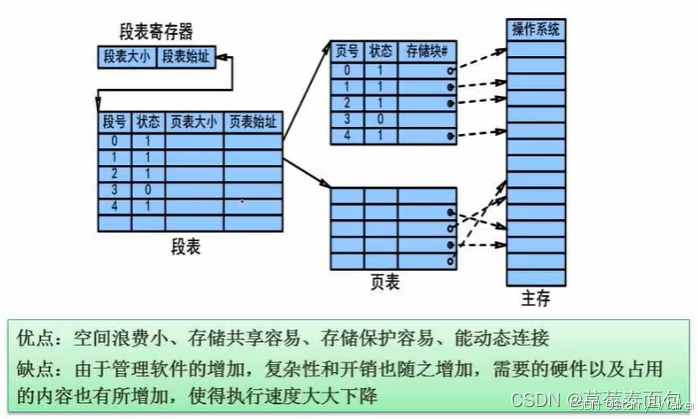
优点:空间浪费小,存储共享容易,存储保护容易,能够动态连接;缺点:由于管理软件的增加,复杂性和开销也随之增加,需要的硬件以及占用的内容也有所增加,使得执行速度大大下降(程序在执行时要先查段表,再查页表,使得系统资源消耗增加)
页面置换算法
快表:由cache组成,减少直接访问内存的时间
(3)先进先出算法(FIFO):即淘汰时按照之前执行的先后顺序进行淘汰,有可能产生“抖动”(抖动即:把经常用到的页置换出去,要用的时候发现没有内存了,造成进程中断)。例如,432143543215用3个页面,比4个缺页要少
(4)最近最少使用算法(LRU):即在保证最近使用的页面不被中断的情况下,将最少使用的页面淘汰,不会产生“抖动”
文件与索引
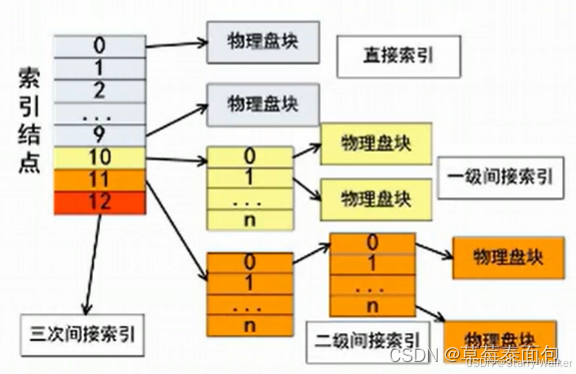
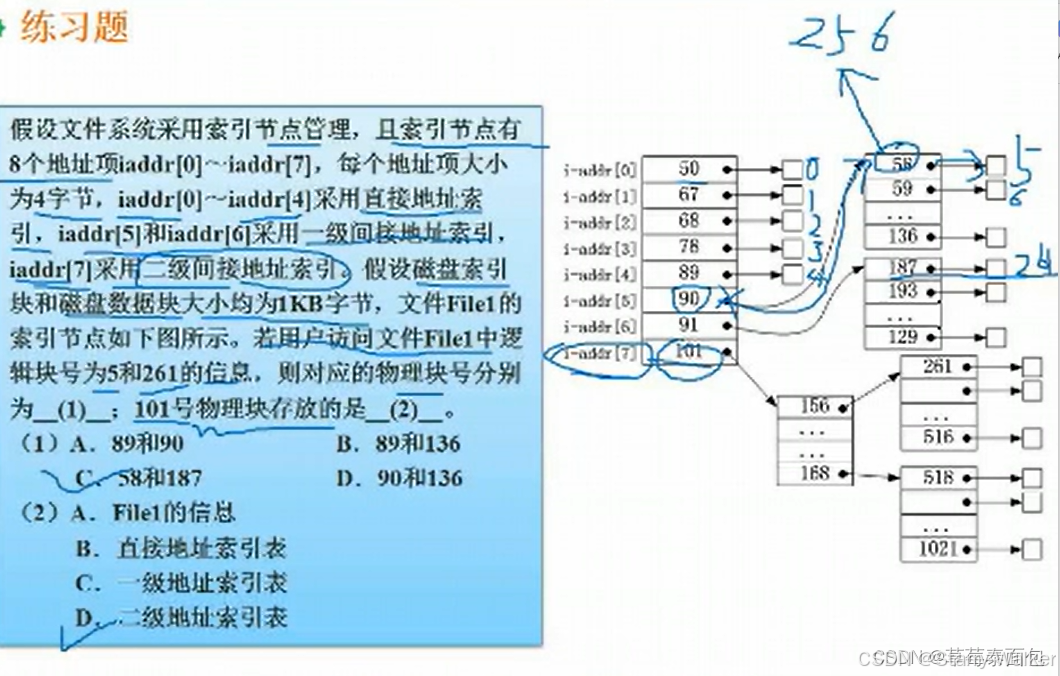
索引一般会有13个节点(默认情况下),从0开始编号,其中索引0到9这十个索引称为直接索引,直接对应物理盘块,每一个物理盘块都对应了索引文件的内容,而索引10则称为间接索引,里面只存储地址,如一个物理盘块的地址大小为4个字节,而一个物理盘块的大小为4k,则4k\4字节等于1024,代表着1024个物理盘块的地址,因此该索引内可以存储的文件大小为4k1024;该10号索引称之为一级间接索引;索引11则是二级间接索引,即索引的内容还是索引,再索引的内容才是物理盘块,二级简介索引存储的文件大小即为:4k1024*1024;虽然分级越多存储的内容越多,但相应的,效率也会更低
1 Byte (B) = 1 字节
1 Byte (字节) = 8 bits bits 通常用于衡量数据传输速度(如网络速度),而 Bytes 更多地用于存储容量。
计算机中64位字长=一次可以处理8B的数据
文件存储管理
重点:位视图法
.概念:将所有存储区域分成无数个物理块,然后以1表示被占用,0表示空闲,将所有空间进行标记(物理块号/系统字长)=哪个字描述


Linux系统的常用命令
attrib:声明
modify:修改
chmod:修改文件权限
change:改变
第五章-软件工程基础
软件开发模型
-
瀑布模型
特征:线性顺序开发,不允许回溯。适用场景:需求明确、变更少的传统项目。
-
原型/演化/增量模型
特征:通过多个原型逐步完善系统。适用场景:需求不明确、需频繁用户反馈的项目。
-
螺旋模型
特征:强调风险管理,迭代开发。适用场景:需求复杂且风险高的项目。
-
V模型
特征:每个阶段都有对应的测试活动。适用场景:质量要求高、需严格测试的系统。
-
喷泉/RAD快速开发模型
特征:快速迭代开发,支持对象导向。适用场景:需求明确、要求快速交付的项目。
-
构件组装模型(CBSD)
特征:基于已有构件组装系统。适用场景:有大量成熟组件的模块化系统。
-
统一过程模型(UP/RUP)
特征:以用例为核心,采用迭代开发。适用场景:大型复杂的企业级系统。
软件开发方法
敏捷开发
1.极限编程(XP)特点:测试先行、结对编程、集体代码所有制、持续集成(可以按日甚至按小时为客户提供可运行的版本)、每周工作40个小时
2.并列争球法特点:使用迭代的方法,其中把每三十天一次的迭代成为一个冲刺,并按需求的优先级来实现产品,多个自组织和自治小组递增实现产品,并通过简短的日常情况会议进行协调
3.水晶法特点:该方法认为每一个不同的项目都需要一套不同的策略、约定和方法论
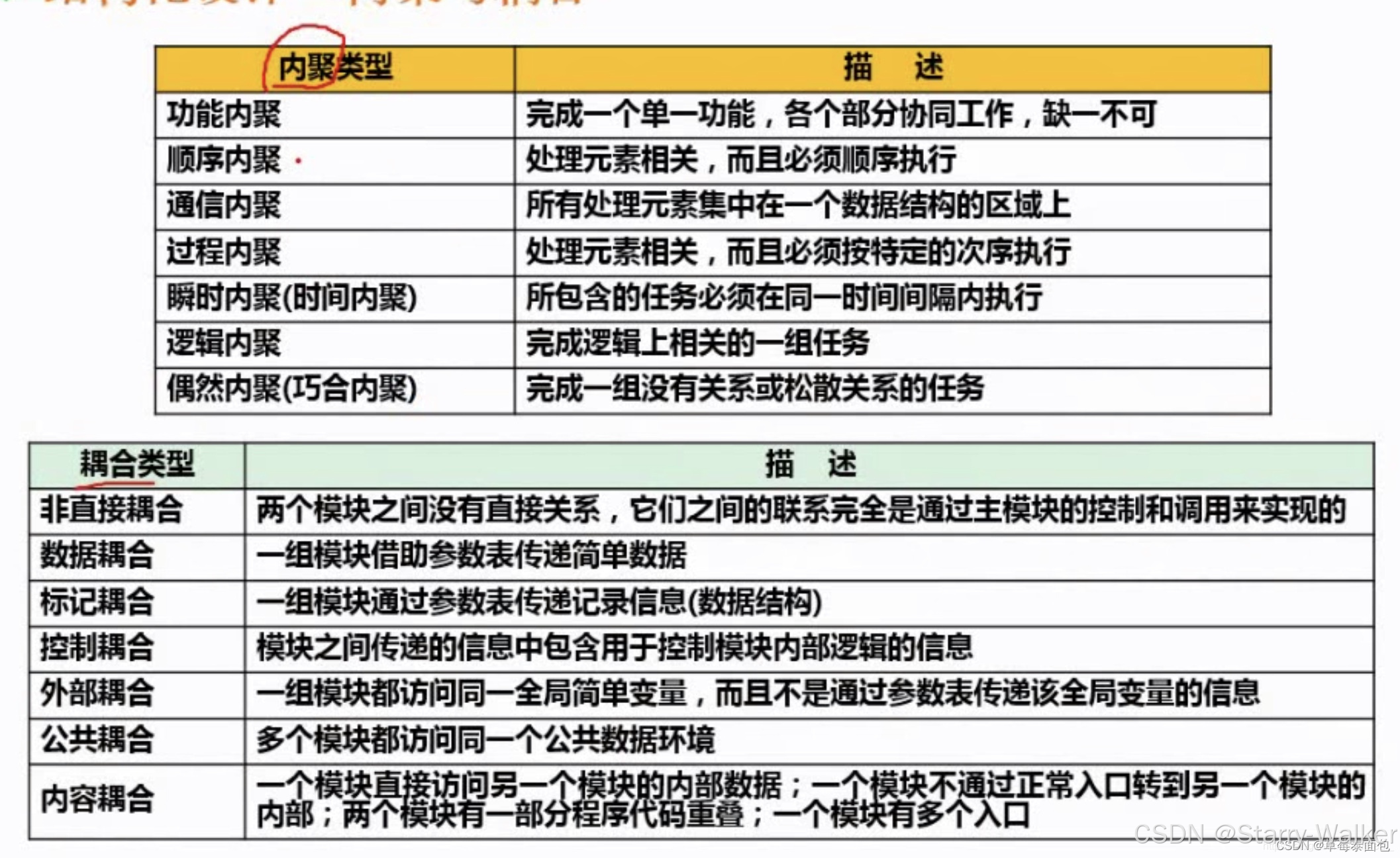
内聚与耦合
第六章-数据库系统
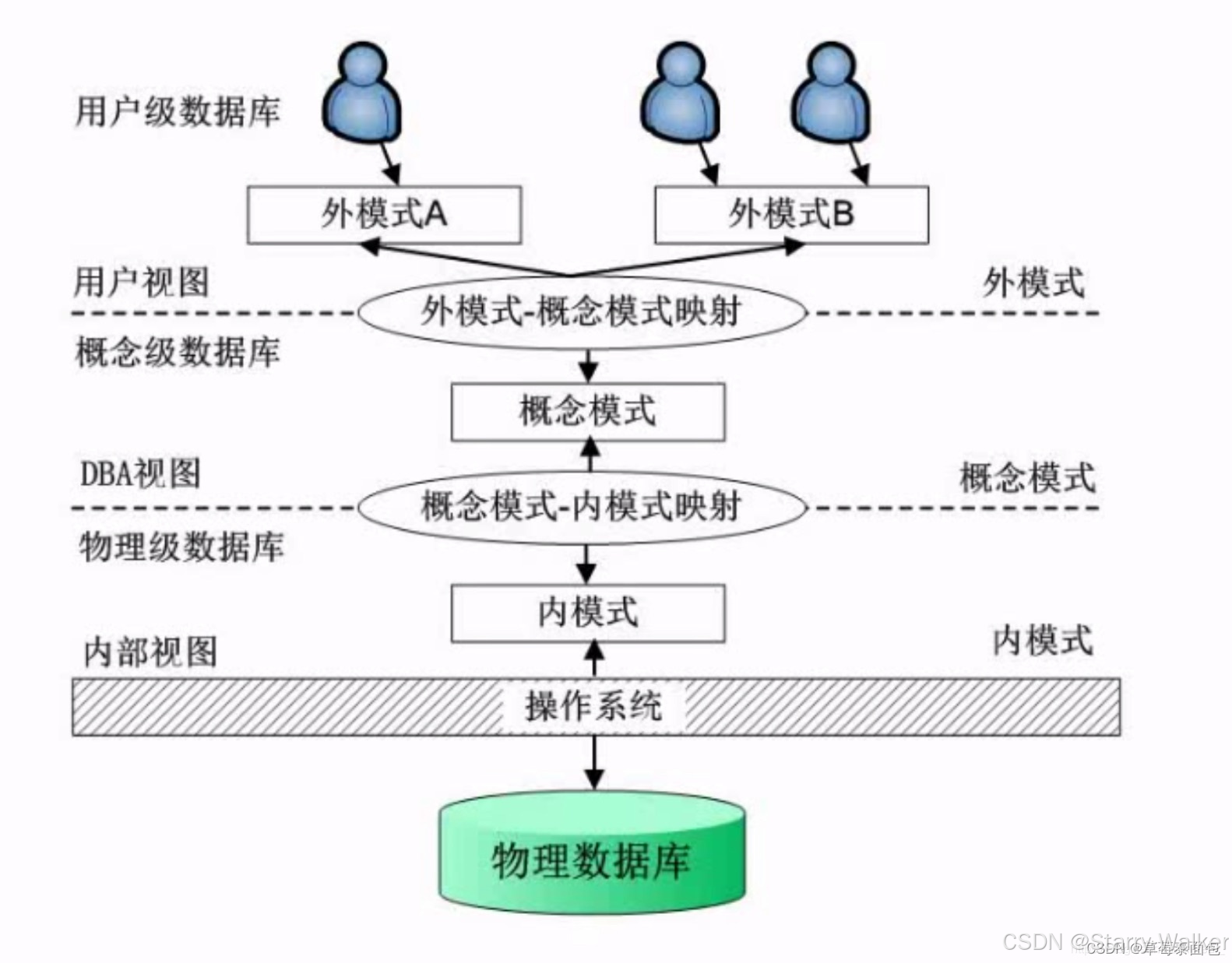
三级模式-两级映射
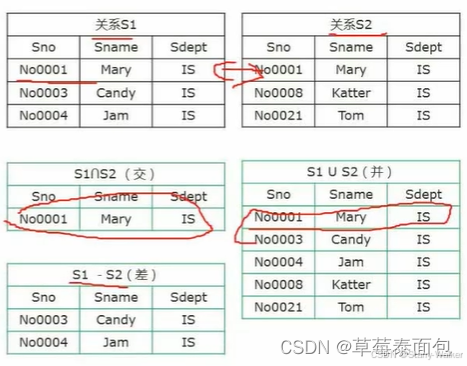
关系代数(必考)
各个运算的表示符号
并(∪)、差(-)、笛卡尔积(×)、投影(π)、选择(σ)
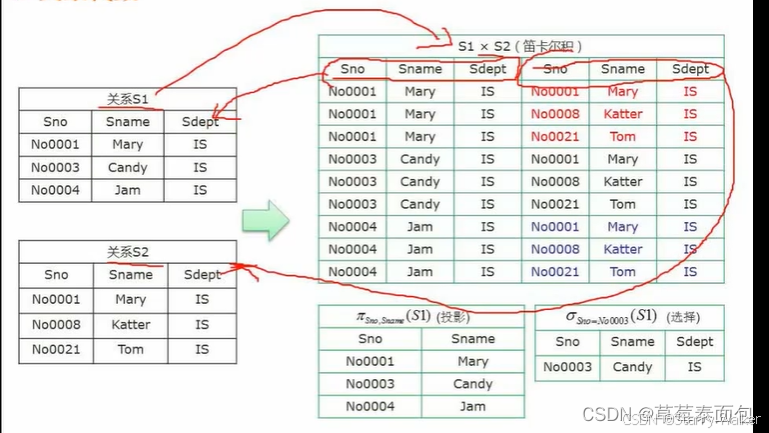
解释:
笛卡尔积
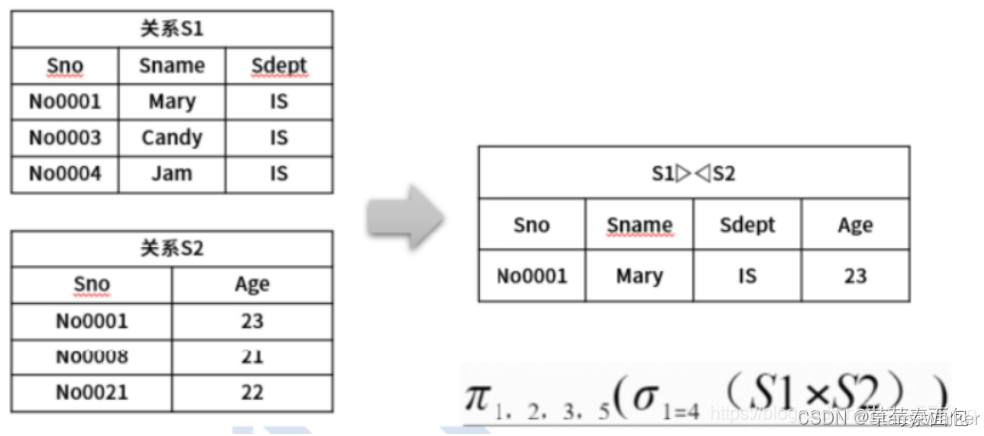
笛卡尔积中若AXB,则将A第一行记录写下,然后将其重复记录三次,然后将B的三行记录与A重写的记录一一对应的写下,然后对A的第二行记录进行同样的重写,以及将B对应的记录重写…
投影
概念:该操作即将所选的“列”记录下来
图示选择Sno、Sname,那么Sno实际是重复的No001 003 004,Sname同理,所以只有三行
选择
概念:该操作将所选的“行”记录下来
选择是根据某些条件对关系做水平切割,对元组行的选择列出如上述中Sn0-Soooo3(S1),是指从S1中选择Sno字段为Soooo3的数据。
自然联接
概念:自然连接的结果以左侧关系为主,右侧关系去除重复列,如R(A,B,C,D,E)和E(C,D,E,F)进行自然连接的结果为:(A,B,R.C,R.D,R.E,F)
规范化理论
函数依赖:即函数关系,如学号对应姓名,姓名可以重复,但学号是唯一的,且唯一的学号对应相应了可重复的姓名
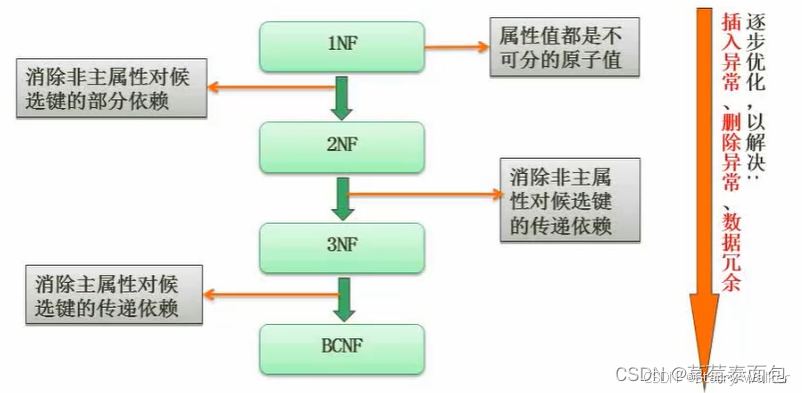
X->Y
部分函数依赖(部分依赖):主键是两个属性的组合键,若主键中的一部分可以确定某个属性,则为部分函数依赖
通过(学号,课程号)的组合键,可以通过主键的一部分即学号确定姓名属性
传递函数依赖(传递依赖):即:若A可以确定B,B可以确定C,则A可以确定C(注意:B不能确定A,因为此时二者即为等价)
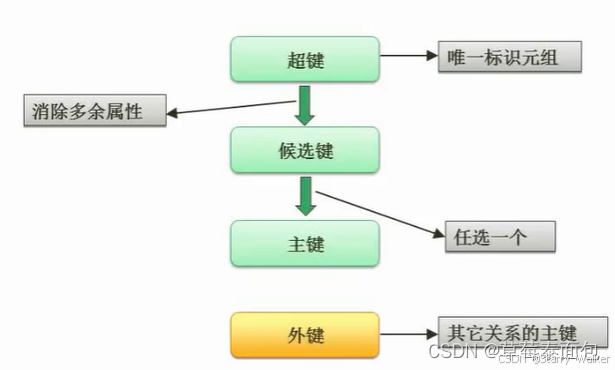
候选键:找入度为0的属性
主属性即为构成候选键的属性
范式
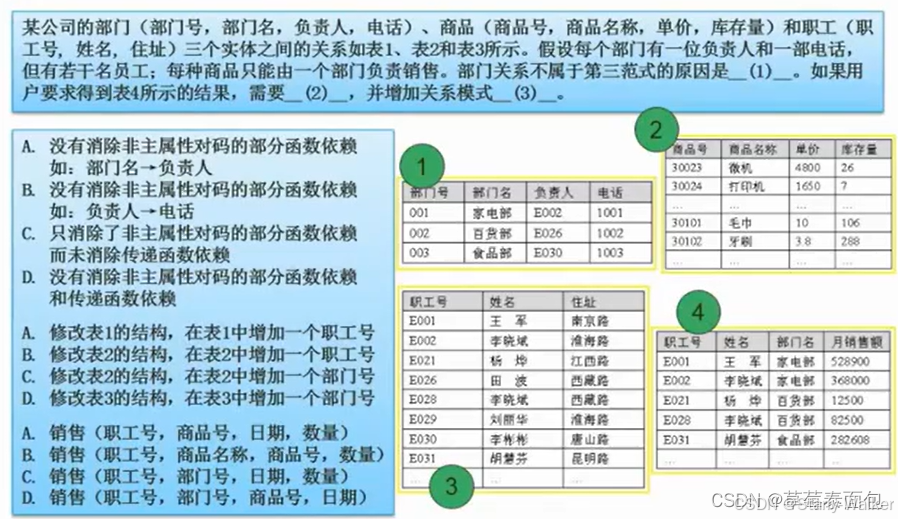
答案:CDA
存在部分函数依赖,如部门名->负责人
数据库安全
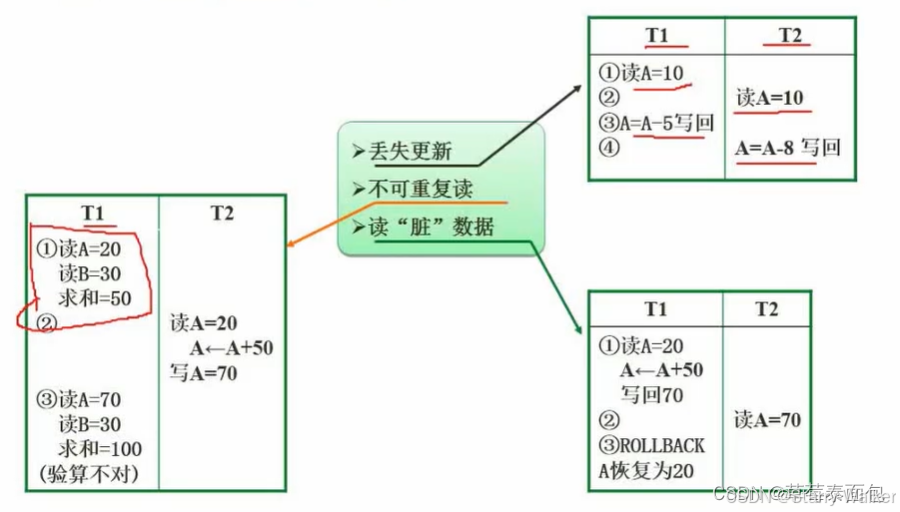
1.丢失更新:
在这两个事务中,T1执行的结果为5,T2执行的结果为2,我们想要得到的是A减去5再减去8的结果,但最终结果为2,因为下一个执行的事务结果会覆盖上一个事务执行的结果
2.不可重复读:
在T1运算中,求A与B的和时,为了提高准确率,程序会再次进行验算,但在第一次运算和第二次运算的间隙,将进行T2运算,T2运算的结果会将A与B的值进行覆盖,这将会产生死锁问题
3.读“脏”数据:
脏数据只是一个临时值,不是真正的数据,不是我们执行过程中真的产生的数据
值70是计算过程产生的数据,属于临时数据,该数据被恢复为了20,使得T2操作将会出错

第七章-计算机网络
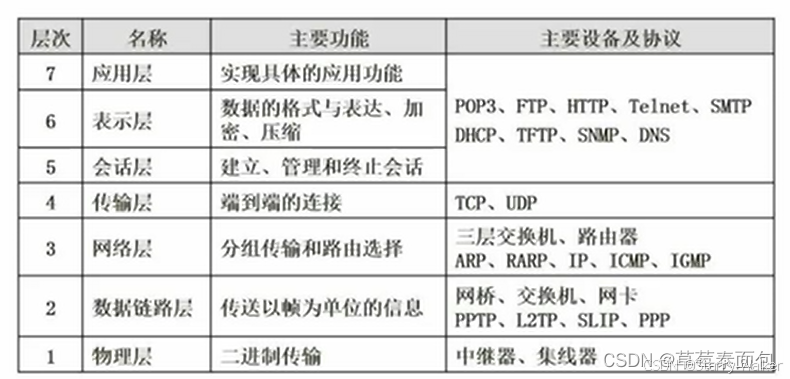
七层模型
网络协议与技术标准
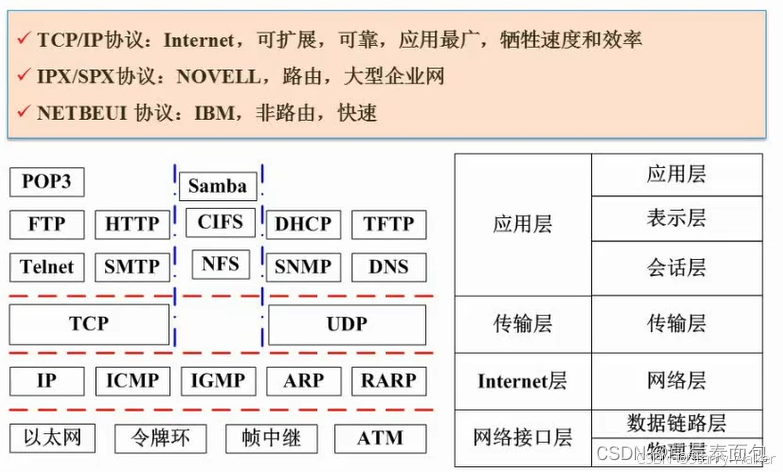
(1)ICMP:称之为因特网的控制协议
用ping检测网络是否通畅
(2)ARP:是地址解析协议(即IP转MAC)
(3)RARP:是反向地址解析协议(MC转IP)
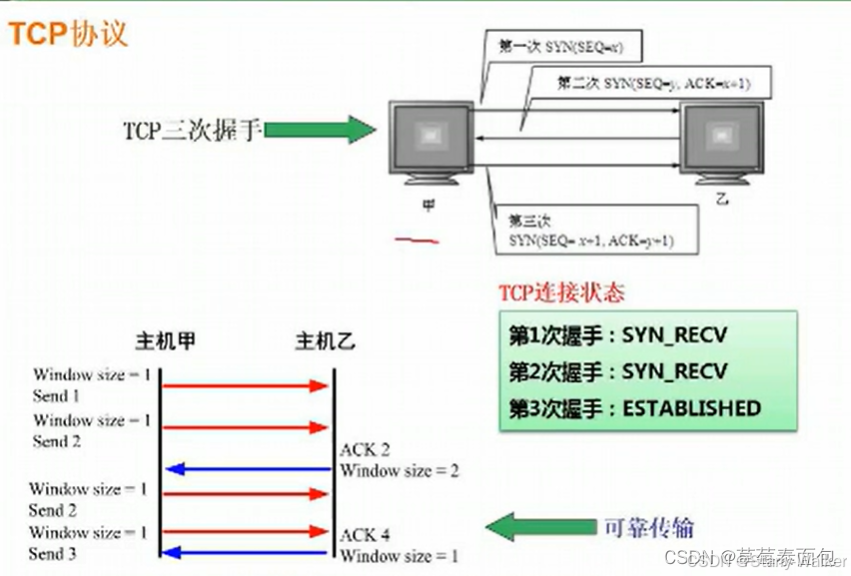
(4)TCP:被称为可靠的协议,因其在通信时会建立连接(通过三次握手来建立连接,即A与B三次互发信息),且在传输信息时有验证机制,以验证数据包是否顺利传输,其上方的FTP,Telnet等协议都是建立在TCP基础上的
(5)UDP:称为不可靠的协议,因其在建立时不会建立连接,因其在传输数据时,会直接将数据发送给另一方
(6)DHCP:用来做动态的IP地址的分配工作
(7)TFTP:是小文件传输协议
(8)SNMP:是简单网络管理协议
(9)DNS:是域名解析协议
(10)位于中间部分的Samba协议、CIFS协议、NFS协议则是可基于两种基本协议
(11)TCP和UDP均提供了端口寻址能力
(12)MIML:是一个互联网标准,扩展了电子邮箱标准,使其能够支持电子邮箱的使用
(13)PGP:是一套用于信息加密、验证的应用程序,可用于加密电子邮件内容
(14)Https:是HTTP的安全版,它是在HTTP的基础上加上了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密
(15)POP3 SMTP是邮件传输协议
(16)Samba(可跨平台)、CIFS、NFS是文件共享协议
常用的端口号
使用TCP协议常见端口主要有以下几种
1)FTP——文件传输协议——21
2)Telnet——远程登陆协议——23
3)SMTP——简单邮件传送协议——25
4)POP3——接收邮件——110
5)HTTP——超文本传输协议——80
使用UDP协议常见端口主要有以下几种:
1)DNS——域名解析服务——53
2)SNMP——简单网络管理协议——161
3)TFTP——简单文件传输的协议——69
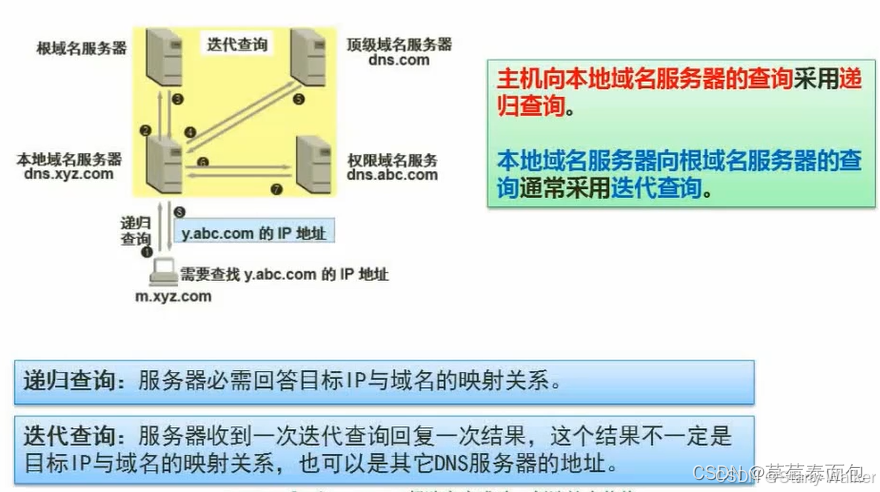
1)主机向本地域名服务器的查询一般都是采用递归查询。
(2)本地域名服务器向根域名服务器的查询采用迭代查询。

、
IP地址与子网划分
在IP地址发展的第一阶段中,IPv4地址被划分为ABC三个类别:
在A类地址中,第一个字节表示网络号,后三个字节用来表示主机号,A类地址包含2^24-2台主机,减掉的2是全零的地址和全1的地址,因为全零代表着一个网络的地址而非主机,全1则代表网络中的广播地址,且其首字节的首个位为0,包含的网络号是从0 ~ 127;
B类地址则是主机号与网络号1:1,第一、二个字节表示网络号,三、四个字节用来表示主机号,网络号的范围是128~191;主机数是2^16-2
C类地址则是网络号与主机号为1:3,第一、二、三个字节表示网络号,四个字节用来表示主机号网络号的范围是192~223;主机数是2^8-2
IP地址发展的第二阶段则是将ABC类IP地址各自再划分为数个范围,划分子网;(网络号:子网号:主机号)
IP地址发展的第三阶段则是采用了无分类编址,如该表示方式:如172.18.129.0/24;”/“号后面的24表示“前24个位都是网络号
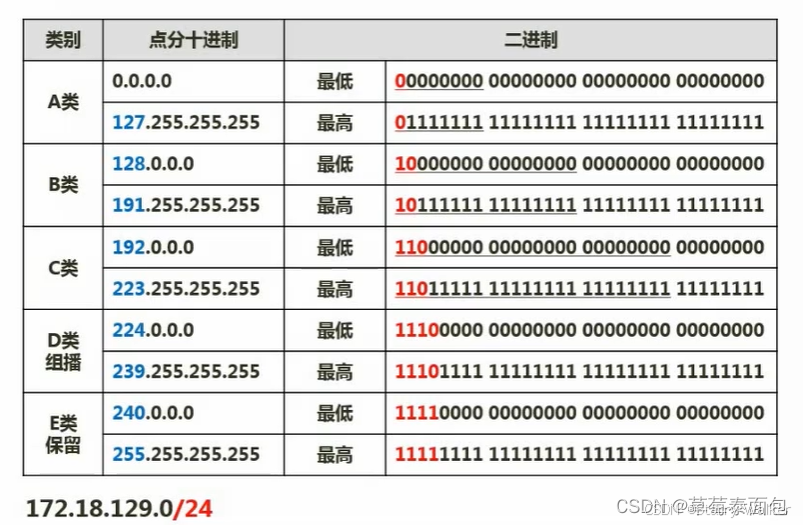

C类子网是24位网络号,12位自由分配,换成无编址-24-20=4位自由分配的子网号)

子网划分
1.子网掩码的概念:将一个IP地址划分为n个子网或者将n个子网合并都需要利用子网掩码,用于区分一个IP地址哪些部分是网络号,哪些部分是主机号,为1则对应网络号,为0则对应主机号
2.子网划分的步骤:首先将十进制划分为二进制数,再将网络号的二进制数全部转换为1,再取主机号的二进制数,取二进制数的数量k与子网划分的个数N满足:2^k>=N;再将取到的主机号的二进制数转换为1,最终将该转换过的IP地址二进制数化为十进制数即为子网掩码(除了主机号之外的二进制全取1)

划分27个子网,2^5>27,所以取5个bit位做子网号

2^k-2>700求出k=10
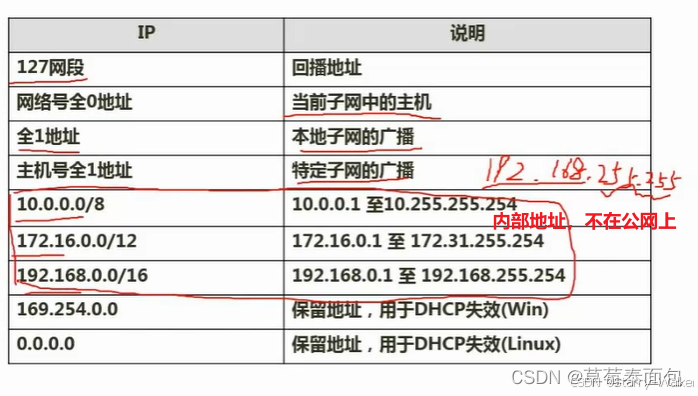
第八章-多媒体技术
音频与图像
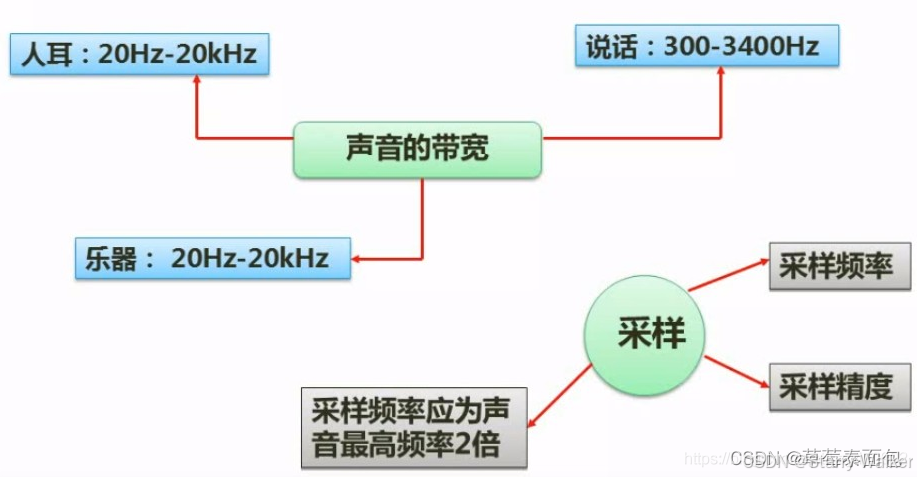
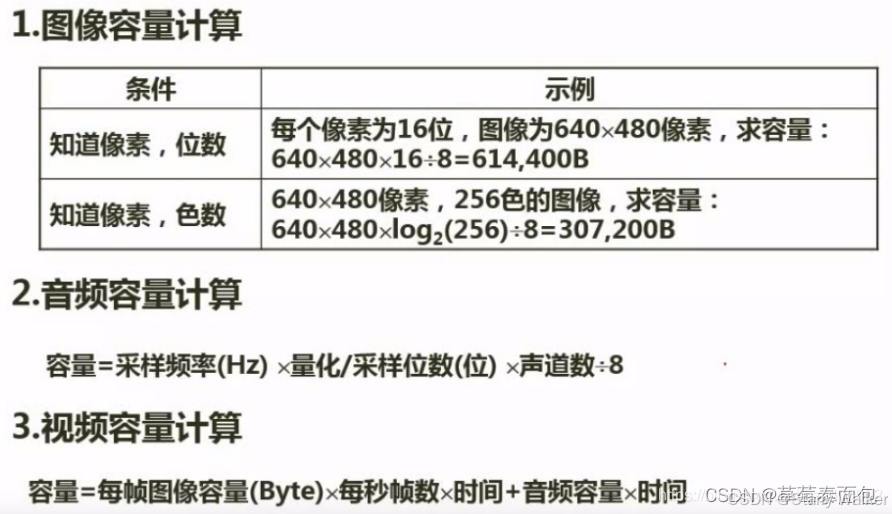
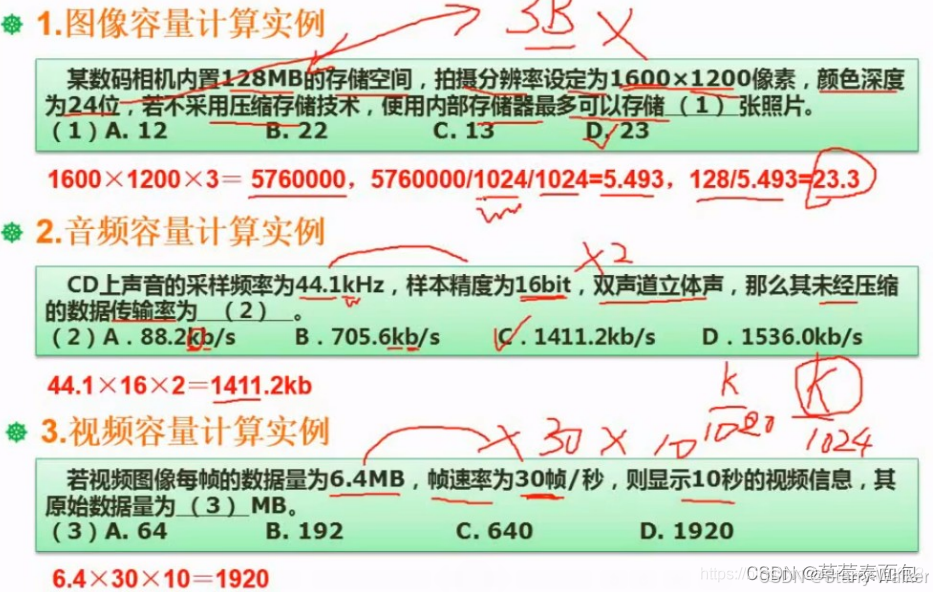
DPI: 像素/英寸,图像分辨率的单位,表示每英寸多少像素点,即组成一幅图的像素密度。
显示分辨率: 显示器上能够显示出的像素点数目,即显示器在横向和纵向上能够显示出的像素点数目。
水平分辨率:显示器水平方向上能够显示的像素点数目。
垂直分辨率:显示器在垂直方向上显示的像素数目。
第九章-软件法律法规
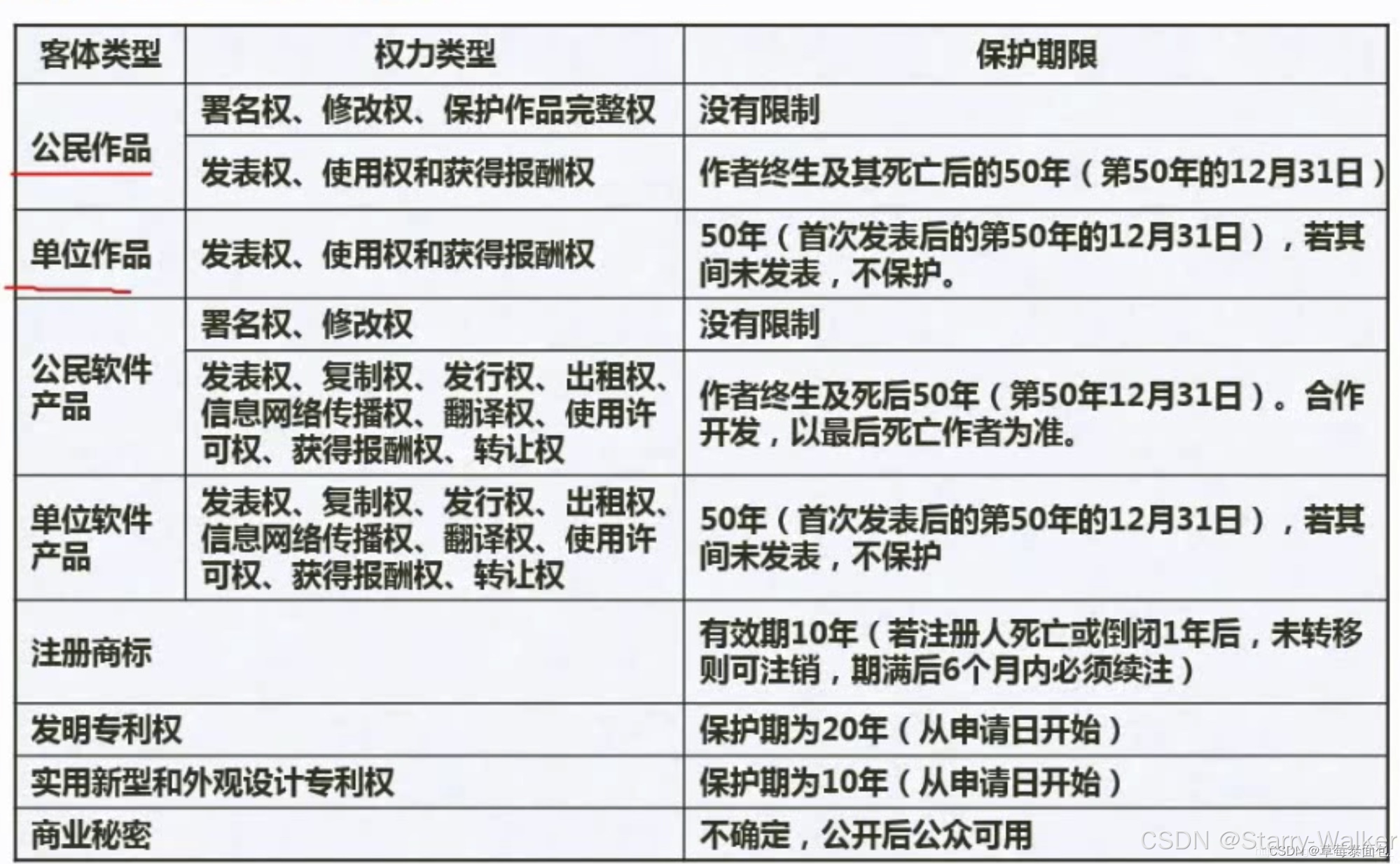
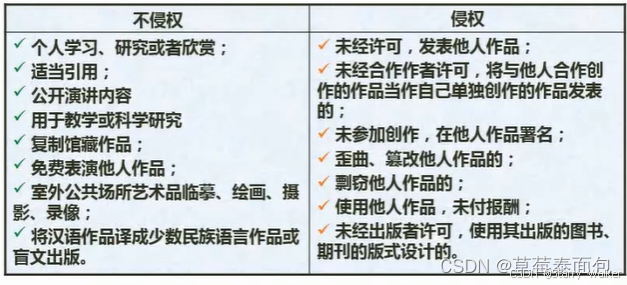
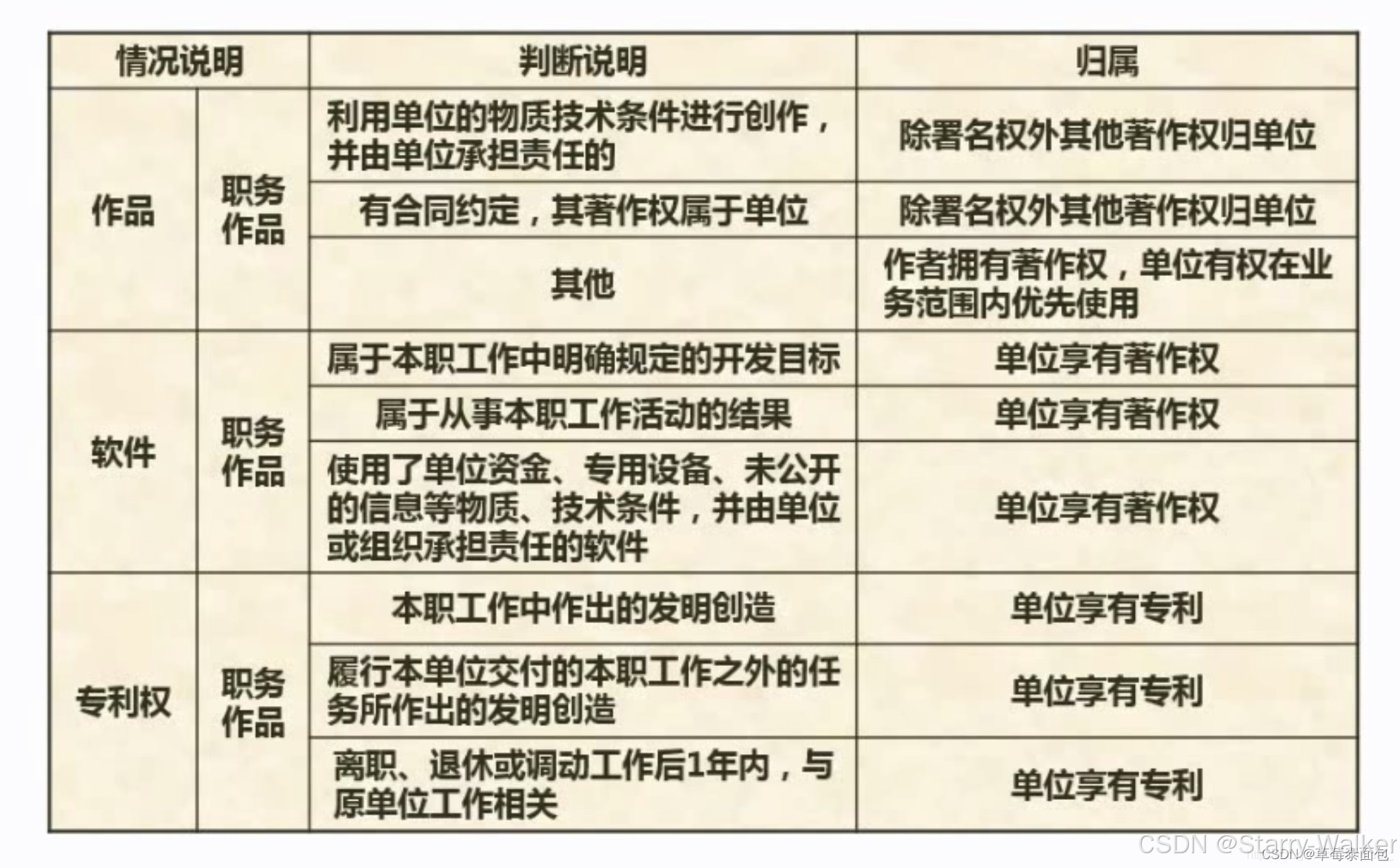
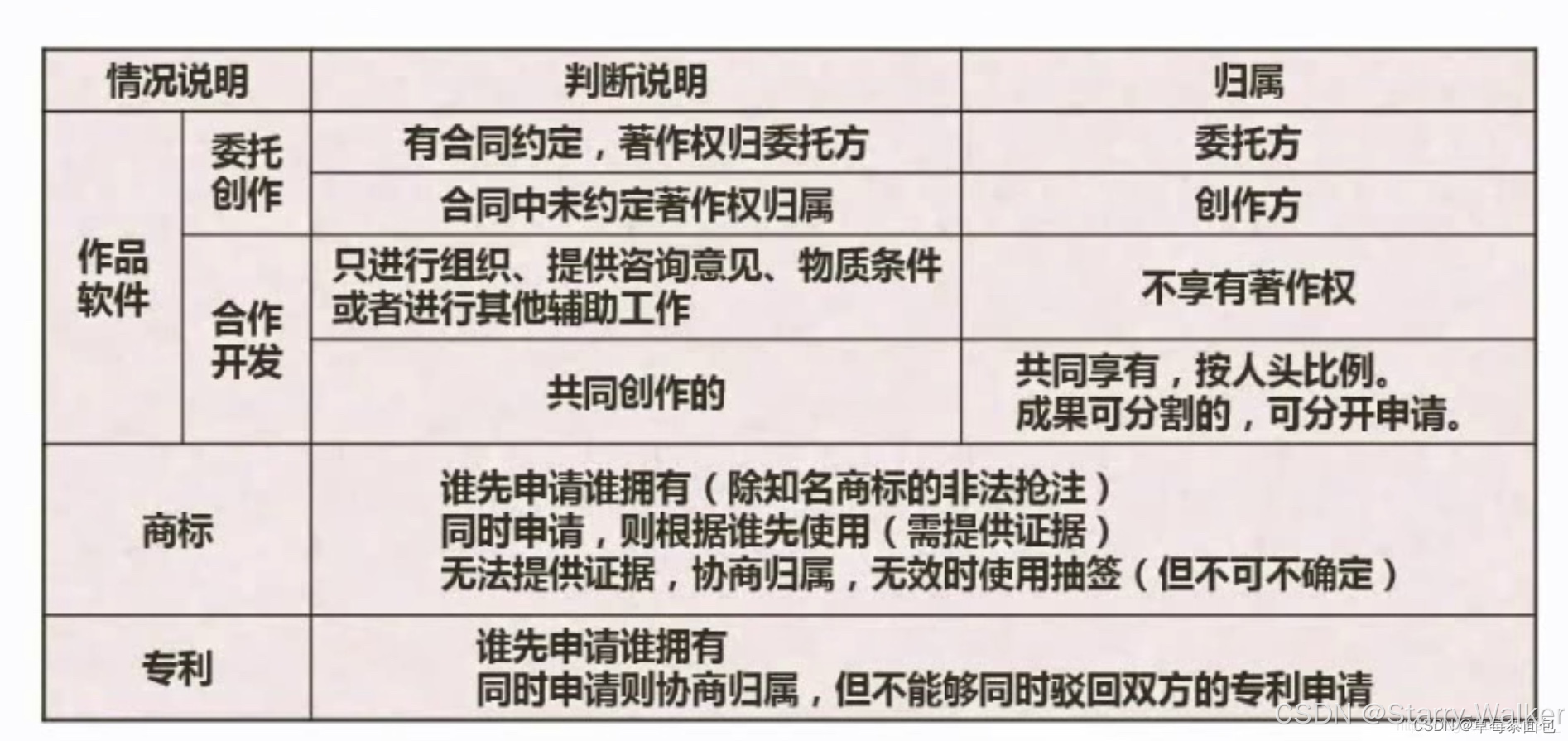
知识产权人确定
工作特殊-署名权自己属有,其他归所在公司
委托看合同,默认归自己,专利和商标看谁先,同时则协商

下午题
数据流图基础

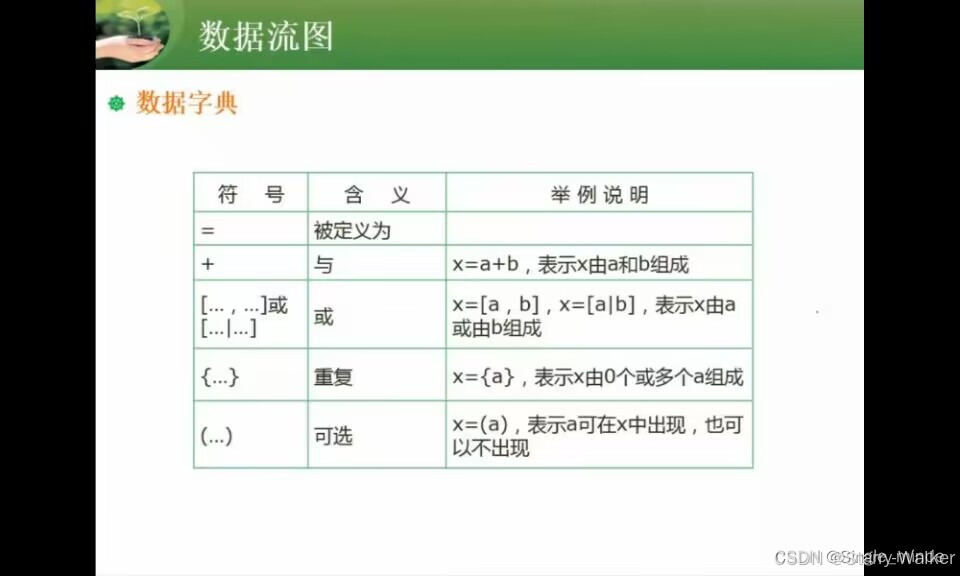
数据流:名词,反应含义。
加工:做处理。
数据存储:表、文件。
外部实体:人员、组织。
解题技巧
1.读题先画出涉及到的名词实体(填实体名词-最好是题干中有的,不能自己造词),同时划出每个实体之间或数据存储与实体间的数据流关系。
2.再确定各个实体之间的 联系(数量对应)
3.涉及到写数据存储--xx表(一定要看和他对应的实体,一般和对应的实体以及数据流的名词相关。
4.根据之前划出的数据流关系,对照数据流图中的联系,补足。(往往是实体与数据存储之间的缺失数据流)可以采用分治法-分子图寻找
5.判断数据流的组成:首先看数据流的两端的实体-返回题干找到对应的功能点总结
ER图与数据库设计
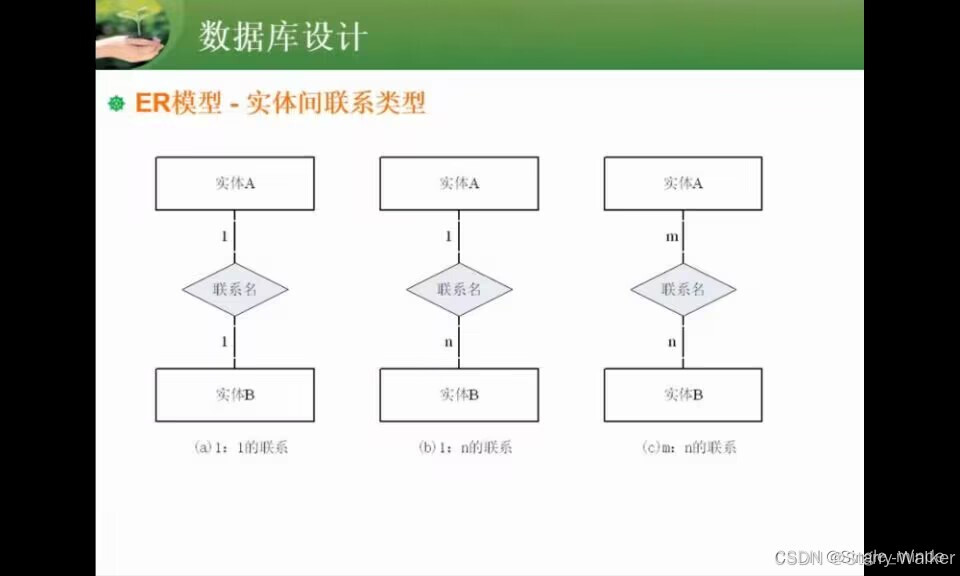
方形-实体 椭圆-属性 菱形-关系
解题技巧
解题流程与技巧:
1.读题-划出实体,标出实体之间数量的对应关系和操作关系,以及每个实体该有的属性
2.若要新增实体-转为关系模式(注意给出实体之间与之前实体间的联系-外键和隐藏属性)
主键约束和外键约束的写法如下
UML建模图(结合设计模式)
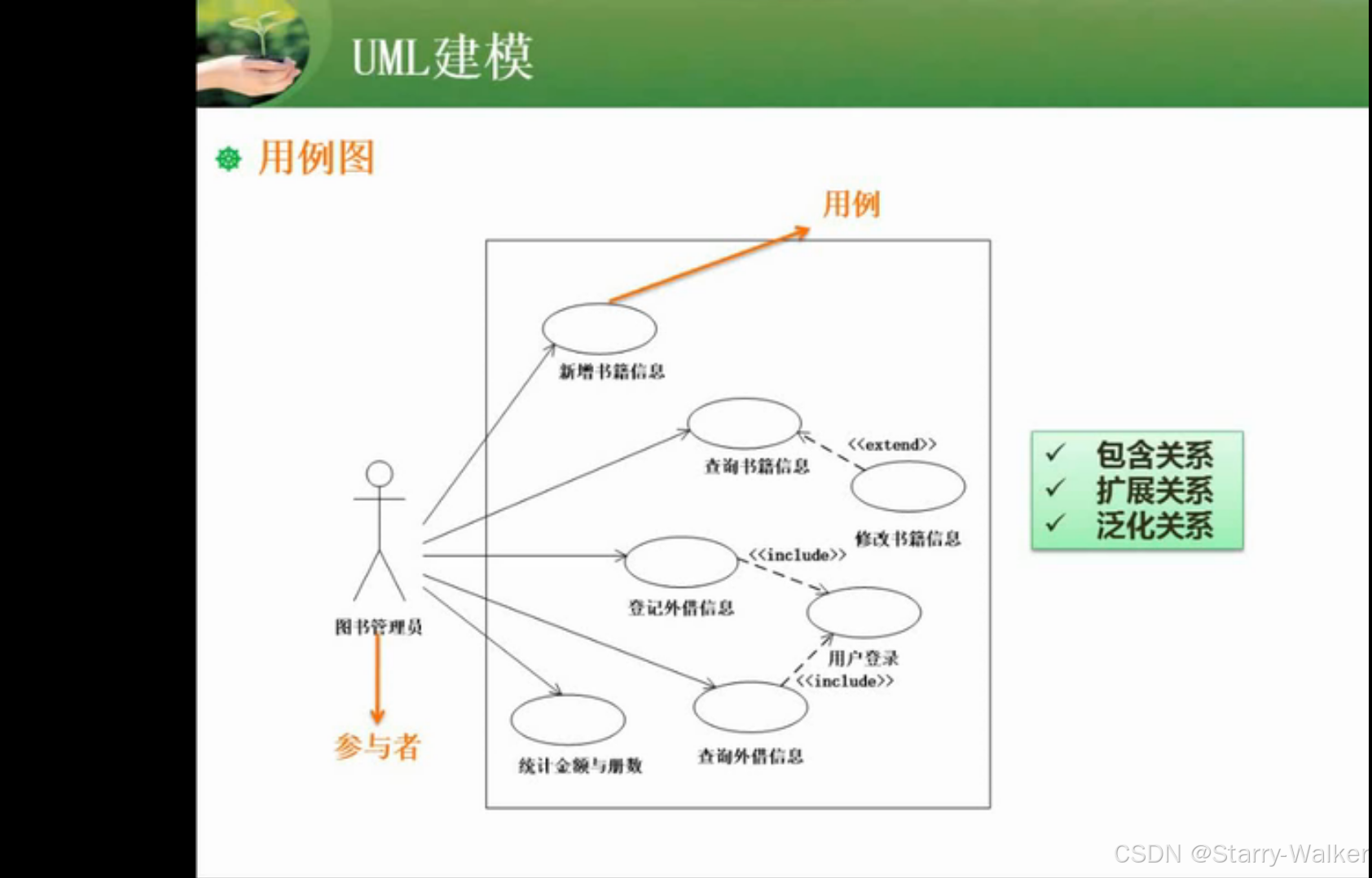
用例图(注意包含和扩展的区别)
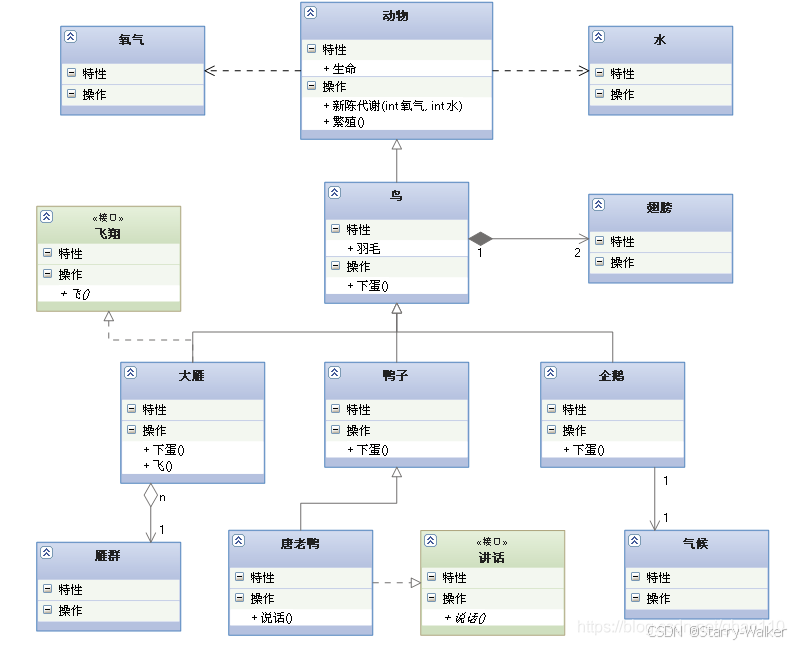
类图(一般是根据文字还原实体类)
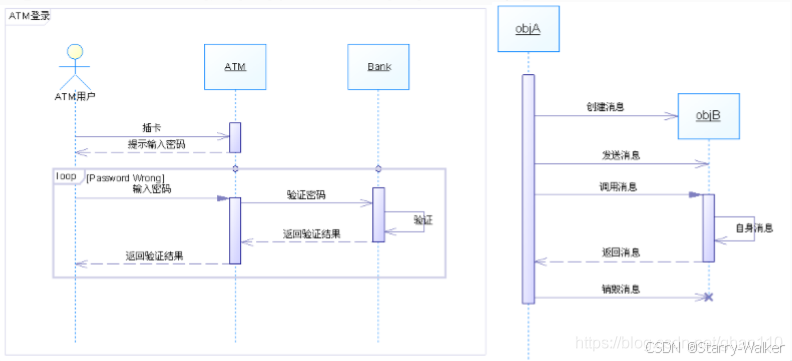
时序图
是一种交互图,交互图展现了一种交互,它由一组对象或角色以及它们之间可能发送的消息构成。交互图专注于系统的动态视图。顺序图是强调消息的 时间次序的交互图。
重点:侧重与了解各个对象之间传递的消息(对象之间的关系),其次才是填对象
状态图
以状态为节点,从一种状态由于有一种触发事件,从而变为另一种状态。
考察:给你一种系统描述,由状态的变迁中,扣除一些关键,让我们填写。
答题思路:总共有几种状态,由该状态变成另一种状态又需要什么条件,把这些转化为图就可能很好的解决状态图。(根据文字的描述)
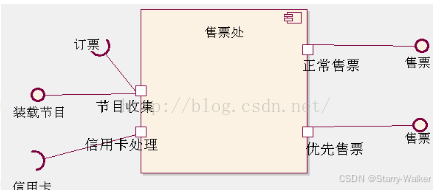
构件图
构件图是用来表示系统中构件与构件之间,类或接口与构件之间的关系图。由源代码文件、二进制代码文件、可执行文件或动态链接库 (DLL) 等构件构成,并通过依赖关系相 连接。
程序设计与设计模式

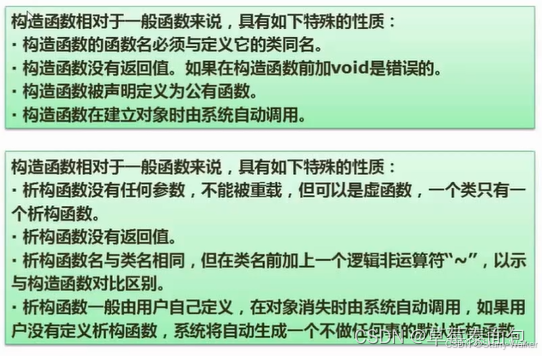
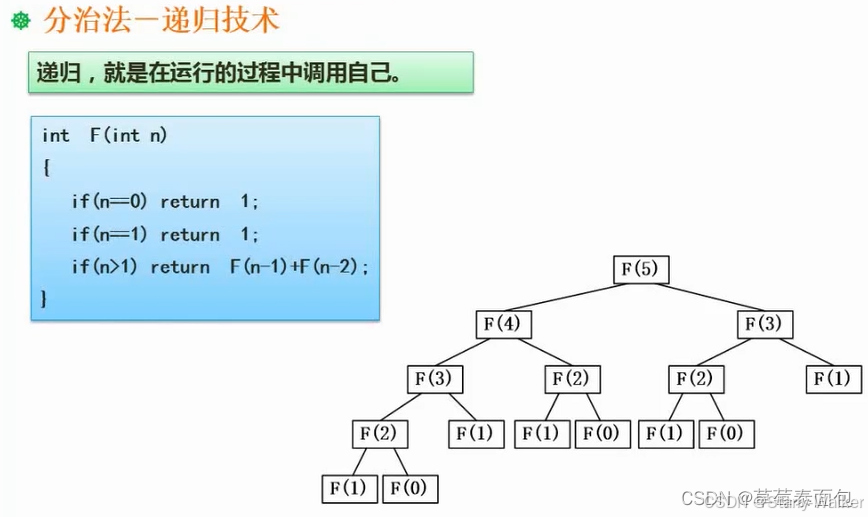
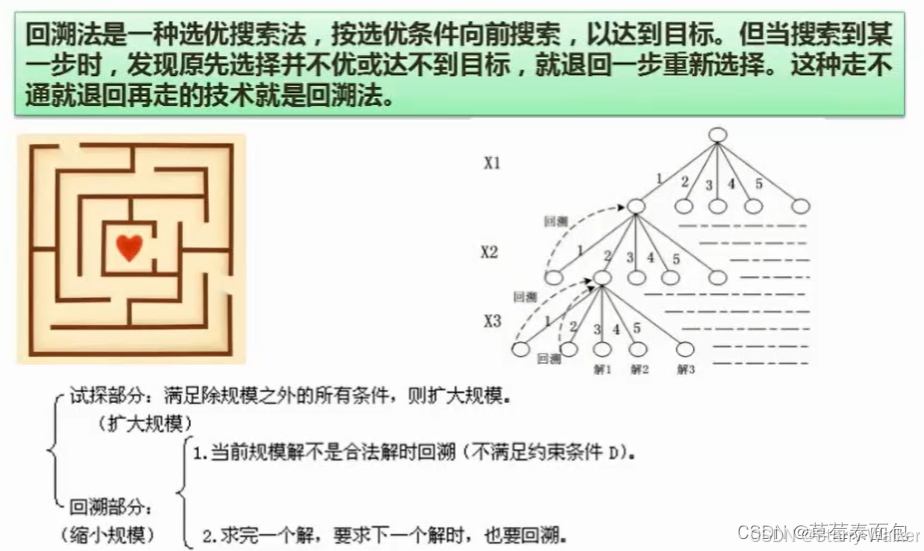
数据结构与算法
常见排序:
冒泡排序:通过反复交换相邻元素,每轮把最大或最小的元素“冒泡”到数组的一端,适合小规模数据。
选择排序:每次从未排序部分中选择最小(或最大)元素,放到前面,直到全部排序完成,交换次数少。
插入排序:逐个将元素插入到已排序部分的正确位置,适合基本有序或小规模数据。
快速排序:选择一个基准,将数组分为小于和大于基准的两部分,递归排序,效率高但极端情况性能差。
归并排序:将数组不断二分,排序后合并,适合大规模数据,稳定且时间复杂度为O(n log n),但需要额外空间。
堆排序:基于堆结构,每次取出堆顶(最大元素),调整堆,逐步完成排序,时间复杂度为O(n log n),不需额外空间。

哈夫曼树构造(堆构造)
从根节点开始,给每条左边的边标记为“0”,右边的边标记为“1”。
邻接表与邻接矩阵
邻接表是图的一种链式存储表示法:
-
对于每一个节点,将与其直接相连的邻居节点存储在一个列表或链表中。
-
每个节点只会存储与其有边相连的节点,因此存储空间更节省,特别适合稀疏图(即边数远小于节点数的平方)。

邻接矩阵是图的一种矩阵存储表示法:
-
使用一个 V×VV 的二维矩阵来表示节点之间的连接关系,其中 V 是节点的总数。
-
如果节点 ii和节点 j 之间有边,则矩阵的 [i][j] 位置设为1(无权图)或边的权重(有权图),否则为0(或表示无穷大,表示没有连接)。
-
邻接矩阵比较适合稠密图(即边数接近节点数的平方),因为它需要的空间较大。

最后的话:
备考中级软件设计师考试是一段充满挑战的旅程,但只要你不轻言放弃,就一定能看到曙光。记住,每一次的努力都不会白费,每一份坚持都会让你离目标更近一步。
如果你觉得这篇文章对你有帮助,或者你对中级软件设计师考试还有其他疑问,欢迎在评论区留言交流。你的反馈是我不断进步的动力!
如果你喜欢我的内容,也欢迎关注我的博客或社交媒体账号。我会持续分享更多关于中级软件设计师考试、IT行业动态以及更多有趣的技术干货。让我们一起在学习的道路上越走越远!
最后,如果你觉得这篇文章值得一看,不妨点个赞,让更多人看到!你的支持是我创作的最大动力!谢谢!
好了,各位亲爱的读者朋友们,希望这篇博客能为你在备考中级软件设计师考试的道路上提供有力的支持。祝你考试顺利,早日成为“大神”!我们一起加油吧! 🚀



















 1654
1654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











