






第1章 计算机系统知识
一 计算机系统基础
计算机的基本硬件系统由运算器、控制器、存储器、输入设备和输出设备五大部件组成。运算器、控制器等部件被集成在一起统称为中央处理单元(Central Processing Unit,CPU)。存储器是计算机系统中的记忆设备,分为内部存储器和外部存储器。前者速度高、容量小,一般用于临时存放程序、数据及中间结果;而后者容量大、速度慢,可长期保存程序和数据。输入设备和输出设备合称为外部设备(简称外设),输入设备用于输入原始数据及各种命令,而输出设备则用于输出处理结果。
1. 五大组成部件
- 运算器
- 控制器
- 存储器(内存、外存、cache)
- 输入设备
- 输出设备CPU = 运算器 + 控制器主机 = CPU + 存储器
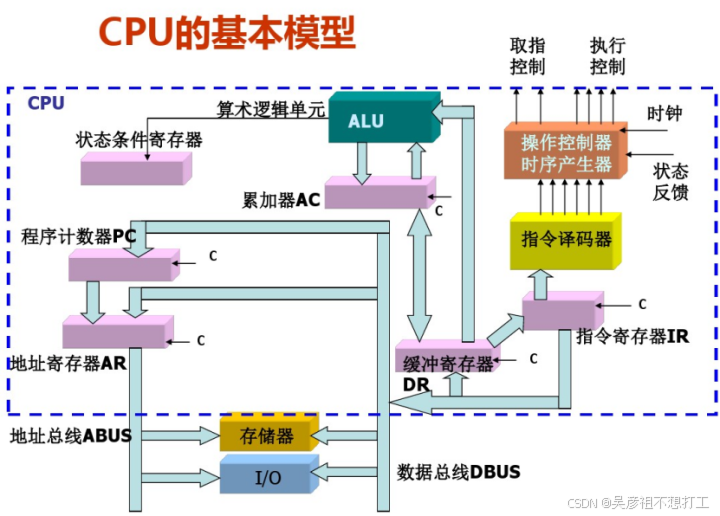
2. 中央处理器 CPU
-
组成:运算器、控制器、寄存器组、内部总线
-
功能:程序控制,操作控制,时间控制,数据处理功能
-
运算器组成(执行算数和逻辑运算,并进行逻辑测试,如与或非比较等)
- 算数逻辑单元ALU:实现对数据的算数和运算逻辑
- 累积寄存器AC:运算结果和源操作数的存放区
- 数据缓冲寄存器DR:暂时存放内存指令和数据
- 状态条件寄存器PSW:保存运行结果的条件码内容
-
控制器组成:(控制整个CPU的工作,最为重要,包括程序控制、时序控制等)
- 指令寄存器IR:暂存CPU执行指令
- 程序计数器PC:存放指令执行地址(寄存信息、计数)
- 地址寄存器AR:保存当前CPU所访问内存地址
- 指令译码器ID:分析指令操作码
-
CPU功能
- 程序控制:通过执行指令来控制程序的执行顾序。是CPU的重要功能
- 操作控制:一条指令功能的实现需要若干操作信号配合完成,CPU产生每条指令的操作信号并将操作信号送往不同的部件,控制相应的部件按指令的功能要求进行操作
- 时间控制:时间,持续时间及出现的8时间顺序都需要进行严格的控制时间,持续时间及出现的8时间顺序都需要进行严格的控制
- 数据处理:CPU通过对数据进行算术运算及逻辑运算等方式进行加工处理,数据加工处理的结果被人们所利用。所以,对数R的加工处理也是CPU最根本的任务
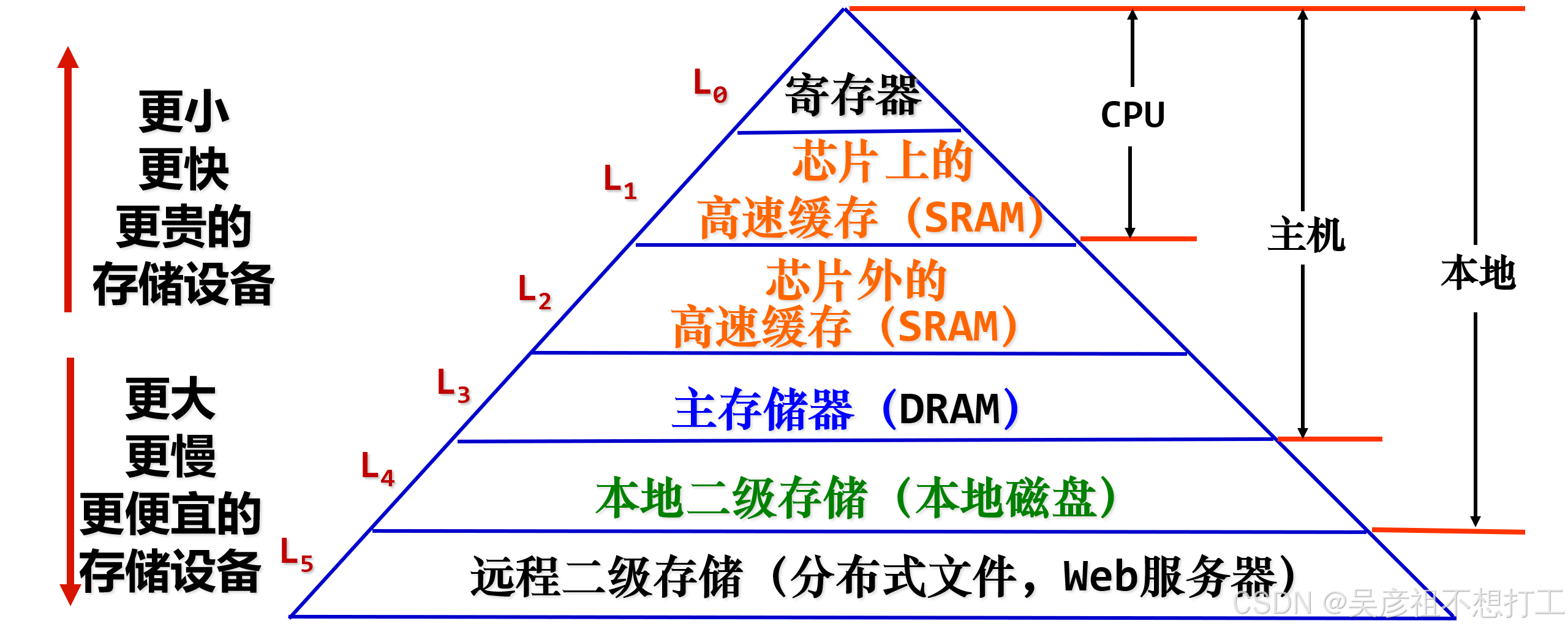
3.存储器
-
存储器结构(速度从高到低):寄存器 – 高速缓存Cache – 主存 – 外存
-
存储器分类
按在计算机中的作用(层次)分类1、主存:又称为内存,用来存放计算机运行期间所需的大量程序和数据,CPU可以直接随机地对其进行访问,也可以和Cache及辅助存储器交换数据。其特点是容量小,存取速度较快,单位成本较高。
2、辅助存储器:又称为外存,用来存储当前暂时不用的程序和数据,以及一些需要永久性保存的信息,它不能与CPU直接交换信息。其特点是容量大,存取速度慢,单位成本低。
3、高速缓冲存储器Cache,位于主存和CPU之间,用来存放正在执行的程序段和数据,以便CPU能高速地使用它们。Cache的存取速度可与CPU的速度相匹配,但其容量小,单位成本高。按访问方式
按地址访问的存储器:随机存储器、顺序存储器和直接存储器
按内容访问的存储器:相联存储器按存取方式分类
1、随机存储器(RAM-Random Access Memory):存储器的任何一个存储单元的内容都可以随机存取,而且存取时间与存储单元的物理位置无关。RAM又分为静态RAM(主要用于高速缓冲存储器Cache,以触发器原理寄存信息)和动态RAM(主要用于主存,以电容充电原理寄存信息)
2、只读存储器(ROM-Read Only Memory):存储器的内容只能随机读出而不能写入。信息一旦写入存储器就固定不变,即使断电,内容也不会丢失。因此,通常用它存放固定不变的程序、常数和汉字字库,甚至用于操作系统的固化。它与随机存储器可共同作为主存的一部分,统一构成主存的地址域。(注意:广义上的只读存储器已可通过电擦除等方式进行写入,其“只读”的概念没有保留,但仍然保留了断电内容保留、随机读取特性、且其写入速度比读取速度慢得多)
3、串行访问存储器。对存储单元进行读/写操作时,需按其物理地址的先后顺序寻址,包括顺序存取存储器(如磁带)与直接存取存储器(如磁盘)
① 顺序存储寄存器:只能按某种顺序存取,存取时间的长短与信息在存储体上的物理位置有关,其特点是存取速度慢。
② 直接存储寄存器:通常先寻找整个存储器中的某个小区域(如磁盘上的磁道),再在小区域内顺序查找。按存储介值进行分类
1、磁表面存储器(磁盘;磁带)
2、磁芯存储器
3、半导体存储器(MOS型半导体存储器,具有高集成度的特点;两极性半导体存储器,具有高速的特点)
4、光存储器(光盘)按信息的可保存性分类
1、易失性存储器:断电后,存储信息即消失的存储器。如 RAM
2、非易失性存储器:断电后,存储信息仍然存在的存储器。如 ROM、磁表面存储器和光存储器
3、破坏性读出:若某个存储单元所存储的信息被读出时,原存储信息被破坏,则称破坏性读出。具有破坏性读出性能的存储器,每次读出操作后,必须紧接一个再生的操作,以便恢复被破坏的信息
4、非破坏性读出:若某个存储单元所存储的信息被读出时,原存储信息不被破坏,则称非破坏性读出。 -
随机访问存储器:RAM
-
静态随机存储器 SRAM (电容,充放电)
-
动态随机存储器 DRAM (触发器)
DRAM SRAM 存储原理 电容 触发器 集成度 高 低 芯片引脚 少 多 速度 慢 快 价格 低 高 刷新 有 无 应用 主存、帧缓冲区 高速缓存存储器 -
4.数据表示
-
进制的转换——权位展开法
系数:当前数据每一位上的数值。
基数:x进制转换至十进制时,基数即为x。
权次幂:从个位起,基数的幂次按0开始递增。
示例:- 十进制 → 十进制
12345 = 1 × 1 0 4 + 2 × 1 0 3 + 3 × 1 0 2 + 4 × 1 0 1 + 5 × 1 0 0 = 12345 12345 = 1 \times 10^4 + 2 \times 10^3 + 3 \times 10^2 + 4 \times 10^1 + 5 \times 10^0 = 12345 12345=1×104+2×103+3×102+4×101+5×100=12345
- 二进制 → 十进制
O B 1011 = 1 × 2 3 + 0 × 2 2 + 1 × 2 1 + 1 × 2 0 = 8 + 2 + 1 = 11 OB1011 = 1 \times 2^3 + 0 \times 2^2 + 1 \times 2^1 + 1 \times 2^0 = 8 + 2 + 1 = 11 OB1011=1×23+0×22+1×21+1×20=8+2+1=11
- 八进制 → 十进制
O 131 = 1 × 8 2 + 3 × 8 1 + 1 × 8 0 = 64 + 24 + 1 = 96 O131 = 1 \times 8^2 + 3 \times 8^1 + 1 \times 8^0 = 64 + 24 + 1 = 96 O131=1×82+3×81+1×80=64+24+1=96
- 十六进制 → 十进制
O X 2 b = 2 × 1 6 1 + 11 × 1 6 0 = 32 + 11 = 43 OX2b = 2 \times 16^1 + 11 \times 16^0 = 32 + 11 = 43 OX2b=2×161+11×160=32+11=43
示例:十进制 100 转换为任意进制
- 二进制
100 / 2 = 50 … 0 50 / 2 = 25 … 0 25 / 2 = 12 … 1 12 / 2 = 6 … 0 6 / 2 = 3 … 0 3 / 2 = 1 … 1 1 / 2 = 0 … 1 \begin{align*} 100 & / 2 = 50 \ldots 0 \\ 50 & / 2 = 25 \ldots 0 \\ 25 & / 2 = 12 \ldots 1 \\ 12 & / 2 = 6 \ldots 0 \\ 6 & / 2 = 3 \ldots 0 \\ 3 & / 2 = 1 \ldots 1 \\ 1 & / 2 = 0 \ldots 1 \\ \end{align*} 100502512631/2=50…0/2=25…0/2=12…1/2=6…0/2=3…0/2=1…1/2=0…1
所以二进制为: OB1100100
- 八进制
100 / 8 = 12 … 4 12 / 8 = 1 … 4 1 / 8 = 0 … 1 \begin{align*} 100 & / 8 = 12 \ldots 4 \\ 12 & / 8 = 1 \ldots 4 \\ 1 & / 8 = 0 \ldots 1 \\ \end{align*} 100121/8=12…4/8=1…4/8=0…1
所以八进制为:O144
- 十六进制
100 / 16 = 6 … 4 6 / 16 = 0 … 6 \begin{align*} 100 & / 16 = 6 \ldots 4 \\ 6 & / 16 = 0 \ldots 6 \\ \end{align*} 1006/16=6…4/16=0…6
所以十六进制为:0X64
-
数的表示
在计算机底层,数据计算通常采用“补码”形式进行操作,而我们直观看到的数据则是“原码”。-
有符号位的数据表达法
符号表示:要注意的是,原码最高位是代表正负号,且不参与计数;而其他编码最高位虽然也是代表正负号,但参与计数。
结构:由两部分组成——最高符号位与数值位。
符号位:最高位表示符号,“0”代表正数,“1”代表负数。-
正数表示
对于正数,其原码、反码和补码完全相同。
原码、反码、补码
最高符号位 数值位 0 00000000 00000000 00000000 00000111 \begin{align*} & \text{最高符号位} \quad \text{数值位} \\ & 0 \quad 00000000\ 00000000\ 00000000\ 00000111 \end{align*} 最高符号位数值位000000000 00000000 00000000 00000111 -
负数表示
原码最高符号位 数值位 1 00000000 00000000 00000000 00000111 \begin{align*} & \text{最高符号位} \quad \text{数值位} \\ & 1 \quad 00000000\ 00000000\ 00000000\ 00000111 \end{align*} 最高符号位数值位100000000 00000000 00000000 00000111
反码:在原码基础上,除了最高符号位保持不变,其余位逐位取反。
最高符号位 数值位 1 11111111 11111111 11111111 11111000 \begin{align*} & \text{最高符号位} \quad \text{数值位} \\ & 1 \quad 11111111\ 11111111\ 11111111\ 11111000 \end{align*} 最高符号位数值位111111111 11111111 11111111 11111000
补码:在反码的基础上,对最低有效位加1。
最高符号位 数值位 1 11111111 11111111 11111111 11111001 \begin{align*} & \text{最高符号位} \quad \text{数值位} \\ & 1 \quad 11111111\ 11111111\ 11111111\ 11111001 \end{align*} 最高符号位数值位111111111 11111111 11111111 11111001
-
补码的零的表示是唯一的,原码-0和+0所对应的补码是相同的
补码表示简化了有符号数的运算和处理,并且转化减法运算为加法运算,使得计算机系统的设计更加高效和简洁
补码的符号位也参与运算,因为符号位正负就是表示整个数值的正负,符号位为0表示正数,为1则表示负数 -
-
浮点数运算
浮点数表示为:N = F × 2 E N = F \times 2^E N=F×2E
其中 ( E ) 称为阶码,( F ) 称为尾数;类似于十进制的科学计数法,如:
85.125 = 0.85125 × 1 0 2 85.125 = 0.85125 \times 10^2 85.125=0.85125×102
二进制表示如:
101.01101011 × 2 3 101.01101011 \times 2^3 101.01101011×23
在浮点数的表示中:
- 阶码为无符号的纯整数,
- 尾数为带符号的纯小数,
- 符号位占据最高位(正数为0,负数为1)。
其表示格式如下:
- 阶码决定浮点数所能表示的数值范围,
- 尾数决定数值的精度。
尾数的表示采用规格化方法,即带符号尾数的补码必须满足:
- 正数为 ( 1.0xxxx ),
- 负数为 ( 0.1xxxx ),其中 ( x ) 可以为0或1。
浮点数的运算过程包括:
- 对阶:使两个数的阶码相同,小阶向大阶看齐,较小阶码每增加一位,尾数相应右移一位。
- 尾数计算:进行相加操作,若为减法,则加负数的尾数。
- 结果规格化:确保尾数表示为规格化形式,即带符号尾数转换为 ( 1.0xxxx ) 或 ( 0.1xxxx )。
-
算数运算和逻辑运算
-
算术运算
-
加法 (+):两个数相加。
-
减法 (-):一个数从另一个数中减去。
-
乘法 (*):两个数相乘。
-
除法 (/):一个数除以另一个数。
-
取模 (%):求两个数值相除的余数。
-
-
-
逻辑运算
针对二进制数,逻辑运算处理的是比特位(0或1):-
逻辑与 (&):两个比特位进行“与”运算,只有当两个比特位均为1时,结果才为1,否则为0。
-
逻辑或 (|):两个比特位进行“或”运算,只要有一个比特位为1,结果就为1,否则为0。
-
异或 (^):两个比特位进行“异或”运算,当两个比特位不同时,结果为1;相同时,结果为0。
-
逻辑非 (! 或 ~):对单个比特位进行“非”运算,0变为1,1变为0。
-
-
位移运算
-
逻辑左移 (<<):二进制数整体向左移动n位,高位溢出的部分被丢弃,低位用0填充。
-
逻辑右移 (>>):二进制数整体向右移动n位,低位溢出的部分被丢弃,高位用0填充(对于无符号数)或用符号位填充(对于有符号数)。
-
算术右移 (>>):专门用于有符号数,向右移动n位时,高位用符号位填充,以保持数的正负属性。
特别注意
算术左移和算术右移:本质上是乘以2的幂次方(左移)和除以2的幂次方(右移)的运算,是算术运算的一种。
短路计算方式:指通过逻辑运算符(&&、ll)左边表达式的值就能推算出整个表达式的值,不再继续执行逻辑运算符右边的表达式。 -
5.校验码
码距:就单个编码 A:00 而言,其码距为1,因为其只需要改变一位就变成另一个编码。在两个编码中,从 A码 到 B码 转换所需要改变的位数称为码距,如 A:00 要转换为 B: 11,码距为2。一般来说,码距越大,越利于纠错和检错。
-
奇偶校验码
在编码中增加1位校验位来使编码中1的个数为奇数(奇校验)或者偶数(偶校验),从而使码距变为2。奇校验可以检测编码中奇数位出错,即当合法编码中的奇数位发生了错误时,即编码中的1变成0或者0变成1,则该编码中1的个数的奇偶性就发生了变化,从而检查出错误。但无法纠错。 -
循环冗余校验码(CRC)
CRC只能检错,不能纠错,采用模二除法运算的只有循环冗余检验CRC。 -
海明校验码
-
海明码原理
海明码的基本思想是通过增加冗余位(校验位)来实现错误检测和纠正。在海明码中,数据位和校验位混合排列,校验位用来检查数据位的奇偶性。 -
编码规则
确定校验位数量:假设数据位数量为m,校验位数量为k,那么满足以下条件的最小r值即为所需校验位的数量:2 k − 1 ≥ m + k 2^k - 1 \geq m + k 2k−1≥m+k
设信息位是 8 位,用海明码来发现并纠正 1 位出错的情况,则校验位的位数至少为( )
直接代入公式,2^k - 1 ≥ 8 + k,即
根据不等式求解,可得 k 至少为 4 -
校验位位置
校验位放置在2的幂次方的位置上,例如第1位、第2位、第4位、第8位等。 -
校验位计算:每个校验位负责检查一组数据位的奇偶性。例如,第1位校验位(P1)负责检查所有位置序号中包含1的位(即第1、3、5、7、…位)的奇偶性;第2位校验位(P2)负责检查所有位置序号中包含2的位(即第2、3、6、7、…位)的奇偶性,以此类推。
-
编码过程:根据上述规则,计算每个校验位的值,使其所负责的数据位组合起来的奇偶性符合预设的奇偶校验规则(通常为偶校验)。
-
解码和错误检测
接收端收到数据后,同样利用校验位检查数据位的奇偶性。如果发现某位数据的奇偶性与预期不符,可以根据校验位的组合错误来定位错误的具体位置,并进行纠正。 -
示例
假设我们要编码的数据为1011,我们首先确定所需的校验位数量,然后按照规则放置校验位和数据位,计算校验位的值,最后完成编码。
例如,对于数据1011,我们至少需要3个校验位(P1、P2、P3),编码后的海明码可能是这样的:
P1(第1位):1
数据位1(第2位):0
P2(第4位):1
数据位2(第5位):1
数据位3(第6位):1
P3(第8位):1
最终编码结果为:10111101
通过这种方式,即使在传输过程中发生单比特错误,接收端也能通过校验位检测并纠正错误,保证数据的正确性。
-
二 计算机体系结构
1.计算机体系结构分类
-
Flynn分类法-Flynn按照指令和数据流不同的组织方式,计算机系统可分为四类
体系结构类型 结构 关键特性 代表 单指令流单数据流 SISD 控制部分:一个 处理器:一个 主存模块:多个 单处理器系统 单指令流多数据流 SIMD 控制部分:一个 处理器:多个 主存模块:多个 各处理器以异步的形式 执行同一条指令 并行处理机 阵列处理机 超级向量处理机 多指令流单数据流 MISD 控制部分:多个 处理器:一个 主存模块:多个 被证明并不可能, 至少不实际 目前没有,有文献称流水线计算机为此类 多指令流多数据流 MIMD 控制部分:多个 处理器:多个 主存模块:多个 能够实现作业、任务、指令等 各级全面并行 多处理机系统多计算机
2. 指令系统
-
复杂指令系统 CISC : 兼容性强,长度可变,有微程序实现
-
精简指令系统 RISC:指令少,使用频率接近,主要依靠硬件实现
指令系统类型 指令 寻址方式 实现方式 其他 CISC 指令长度不固定、数量多、使用频率差别大、可变长格式 支持多种 微程序控制技术 研制周期长、难优化编译 RISC 指令定长、数量少、使用频率接近、大部分为单周期指令,操作寄存器 支持方式少 增加了通用寄存器,硬布线逻辑控制为主、适合采用流水线 优化编译、有效支持高级语言
3. 指令流水线原理
-
RISC流水线技术
- 1)超流水线(时间换空间)
- 2)超标量(空间换时间)
- 3)超长指令字VLIM(执行多条指令,发挥软件作用)
-
流水线时间计算:
设:总指令数为 n ; 单条指令总执行时间为 t单 ; 单条指令在流水线中耗时时间最长段时间 t周
流水线周期: 指令执行时耗时最长的那个时间段 公式为: t周流水线执行总时间 ( t总 ) 可以通过以下公式计算:
t 总 = t 单 + ( n − 1 ) × t 周 t_{总} = t_{单} + (n-1) \times t_{周} t总=t单+(n−1)×t周
流水线的吞吐率 ( R ) 表示单位时间内流水线能完成的指令数量,其计算公式为:
R
=
n
t
总
=
n
t
单
+
(
n
−
1
)
×
t
周
R = \frac{n}{t_{总}} = \frac{n}{t_{单} + (n-1) \times t_{周}}
R=t总n=t单+(n−1)×t周n
-
流水线的加速比计算
加速比即使用流水线后的效率提升度,即比不使用流水线快大多少份越高表明流水线效率越高,公式如下:S = 不使用流水线执行时间 使用流水线执行时间 S=\frac{不使用流水线执行时间}{使用流水线执行时间} S=使用流水线执行时间不使用流水线执行时间
速度比较:立即 > 寄存器 > 直接 > 间接1.立即寻址
直接在指令中给出操作数2.寄存器寻址(Register Addressing)
寄存器寻址是指操作数直接存储在寄存器中。指令中的地址字段指定要使用的寄存器编号,而不是内存地址。这种寻址方式速度最快,因为操作数直接存储在寄存器中,无需访问内存。寄存器寻址的灵活性较差,由于寄存器数量有限,只能操作寄存器中的数据。3.直接寻址(Direct Addressing)
直接寻址是指指令中直接给出要操作的数据的地址。指令中的地址字段直接指向要操作的内存单元。这种寻址方式速度较快,因为指令直接指向数据的地址,无需额外计算。不过,直接寻址的灵活性较差,只能操作指定地址的数据。4.间接寻址(Indirect Addressing)
**间接寻址是通过指令中的地址字段间接地获取要操作的数据的地址。**指令中的地址字段指向一个存储着数据地址的内存单元。通过这个间接的地址,可以找到实际要操作的数据。间接寻址的灵活性较好,可以通过改变间接地址来操作不同的数据。但是,由于需要额外的内存访问,速度相对较慢。
4.存储系统
-
存储器的层次化结构
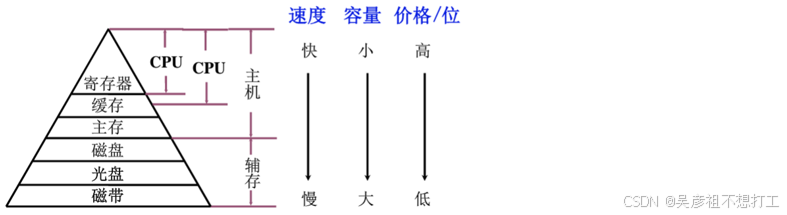
- 缓存与主存之间主要解决速度问题(cpu和主存速度的不匹配),因此通过硬件方法实现(主存速度的更新换代远跟不上CPU的发展,速度差异存在“剪刀差”)
-
主存与辅存之间主要解决容量问题,因此使用软硬件相结合的方法
-
缓存与主存使用的是主存储器的地址,也就是实地址(也叫物理地址);主存与辅存构成虚拟存储器,使用的是虚地址(也叫逻辑地址),在下文虚拟存储器部分会进行详细阐述
-
高速缓存 Cache
高速缓存Cache用来存储当前最活跃的程序和数据,直接与CPU交互,位于CPU和主存之间,容量小,速度为内存的5-10倍,由半导体材料构成。其内容是主存内存的副本拷贝,对于程序员来说是透明的。Cache与主存地址映射由硬件完成。- Cache和主存之间的映射方式(地址映射)
全相联映射 (fully-associated) —— 各主存都可以映射到cache的任意数据块。
直接相联映射 (direct mapped) —— 每一个主存块地址只可以映射到cache的固定行。
组相联映射 (set-associated) —— 在组间采用直接映射,在组内采用全相联映射。
- Cache和主存之间的映射方式(地址映射)
在CPU与三级存储体系之间的关系,存在数据传输的层次结构。当CPU需要访问数据时,它首先会检查高速缓存,如果数据在缓存中命中,则可以直接访问。如果数据不在高速缓存中,CPU将在主存中查找。如果数据在主存中,CPU会将数据加载到高速缓存中,并进行后续的操作。如果数据既不在高速缓存中也不在主存中,则需要从硬盘中加载数据到主存,再由主存传输到高速缓存,最后供CPU使用。这个层次结构的目标是尽可能减少CPU等待数据的时间,提高整体的计算机性能。
5.输入输出技术
- 程序控制方式
- 特点:CPU主动查询外设状态,判断数据是否准备好。
- 效率:极低,因为CPU需要频繁查询,浪费大量处理时间。
- 中断方式
- 特点:外设完成数据传输后主动通知CPU,通过中断信号触发CPU处理。
- 效率:相对较高,CPU无需持续查询,节省处理时间。
- 关键概念:
- 中断响应时间:从发出中断请求到开始执行中断处理程序的时间。
- 中断处理时间:从开始处理中断到处理结束的时间。
- 中断向量:提供中断服务程序的入口地址,支持多级中断嵌套。
- 堆栈保护:使用堆栈保存断点和现场信息,确保中断处理后的正确恢复。
- DMA方式
- 特点:数据传输由DMA控制器直接管理,无需CPU干预。
- 效率:高,因为CPU仅需负责初始化等少量工作,数据传输过程独立进行。
- 关键概念:
- 总线周期:DMA请求在总线周期结束时被响应,区别于指令执行结束时的中断响应。
- 数据通路:在主存和外设间建立直接数据传输路径。
- 通道方式
- 特点:专用处理机,独立于CPU,专门负责数据传输任务。
- 效率:高效,数据传输完全独立,不占用CPU资源。
- 传送方式:
- 字节多路通道:每次传送一个字节,适用于低速设备,采用多路复用方式。
- 选择通道:一次选择一个设备,连续传送所有数据,适用于高速设备。
常见接口:包括USB、HDMI、以太网等
6. 总线结构
-
按总线功能进行分类:
-
片内总线
片内总线是芯片内部的总线。它是CPU芯片内部寄存器与寄存器之间、寄存器与ALU之间的公共连接线。 -
系统总线
系统总线是计算机系统内各功能部件(CPU、主存、I/O接口)之间相互连接的总线。
按系统总线传输信息内容的不同分:-
数据总线(DB)
传输各功能部件之间的数据信息,包括指令和操作数;位数(根数)与机器字长、存储字长有关;【双向】 -
地址总线(AB)
传输地址信息,包括主存单元或I/O端口的地址; 位数(根数)与主存地址空间大小及设备数量有关;【单向】 -
控制总线(CB)
传输控制信息;一根控制线传输一个信号; 有出:CPU送出的控制命令; 有入:主存(或外设)返回 CPU的反馈信号。
-
-
通信总线
通信总线是用于计算机系统之间或计算机系统与其他系统(如远程通信设备、测试设备)之间信息传送的总线,通信总线也称为外部总线。数据通路表示的是数据流经的路径
数据总线是承载的媒介
-
-
按位置分:
- 内部总线(处理器内部通信总线)
- 外部总线(设备一级的总线,计算机外部设通信的总线)
-
按数据传输格式进行分类:
-
串行总线
优点:只需要一条传输线,成本低廉,广泛应用于长距离传输;应用于计算机内部时,可以节省布线空间。
缺点:在数据发送和接收的时候要进行拆卸和装配,要考虑串行-并行转换的问题。 -
并行总线
优点:总线的逻辑时序比较简单,电路实现起来比较容易。
缺点:信号线数量多,占用更多的布线空间;远距离传输成本高昂;由于工作频率较高时,并行的信号线之间会产生严重干扰,对每条线等长的要求也越高,所以无法持续提升工作频率。
-
三 系统可靠性分析
1.计算机安全概述
-
计算机的安全等级
美国的计算机系统安全等级主要基于1985年美国国防部发布的《可信计算机系统评估标准》(Trusted Computer System Evaluation Criteria, TCSEC),通常被称为“橙皮书”(Orange Book)。该标准将计算机系统的安全级别分为四组七等级,具体如下:组别 等级 描述 D组 D1 最低安全级别,无安全保护,如早期的个人电脑操作系统。 C组 C1 自主访问控制(Discretionary Access Control, DAC),提供了基本的用户账户和权限。 C组 C2 强化的DAC,增加了审计跟踪和资源隔离。 B组 B1 标签安全(Labeled Security),数据和文件有标签,实现了强制访问控制(Mandatory Access Control, MAC)。 B组 B2 结构化保护(Structured Protection),MAC和安全内核的概念。 B组 B3 安全域(Security Domain),增加了硬件安全机制和形式化安全策略模型。 A组 A1 验证设计(Verified Design),最高安全级别,要求系统有形式化的安全证明和文档。 这些安全级别按照从D到A的顺序递增,A1是最高安全级别,意味着系统有最严格的访问控制和最全面的安全保障措施。这些标准为计算机系统的设计和评估提供了基础,尤其是在政府和军事领域,对于确保数据的机密性、完整性和可用性至关重要。
-
典型的安全威胁
威胁类型 描述 授权侵犯 未经授权的用户或实体获得了访问或控制资源的权限,通常通过利用系统漏洞或弱口令实现。 拒绝服务 (DoS) 通过耗尽资源或带宽,阻止合法用户访问服务或网络资源。 窃听 在数据传输过程中,未经授权的第三方监听或记录通信内容,以获取敏感信息。 信息泄露 敏感信息意外或故意暴露给未经授权的个人或实体,可能导致隐私泄露或商业机密损失。 截获修改 攻击者在数据传输过程中截获信息,并对其进行修改,然后继续传输,以达到欺骗的目的。 假冒 攻击者冒充合法用户或实体,以获取访问权限或进行欺诈活动。 否认服务 (DDoS) 分布式拒绝服务攻击,通过多台被控制的计算机向目标发送大量请求,导致服务不可用。 否认 攻击者在进行攻击后,否认自己的行为,使责任难以追溯。 非法使用 未经授权的用户或实体使用系统资源,进行非授权的操作,如数据篡改或系统控制。 人员疏忽 内部人员因缺乏安全意识或培训不足,导致安全漏洞被利用,如弱口令或点击恶意链接。 完整性破坏 数据在存储或传输过程中被未经授权的修改,导致数据的完整性和准确性受损。
2.加密及认证技术
-
加密
-
对称加密(共享密钥加密算法):使用同一个密钥进行加密和解密的过程。这种加密方法速度快,适合加密大量数据,但密钥的管理和分发是个挑战。
典型算法:DES(Data Encryption Standard)、3DES(Triple Data Encryption Algorithm)、AES(Advanced Encryption Standard)等。 -
非对称加密(公开密钥加密算法):使用一对密钥,即公钥和私钥,进行加密和解密。公钥用于加密,而私钥用于解密,反之亦然。这种加密方法安全级别高,但速度相对较慢。
典型算法:RSA、ECC(Elliptic Curve Cryptography)等。
-
-
认证
-
摘要技术(哈希函数):使用哈希函数将任意长度的数据转换为固定长度的摘要,即使输入数据有微小变化也会导致摘要完全不同。常用于检测数据是否被篡改。
典型算法:MD5、SHA-1、SHA-256等。 -
数字签名:结合非对称加密和摘要技术,发送方使用其私钥对数据摘要进行加密,接收方使用发送方的公钥解密并验证数据的完整性和来源。
过程:发送方使用私钥对数据摘要加密生成数字签名;接收方使用发送方的公钥解密数字签名并与自己计算的数据摘要比对。 -
数字证书:由可信的第三方机构(CA,Certificate Authority)颁发,用于证明公钥属于某个实体。数字证书包含公钥、实体信息和CA的数字签名。(对用户身份进行认证)
作用:确保公钥的真实性和有效性,防止中间人攻击。
-
3.计算的可靠性
系统可靠性分析对于设计和维护复杂系统至关重要,它帮助我们评估系统的稳定性和预测潜在的故障点,从而采取措施提高系统整体的可靠性和可用性。
可靠性:系统在规定条件下和规定时间内完成预定功能的概率。
故障率:单位时间内系统发生故障的概率,通常用λ表示。
平均无故障时间(MTTF):系统平均能够正常运行的时间。
平均修复时间(MTTR):系统平均需要的修复时间。
-
串联系统可靠性
在串联系统中,所有组件必须正常工作才能使整个系统正常运行。串联系统的总可靠性R_total可以通过以下公式计算:R t o t a l = R 1 × R 2 × . . . × R n R_{total} = R_1 \times R_2 \times ... \times R_n Rtotal=R1×R2×...×Rn
其中,( Ri ) 是第 i 个组件的可靠性。
-
并联系统可靠性
在并联系统中,只要有一个或多个组件正常工作,系统就能正常运行。并联系统的总可靠性 Rtotal 可以通过以下公式计算:
R t o t a l = 1 − ( 1 − R 1 ) × ( 1 − R 2 ) × . . . × ( 1 − R n ) R_{total} = 1 - (1 - R_1) \times (1 - R_2) \times ... \times (1 - R_n) Rtotal=1−(1−R1)×(1−R2)×...×(1−Rn)其中,( Ri ) 是第 i 个组件的可靠性。
-
可靠性与MTTF的关系
系统的平均无故障时间(MTTF)与故障率(λ)成倒数关系:M T T F = 1 λ MTTF = \frac{1}{\lambda} MTTF=λ1
-
系统可用性
系统可用性A是衡量系统在任意时刻处于工作状态的概率,可通过以下公式计算:A = M T T F M T T F + M T T R A = \frac{MTTF}{MTTF + MTTR} A=MTTF+MTTRMTTF
其中,MTTR是平均修复时间。
第2章 程序设计语言基础知识
一 程序设计语言概述
- 程序设计语言是为了书写计算机程序而人为设计的符号语言,用于对计算过程进行描述、组织和推导
1. 各语言特点
- 低级语言:机器语言(计算机硬件只能识别0和1的指令程序),汇编语言
- 高级语言:功能更强,抽象级别更高,与人们使用的自然语言比较接近
| Fortran语言,科学计算,执行效率高 |
| Pascal语言,为教学而开发的,表达能力强,delphi |
| C语言,指针操作能力强,高效 |
| Lisp语言,函数式程序语言,符号处理,人工智能 |
| C++语言,面向对象,高效 |
| Java语言,面向对象,中间代码,跨平台 |
| C#语言,面向对象,中间代码,.NET |
| Prolog语言,逻辑推理,间接性,表达能力强,数据库和专家系统 |
- 都是将高级语言翻译成计算机硬件认识的及其语言。
- 编译:生成独立的可执行文件(预处理=>编译=>链接),直接运行,运行时无法控制源程序,效率高。
- 解释:不生成可执行文件,可以逐条解释执行,用于调试模式,可以控制源程序,因为还需要控制程序,因此执行速度慢,相对于编译效率低。
- 编译型:C、C++、Delphi、Pascal、Fortran
- 解释型:Java、Basic、javascript、python
java有编译和解释性 Java编译程序生成字节码(byte-code),再由解释器解释运行。
| 解释器 | 编译器 | |
|---|---|---|
| Input(输入) | 每次读取一行 | 整个程序 |
| Output(输出) | 不产生任何的目标代码 | 生成中间目标代码 |
| 工作机制 | 编译和执行同时进行 | 编译在执行之前完成 |
| 生成程序 | 不生成输出程序 | 生成exe |
| 修改 | 直接修改就可运行 | 如果需要修改代码,则需要修改源代码,重新编译 |
| 运行速度 | 慢 | 快 |
| 内存 | 少 | 多 |
| 错误 | 解释器读取一条语句并显示错误 | 编译器在编译时显示所有错误和警告。 |
决策表又称判断表,是一种呈表格状的图形工具,适用于描述处理判断条件较多,各条件又相互组合、有多种决策方案的情况。
符号表在编译程序工作的过程中需要不断收集、记录和使用源程序中一些语法符号的类型和特征等相关信息。这些信息通常以表格形式存储于系统中
广义表,又称列表,也是一种线性存储结构。通常,广义表中存储的单个元素称为“原子”,而存储的广义表称为“子表”。
索引表是一张指示逻辑记录和物理记录之间对应关系的表。索引表中的每项索引项按键(或逻辑记录号)顺序排列。在索引顺序文件中,可对—组记录建立一个索引项。
3. 程序语言组成
- 语法:表示程序的结构或形式,即构成语言的各个记号之间的组合规律,但不涉及这些记号的特定含义,也不涉及使用者。语法是程序设计语言的基础,它定义了如何通过一组记号(如符号、关键字等)来构建程序的结构。***(一组规则)***
- 语义:表示程序的含义,即按照各种方法所表示的各个记号的特定含义,但不涉及使用者。语义关注的是程序的功能和意义,它定义了程序中各个元素(如变量、函数等)如何相互作用以及它们的具体含义。
- 语用:表示程序与使用者的关系。语用考虑的是程序如何被人类使用者理解和使用,包括程序的文档、用户界面等方面。
二.程序设计语言的基本成分
1. 数据成分
是一种程序设计语言的数据和数据类型,数据分为常量(程序运行时不可改变)、变量(可以改变)、全局量(存储空间在静态数据区分配)、局部量(存储空间在堆栈区分配)
2. 数据类型
整型、字符型、双精度、单精度浮点型、布尔型等
3. 运算成分
指明允许使用的运算符号即运算规则,包括算数运算、逻辑运算、关系运算、位运算等。
4. 控制成分
指明语言允许标书的控制结构。包括顺序结构、选择结构、循环结构(初始化+循环体+循环条件)
5. 传输成分
指明语言允许的数据传输方式。如:赋值处理、数据的输入输出等
6. 函数
C程序有一个或多个函数组成,每个函数都有一个名字,其中有且仅有一个名字为main函数作为运行时的起点。函数式程序模块的主要成分,是一段具有独立功能的程序。函数使用涉及三个概念:函数定义、函数声明(先声明后使用)、函数调用
7 调用
- 传值调用:将实参的值传递给形参,形参的改变不会导致调用点所传的实参的值改变。实参可是是合法的变量、常量、表达式
- 传址调用:即引用调用,将实参的地址传值给形参,即相当于实参存储单元的地址引用,因此其值改变的同时就改变了实参的值,实参不能为常-量,只能是合法的变量和表达式。
- 因此,在编程时,要改变参数值,就传址,不改变,就传值
三.编译程序基本原理
1. 功能
是把高级语言书写的程序翻译成汇编语言或机器语言
分为6个阶段:
- 1.词法分析:对源程序字符进行扫描根据构词规则识别单词(也称单词符号或符号)
- 2.语法分析:逻辑阶段,根据识别的单词组合成各类语法短语,如:程序,语句,表达式等,分析判断源程序在结构是否正确
- 3.语义分析:逻辑阶段,对结构上正确的源程序进行上下文有关性质的审查。如:类型匹配、除法除数不为0等。分为静态语义错误(编译阶段能够发现)、动态语义错误(运行时能发现)
- 4.中间代码和目标代码生成:中间代码是语义分析产生的需要经过优化链接,最终生成可执行的目标代码。引入中间代码的目的是进行与机器无关的代码优化处理。常用的中间代码有后缀式(逆波兰式)、三元式(三地址码)、四元式和树等形式。
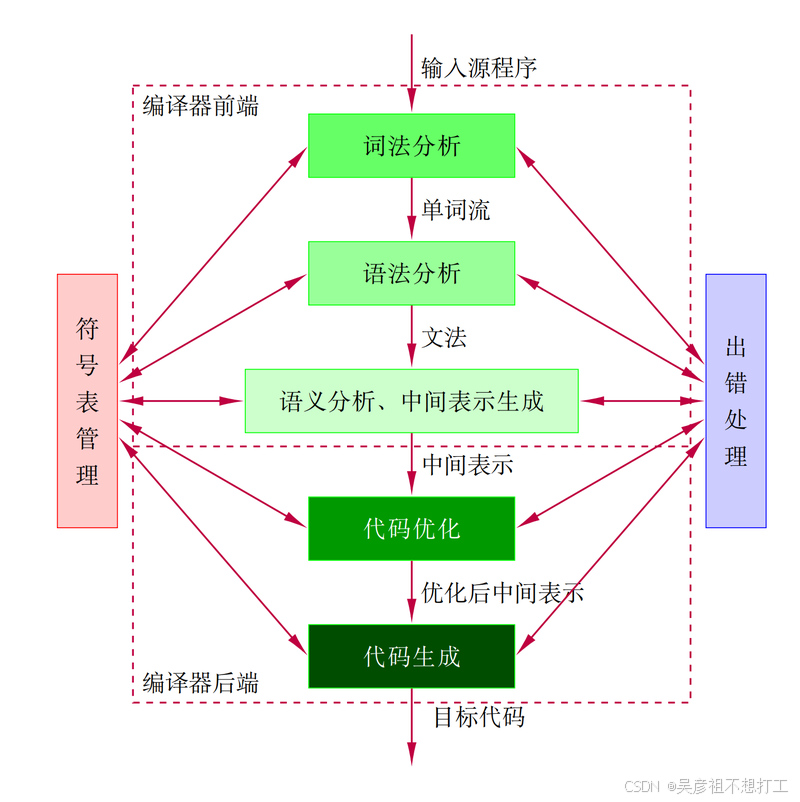
2. 文法定义
-
形式文法四元组G=(V,T,S,P)
S: 文法开始符号
V: 不是语言组成部分,可理解为占位符;非终结符:能够推导出其他元素
P:产生式。用终结符替代非终结符的规则;即非终结符推导出终结符的公式
T: 终结符,语言组成部分,是最终结果;不能推导出其他元素 -
闭包
正则闭包(所有幂的组合 )
A + = A 1 ∪ A 2 ∪ A 3 ∪ . . . ∪ A n A^+ = A^1 \cup\ A^2\cup\ A^3\cup\ ...\cup\ A^n A+=A1∪ A2∪ A3∪ ...∪ An
闭包(正则闭包的基础上,加上A0 = { ε })
A ∗ = A 0 ∪ A + A^* = A^0 \cup\ A^+ A∗=A0∪ A+ -
2.3 文法类型:
- 0型文法也叫短语结构文法
- 1型 ==> 语义分析(上下文有关)
- 2型 ==> 语法分析(上下文无关)
- 3型文法也叫正则文法或正规文法
四.正规式
-
正规集:程序设计语言的单词表、词汇集构成的集合,即是字的集合。它有一定特殊性,我们称之为正规集。用来代表程序语言的单词表。
-
正规式:可以说是正规集的名称。
-
正规集可以用正规表达式(简称正规式)表示
-
正规表达式是表示正规集一种方法
-
一个字集合是正规集当且仅当它能用正规式表示
用于词法分析,对于字母表
Σ,其上的正规式及其表示的正规集可以递归定义如下:
ε是一个正规式,它表示集合L(ε)= {ε}。
若α是Σ上的字符,则α是一个正规式,它所表示的正规集为{α}。
若正规式r和s分别表示正规集L®和L(s),则:
①r|s是正规式,表示集合L(r) U L(s)。
②r·s是正规式,表示集合L(r)L(s)。
③r*是正规式,表示集合(L(r))*。
④(r)是正规式,表示集合L(r)。
仅由有限次地使用上述三个步骤定义的表达式才是Σ上的正规式。
五.有限自动机
-
确定有限自动机(DFA,Deterministic Finite Automata)
确定有限自动机 M 是一个五元式 M =(S,Σ,f,S0,F),其中:
S:有穷状态集
Σ:输入字母表(有穷)
f :状态转换函数,即状态转换图中的弧,S×Σ→S的单值部分映射,
f(s,a)=s’,s是现态,输入字符a后,到达s’态
"单值"是说确定的s,a对应唯一的s’
"部分"是说,有些状态(终态)可能与任何字符均不存在映射
S0:唯一的初态
F:终态集(可空)
DFA与状态转换图

其中 f 为:
f ( S 0 , a ) = S 1 , f ( S 0 , b ) = S 2 , f ( S 1 , a ) = S 3 , f ( S 1 , b ) = S 2 , f ( S 2 , a ) = S 1 , f ( S 2 , b ) = S 3 , f ( S 3 , a ) = S 3 f(S_0,a)=S_1, f(S_0,b)=S_2, f(S_1,a)=S_3, f(S_1,b)=S_2,\\ f(S_2,a)=S_1, f(S_2,b)=S_3, f(S_3,a)=S_3 f(S0,a)=S1,f(S0,b)=S2,f(S1,a)=S3,f(S1,b)=S2,f(S2,a)=S1,f(S2,b)=S3,f(S3,a)=S3
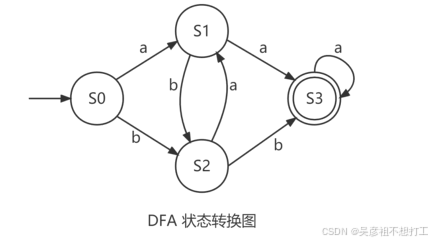
本质就是有向图从起点到终点的遍历。
-
非确定有限自动机 (NFA,Nondeterministic Finite Automata)
非确定有限自动机 M 是一个五元式 M = (S,Σ,f,S0,F),其中:
S:有穷状态集
Σ:输入字母表(有穷)
f :状态转换函数,即状态转换图中的弧,S×Σ→2S的部分映射,
(2S即S的幂集,是由S的所有子集组成的集合,2S = { A|A⊆S })
f(s,a)=S’,s是现态,输入字符a后,可到达状态集S’里的任何一个状态,S’ ⊆ 2S
不保证是单值映射,因此是NFA(NFA的N)
另外需要注意的是,弧接受的可以是字,甚至是甚至
S0:非空的初态集
F:终态集(可空)
对于Σ上的任何字α,若存在一条由初态到某一终态的道路,且这条通路上所有弧上的字符/字连接成的字为α,则称字α为NFA M 所接受/识别
NFA M 所识别的字的全体记为L(M) -
NFA与DFA的区别
FA\区别 初态 映射(后继状态) 弧接受的内容 DFA(确定) 唯一 单值映射 字符 NFA(不确定) 初态集(可以不唯一) 映射结果也是状态集(不唯一) 字(字符)、正规式 -
正规式与有限自动机之间的转换
-
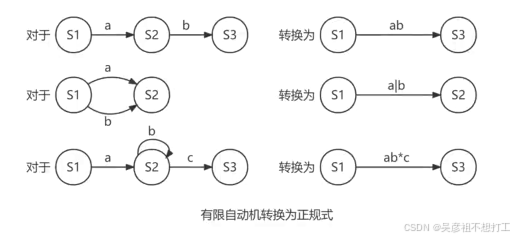
有限自动机转换为正规式的过程
-
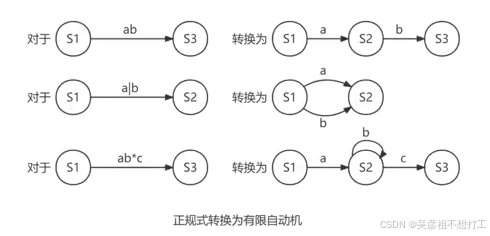
正规式转换为有限自动机的过程
-
六.语法分析方法
1. 自上而下语法分析:
最左推导,从左至右。给定文法G和源程序串r,从G的开始符号出S出发,通过反复使用产生式对举行中的非终结符进行替换(推导),逐步推出r
递归下降:利用函数之间的递归调用模拟语法树自上而下的构造过程,是一种自上而下的语法分析方法
2. 自下而上语法分析:
最右推导,从右至左。从右至左。从给定的输入串r开始,不断寻找子串与文法G中某个产生式P的候选式进行匹配,并用P的左部代替(归约)之,逐步归约到开始符号S
移进-归约思想:设置一个栈,将输入符号逐个移进栈中,栈顶形成某产生式的又不时,就用左部去替换,称为归约。从右部推导出左部,是一种自下而上的语法分析方法
递归下降属于自上而下语法分析。移进-归约属于自下而上语法分析
第三章 数据结构
一 线形结构
1.线性表
概念
- 每个元素最多只有一个出度和一个入度,表现为一条线装.线性表按照存储范式分为顺序表和链表.
存储结构
-
顺序存储: 用一组地址联系度的存储单元一次存储线性表中的数据元素,使得逻辑上相邻的元素物理上也相邻
- 优点:可以随机存取表中元素,读取、查找比较方便。
- 缺点:必须按最大可能长度预分配存储空间,存储空间的利用率低,表的容量难以扩容,是一种静态存储结构;插入与删除需要移动大量元素,平均移动次数为n/2。
-
链式存储: 存储各数据元素的结点的地址并不要求是连续的,数据元素逻辑上相邻,物理上分开
- 优点:插入与删除不需要移动元素,较为方便,只需要修改指针即可;存储空间不需要提前确定,可以动态改变,是一种动态存储结构。
- 缺点:不能对数据元素进行随机访问;需要存储指针,有空间浪费存在。
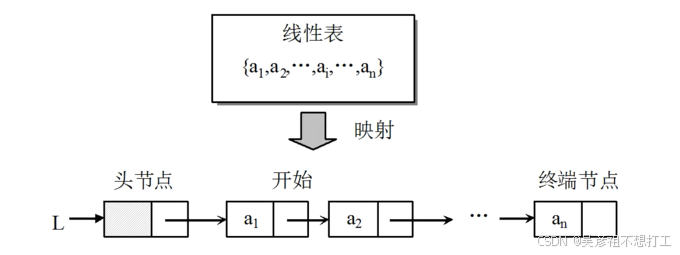
n个元素的有限序列。特点:
①存在唯一一个被称为"第一个”的元素;
②存在唯一一个被称为"最后一个”的元素;
③除第一个元素外,集合中的每个元素均只有一个直接前驱;
④除最后一个元素外,集合中的每个元素均只有一个直接后继。
2.栈
概念
- 栈是限定仅在表尾进行插入或删除操作的线性表,表尾称为栈顶,表头称为栈底,是一种先进后出(LIFO)的线性结构。栈的应用:括号匹配、迷宫求解和汉诺塔。
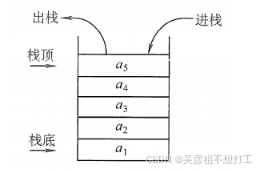
栈顶(Top):线性表允许进行插入删除的那一端。
栈底(Bottom):固定的,不允许进行插入和删除的另一端。
空栈:不含任何元素的空表。
举例:
利用栈对算术表达式10*(40- 30 /5)+20求值时,存放操作数的栈(初始为空)的容量至少为___,才能满足暂存该表达式中的运算数或运算结果的要求。
A.2 B.3 C.4 D.5
答案:C
解析:在计算算术表达式的值时,通常需要使用两个栈:一个运算符栈和一个操作数栈。对于给定的表达式
10*(40 -30/5)+20可以按照步骤进行1、将表达式转换为后缀(逆波兰》表达式:1040305/*20+。(简单求法:按运算的优先顺序依次将运算符写在运算对象的后面,例如,把atb写成ab+)
2、从左到右扫描表达式,遇到数字就将其压入操作数栈中,遇到运算符就从操作数栈中弹出相应的操作数进行计算,计算结果再压入操作数楼中在这个过程中,需要使用一个运算符栈来保存运算符及其优先级。
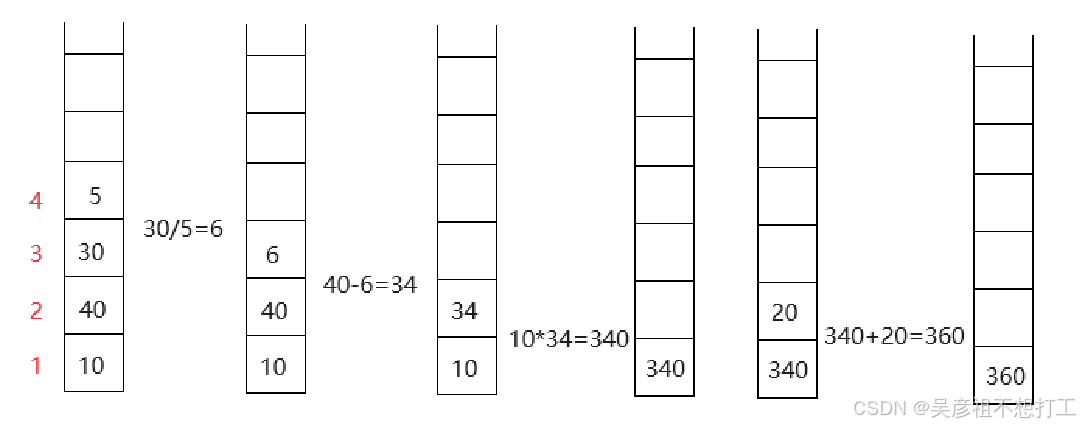
3.队列
概念
- 队列是只允许在表的一端进行插入,在另一端进行删除操作的线性表,允许插入的一端称为队尾,允许删除的一端称为队头,是一种先进先出(FIFO)的线性结构。队列的应用:操作系统中的作业排队。

队头(Front):允许删除的一端,又称队首。
队尾(Rear):允许插入的一端。
空队列:不包含任何元素的空表。
队列的顺序存储结构
队列的顺序实现是指分配一块连续的存储单元存放队列中的元素,并附设两个指针:队头指针 front指向队头元素,队尾指针 rear 指向队尾元素的下一个位置。
- 顺序队列
初始状态(队空条件):
Q->front == Q->rear == 0。
进队操作:队不满时,先送值到队尾元素,再将队尾指针加1。
出队操作:队不空时,先取队头元素值,再将队头指针加1。
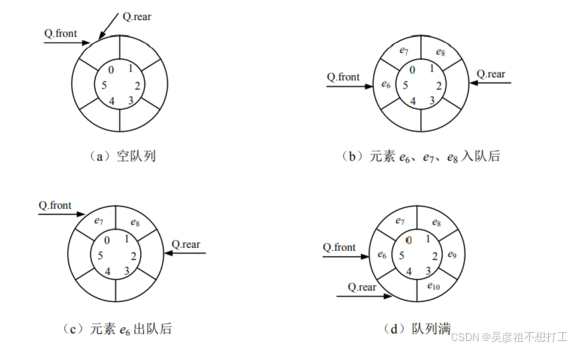
- 循环队列
循环队列是一种顺序表示的队列,用一组地址连续的存储单元依次存放从队头到队尾的元素。由于队列中队头和队尾的位置是动态变化的,要附设两个指针front和rear,分别指示队头元素和队尾元素在数组中的位置。
初始时:Q->front = Q->rear=0。
队首指针进1:Q->front = (Q->front + 1) % MAXSIZE。
队尾指针进1:Q->rear = (Q->rear + 1) % MAXSIZE。
队列长度:(Q->rear - Q->front + MAXSIZE) % MAXSIZE。
- 优先队列:元素被赋予优先级。当访问元素时具有最高优先级的元素最先删除。 使用堆来存储,因为其不是按照元素进队列的顺序决定的。
4.串
串是仅由字符构成的有限序列,是一种线性表,一般记为s = ‘a1a2…an’,其中,s是串的名称,用单引号括起来的字符序列是串值。串中字符的个数n称为串的长度。
空串:长度为0的串称为空串,空串不包含任何字符。
空格串:由一个或多个空格组成的串。
子串:由串中任意长度的连续字符构成的序列称为子串。含有子串的串称为主串。空串是任意串的子串。
串的模式匹配算法
子串的定位操作,用于查找子串在主串中第一次出现的位置的算法。
-
布鲁特-福斯算法:基本的模式匹配算法,其基本思想是从主串的第一个字符起与模式串的第1个字符比较,若相等,则继续逐个字符进行后续的比较;否则从主串的第2个字符起与模式串的第1个字符重新比较,直至模式串中每个字符依次和主串中的一个连续字符序列相等为止,此时称为匹配成功,否则称为匹配失败。
-
KMP算法:是对基本匹配算法的改进,其改进之处在于:每当匹配过程中出现相比较的字符不相等时,不再需要回溯主串的字符位置指针,而是利用已经得到“部分匹配”结果,将模式串向右“滑动”尽可能远的距离,再继续比较即可。
- next函数:next数组用于优化字符串匹配过程,避免不必要的回溯。对当模式串第j个字符与主串失配时,模式串中与主串继续匹配的位置。
n e x t [ j ] = { 0 , 当j=1时 m a x { k ∣ 1 < k < j , P 1 P 2 … P k − 1 = P j − k + 1 … P j − 1 } , 当集合不为空时 1 , 其他 next[j] = \begin{cases} 0, & \text{当j=1时} \\ max\{k | 1 < k < j, P_1P_2…P_{k-1} = P_{j-k+1}…P_{j-1}\}, & \text{当集合不为空时} \\ 1, & \text {其他} \\ \end{cases} next[j]=⎩ ⎨ ⎧0,max{k∣1<k<j,P1P2…Pk−1=Pj−k+1…Pj−1},1,当j=1时当集合不为空时其他
举例:
主串 a b a c d e f … 模式串 a b a b 此时第四个字符匹配失败,即
j=4
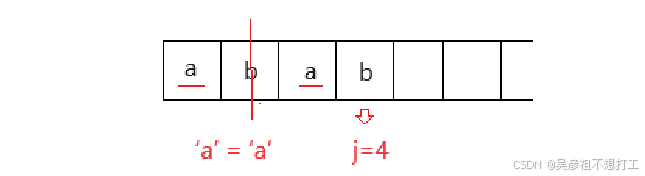
带入公式:
P1 = P3 ==> k-1 = 1,j-k+1 = 3 ==> k = 2
简单算法:
k = ‘a’ 字符串长度+1 = 1+1 =2
5.数组
概念
- 数组是定长线性表的扩展,N维数组是一个”同构”的数据结构,其每个数据元素类型相同,结构一致。可以表示为行向量形式或者列向量形式线性表,单个关系最多只有一个前驱和一个后继,本质是线性的。
特点
- 元素数目固定,元素类型相同,下标关系具有上下界的约束且有下标序列一般不做插入和删除运算,适用于顺序结构
数组存储地址计算:
假设每个元素占用存储长度len,起始地址a
| 数组类型 | 存储地址计算 |
|---|---|
一维数组a[n] | a[i]的存储地址为a+i*len |
二维数组a[m][n] | a[i][j]的存储地址为a+(i*n+j)*len(按行存储) a[i][j]的存储地址为a+(j*m+i)*len(按列存储) |
举例:
已知6行8列(a[6][8])的二维数组a中的各元素占两个字节,求元素a[2][5]**按行优先存储**的存储地址?
按行存储: 先优先存储2行,再存储到第5列,如下图所示
存储地址 = a + ( 2 行 ∗ 8 列 + 5 ) ∗ 2 字节 存储地址 = a+(2_行*8_列+5)*2_{字节} 存储地址=a+(2行∗8列+5)∗2字节
* * * * * * * * * * * * * * * * * * * * a[2][5]
6.矩阵
特殊矩阵
矩阵中的元素(或非0元素)的分布有一定的规律。常见的特殊矩阵有对称矩阵、三角矩阵和对角矩阵。
-
对称矩阵
n阶矩阵A中的元素满足aij = aji,其中1≤i,1≤j,则称为n阶对称矩阵。
假设以一维数组sa[n(n + 1)/2]作为n阶矩阵A的存储结构,则sa[k]与矩阵元素aij 之间的一一对应关系是:
k = { i ( i − 1 ) 2 + j − 1 , 当i≥j j ( j − 1 ) 2 + i − 1 , 当i<j k= \begin{cases} \frac {i(i-1)}{2}+j-1,& \text{当i≥j} \\ \frac {j(j-1)}{2}+i-1,& \text{当i<j} \\ \end{cases} k={2i(i−1)+j−1,2j(j−1)+i−1,当i≥j当i<j 在题目中选用特殊值带入计算即可
-
三角矩阵
矩阵的上三角或下三角(不包括对角线)中的元素均为常数c或零的n阶矩阵。

-
对角矩阵
矩阵中的非零元素都集中在以主对角线为中心的带状区域。示意图如下:

-
稀疏矩阵
在一个矩阵中,若非零元素的个数远远小于零元素的个数,且非零元素的分布没有规律,则称之为稀疏矩阵。一般来说,非零元素的个数小于5%,就可以称为是稀疏矩阵。
稀疏矩阵的存储方式:- 三元组,用三个域存储每个非零元素,即行、列、值。
- 十字链表,对于每个非零元素会有5个域,分别是行、列、值、指向同行下一个非零元素的指针right和指向同列下一个非零元素的指针down。
7.广义表
- 线性表的元素都是结构上不可分得单元素,而广义表的元素即可以单元素,也可以是有结构的表。
- 广义表一般记为:LS = (a1,a2,a3,…,an)
- 广义表中,LS 是表名,ai 是表元素,它可以是子表,也可以是单元素。
- n是广义表的长度,n = 0的广义表为空表;而递归意义的重数就是广义表的深度,即定义中包含括号的重数(单边括号的个数,原子的深度是0,空表的深度为1 )
- head( )取表头:
可以是第一个表元素,也可以是子表也可以是单元素 - tail( )取表尾:
除了第一个表元素,其它所有表元素构成的表称为表尾,非空广义表的表尾必定是一个表,即使表尾是单元素
二 树
- 树结构是一种非线性结构,树中的每一个数据元素可以有两个或两个以上的直接后继元素,用来描述层次结构关系
- 树是n个节点的有限集合(n>=0),单n=0时称为空树,在任一颗费空树中,有且仅有一个根节点;其余节点可分为m(m>0)个互不相交的有限子集T1,T2,…Tm其中每个Ti又都是一棵树,并且成为根节点的子树。
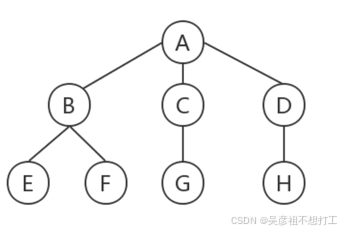
- 双亲、孩子和兄弟。结点子树的根称为该结点的孩子结点;相应地,该结点称为其子结点的双亲。具有相同双亲的结点互为兄弟。
- 结点的度。一个结点拥有子树的个数称为该结点的度。例如,在图中,A的度为3,B的度为2,C的度为1,D的度为1。
- 叶子结点。叶子结点是指度为0的结点,也称为终端结点。例如,在图中的E、F、G、H都是叶子结点。
- 结点的层次。例如,在图中的结点A在第一层,B、C、D在第二层,E、F、G、H在第三层、
- 树的深度。一棵树的最大层数为该树的深度(或高度)。例如,图中树的深度为3。
- 有序/无序树。如果树中各结点的各个子树是从左到右有序排列且不能交换,则称该树为有序树,否则称为无序树。
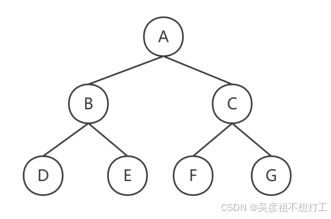
1.二叉树
二叉树是n个结点的有限集合,它或者是空树,或者是由一个根结点及两颗互不相交的分别称为左、右子树的二叉树所组成。与树的区别是二叉树各个结点的度最大为2.
2.满二叉树
在一棵二叉树中,如果所有非叶子结点都同时具有左孩子和右孩子,并且所有叶子结点都在同一层上,即一棵深度为k并且含有 2k-1 个结点的二叉树称为满二叉树。
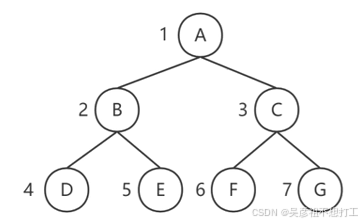
3.完全二叉树
一棵深度为k,有n个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。
4.二叉树的性质
- 在二叉树的第 i 层上最多有 2 i-1 个结点 (i ≥ 1)
- 深度为 k 的二叉树最多有2 k-1 个结点( k ≥ 1)
- 对于任何一棵二叉树,如果其叶子结点数为n0,度为2的结点数为 n2,则有 n0 = n2+ 1
- 节点总数n = 分支总数m+1 = n1 + n2
- 分支个数m = 1* n1 + 2* n2
- 具有n个结点的完全二叉树的深度为 [log2n] +1;
举例
已知树T的度为4,且度为4的结点数为7个、度为3的结点数5个、度为2的结点数为8个、度为1的结点数为10个,那么T的叶子结点个数为____。(注:树中结点个数称为结点的度,结点的度中的最大值称为树的度)
解析:
节点总数n = 分支总数m+1
节点总数n = n1 + n2 + …
分支个数m = 1* n1 + 2* n2+ …
{ n = m + 1 n = n 0 + n 1 + n 2 + n 3 + n 4 = n 0 + 10 + 8 + 5 + 7 = n 0 + 30 m = 1 ∗ n 1 + 2 ∗ n 2 + 3 ∗ n 3 + 4 ∗ n 4 = 10 + 16 + 15 + 28 = 69 \begin{cases} n=m+1 \\ n= n_0+n_1+n_2+n_3+n_4=n_0+10+8+5+7=n_0+30 \\ m=1*n_1+2*n_2+3*n_3+4*n_4=10+16+15+28=69 \end{cases}\\ ⎩ ⎨ ⎧n=m+1n=n0+n1+n2+n3+n4=n0+10+8+5+7=n0+30m=1∗n1+2∗n2+3∗n3+4∗n4=10+16+15+28=69
解的 n0 = 40
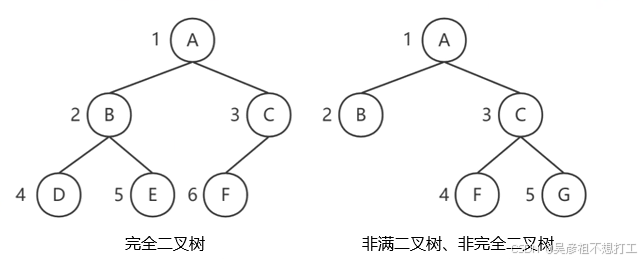
5.二叉树的存储结构
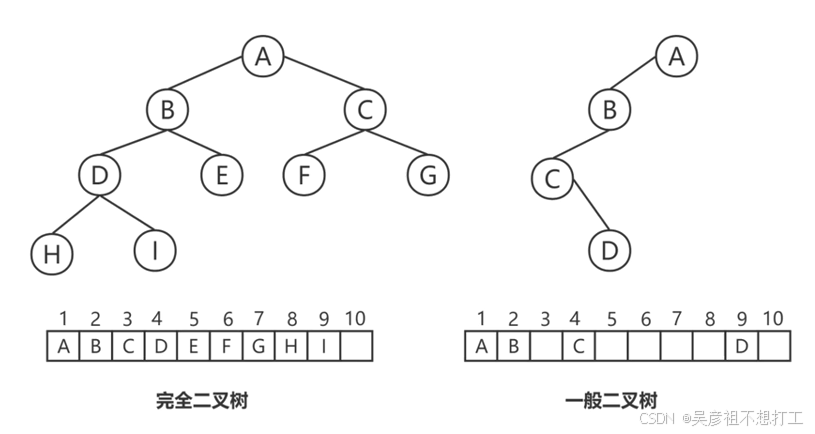
- 顺序存储
在采用顺序存储时,完全二叉树与一般二叉树相比节省了空间,这是因为一般二叉树需要添加一些“虚结点”而造成了空间的浪费,如图下图所示。
- 二叉树的链式存储结构
一般用二叉树表来存储二叉树节点,二叉树表中除了节点本身的数据外,还存储有左孩子节点的指针,右孩子节点的指针,即有一个数据 +两个指针。每个二叉链表节点存储一个二叉树节点,头指针则指向根节点.
6.二叉树的遍历
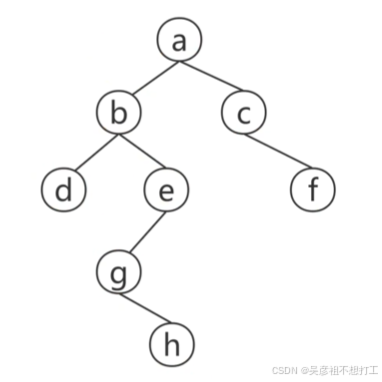
遍历是按某种策略访问树中的每个结点且仅访问一次的过程。二叉树的遍历可以分为:
前序遍历:根左右 abdeghcf
中序遍历:左根右 dbgheacf
后序遍历:左右根 dhgebfca
层次遍历:按层次,从上到下,从左到右 abcdefgh
7.线索二叉树
-
使用线索二叉树目的:
获取节点的前驱后后继信息 -
使用线索二叉树原因:
二叉树的链式存储只能获取到某节点的左孩子和右孩子节点,无法获取其遍历时的前驱和后继节点。因此可以在链式存储中增加两个指针域,使其分别指向前驱和后继节点,但是这样太浪费存储空间
若n个结点的二叉树使用二叉链表存储,则必然有n+1个空指针域,利用这些空指针域来存储结点的前驱和后继结点信息,为此需要增加两个标志,以区分指针域存放的到底是孩子结点还是遍历结点,如下:

8.最优二叉树(哈夫曼树)
-
最优二叉树也称为哈夫曼树,是一种带权路径长度最短的二叉树。
- 路径:树中一个结点到另一个结点之间的通路;
-
路径长度:通路上的分支个数;
-
树的路径长度:根结点到每一个吐子结点之间的路径长度之和;
-
权:结点代表的值;
-
结点的带权路径长度:该结点到根结点之间的路径长度与该结点权值的乘积;
-
树的带权路径长度:树中所有叶子结点的带权路径长度之和。
-
最优二叉树的构建
假设有n个权值,则构造出的哈夫曼树有n个叶子结点。n个权值分别设为W1、W2 … Wn,则哈夫曼树的构造规则为:
-
将 W1、W2 … Wn 看成是有n棵树的森林(每棵树仅有一个结点);
-
在森林中选出两个根结点的权值最小的树合并(所以哈夫曼树的度不可能为1),作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
-
从森林中删除选取的两棵树,并将新树加入森林;
-
重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树.
- 哈夫曼编码
霍夫曼编码又称哈夫曼编码(赫夫曼编码),也就是总字符编码长度最短的编码。先构造哈夫曼树,左分支表示字符“0”,右分支表示字符“1”,可得到字符的哈夫曼编码。注意:构造哈夫曼树时一般遵循权值“左小右大”的原则。
举例
下表为某文件中字符的出现频率,采用霍夫曼编码对下列字符编码,则字符序列“bee”的编码为____;编码“110001001101”对应的字符序列是____。
字符 a b c d e f 频率 45 13 12 16 9 5
- A.10111011101 B.10111001100 C.001100100 D.11001101
- A.bad B.bee C.face D.bace
解析:构建哈夫曼树,字符为结点,频率为权值
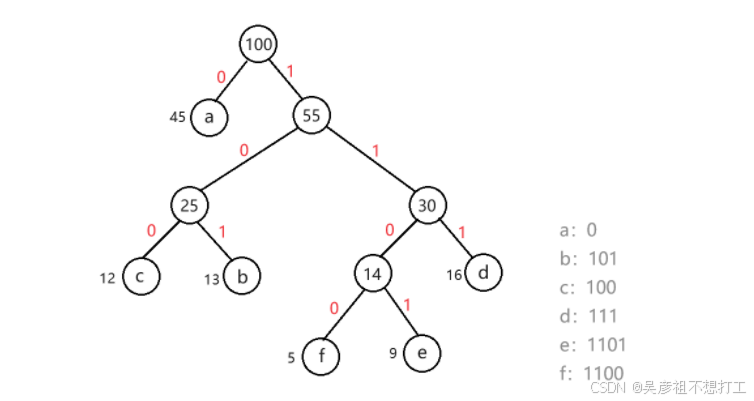
由图中的哈夫曼编码得知:
“bee”的编码为 101 1101 1101
“face”的编码为 1100 0 100 1101
9.树和森林
-
树的存储结构
-
双亲表示法:用一组连续的地址单元存储树的节点,并在每个节点中附带一个指示器,指出其双亲节点所在数组元素的下标。
-
孩子表示法:在存储结构中用指针指出节点的每个孩子,为树中的每个节点的孩子建立一个链表。
-
孩子兄弟表示法:又称为二叉链表表示法,为每个存储节点设置两个指针域,分别指向该节点的第一个孩子和下一个兄弟节点。
-
-
树和森林的遍历
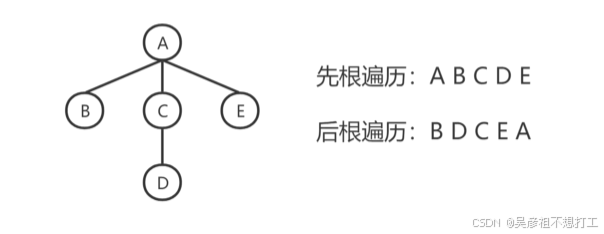
由于树中的每个节点可能有多个子树,因此遍历树的方法有两种:-
先根遍历: 先访问根节点,再依次遍历根的各颗子树。
-
后根遍历: 先遍历根的各颗子树,再访问根节点。
-
森林中有很多颗树,森林的遍历方法也分为两种,与树的遍历类似,就是对森林中的每颗树都依次做先根遍历或后根遍历。
-
树和二叉树的转换
转换原理:树的最左边结点作为二叉树的左子树,树的其他兄弟结点作为其左边兄弟结点的右子树。任何一颗与树对应的二叉树,其右子树必为空。如下图中第一棵树转为二叉树:
B作为A的子树,C、D作为B的兄弟结点,C作为B的右子树,D做C的右子树。
二叉树森林转二叉树同理:
根节点为A的树作为左子树,根节点E、G的树为它的兄弟树,E树做A树的右子树,G树做E树的右子树。
相反的二叉树转森林,将所有右子树拆出来,再将拆出的二叉树转为树。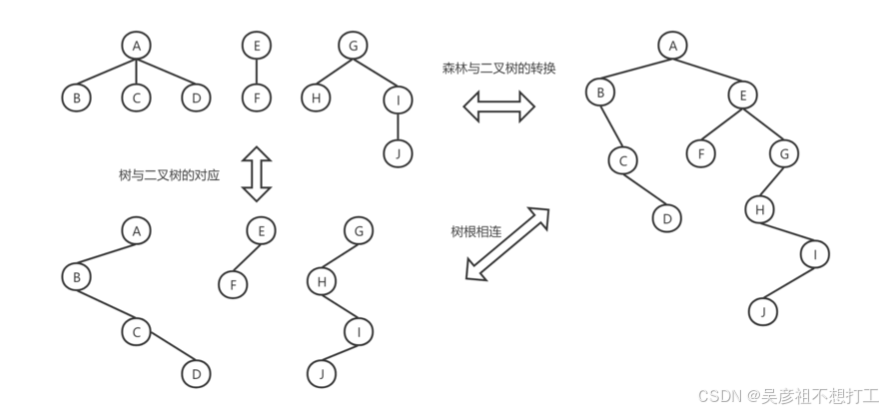
10.二叉排序树(二叉查找树、二叉搜索树)
查找二叉树上的每个结点都存储一个值,且每个结点的所有左孩子结点值都小于父节点值,而所有右孩子结点值都大于父结点值,是一个有规则排列的二叉树,这种数据结构可以方便查找,插入等数据操作。
二叉排序树的查找效率取决于二叉排序树的深度,对于结点个数相同的二叉排序树,平衡二叉树的深度最小,而单枝树的深度是最大的,故效率是最差的。
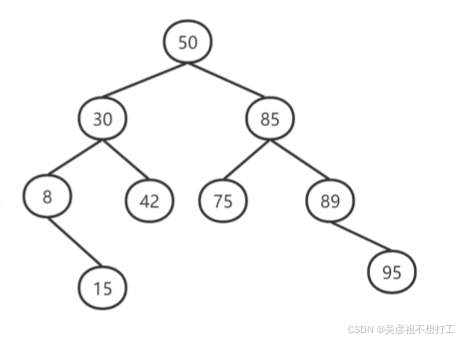
11.平衡二叉树
平衡二叉树,又称AVL树,它或者是一棵空树,或者具有如下性质:
- 它的左子树和右子树都是平衡二叉树;
- 左子树和右子树的深度之差的绝对值不超过1。
希望任何序列构成的二叉排序树都是平衡二叉树,这样其平均查找长度与log(n)同量级。
三 图
1.图的定义
图也是一种非线性结构,图中任意两个顶点之间都可能有直接关系,相关定义如下:
- 有向边和无向边:带箭头的单通道为有向边,不带箭头的双通道为无向边;
- 无向图:图中任意顶点之间均为无向边;
- 有向图:图中任意顶点之间均为有向边;
- 完全图:①无向完全图中,两两顶点之间均有连线,n个顶点的无向完全图有
n*(n-1)/2条边;②有向完全图中,两两顶点之间均有连线,n个顶点的有向完全图有n*(n-1)条边。 - 路径:存在一条通路,可以从一个顶点到达另一个顶点,有向图的路径也是有方向的。
- 连通图和连通分量:针对无向图。若从顶点y到顶点u之间是有路径的,则说明v和u之间是连通的,若无向图中任意两个顶点之间都是连通的,则成为连通图。无向图G的极大连通子图称为其连通分量。
- 强连通图和强连通分量:针对有向图。若有向图中任意两个顶点之间都相互存在路径,即存在顶点v到顶点u,也存在顶点u到顶点v的路径,则称为强连通图。有向图中的极大连通子图称为其强连通分量。
- 生成树:一个连通图的生成树就是该图的连通性不变,但没有环路的子图。一个有n个顶点的生成树有且仅有n-1条边。
- 网:边带权值的图称为网。

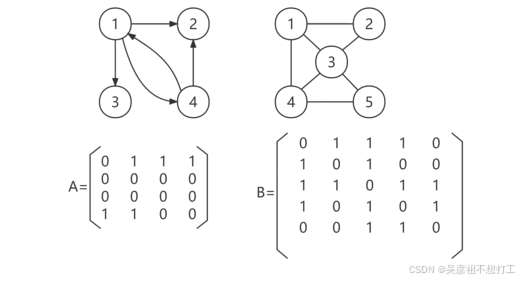
2.图的存储结构
图的存储主要有两种:邻接矩阵和邻接表。
- 邻接矩阵
n个顶点的图可以用n*n的邻接矩阵来表示。如果顶点 i 到顶点 j 存在边,则矩阵元素A[ij]的值置为1,否则为0。
- 邻接表
邻接表是链式存储结构。用一个一维数组存储所有的顶点,对于数组中的每个顶点都生成一个链表。链表中每个顶点(表结点〉包括顶点号、顶点信息(如边的权值)、以及指向下一个顶点的指针。
表结点的个数 = 图边的个数
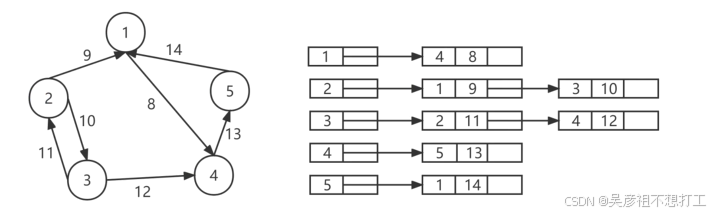
-
图的遍历
图的遍历是从图中的任意一个顶点出发,对图中的所有顶点访问一次且只访问一次。分为深度优
先搜索和广度优先搜索。- 深度优先搜索
类似于树的先根遍历。①第一步:访问一顶点V;②第二步:依次搜索顶点V的所有邻接顶点;③第三步:若邻接顶点未被访问,则深度优先搜索邻接顶点,若已被访问,则跳到顶点V的下一个邻接顶点。
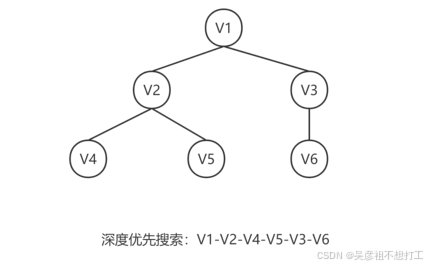
- 广度优先搜索
类似于树的层次遍历。①第一步:访问一顶点V;②第二步:依次访问顶点V的所有未被访问的邻接点;③第三步:分别访问这些邻接点的未被访问的所有邻接点。广度优先搜索体现为“深度越小越优先被访问”。
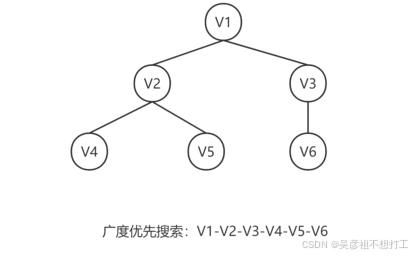
两种优先搜索的时间复杂度:使用邻接矩阵均为O(n2),使用邻接表均为O(n+e),其中n为顶点的个数,e为边的个数。
- 深度优先搜索
3.生成树和最小生成树
生成树:一个连通图的生成树就是该图的连通性不变,但没有环路的子图。一个有n个顶点的生成树有且仅有n-1条边。
最小生成树:①包含连通图的所有顶点的树;②有且仅有n-1条边;③这些边的权值最小。注意:最小生成树是一棵树,而不是图,也没有环路。
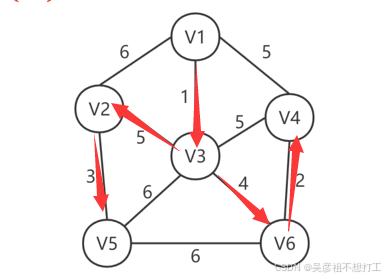
求连通带权无向图的最小生成树:
-
普里姆算法(Prim)
选择一条权值最小的边,并选中边的顶点 ,从已选顶点中连接权值最小的边,直至连接所有顶点,但不能出现环路。时间复杂度为O(n2), n为顶点个数,因此只与顶点相关,适用于求稠密图的最小生成树。 -
克鲁斯卡尔算法(Kruskal)
选择权值最小的边连接,直至连接所有的顶点,但不能出现环路。时间复杂度为O(elog2e),e为边的个数,因此只与边相关,适用于求稀疏图的最小生成树。
4.拓扑排序和关键路径
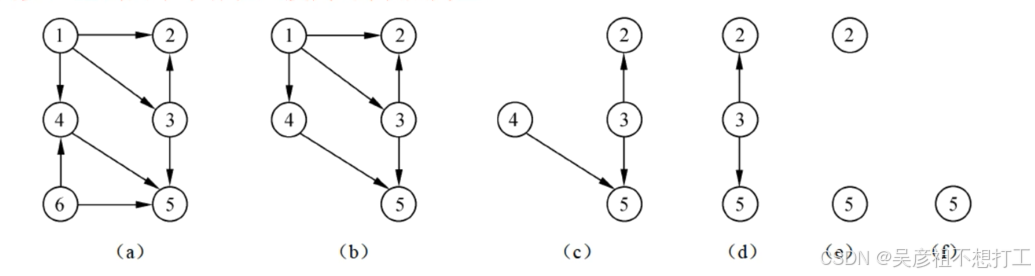
-
AOV网和拓扑排序
AOV网:如果有向图的顶点表示活动,有向边表示活动之间的优先关系,则称这样的图为以顶点表示活动的网。对AOV网进行拓扑排序,若顶点全部输出,则不存在环路。
拓扑排序:①在AOV网中选择入度为O的顶点并输出;②从网中删除该顶点及与该顶点有关的弧;③重复前两步,直到网中不存在入度为0的顶点为止。
-
AOE网和关键路径
AOE网:如果有向图的顶点表示事件,有向边表示活动,边的权值表示活动持续时间,则这种带权有向图称为以边表示活动的网。
在从源点到汇点的路径中,长度最长的路径称为关键路径。关键路径上的所有活动均是关键活动。如果任何一项关键活动没有按期完成,就会影响整个工程的进度,而缩短关键活动的工期通常可以缩短整个工程的工期。关键路径上的长度就是完成整个工程项目的最短工期。
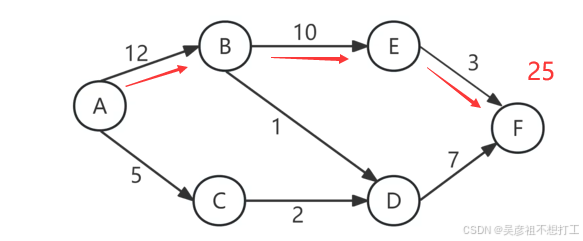
5.最短路径
从源点到各顶点最短的路径为最短路径。
-
迪杰斯特拉(Dijkstra)
使用贪心策略解决图的单源最短路径问题。 -
弗洛伊德(Floyd)
使用动态规划的思想解决图的多源点之间最短路径的问题。
四 查找
1.顺序查找
顺序查找的基本思想:从表的一端开始,逐个将表中记录的关键字与给定值进行比较,若相等,则查找成功;若整个表中记录的关键字与给定值均不相等,则查找失败。
平均查找长度:
A
S
L
=
n
+
1
2
其中n为表中记录的个数
ASL= \frac{n+1}{2} \text{其中n为表中记录的个数}
ASL=2n+1其中n为表中记录的个数
- 优点:算法简单且适应面广,对表的结构没有要求,表中记录也无须有序。
- 缺点:n值较大时,平均查找长度较大,查找效率较低。
2.二分查找(折半查找)
假设表中的元素存储在一维数组r[1,…,n]中,且表中元素按递增排序,则折半查找的基本思想为:将给定值key与表中中间位置元素r[mid]进行比较,若key == r[mid],则查找成功;若key >r[mid],则给定值key在后半个子表r[mid + 1,…,n]中继续递归查找;若key <r[mid],则给定值key在前半个子表r[1,…, mid- 1]中继续递归查找;递归以上步骤,直到查找成功或子表为空为止。
平均查找长度:
A
S
L
=
l
o
g
2
(
n
+
1
)
−
1
其中n为表中记录的个数
ASL=log_2(n + 1)-1 \text{其中n为表中记录的个数}
ASL=log2(n+1)−1其中n为表中记录的个数
- 优点:查找效率较高。
- 缺点:顺序存储且表中元素必须有序排列(前提条件);插入和删除需要移动大量元素。
3.分块查找
又称为索引顺序查找,是对顺序查找方法的一种改进,查找效率介于顺序查找和折半查找之间。在分块查找中,首先将表分成若干块,每一块的关键字不一定有序,但块之间是有序的 ;此外还建立了一个索引表,索引表按关键字有序排列。
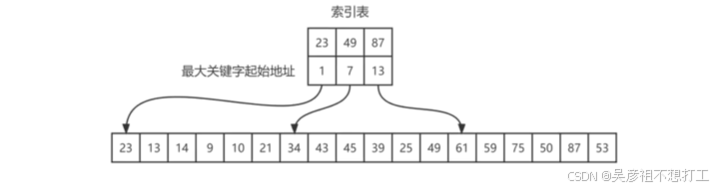
平均查找长度:
A
S
L
=
1
2
(
n
s
+
s
)
+
1
b为索引表的大小,s为每块记录的个数
ASL=\frac{1}{2}(\frac{n}{s} + s)+1 \text{b为索引表的大小,s为每块记录的个数}
ASL=21(sn+s)+1b为索引表的大小,s为每块记录的个数
- 优点:查找效率好于顺序查找,可通过索引表,查找给定值所在的块。
- 缺点:查找效率不及折半查找。
4.哈希表
前面三种查找都是以关键字比较为基础,而哈希表,也称为散列表,通过计算以记录的关键字为自变量的函数(哈希函数)来得到该记录的存储地址。在查找操作时,用同一哈希函数H(key)计算待查记录的存储地址,到相应的存储单元中匹配信息来判定是否查找成功。
-
哈希函数的构造方法
直接定址法、数字分析法、平方取中法、折叠法、随机数法、除留余数法等。 -
处理冲突的方法
对于不同的关键字,却有相同的哈希函数值,则称为冲突。解决冲突就是为出现冲突的关键字找到另一个尚未使用的哈希地址。
①开放定址法
H i = ( H ( k e y ) + d i ) % m , i = 1 , 2 , … , k ( k ≤ m − 1 ) 其中 H i 为哈希地址, H ( k e y ) 为哈希函数 , m 为哈希表表长, d i 为增量序列 H_i = (H(key)+d_i)\%m,i=1,2,…,k(k≤m-1) \\其中H_i为哈希地址,H(key)为哈希函数,m为哈希表表长,d_i为增量序列 Hi=(H(key)+di)%m,i=1,2,…,k(k≤m−1)其中Hi为哈希地址,H(key)为哈希函数,m为哈希表表长,di为增量序列
di = 1,2,…,m -1,称为线性探测再散列;
di = 12,-12,22,-22,…,±k2(k ≤m/2),称为二次探测再散列;
di 伪随机数序列,称为随机探测再散列;
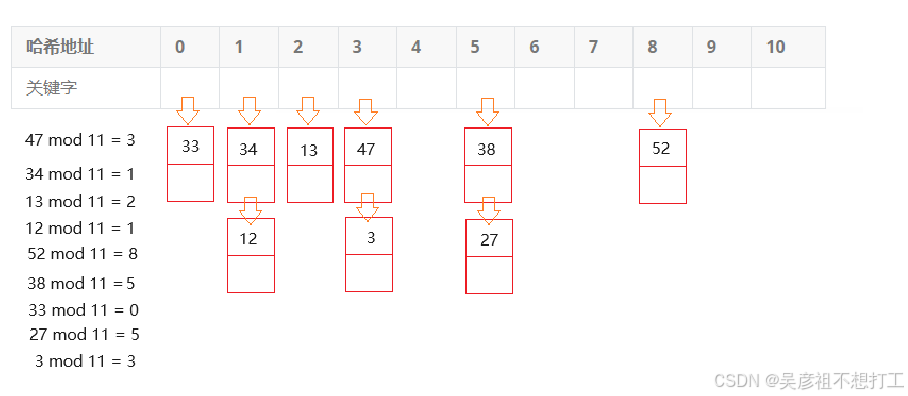
举例
设关键码序列为“47,34,13,12,52,38,33,27,3”,哈希表长为11,哈希函数为
Hash(key) = key mod 11,请使用线性探测再散列解决冲突,构造哈希表,并求平均查找长度。
哈希地址 0 1 2 3 4 5 6 7 8 9 10 关键字 哈希表长11,即m=11,通常序列数为q = 9时,m≥q,且取最小的质数,即11

②链地址法
将冲突的元素存放在一个链表里,通过链表查找冲突的数据元素。
上题改用链地址法存储
五 排序
排序的定义:将任意排列的一组元素变成一组有序排列(递增或递减)的元素。排序的分类:
-
稳定排序与不稳定排序:待排元素中的相同值在排序后的次序关系不变,这样的排序称为稳定排序,否则为不稳定排序。
-
内排序和外排序:排序在内存中进行的称为内排序,在外存中进行的称为外排序。
1.直接插入排序
将待排元素插入到有序序列的合适位置中。是一种稳定的排序方法。
将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
时间复杂度:在最好情况下(刚好序列是待排的顺序)的时间复杂度为O(n),在最坏情况下(序列与待排顺序正好相反)的时间复杂度为O(n2)。
空间复杂度:需要一个临时变量记录待排元素的值(哨兵),空间复杂度为O(1)。
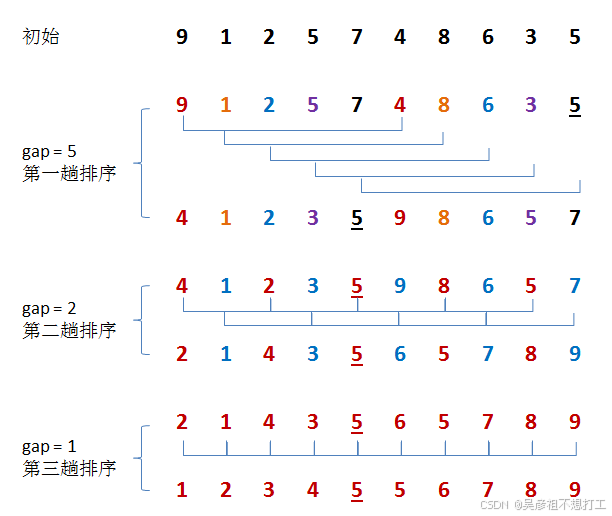
2.希尔排序
直接插入排序的改进,本质是一种分组插入排序,希尔排序的基本思想是:将待排元素按一定“增量”进行分组,然后对每个分组分别进行直接插入排序,随着增量的减小,一直到1,从而使整个序列变得有序。是一种不稳定的排序方法。
增量的取值:
d
1
=
n
2
,
d
2
=
d
1
2
,
d
3
=
d
2
2
,
…
,
d
i
=
1
,
n
待排序列的个数
(
每次取上次的一半
)
d_1= \frac{n}{2},d_2= \frac{d_1}{2},d3 = \frac{d_2}{2},…,d_i = 1, \ \ \ n 待排序列的个数(每次取上次的一半)
d1=2n,d2=2d1,d3=2d2,…,di=1, n待排序列的个数(每次取上次的一半)
时间复杂度:约为O(n1.3)。
空间复杂度:仅需要一个元素的辅助空间,空间复杂度为O(1)。
3.冒泡排序
冒泡排序是交换排序的一种,是一种稳定的排序方法。
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
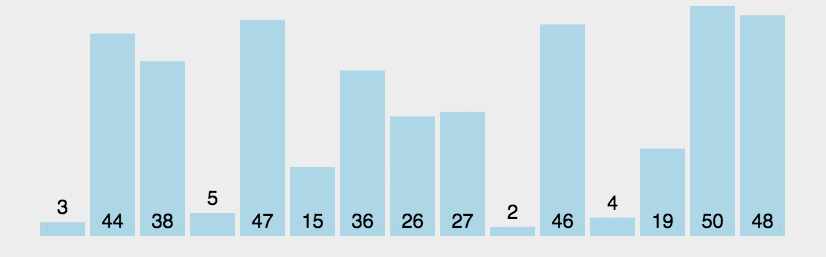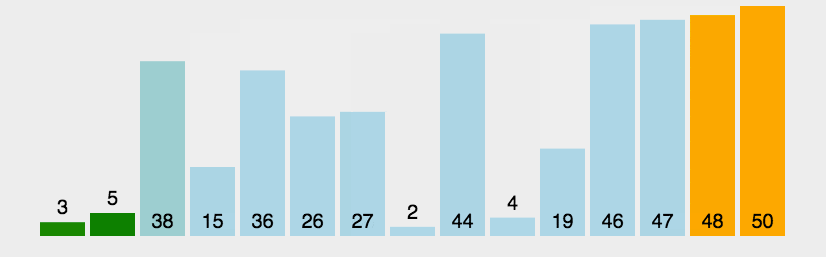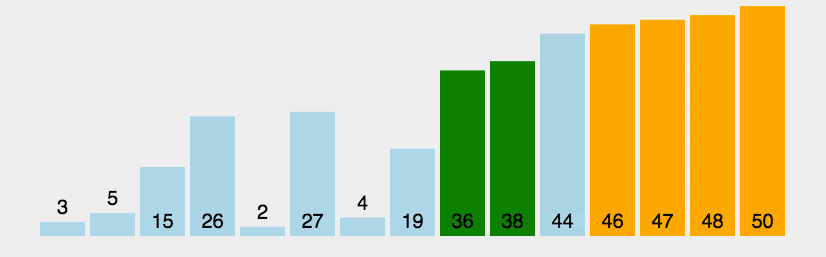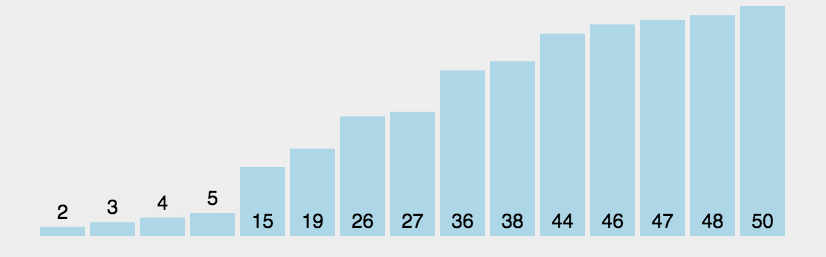
时间复杂度:O(n2)。
空间复杂度:仅需要一个元素的辅助空间,空间复杂度为O(1)。
4.快速排序
快速排序是对冒泡排序的一种改进。快速排序的基本思想是:通过一趟排序将要排序的数据分成独立的两个部分,其中一部分的所有数据都比另外一部分的所有数据要小,然后再分别对这两个部分进行决速排序,整个排序过程可以递归进行,从而使整个序列有序。是一种不稳定的排序方法。
从数列中挑出一个元素,称为 “基准”(pivot);
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
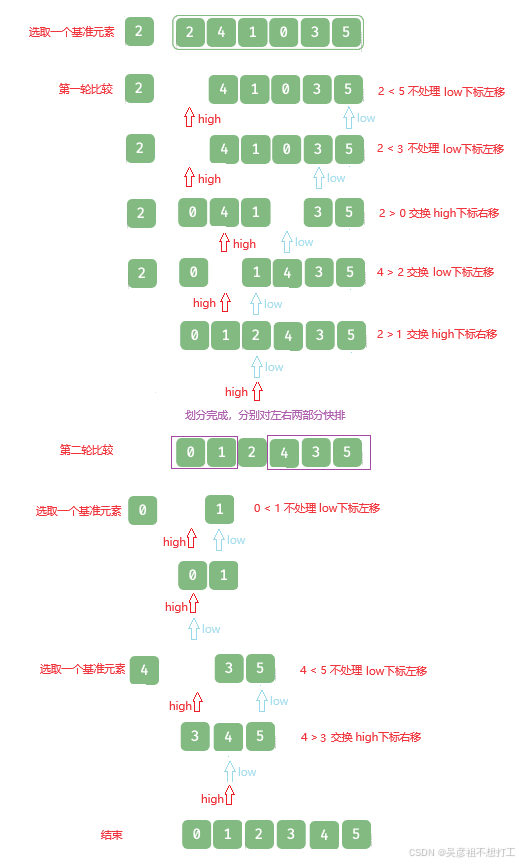
时间复杂度:O(nlog2n);在最坏情况下,即初始序列按关键字有序或基本有序时,快速排序的时间复杂度为O(n2)。
空间复杂度:需要栈空间来实现递归,栈空间最大深度为[log2n]+1,则空间复杂度为O(log2n)。
5.简单选择排序
选择排序的一种,简单选择排序的基本思想是:从待排元素中选出最小的元素放在已排序序列的末尾,重复以上过程。是一种不稳定的排序方法。
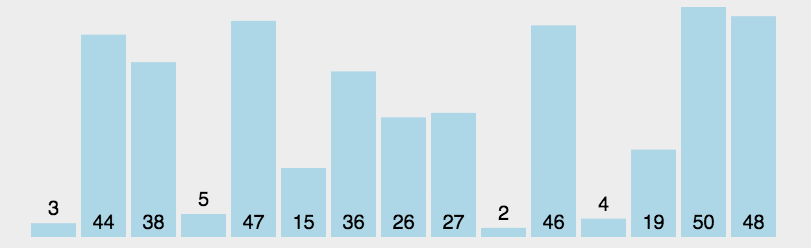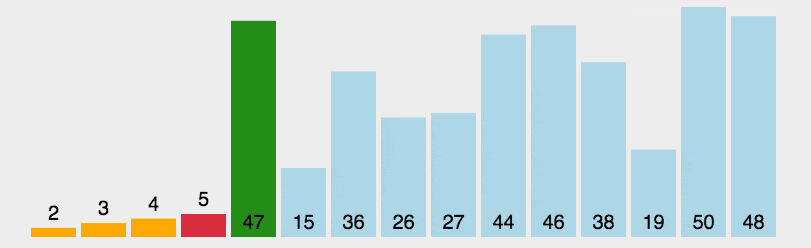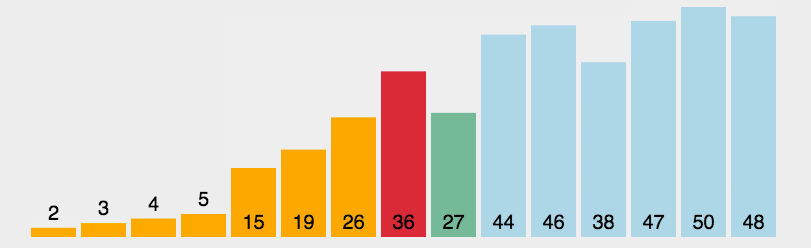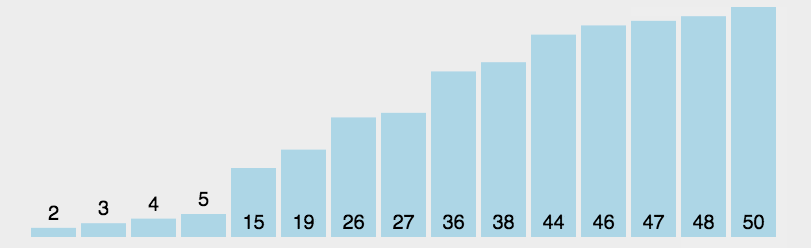
时间复杂度:O(n2);
空间复杂度:仅需要一个元素的辅助空间,空间复杂度为O(1)。
6.堆排序
选择排序的一种。堆是一种特殊的完全二叉树,堆顶元素(根结点)是堆中的最大值(或最小值),并且任何一颗子树也都是堆。若堆顶元素为最小值,则为小根堆;若堆顶元素为最大值,则为大根堆。
- 大根堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列;
- 小根堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列;
堆排序的基本思想:
①将待排元素建立一个初始堆
②输出堆顶的元素,即最大值(或最小值)
③将剩余待排元素重新建立一个新的堆,重复以上步骤。
建立初始堆的步骤:
①对待排元素按层次遍历,构建一棵完全二叉树
②从最后一个非叶子节点开始,按照堆的定义进行调整。
时间复杂度:O(nlog2n);
空间复杂度:仅需要一个元素的辅助空间,空间复杂度为O(1)。
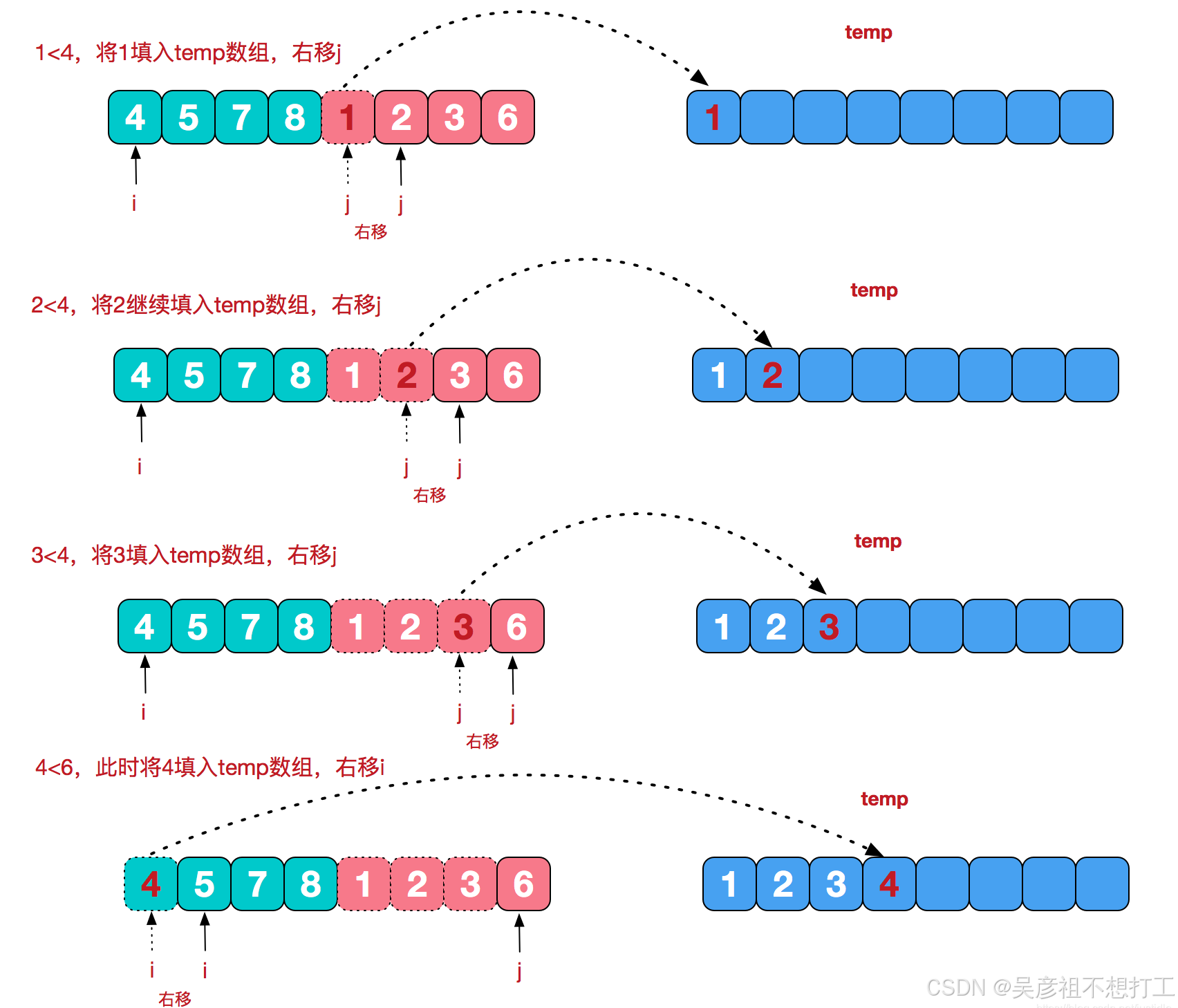
7.归并排序
归并排序的基本思想是:是将两个有序序列合并为一个有序序列。和快速排序一样,是一种采用分治法的排序方法。是一种稳定的排序方法。
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置;
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
- 重复步骤 3 直到某一指针达到序列尾;
- 将另一序列剩下的所有元素直接复制到合并序列尾。
合并两个有序数组流程:
时间复杂度:;
空间复杂度:需要n个元素的辅助空间,空间复杂度为O(n)。
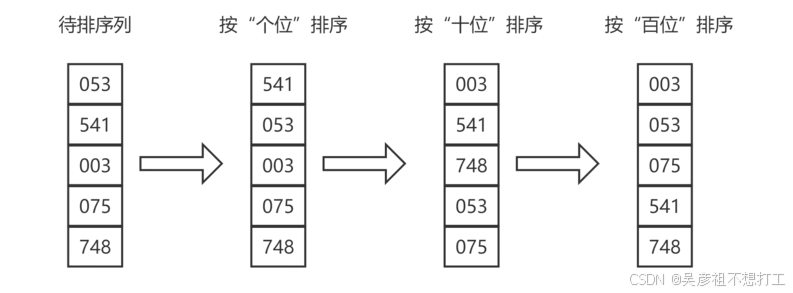
8.基数排序
基数排序的基本思想是:按组成关键字的各个数位的值进行排序。是分配排序的一种。是一种稳定的排序方法。
时间复杂度:O(d(n +r)),其中n为待排元素的个数,d为关键字的位数,r是进制基数;
空间复杂度:O(rd)。
9.总结
重点:喜欢这样考复杂度和稳定性
| 排序方法 | 时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|
| 直接插入排序 | O(n2) | O(1) | 稳定 |
| 简单选择排序 | O(n2) | O(1) | 不稳定 |
| 冒泡排序 | O(n2) | O(1) | 稳定 |
| 希尔排序 | O(n1.3) | O(1) | 不稳定 |
| 快速排序 | O(nlog2n) | O(log2n) | 不稳定 |
| 堆排序 | O(nlog2n) | O(1) | 不稳定 |
| 归并排序 | O(nlog2n) | O(n) | 稳定 |
| 基数排序 | O(d(n +r)) | O(rd) | 稳定 |
第四章 操作系统
1.操作系统的基本概念
-
操作系统定义及作用
操作系统的定义:能有效地组织和管理系统中的各种软/硬件资源,合理地组织计算机系统工作流程,控制程序的执行,并且向用户提供一个良好的工作环境和友好的接口。
操作系统的两大作用:
(1)通过资源管理提高计算机系统的效率;
(2)改善人机界面向用户提供友好的工作环境。 -
操作系统特征和功能
特征:并发性、共享性、虚拟性、不确定性。
功能:进程管理、文件管理、存储管理、设备管理和作业管理。 -
操作系统的分类
批处理操作系统、分时燥作系统(轮流使用CPU工作片)、实时操作系统(快速响应)、网络操作系统、分布式操作系统文物理分散的计算机互联系统)、微机操作系统(Windows)、嵌入式操作系统。
2.进程管理
- 程序与进程
进程由**程序、数据和进程控制块(PCB)**组成。进程是资源分配和独立运行的基本单位。特征:动态性、并发性、共享性、独立性、结构性、制约性。
进程与程序的区别:
(1)进程是动态的,程序是静态的,进程是程序在数据集上的一次执行;
(2)进程具有并发性,程序没有;
(3)进程是资源分配的基本单位,程序不是;
(4)进程与程序不是一一对应的,**一个进程通常对应一个程序,**而一个程序可以对应零个或多个进程。
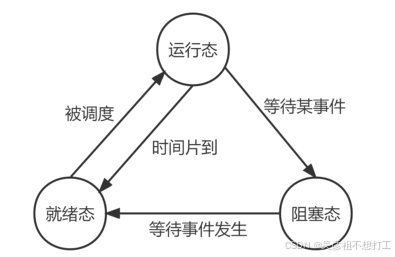
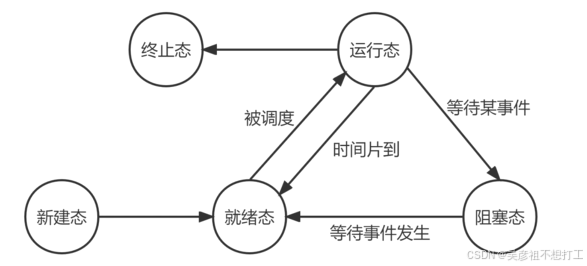
- 进程的状态及其转换
三态模型:运行态、就绪态和阻塞态。
五态模型:运行态、就绪态、阻塞态、新建态和终止态。
-
进程控制
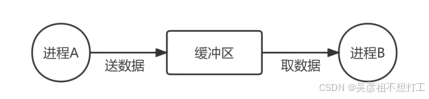
多个并发进程存在资源共享和相互合作,因此进程之间需要进行通信。
同步和互斥
同步是合作进程间的直接制约问题,互斥是申请临界资源进程间的间接制约问题。
进程的同步:系统中需要相互合作、协同工作的进程之间的通信。
进程的互斥:系统中多个进程因争夺临界资源而互斥执行。每次只能给一个进程使用的资源称为临界资源,如打印机。
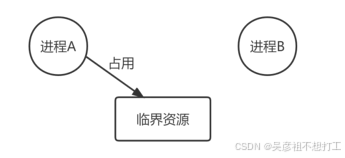
信号量操作(PV操作)
两类信号量:互斥信号量,对临界资源采用互斥访问,使用互斥信号量后其他进程无法访问,初值为1。同步信号量,对共享资源的访问控制,初值不定。
Р操作和V操作都是原子操作,用来解释进程间的同步和互斥原理;
V操作可以简单理解为将某资源+1,Р操作有两层含义:先将某资源-1,再判断是否小于0,即判断是否有该资源;(P操作申请资源,V操作释放资源)
举例
假设系统有n(n>5)个进程共享资源R且资源R的可用数为5。若采用PV操作,则相应的信号量S的取值范围应为___。
A.-1~n-1 B.-5~5 C.-(n- 1)~1 D.-(n- 5)~5S信号量指可用资源的数目 所以最多是 5个(所有资源可用数)
最小取值:所有资源全部被进程占有,多余的进程数目为(n-5),所以S的取值为:-(n- 5)~5
-
管程(Monitor)
是一种操作系统中的同步机制,它的引入是为了解决多线程或多进程环境下的并发控制问题。
在传统的操作系统中,当多个进程或线程同时访问共享资源时,可能会导致数据的不一致性、竞态条件和死锁等问题。为了避免这些问题,需要引入一种同步机制来协调并发访问
管程提供了一种高级的同步原语,它将共享资源和对资源的操作封装在一个单元中,并提供了对这个单元的访问控制机制。相比于信号量机制,用管程编写程序更加简单,写代码更加轻松。 -
进程调度
进程调度方式是指当有更高优先级的进程到来时如何分配CPU。调度方式分为可剥夺和不可剥夺两种。
可剥夺:指当有更高优先级的进程到来时,强行将正在运行进程的CPU分配给高优先级的进程;
不可剥夺:指当有更高优先级的进程到来时,必须等待正在运行的进程释放占用的CPU,然后将CPU分配给高优先级的进程。 -
三级调度
在某些操作系统中,一个作业从提交到完成需要经历高、中、低三级调度。-
高级调度:作业调度,决定哪个后备作业可以调入主系统做好运行的准备。
-
中级调度:对换调度,决定交换区中的哪个就绪进程可以调入内存。
-
低级调度:进程调度,决定内存中的哪个就绪进程可以占用CPU。低级调度是操作系统中最活跃、最重要的调度程序。
-
-
调度算法
- 先来先服务(FCFS):按先后次序分配CPU。有利于长作业,不利于短作业,有利于CPU繁忙型作业,不利于I/O繁忙型作业。
- 时间片轮转:分配给每个进程时间片,轮流占用CPU。通过时间片轮转提高进程并发性和响应时间特性,从而提高资源利用率。
- 优先级调度:系统选择优先级大的进程占用CPU。
- 多级反馈调度:时间片轮转和优先级调度结合而成。设置多个就绪队列1、2、3…n,每个队列分别赋予不同的优先级,队列1最高,队列n最低,分配不同的时间片长度;新进程先进入队列1的末尾,按FCFS原则,执行队列1的时间片;若未能执行完进程,则转入队列2的末尾,依次类推。
-
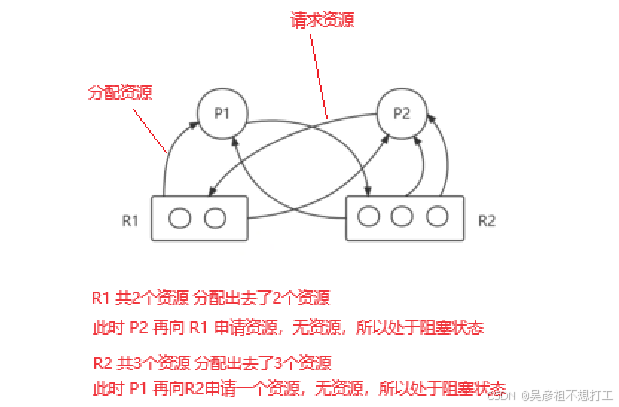
死锁
所谓死锁,是指两个以上的进程因相互争夺对方占用的资源而陷入无限等待的现象
死锁产生的4个必要条件
保持(进程占有资源并等待其他资源)、不可剥夺(系统不能剥夺进程资源)和环路(进程资源图是一个环路)**。
进程资源图:死锁不可化简,未死锁可化简
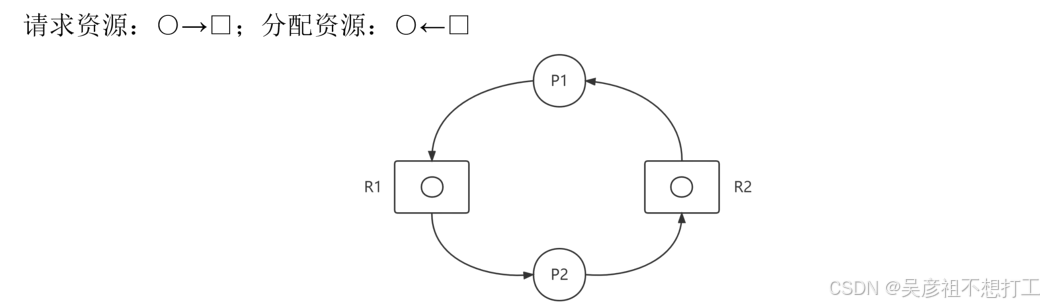
举例
-
死锁的处理策略
-
死锁预防:采用某种策略限制并发进程对资源的请求,破坏死锁产生的4个必要条件,使系统在任何时刻都不满足产生死锁的必要条件。
-
死锁避免:提前计算出一条不会产生死锁的资源分配方法。著名的死锁避免算法有银行家算法。
-
死锁检测:允许死锁产生,但系统定时运行一个死锁检测程序,判断系统是否发生死锁,若检测到有死锁,则设法加以解除。
-
死锁解除:即死锁发生后的解除方法,如资源剥夺法、撤销进程法等。
-
死锁资源的计算:系统内有n个进程,每个进程都需要R个资源
发生死锁的最大资源数:
R
m
a
x
=
n
∗
(
R
−
1
)
即每个进程都缺一个资源
R_{max} =n * (R-1) \ \text{即每个进程都缺一个资源} \\
Rmax=n∗(R−1) 即每个进程都缺一个资源
不发生死锁的最小资源数:
R
m
i
n
=
n
∗
(
R
−
1
)
+
1
即发生死锁的最大资源数再加一个资源。
R_{min} = n * (R-1)+1\ \text{即发生死锁的最大资源数再加一个资源}。
Rmin=n∗(R−1)+1 即发生死锁的最大资源数再加一个资源。
举例
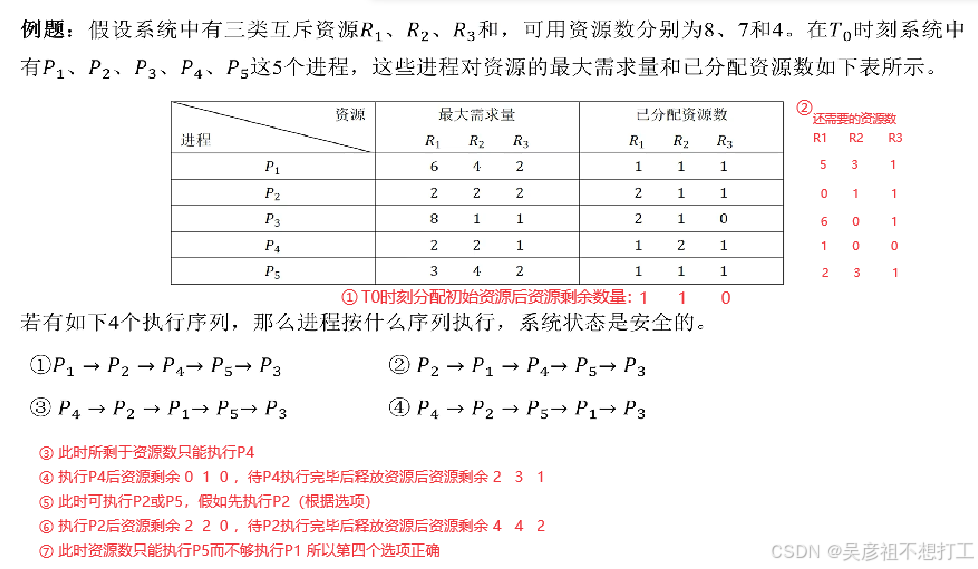
- 线程
线程是进程中的一个实体,是可拥有资源的独立单位;可独立分配和调度的基本单位。线程是调度的最小单位,进程是拥有资源的最小单位,线程可以共享进程的公共数据、全局变量、代码及一些进程级的资源(如打开文件和信号)等,但不能共享线程独有的资源,如线程的栈指针等标识数据。一个进程内的线程在其他进程不可见。
线程共享的内容包括:进程代码段、进程的公有数据(利用这些共享的数据,线程很容易的实现相互之间的通讯)、进程打开的文件描述符、信号的处理器、进程的当前目录、进程用户ID与进程组ID。线程独有的内容包括:线程ID、寄存器组的值、线程的堆栈、错误返回码、线程的信号屏蔽码。
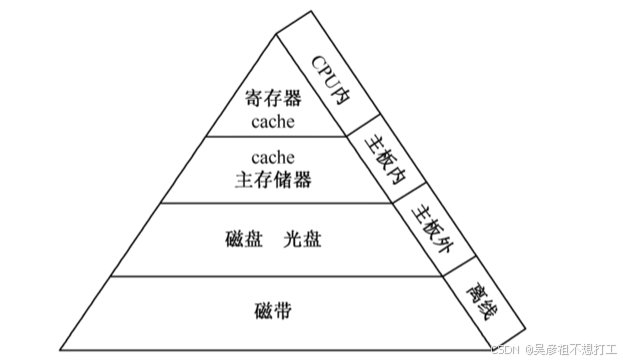
3.存储管理
- 存储器的结构
-
地址重定位
逻辑地址:逻辑地址是由操作系统分配给程序使用的虚拟地址,它是在程序中使用的地址,而不是实际存在的地址,也被称为虚拟地址。
物理地址:物理地址是实际存在于计算机系统中的地址,也称为实际地址。物理地址是存储器的绝对地址,范围从00000H~FFFFFH,是CPU访问存储器时由地址总线发出的地址。
地址重定位将逻辑地址变换成主存物理地址的过程,分为静态重定位(程序装入主存时就完成了变换)和动态重定位(边运行边变换)。 -
存储管理方案
将主存的用户区划分成若干个区域,每个区域分配给一个用户作业使用,"并限定它们只能在自己的区域中运行。
按划分方式不同,分区存储可分为:
(1)固定分区:静态分区方式,将主存划分成若干个固定的分区,将要运行的作业装配进去,由于分区固定,且与作业大小可能不同,会产生碎片,造成空间浪费。
(2〉可变分区:动态分区方式,主存空间的分区在作业装入时划分,分区大小与作业大小相同。可变分区的请求与释放算法:
①最佳适应算法:假设系统中有n个空白分区,当用户申请空间时,从这n个空白分区中找到一个最接近用户需求的分区。可能会产生许多无用的小分区,称为外碎片。
②最差适应算法:系统总是将用户作业装入最大的空白分区。
③首次适应算法:系统从主存的低地址开始选择一个能装入作业的空白分区。
④循环首次适应算法:每次分配都是从刚分配的空白分区开始寻找一个能满足用户要求的空白分区。(3)可重定位分区:可解决碎片问题,移动所有已经分配好的分区,使之成为连续区域。在用户请求空间得不到满足或某个作业执行完毕时进行。
-
分区保护
分区保护的目的是防止未经核准的用户访问分区。 -
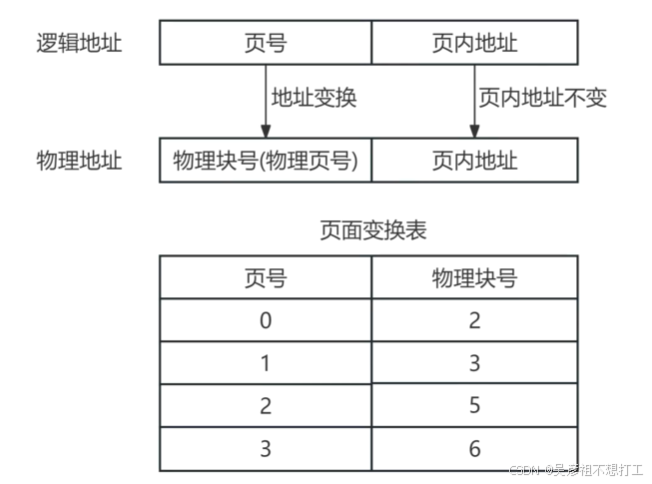
分页存储管理
分区管理方案的主要问题是用户程序必须装入连续的地址空间中,若无法满足用户要求的连续空间,需要进行分区靠拢操作,这是以耗费系统时间为代价的。为此,引入了分页存储管理方案。- 纯分页存储管理
将进程的地址空间划分成若干个大小相等的区域,称为页。相应地,将主存划分成与页相同的若干个物理块,称为块,在为进程分配主存时,将进程中若于页分别装入多个不相邻的块中。
- 快表
将页表中经常使用的页号等对应关系存放在Cache中,称为快表。加快变换速度,快速得到真正的物理地址。
- 纯分页存储管理
举例
假设计算机系统的页面大小为4K,进程P的页面变换表如下表所示。若Р要访问的逻辑地址为十六进制3C20H,那么该逻辑地址经过地址变换后,其物理地址应为____。
页号 物理号快 0 2 1 3 2 5 3 6 解析:
逻辑地址的构成:页号 + 页内地址
页面大小 4K = 212 bit
逻辑地址16进制:3C20H 共16位,页面大小即页内地址占了12位,所以页号占4位,即3,即为10进制3,对应物理块号6,页内地址(C20H)保持不变,物理地址为:6C20H。
-
分段存储管理
将进程空间划分成若干个段,每段也有段号和段内地址,每段是一组完整的逻辑信息。
分页与分段的区别:分页是根据物理空间划分,每页大小相同;分段是根据逻辑空间划分,每段是一个完整的功能,便于共享,但是大小不同。 -
段页式存储管理
先将整个主存划分成若干个大小相等的存储块,将用户程序按程序的逻辑关系分为若干个段,再将每个段划分成若干个页。既具有分页系统能有效地提高主存利用率的优点,又具有分段系统能很好地满足用户需要的长处。
优点:空间浪费小、存储共享容易、存储保护容易、能动态连接;
缺点:由于管理软件的增加,复杂性和开销也随之增加,需要的硬件以及占用的内容也有所增加,使得执行速度大大下降。

最多可有1024(210)个段,每个段最大允许有1024(210)个页,页的大小为4K(212 bit)
-
虚拟存储管理
程序的局部性原理
CPU对主存中的指令和数据的访问,在一小段时间内,总是集中在一小块存储空间里。
①时间局部性:最近被访问过的指令和数据很可能被再次访问;
②空间局部性:最近访问过的指令和数据往往集中在一小片存储区域中。
页面置换算法
有时候,进程空间分为10个页面,而系统内存只有3个物理块,无法一次性全部分配,就需要先分配一部分进程,再根据算法进行淘汰,淘汰的算法称为页面置换算法。
缺页:需要执行的页不在物理内存中,需要从外部调入内存。会增加执行时间,因此缺页次数越多,系统效率越低。- 最佳置换算法:理想化的算法,选择最长时间不再被访问的页面置换。
- 先进先出置换算法:淘汰最先进入主存的页面,即选择在主存中驻留时间最久的页面予以淘汰。
- 最近最少未使用置换算法:选择最近最少未使用的页面予以淘汰,根据局部性原理这种方式效率较高。
- 最近未用置换算法:优先淘汰最近未访问的,而后淘汰最近未被修改的页面。
4.设备管理
-
I/O软件
设计I/O软件的主要目标是设备独立性和统一命名。I/O软件独立于设备,就可以提高设备管理软件的设计效率。当输入/输出设备更新时,没有必要重新编写全部设备驱动程序。 -
通道技术
CPU只需向通道发出IO命令,通道收到命令后,从主存中取出本次IO要执行的通道程序仅当通道完成IO任务后才向CPU发出中断信号。目的:使数据传输独立于CPU,将CPU从繁忙的IO工作中解脱出来。 -
DMA技术
直接内存存取(DMA),是指数据在主存与设备之间直接成块传送,即在主存与设备间传送一个数据块的过程不需要CPU的任何干涉。(开始和结束时需要CPU干预) -
缓冲技术
包括硬件缓冲(硬件寄存器)和软件缓冲(操作系统)。为了提高外设利用率,尽可能使外设处于繁忙状态。引入缓冲技术的原因:①缓和CPU与I/O设备之间速度个匹配的矛盾。②减少对CPU的中断频率,放宽对中断响应时间的限制。③提高CPU和I/O设备之间的并行性。 -
Spooling技术
假脱机技术,用一类物理设备模拟另一类物理设备的技术,是使独占使用的设备变成多台虚拟设备的一种技术。 -
磁盘调度
磁盘的结构:磁盘有正反两个盘面,每个盘有多个同心圆,每个同心圆是一个磁道,每个同心圆
又被划分为多个扇区,数据就被存放在一个个扇区中。
寻道时间:磁头移动到磁道所需
磁盘调度的目标是使磁盘的平均寻道时间最少。
磁盘调度算法-
先来先服务(FCFS):根据进程请求访问磁盘的先后次序进行调度。
-
最短寻道时间优先(SSTF):最短移臂调度算法,要求访问的磁道与当前磁头所在的磁道距离最近,使得每次寻道时间最短,但平均寻道时间不一定最短。
-
扫描算法(SCAN):电梯调度算法,每次选择距离最近的同一个方向的磁道访问
-
单向扫描调度算法(CSCAN):每次均从头到尾依次扫描访问。
-
5.文件管理
-
文件的逻辑结构
无结构的流式文件,是由一串二进制流或顺序字符流构成的文件,如二进制文件或字符文件。
有结构的记录式文件,是由一个以上的记录构成的文件,称为记录式文件,如数据库表。 -
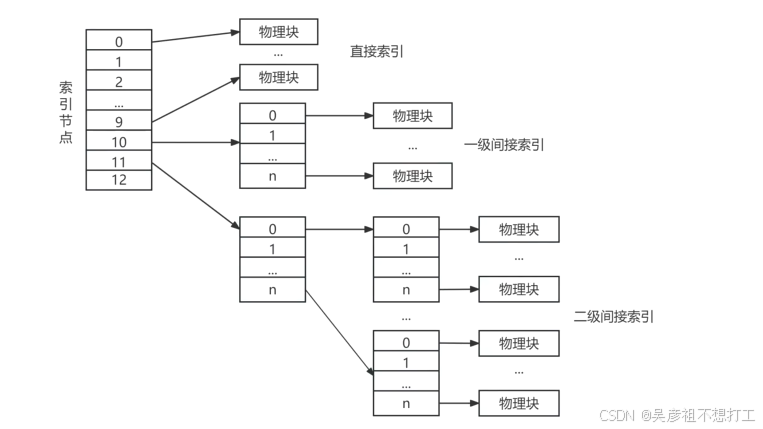
文件的物理结构
①连续结构,逻辑上连续的文件信息(如记录)依次存放在连续编号的物理块上;
②链接结构,逻辑上连续的文件信息存放在不连续编号的物理块上;
③索引结构,逻辑上连续的文件信息(如记录)存放在不连续的物理块中,系统为每个文件建立一张索引表。索引表记录了文件信息所在的逻辑块号对应的物理块号;
④多个物理块的索引表,根据一个文件大小的不同,其索引表占用物理块的个数不同,一般占一个或多个物理块。
在UNIX文件系统中采用的是三级索引结构,其文件索引表项分4种寻址方式:直接寻址、一级间接寻址、二级间接寻址和三级间接寻址。
-
文件目录
文件目录也是一种数据结构,用于标识系统中的文件及其物理地址,供检索时使用。 -
文件控制块(FCB)
基本信息,如文件名、文件的物理地址、文件的长度和文件块数等。
存储控制信息,如文件存取权限等。
使用信息,如文件建立时间、修改时间等。 -
目录结构
文件目录结构的组织方式直接影响到文件的存取速度,关系到文件的共享性和安全性。-
一级目录结构
整个系统中只建立一张目录表,每个文件占一个目录项。 -
二级目录结构
早期的多用户操作系统,采用两级目录结构。分为主文件目录(MFD,Master File Directory)和户文件目录(UFD,User Flie Directory) 。 -
多级目录结构
在多道程序设计系统中常采用多级目录结构,这种目录结构像一棵倒置的有根树,所以也称为树形目录结构。从树根向下,每一个结点是一个目录,叶子结点是文件。Windows、UNIX、MS-DOS等操作系统均采用多级目录结构。
-
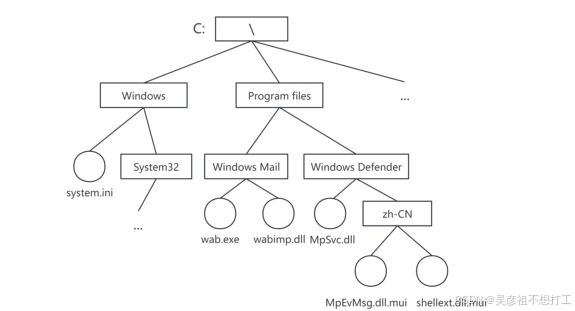
-
绝对路径和相对路径
wab.exe的绝对路径:C:\Program files\Windows Mail\wab.exe
wab.exe对于Program files目录的相对路径:Windows Mail\ -
位示图
在外存上建立一张位示图(Bitmap),记录文件存储器的使用情况。每一位对应文件存储器上的一个物理块,0表示空闲,1表示占用。主要特点:位示图的大小由磁盘空间的大小(物理块总数)决定。
位示图一般用连续的“字”来表示。假设系统字长为32位,位示图中的每个二进制位对应一个物理块,因此可以用(字号,位号)对应一个物理块。
6.作业管理
作业是系统为完成一个用户的计算任务(或一次事务处理)所做的工作总和。例如,对用户编写的源程序,需要经过编译、连接、装入以及执行等步骤得到结果,这其中的每一个步骤称为作业步。
作业由程序、数据和作业说明书3个部分组成。
-
作业状态及转换
作业的状态分为4种:提交、后备、执行和完成。其中,执行就是作业调入系统中执行,与进程执行状态类似。实际上,作业调度是比进程调度更加高级的调度。 -
作业控制块和作业后备队列
作业控制块(JCB):是记录与该作业有关的各种信息的登记表。是作业存在的唯一标志,包括用户名、作业名和状态标志等信息。 -
作业调度算法
- 先来先服务算法。按作业到达的先后进行调度,即启动等待时间最长的作业。
- 短作业优先算法。优先调度运行时间最短的作业。
- 响应比高优先算法。响应比高的作业优先调度。
- 优先级调度算法。优先级高的作业优先调度。
- 均衡调度算法。根据系统的运行情况和作业本身的特性对作业进行分类。作业调度程序从这些不同类别的作业中挑选作业执行。
响应比 R p = 作业响应时间 作业执行时间 = 作业执行时间 + 作业等待时间 作业执行时间 响应比R_p = \frac{作业响应时间}{作业执行时间} = \frac{作业执行时间+作业等待时间}{作业执行时间} 响应比Rp=作业执行时间作业响应时间=作业执行时间作业执行时间+作业等待时间
举例
作业j1、j2、j3的提交时间和所需运行时间如下表所示。若采用响应比高优先调度算法,则作业调度次序为____。作业号 提交时间 运行时间(分钟) j1 6:00 30 j2 6:20 20 j3 6:25 6 j1执行完时间为6:30,此时j1和j2都被提交,所以计算响应比:
R2 = 20 + 10 / 20 = 1.5
R3 = 5 + 6 / 6 = 1.83
调度顺序: j1=> j3 => j2
第五章 软件工程基础知识
1.软件工程概述
软件工程指的是应用计算机科学、数学及管理科学等原理,以工程化的原则和方法来解决软件问题的工程,目的是提高软件生产率、提高软件质量、降低软件成本。
计算机软件指的是计算机系统中的程序及其文档
按照软件的应用领域,将计算机软件分为以下十类,包括:①系统软件;②应用软件;③工程/科学软件;④嵌入式软件;⑤产品线软件;⑥Web应用软件(WebApp);⑦人工智能软件计算;⑨网络资源;⑩开源软件。
-
七条基本原理
①用分阶段的生命周期计划严格管理;
②坚持进行阶段评审;
③实现严格的产品控制;
④采用现代的程序设计技术;
⑤结果应能清楚地审查;
⑥开发小组的人员应少而精;
⑦承认不断改进软件工程实践的必要性。 -
软件生存周期
①可行性分析与项目开发计划(成本、技术、时间…)=> 可行性分析报告、项目开发计划
②需求分析 => 软件需求说明书
③概要设计 => 概要设计说明书
④详细设计 => 详细设计文档
⑤编码 => 编写程序代码
⑥ 测试 => 软件测试计划、测试用例、测试报告
⑦维护 => 软件维护是软件生存周期中时间最长的阶段。 -
软件过程
能力成熟度模型CMM
能力成熟度模型CMM是对软件组织进化阶段的描述,随着软件组织定义、实施、测量、控制和改进其软件过程,软件组织的能力经过这些阶段逐步提高。将软件过程的改进分为五个成熟度级别。
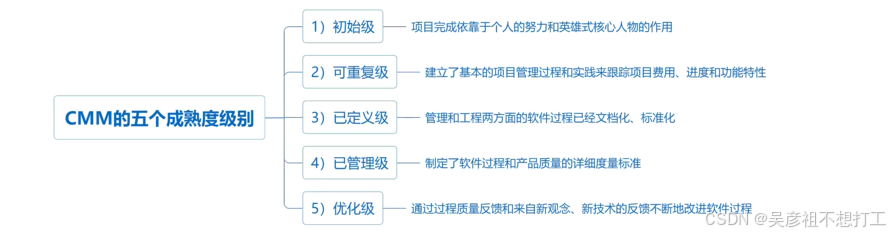
C5(优化的):关键词优化改进;C4(定量管理的):关键词软件过程,产品质量的度量;C3(已定义的) :关键词标准化,文档化;C2(已管理的):关键词管控;C1 (已执行的):关键词输入产品转输出产品
能力成熟度模型集成(CMMI)
CMMI是若干过程模型的综合和改进,定义持多个上住于P awnn框架。CMMI提供了两种表示方法:阶段式模型和连续式模型。
①阶段式模型。结构类似于CMM,它关注组织的成熟度。CMMI-SE/SW/IPPD 1.1版本中有五个成熟度等级。-
初始级:过程不可预测且缺乏控制。
-
已管理级:过程为项目服务。
-
已定义级:过程为组织服务。
-
定量管理级:过程已度量和控制。
-
优化级:集中过程改进。
②连续式模型。关注每个过程域的能力,一个组织对不同的过程域可以达到不同的过程域能力等级(简称CL)。CMMI中包括六个过程域能力等级。
- CL0(未完成的):过程域未执行。
- CL1(已执行的):其共性目标是过程将可标识的输入工作产品转换成可标识的工作产品。
- CL2(已管理的):其共性目标集中于已管理的过程的制度化。
- CL3(已定义级的):其共性目标集中于已定义的过程的制度化。
- CL4(定量管理的):其共性目标集中于可定量管理的过程的制度化。
- CL5(优化的):使用量化手段改变和优化过程域。
-
2.软件过程模型
-
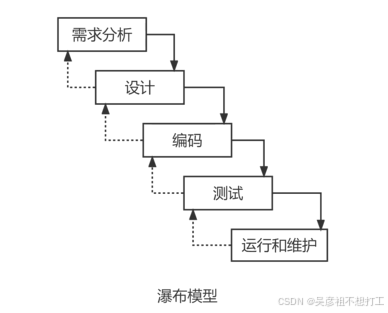
瀑布模型
以文档作为驱动、适合软件需求很明确的软件项目的开发。
优点:容易理解、成本低、强调开发的阶段性早期计划及需求调查和产品测试。
缺点:客户必须能完整、正确和清晰地表达需求;难以评估项目进度状态;项目快结束时,出现大量的集成与测试工作;需求或设计的错误往往只有到了项目后期才能被发现,对项目风险的控制能力较弱,通常会导致项目延期,开发费用超出预算。
-
增量模型
增量模型将需求分段为一系列产品,每一个增量都可以分别开发。
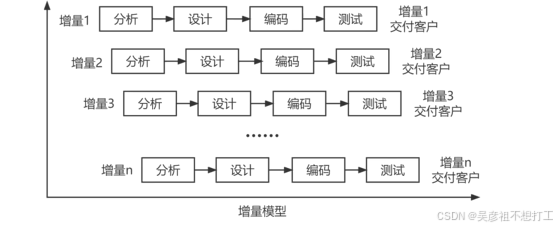
优点:第一个可交付的版本成本和时间很少;开发由增量表示的小系统所承担的风险不大;由于很快发布了第一个版本,因此可减少用户需求的变更。同时,它也具有瀑布模型所有的优点。
缺点:若没有对用户的变更要求进行规划,那么产生的初始增量可能会造成后来增量的不稳定;若需求不像早期思考的那样稳定和完整,那么一些增量就可能需要重新开发或重新发布;管理发生的成本、进度和配置的复杂性可能会超出组织的能力。 -
演化模型
典型的演化模型有原型模型和螺旋模型。演化模型适用于软件需求不够明确的情况。-
原型模型(快速原型模型)
原型模型适用于用户需求不明确、需求经常变化且系统规模不太大、不太复杂的软件项目。 -
螺旋模型
对于一个复杂的大项目,开发一个原型往往达不到要求。螺旋模型将瀑布模型和演化模型(原型模型)结合起来,加入两种模型均忽略的风险分析,弥补了这两种模型的不足。
-
-
喷泉模型
喷泉模型是以用户需求为动力、以对象为驱动的模型,适用于面向对象的开发方法。它克服了瀑布模型不支持软件重用和多项开发活动集成的局限性。喷泉模型使开发过程具有迭代性和无间隙性。
优点:各个阶段没有明显的界线,开发人员可以同步进行;可以提高软件项目的开发效率,节省开发时间。
缺点:电于在各个开发阶段是重叠的,在开发过程中需要大量的开发人员,不利于项目的管理;要求严格管理文档,使得审核的难度加大。 -
基于构件的软件模型
基于构件的开发模型是指利用顾先包装的构件来构造应用系统。
构件可以是组织内部开发的构件,也可以是商品化成品软件构件。基于构建的开发模型具有许多螺旋模型的特点,它本质上是演化模型,需要以迭代方式构建软件。其不同之处在于基于构建的开发模型采用预先打包的软件构建开发应用系统。
构件是面向软件体系架构的可复用软件模块。构件(component〉是可复用的软件组成成份,可被用来构造其他软件。它可以是被封装的对象类、功能模块、软件框架(framework)、软件构架、文档、设计模式等。 -
形式化方法模型
形式化方法是建立在严格数学基础上的一种软件开发方法,主要活动是生成计算机软件形式化的数学规格说明。 -
统一过程模型
统一过程模型是一种“用例和风险驱动,以架构为中心,迭代并增量”的开发过程,由方法和支持。 -
敏捷方法
敏捷方法的总体目标是通过“尽可能早地、持续地对有价值的软件进行交付”使客户满意。敏捷过程的典型方法有很多,每一种方法基于一套原则,这些原则实现了敏捷方法所宣称的理念,即敏捷宣言。
常用的敏捷方法:- 极限编程(XP):四大价值观:沟通、简单性、反馈和勇气。
- 水晶法(Crystal):认为人对软件质量有重要的影响,随着项目质量和开发人员素质的提高,项目和过程的质量也随之提高。
- 并列争球法(Scrum):使用迭代的方法,其中,把每30天一次的迭代称为一个“冲刺”,并按需求的优先级别来实现产品。
- 自适应软件开发(ASD):是一种敏捷软件开发方法,倡导根据需求的变化及时调整开发过程,实现软件开发的自适应性能力。
- 敏捷统一过程(AUP):采用“在大型上连续”以及在“在小型上迭代”的原理来构建软件系统。
3.需求分析
- 功能需求:考虑系统要做什么、什么时候做、如何修改或升级。
- 性能需求:考虑软件开发的技术性指标,如存储容量限制、执行速度、响应时间、吞吐量等。
- 用户或人的因素:考虑用户的类型。
- 环境需求:考虑软件应用的环境。
- 界面需求:考虑来自其他系统的输入或到其他系统的输出等。
- 文档需求:考虑需要哪些文档、文档针对哪些读者。
- 数据需求:考虑输入、输出格式,接收、发送数据的频率,数据的精准度、数据流量、数据保持时间。
- 资源使用需求:考虑软件运行时所需要的资源。
- 安全保密需求:考虑是否需要对访问系统或系统信息加以控制。
- 可靠性需求:考虑系统的可靠性需求、系统是否必须检测和隔离错误、出错后重启系统所允许的时间等。
- 软件成本消耗或开发进度需求:考虑开发是否有规定的时间表。
- 其他非功能性需求:如采用某种开发模式、确定质量控制标准、里程碑和评审、验收标准等。
4.系统设计
-
概要设计
-
软件系统总体结构设计:将系统按功能划分成模块;确定每个模块的功能;确定模块之间的调用关系;确定模块之间的接口,即模块之间传递的信息;评价模块结构的质量。
-
数据结构及数据库设计;如E-R图。
-
编写概要设计文档:概要设计说明书、数据库设计说明书、用户手册及修订测试计划;
-
评审。
-
-
详细设计
-
对每个模块进行详细的算法设计;
-
对模块内部的数据结构进行设计;
-
对数据库进行物理设计,即确定数据库的物理结构;
-
其他设计(代码设计、输入/输出设计、用户界面设计);
-
编写详细设计说明书;
-
评审。
-
5.系统测试
- 系统测试与调试
系统测试是为了发现错误而执行程序的过程,成功的测试是发现了至今尚未发现的错误的测试。测试的目的是以最少的人力和时间发现潜在的各种错误和缺陷。信息系统测试包挺软件测试硬件测试、网络测试。
-
传统软件的测试策略
软件测试分为4步:单元测试、集成测试、确认测试(验收测试)和系统测试。单元测试主要是发现程序代码中的问题,针对详细设计和软件实现阶段的工作进行的
集成测试验证系统模块是否能够根据系统和程序设计规格说明的描述进行工作,即模块以及模块之间的接口的测试
系统测试则是验证系统是否确实执行需求规格说明中描述的功能和非功能要求,因此测试目标在需求分析阶段就已经定义。
-
测试方法
软件测试分为静态测试和动态测试。
静态测试:被测程序不在机器上运行,采用人工检测和计算机辅助静态分析的于段对程厅进仃测试。
动态测试:通过运行程序发现错误,一般采用黑盒测试和白盒测试。- 黑盒测试也称功能测试,在不考虑软件内部结构和特性的情况下,测试软件的外部特性。常用的黑盒测试技术有等价类划分、边界值分析、错误推测和因果图等。
- 白盒测试也称结构测试,根据程序的内部结构和逻辑来设计测试用例,对程序的路径和过程进行测试,检查是否满足设计的需要。常用的白盒测试技术有逻辑覆盖、循环覆盖和基本路径测试。
逻辑覆盖:语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、条件组合覆盖和路径覆盖。
-
调试
调试发生在测试之后,其任务是根据测试时所发现的错误找出原因和具体的位置,进行改正。调试工作主要由程序开发人员进行,谁开发的程序就由谁来进行调试。
6.运行与维护
-
系统转换
一个系统开发完成后,让它实际运行一段时间,是对系统最好的检验和测试方法。新旧系统之间的转换方法有直接转换、并行转换和分段转换。-
直接转换。直接启用新系统,终止旧系统。适用于一些处理过程不太复杂、数据不太重要的场合。
-
并行转换。新旧系统并行工作一段时间,经过一段时间的考验后,新系统正式替代旧系统。适用于较复杂的大型系统。主要特点是安全、可靠,但费用和工作量都很大。
-
分段转换。直接转换和并行转换的结合。在新系统全部正式运行前,一部分一部分地替代旧系统。既保证了可靠性,又不至于费用太大。
-
-
系统维护
系统维护是在软件已经交付使用之后为了改正错误或满足新的需求而修改软件的过程。系统可维护性的评价指标有可理解性、可测试性和可修改性。文档是软件可维护性的决定因素。
系统维护主要包括硬件维护、软件维护和数据维护。软件维护的内容:- 正确性维护:改正在系统开发阶段已发生而系统测试阶段尚未发现的错误。占整个维护工作量的17%~21%。
- 适应性维护:使应用软件适应信息技术变化和管理需求变化而进行的修改。占整个维护工作量的18%~25%。
- 完善性维护:为扩充功能和改善性能而进行的修改。占整个维护工作的50%~60%。
- 预防性维护:为改进应用软件的可靠性和可维护性,为适应未来的软/硬环境的变化,应主动增加预防性的新功能,以使应用系统适应各类变化而不被淘汰。占整个维护工作量的4%左右。
7.软件项目管理
有效的软件项目管理集中在4P上:人员(Person) 、产品(Product) 、过程( Procedure) 、项目(Project)。
人员:参与项目的人员类型有项目管理人员、高级管理人员、开发人员、客户、最终用户。
产品:开展项目计划之前,应先进行项目定义,即定义项目范围,其中包括建立产品的目的和范围、可选的解决方案、技术、管理约束等。
过程:对于软件项目来说,强调的是对其进行过程控制,通常将项目分解为任务、子任务等。
项目:常见的软件项目办法有明确目标及过程、保持动力、跟踪进展、作出明智的决策、
进行事后分析。
-
软件项目估算
软件项目估算涉及人、技术、环境等多种因素,因此很难在项目完成前准确地估算出开发软件所需的成本、持续时间和工作量。常用的估算方法有三种:基于已经完成的类似项目进行估算、基于分解技术进行估算、基于经验估算模型的估算。 -
进度管理
进度管理的目的是确保软件项目在规定的时间内按期完成。进度安排的常用图形描述方法有甘特图(GanttChart)和项目计划评审技术图(PERT))。
下面是一个软件项目的活动图(PERT图),顶点表示里程碑,连接顶点的边表示活动,边上的权重表示完成
该活动所需要的时间(天)。
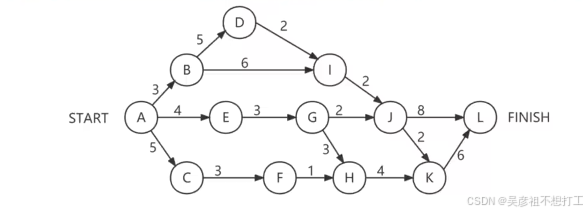
关键路径:从开始顶点到结束顶点之间距离最长的一条路径。关键路径上的长度就是完成整个工程项目的最短工期。
松弛时间:最迟开始时间 - 最早开始时间。关键路径上的活动的松弛时间均为0。 -
软件项目的组织
开发组织采用什么形式,不仅要考虑到项目的特点,还要考虑参与人员的素质。软件项目组织的
原则有:①尽早落实责任;②减少交流接口;③责权均衡。
(1)主程序员制小组
由一名主程序员、若干名程序员、一名后援工程师和一名资料员组成。主程序员通常由高级工程师承担。突出主程序员的领导作用,小组内的通信主要体现在主程序员与程序员之间。
(2)民主制小组
小组成员之间地位平等,工作目标和决策由全体成员决定,这种形式的组内通信路径较多。n 个小组成员的通信路径 = n ( n − 1 ) 2 n个小组成员的通信路径 = \frac{n(n-1)}{2} n个小组成员的通信路径=2n(n−1)
(3)层次式小组
由一名组长领导若干名高级程序员,每名高级程序员领导若干名程序员。组长通常是项目负责人,负责全组的技术工作,进行任务分配,组织评审。高级程序员负责项目的一个部分或一个子系统。 -
软件项目配置
软件配置管理(SCM)用于整个软件工程,主要目标是识别变更、控制变更、确保变更正确实现、报告有关变更。 -
风险管理
软件风险包括两个特性:不确定性和损失。不确定性是指风险可能发生也可能不发生;损失是指风险发生后会产生的恶性后果。常见的商业风险有:市场风险、策略风险、销售风险、管理风险、预算风险。 -
成本估算
专家估算模型:主要依赖于专家的背景和经验,具有较大的主观性。
Wolverton模型:基于一个成本矩阵,定义不同的软件类型(如控制、输入/输出等)和难易(容易和困难)的成本,基于此计算软件开发的成本。
COCOMO模型:将规模视为成本的主要因素,考虑多个成本驱动因子。
COCOMO ll 模型:还考虑了软件开发的不同阶段,包含三个阶段性模型,即应用组装模型、早期设计阶段模型和体系结构阶段模型。
8.软件质量
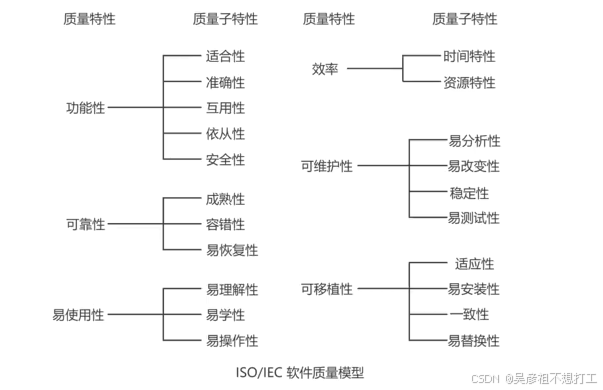
软件质量是指反映软件系统或软件产品满足规定或隐含需求的能力的特征和特性全体。讨论软件质量首先要了解软件的质量特性,在ISO/IEC 9126中,软件质量由三个层次组成,第一层为质量特性,第二层为质量子特性,第三层为度量指标。
-
软件质量保证
软件质量保证是指为保证软件系统或软件产品充分满足用户要求的质量而进行的有计划、有组织的活动,其目的是生产高质量的软件。
在软件质量方面强调以下三个要点:
①软件必须满足用户规定的需求;
②软件应遵循规定标准所定义的一系列开发准则;
③软件还应满足某些隐含的需求。
软件质量保证包括与以下七个主要活动相关的各种任务:
①应用技术方法;
②进行正式的技术评审;
③测试软件;
④标准的实施;
⑤控制变更;
⑥度量;
⑦记录、保存和报告。 -
软件容错技术
提高软件质量和可靠性的技术大致分为两类:避开错误和容错技术。实现容错的主要手段是元余,常见的冗余技术有:
(1)结构冗余:又分为静态冗余、动态冗余和混合冗余。
(2)信息冗余:为检测或纠正正在运算或传输中的信息错误需外加的一部分信息。
(3)时间冗余:以重复执行指令或程序来消除瞬时错误带来的影响。
(4)冗余附加技术:为实现上述冗余技术所需要的资源和技术,包括程序、指令、数据、存放和调动它们的空间和通道等。 -
软件的度量
软件度量用于对产品及开发产品的过程进行度量,如成本、效益、开发人员的生产率、可靠性、可维护性等。软件度量的方法:
面向规模的度量
面向规模的度量主要是通过对质量和生产率的测量进行规范化得到的,而这些量都是根据开发过的软件的规模得到的。
面向功能的度量
面向功能的度量以功能测量数据为规范化值。应用最广泛的面向功能的度量是功能点(FP)。功能点是根据软件信息域的特性及复杂性来计算的。
软件复杂性度量
软件复杂性度量是指理解和处理软件的难易程度。软件复杂性度量的参数有很多,主要包括:
①规模;②难度;③结构;④智能度。软件复杂性包括程序复杂性和文档复杂性。
典型的程序复杂性度量有McCabe环路复杂性度量和Halstead复杂性度量。
McCabe度量法是一种基于程序控制流的环路复杂性度量方法,以图论为工具,先画出程序图(退化的程序流程图),然后用该图的环路数作为程序复杂性的度量值。
在一个强连通的有向图G中,环的个数V(G)由以下公式给出:V ( G ) = m − n + 2 p V(G) = m -n+ 2p V(G)=m−n+2p
其中,V(G)是有向图G中的环路数,m是图G中弧的个数,n是图G中的结点数,p是G中的强连通分量个数(p通常为1)。
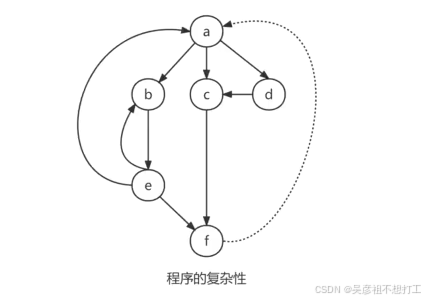
下述3种方法中的任何一种来计算环路复杂度:
(1)程序图G中的区域数等于环路复杂度(封闭区域数+1(一个非封闭区域))。
(2)程序图G的环形复杂度V(G)= E - N+2,其中,E是程序图中边的条数,N是结点数。
(3)程序图G的环形复杂度V(G)= P + 1,其中,P是程序图中判定结点(有2条输出弧)的数目。有n (n>2)条输出弧的判定结点对应程序中的n-1个判断。(判定节点+1)`
第六章 结构化开发方法
1.系统设计的基本原理
-
抽象
重点说明一个实体的本质方面,忽略或掩盖不太重要或非本质的方面。
抽象的最底层就是实现该软件的源程序代码。
较低抽象层次的模块是较高抽象层次模块对问题解法描述的细化。 -
模块化
在程序中是数据说明、可执行语句等程序对象的集合,或者是单独命名和编制的元素,模块是可以组合分解和
更换的单元;使程序的结构清晰、容易阅读、理解、测试和修改 -
信息隐蔽
开发整体程序结构时使用的法则,即将每个程序的成分隐蔽或封装在一个单一的设计模块中,在定义每一个模
块时,尽可能少地显露其内部的处理;提供软件的可修改性、可测试性、可移植性。 -
模块独立
每个模块完成一个相对独立的特定子功能,并且与其他模块联系简单;耦合性和内聚性。
2.耦合
模块之间的相对独立性的度量, 耦合取决于模块之间接口的复杂度、调用模块的方式以及通过接口的信息类型。
- 无直接耦合:模块之间没有任何关系
- 数据耦合:模块之间传递的是简单数据值
- 标记耦合:传递的是数据结构
- 控制耦合:传递的是控制变量
- 外部耦合:通过软件之外的环境连接
- 公共耦合:通过公共数据环境相互作用
- 内容耦合:一个模块之间使用另外一个模块的内部数据,或通过非正常入口转入另一个模块内部时
3.内聚
一个模块内部各个元素彼此结合的紧密程度的度量
-
偶然内聚:模块内各元素毫无关系
-
逻辑内聚:模块内执行若干个逻辑相似的功能,通过参数确定该模块完成哪一个功能。
-
时间内聚:需要同时执行的动作组合在一起形成的模块
-
过程内聚:一个模块完成多个任务,这些任务必须按指定的过程执行。
-
通信内聚:模块内的各个处理元素都在同一个数据结构上操作,或者各处理使用相同的输入数据或者产生相同的输出数据
-
顺序内聚:一个模块中的各个处理元素都密切相关与同一功能且必须顺序执行,前一功能元素的输出就是下一功能元素的输入
-
功能内聚:模块所有元素共同作用完成一个功能,缺一不可
4.系统结构设计原则
- 分解-协调:整个系统是一个整体,具有整体目的和功能,但这些目的和功能的实现又是由相互联系的各个组成部分共同工作的结果。
- 自顶向下:先确定上层模块的功能,再确定下层模块的功能。
- 信息隐蔽、抽象:上层模块只规定下层模块做什么和所属模块间的协调关系,但不规定怎么做,以保证各模块的相对独立性和内部结构的合理性,使得模块与模块之间层次分明,易于理解、实施和维护。
- 一致性:要保证整个软件设计过程中具有统一的规范、统一的标准和统一的文件模式等。
- 明确性:避免病态接口,降低耦合度,每个模块必须功能明确、接口明确,消除多重功能和无用接口
- 高内聚、低耦合:模块之间的耦合尽可能小,模块的内聚度尽可能高。
- 模块之间的扇入系数和扇出系数合理:一个模块直接调用其他模块的个数称为模块的扇出系数;反之,一个模块被其他模块调用时,直接调用它的模块个数称为模块的扇入系数。
- 模块的规模适当:过大的模块常常使系统分解得不充分,过小的模块有可能降低模块的独立性,造成系统接口的复杂性。
- 模块的作用范围要在其控制范围之内
5.系统文档
- 用户与分析人员:可行性研究报告、总体规划报告、系统开发报告和系统方案说明书
- 开发人员与项目管理人员:系统开发计划(工作任务分解表、PERT图、甘特图和预算分配表)、系统开发月报以及系统开发总结报告
- 测试人员与开发人员:系统方案说明书、系统开发合同、系统设计说明书和测试计划
- 开发人员和用户在系统运行期间沟通:用户手册和操作指南
- 开发人员和维护人员:系统设计说明书和系统总结报告
6.结构化分析方法
结构化分析与设计方法是一种面向数据流的传统软件开发方法,它以数据流为中心构建软件的分析模型和设计模型。结构化分析SA、结构化设计SD、结构化程序设计SP构成了完整的结构化方法。
结构化分析方法是将系统开发看成工程项目,有计划、有步骤地进行工作,是一种应用很广泛的开发方法,采用“自顶向下,逐层分解”的开发策略。
分为以下几部分:
-
一套分层的数据流图DFD:用来描述数据流从输入到输出的变换流程。
-
一本数据字典DD:用来描述DFD中的每个数据流、文件以及组成数据流或文件的数据项。
-
一组小说明(也称加工逻辑):用来描述每个基本加工(即不在分解的加工)的加工逻辑。
-
处理任何复杂问题的两个基本手段
- 抽象
- 结构化方法:自上向下逐层分解,自下向上抽象。
-
数据流图(DFD)组成
数据流:由一组固定成分的数据组成,表示数据的流向。
加工:描述输入数据流到输出数据流之间的变换,即过程。
数据存储:用来表示存储数据,每个*数据存储都有一个名字。
外部实体:是指存在于软件系统外的人员*、组织或其它系统。它指出 系统所需数据的发源地和系统所产生的数据的归宿地。父图与子图平衡。输入/输出数据流保持一致。
数据守恒。输出数据流数据从输入数据流中获得,或通过该加工的处理而产生。
加工未使用其输入数据流中的某些数据项。
局部数据存储。
一个加工输出数据流不能与该加工输入数据流同名。 -
数据字典(DD)
就是用来定义表示数据流图中各个成分的具体含义的,它以一种准确的、无二义性的说明方法为系统的分析、设计及维护提供了有关元素一致的定义和详细的描述。
数据字典中有4类条目:数据流、数据项、数据存储、基本加工。数据流条目给出了DFD中数据流的定义,通常列出该数据流的各组成数据项。
数据存储条目是对数据存储的定义。
数据项条目是不可再分解的数据单位。
加工条目是用来说明DFD中基本加工的处理逻辑。
7.结构化设计方法
是将结构化设计分析得到的数据流图映射出软件体系结构的一种设计方法。强调模块化、自顶向下逐步求精、信息隐蔽、高内聚、低耦合等设计规则。软件设计分为概要设计和详细设计两个步骤。
-
步骤
- 建立一个满足软件需求的初始结构图(自顶向下、逐步求精、信息隐蔽、高内聚低耦合)
- 对结构图改进
- 书写设计文档
- 设计评审
-
结构图:
模块:指具有一定功能并可以用模块名调用的一组程序语句,一个模块具有外部特征和内部特征;
调用:模块和模块之间的调用关系用从一个模块指向另一个模块的箭头来表示;
数据:模块间还经常用带注释的短箭头表示模块调用过程中来回传递的消息。箭头尾部带空心圆的表示传递的是数据,带实心圆的表示传递的是控制信息。
结构图的形态特征:深度:指控制图控制的层次,也就是模块的层数;
宽度:指一层中最大的模块个数;
扇出:指一个模块的直接下属模块的个数;
扇入:指一个模块的直接上属模块的个数。 -
DFD信息流分类
变换流:外部形式转换为内部表示
信息流:信息沿着输入通路到达另一个事务中心,选择一个来执行。呈辐射状。 -
变换分析
确定输入流和输出流,分离出变换中心。
第一级分解(顶层和第一层)
第二季分解(中、下层)
事物分析 -
结构化设计主要包括:
①体系结构设计:定义软件的主要结构元素及其关系。
②数据设计:基于实体联系图确定软件涉及的文件系统的结构及数据库的表结构。
③接口设计:描述用户界面,软件和其他硬件设备、其他软件系统及使用人员的外部接口,以及各种构件之间的内部接口。
④过程设计:确定软件各个组成部分内的算法及内部数据结构,并选定某种过程的表达形式来描述各种算法。
8.结构化程序设计方法
- 采用自顶向下、逐步求精的程序设计方法。
- 使用3种基本控制结构构造程序。任何程序都可以由顺序、选择、重复3种基本控制结构构造,这3种基本结构的共同点是单入口、单出口。
9.WebApp分析与设计
-
WebApp特性
网络密集型、并发性、无法预知的负载量、性能、可用性、数据驱动 -
WebApp需求模型
内容模型(文字、图像、音频、视频):描述内容对象的构件能力
交互模型:用例、顺序图、状态图、用户界面原型
功能模型
导航模型
配置模型:环境和基础设施 -
WebApp设计
通用特性:可用性、功能性、可靠性、效率、可维护性、安全性、可扩展性、及时性
设计目标:简单性、一致性、符合性、健壮性、导航性、视觉吸引与兼容性
设计动作:架构设计、构件设计(内容、功能)、内容设计(线性、网络、层次、网格结构)、导航设计、美学设计、界面设计
10.用户界面设计
-
3条黄金原则
用户操纵控制、减少用户的记忆负担、保持界面一致 -
用户操纵控
不强迫用户进入不必要的或不希望的动作的方式来定义交互模式
提供灵活的交互
允许中断和撤销用户交互
当技能级别增长时,可以交互流线化并允许定制交互
使用户与内部技术细节隔离开
允许用户与出现在屏幕上的对象直接交互 -
减少用户的记忆负担
减少对短期记忆的要求
建立有意义的默认
定义直观的快捷方式
界面的视觉布局应基于真实世界的象征
不断改进的方式揭示信息 -
保持界面一致
允许用户将当前任务放入有意义的环境中
在应用系统家族内保持一致性
如果过去的交互模型已经建立了用户的期望,除非有不得已的理由,否则不要改变它 -
用户界面分析和设计模型
软件工程师所创建的设计模型
人机界面设计工程师所创建的设计模型
最终用户在脑海里对世界产生的映像
系统实现者创建的系统映像 -
用户界面分析设计4个框架
界面分析建模、界面设计、界面构造、界面确认 -
用户界面设计问题
系统响应时间、帮助设施、错误信息处理、菜单和命令标记
第七章 面向对象技术
1.面向对象技术基础
面向对象技术(Object-oriented technology)是一种软件开发方法论,也是一种编程范式,它通过将系统中的实体抽象为对象,并将对象之间的关系和行为通过封装、继承和多态等机制进行描述和实现。
面向对象技术的特点包括:
| 概念 | 描述 |
|---|---|
| 封装 | 数据和方法封装在一个对象中,通过限制对对象内部的访问来隐藏实现细节,提高了程序的模块化和安全性。 |
| 继承 | 一个类可以从另一个类派生而来,并继承父类的属性和方法。继承可以提高代码的重用性和扩展性。 |
| 多态 | 同一类型的对象在不同的上下文环境下可以表现出不同的行为。多态性使得程序可以根据对象的实际类型来选择对应的方法。 |
| 抽象 | 通过抽象可以从众多的实体中抽取出共同的特征和行为,形成抽象类或接口,便于设计和维护系统。 |
| 消息传递 | 面向对象的通信方式是通过对象之间的消息传递来实现的,对象之间通过发送和接收消息来进行沟通和协作。 |
-
面向对象分析
确定问题域,理解问题;认定对象、组织对象、描述对象之间的相互关系(作用)、定义对象操作、定义对象的内部消息 -
面向对象设计
是设计分析模型和实现相应源代码,在目标代码环境中这种源代码可被执行,设计问题域的解决方案作用;识别类及对象、定义属性、定义服务、识别关系、识别包。
-
面向对象实现
主要强调采用面向对象程序设计语言实现系统。 -
面向对象测试
与普通测试相同,可分为四个层次,算法层、类层、模板层、系统层;根据规范说明来验证系统设计的正确性。
依赖:
泛化:一个类与它的一个或多个细化类之间的关系
组合:一种聚合关系,其中整体负责其部分的创建和销毁,如果整体不存在,那么部分也将不存在。
聚合:较大的整体类包含一个或多个较小的部分类
2.UML
UML(统一建模语言)是一种用于软件系统的设计、建模和文档化的标准化语言。作为软件设计师,使用UML可以帮助我们更好地理解和描述软件系统的结构和行为。
在软件设计过程中,UML为设计师提供了一系列的图形符号和规范,用于表示系统中的各种元素,如类、对象、关系、行为和状态。这些图形符号包括类图、对象图、活动图、时序图、状态图等。
使用UML可以帮助设计师进行需求分析、系统设计和系统架构等工作。通过绘制UML图,设计师可以清晰地展示系统的结构和行为,从而帮助开发人员更好地理解需求和实现软件系统。
UML还提供了一些常用的设计模式,用于解决常见的软件设计问题。设计师可以根据系统的需求选择适合的设计模式,并使用UML进行建模和描述。
UML图分为静态视图和动态视图
静态图分为:用例图,类图,对象图,包图,构件图,部署图。
动态图分为:状态图,活动图,协作图,序列图。
进行面向对象设计时,类图中可以展现类之间的关联关系,还可以在类图中图示关联中的数量关系,即多重度。表示数量关系时,用多重度说明数量或数量范围,表示有多少个实例(对象)能被连接起来,即一个类的实例能够与另一个类的多少个实例相关联。
3.设计模式
在软件设计中,设计模式是一种被广泛接受并被证明可行的解决方案,用于解决常见的软件设计问题。设计模式可以提供一种可重用的解决方案,使软件设计人员能够更好地组织和管理代码,同时提高软件的可维护性和可扩展性。
- 创建型模式:用于创建对象的模式
| 名称 | 描述 |
|---|---|
| 抽象工厂模式(Abstract Factory) | 提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们具体的类。 |
| 构建器/生成器模式(Builder) | 将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。 |
| 工厂方法模式(Factory Method) | 定义一个用于创建对象的接口,让子类决定实例化哪一个类。使一个类的实例化延迟到其子类。 |
| 原型模式(Prototype) | 用原型实例指定创建对象的种类,并且通过复制这些原型创建新的对象。 |
| 单例模式(Singleton) | 保证一个类仅有一个实例,并提供一个访问它的全局访问点。 |
- 结构型模式:主要处理类和对象的组合问题,让类或对象形成更大的结构提供相应的指导
| 名称 | 描述 |
|---|---|
| 适配器模式(Adapter) | 将一个类的接口转换成客户希望的另外一个接口。使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。 |
| 桥接模式(Bridge) | 将抽象部分与其实现部分分离,使它们可以独立地变化。 |
| 组合模式(Composite) | 将对象组合成树形结构以表示**“部分-整体”的层次结构**,使得用户对单个对象和组合对象的使用具有一致性。 |
| 装饰模式(Decorator) | 对对象进行包装,动态地给一个对象添加一些额外的职责。(给对象添加行为) |
| 外观模式(Facade) | 为子系统中的一组接口提供一个一致的界面。定义了一个高层接口,这个接口使得这一子系统更加容易使用。(简化接口)。 |
| 享元模式(Flyweight) | 运用共享技术有效地支持打两细粒度的对象。 (对象共享) |
| 代理模式(Proxy) | 为其他对象提供一种代理以控制对这个对象的访问。 |
- 行为型模式:主要描述类或对象交互的情况以及职责的分配问题
| 名称 | 描述 |
|---|---|
| 职责链模式(Chain of Responsibility) | 通过给多个对象处理请求的机会,减少请求的发送者与接受者之间的耦合,将接收对象链接起来,在链中传递请求,知道有一个对象处理这个请求(传递职责)。 |
| 命令模式(Command) | 将一个请求封装成一个对象,从而让你使用不同的请求把客户端参数化,对请 求排队或者记录请求日志,可以提供命令的撤销和恢复功能 |
| 解释器模式(Interpreter) | 给定一种语言,定义它的文法表示,并定义一个解释器,该解释器用来根据文法表示来解释语言中的句子。 |
| 迭代器模式(Iterator) | 提供一种方法来顺序访问一个聚合对象中的各个元素,而不需要暴露该对象的内部表示。 |
| 中介者模式(Mediator) | 用一个中介对象来封装一系列的对象交互。它使各对象不需要显式地相互调用,从而达到低耦合,还可以独立地改变对象间的交互(不直接引用)。 |
| 备忘录模式(Memento) | 在不破坏封装性的前提下,捕获一个对象内部状态,并在该对象之外 保存这个状态,从而可以在以后将该对象恢复到原先保存的状态。 |
| 观察者模式(Observer) | 定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并自动更新。 |
| 状态模式(State) | 允许一个对象在其内部状态改变时改变它的行为(转态变成类)。 |
| 策略模式(Strategy) | 定义一系列的算法,把它们一个个封装起来,并且使它们之间可互相替换,从而让算法可以独立于使用它的用户而变化(多方案切换)。 |
| 模板方法模式(Template Method) | 定义一个操作中的算法的骨架,而将一些步骤延迟到子类中,使得子类可以不改变一个算法的结构即可重新定义算法的某些特定的步骤 |
| 访问者模式(Visitor) | 表示一个作用于某对象结构中各元素的操作,使得在不改变各元素类的前提下定义作用于这些元素的新操作 |
第八章 算法设计与分析
1.基本概念
算法是对特定问题求解步骤的一种描述,它是指令的有限序列,其中每一条指令表示一个或多个操作。简单的说算法就是某个问题的解题思路
- 有穷性。一个算法必须总是(对任何合法的输入值)在执行有穷步之后结束,且每一步都可在有穷时间内完成。
- 确定性。算法中的每一条指令必须有确切的含义,理解时不会产生二义性。在任何条件下,算法只有唯一的一条执行路径,即对于相同的输入只能得出相同的输出。
- 可行性。一个算法是可行的,即算法中描述的操作都可以通过已经实现的基本运算执行有限次来实现。
- 输入。一个算法有零个或多个输入,这些输入取自于某个特定的对象的集合,
- 输出。一个算法有一个或多个输出,这些输出是同输入有着某些特定关系的量。
算法的表示:
- 自然语言。容易理解,但容易出现二义性,并且算法通常很冗长。
- 流程图。直观易懂,但严密性不如程序设计语言,灵活性不如自然语言。
- 程序设计语言。可用计算机直接执行,但抽象性差,使算法设计者拘泥于描述算法的具体细节,忽略了“好”算法和正确逻辑的重要性。此外,还要求算法设计者掌握程序设计语言及编程技巧。
- 伪代码。介于自然语言和程序设计语言之间的方法,它采用某一程序设计语言的基本语法同时结合自然语言来表达。计算机科学家从来没有对伪代码的书写形式达成过共识。在伪代码中可以采用最具表达力的、最简明扼要的方法来表达一个给定的算法。
2.算法分析基础
-
空间复杂度:一个算法在运行过程中临时占用存储空间大小的度量。一个算法的空间复杂度只考虑在运行过程中为局部变量分配的存储空间的大小。
-
时间复杂度:程序运行从开始待结束所需要的时间。
时间复杂度是一个大概的规模表示,一般以循环次数表示,O(n)元说明执行时间是n的正比,另外,log对数的时间复杂度一般在査找二叉树的算法中出现。渐进符号O表示一个渐进变化程度,实际变化必须小于等于O括号内的渐进变化程度。- O(1):常数时间复杂度。
- O(n):线性时间复杂度。
- O(n²):平方时间复杂度。
- O(log n):对数时间复杂度。
- O(n log n):线性对数时间复杂度。
常见的对算法执行所需时间的度量:
O
(
1
)
<
O
(
l
o
g
2
n
)
<
O
(
n
)
<
O
(
n
l
o
g
2
n
)
<
O
(
n
2
)
<
O
(
n
3
)
<
O
(
2
n
)
<
O
(
n
!
)
O(1)<O(log_2^n)<O(n)<O(nlog_2^n)<O(n²)<O(n^3)<O(2^n)<O(n!)
O(1)<O(log2n)<O(n)<O(nlog2n)<O(n2)<O(n3)<O(2n)<O(n!)
- 算法的复杂度
常数级:代码中没有循环 O(1)
线性级:一重循环 for(i = 0; i < n; i++) O(n)
对数级:出现“乘” while(count < n){…} O(logn)
平方级:多重循环 for( ){for( ){…}…} O(nm)
3.分治法
-
递归
递归是指子程序(或函数)直接或间接调用自己。有两个基本要素:
①递归出口,也就是边界条件,即递归到何时终止;
②递归体,即大问题是如何分解为小问题的。
阶乘函数可递归定义为:n ! = { 1 , n = 0 n ( n − 1 ) ! , n > 0 n! =\begin{cases} 1,n=0\\ n(n-1)!,n>0 \end{cases} n!={1,n=0n(n−1)!,n>0
将一个难以直接解决的大问题分解成一些规模较小的相同问题,逐个击破、分而治之。如果规模
为n的问题可分解成k个子问题,1≤k ≤n,这些子问题相互独立且与原问题相同,递归地解决这些子问题,然后将各子问题的解合并得到原问题的解。- 边界条件:确定递归到何时终止。
- 递归模式:大问题是如何被分解为小问题的。
-
动态规划
与分治法类似,其基本思想也是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解。与分治法不同的是,适合用动态规划法求解的问题,经分解得到的子问题往往不是独立的。
动态规划法通常用于求解具有某种最优性质的问题。在这类问题中,可能会有许多可行解,每个解都对应于一个值,我们希望找到具有最优值(最大值或最小值)的那个解。当然,最优解可能会有多个,动态规划法能找出其中的一个最优解。
与分治法区别:每个子问题不是相互独立的,并且不全部相同。
与贪心法区别:动态规划不仅每一步最优,全局也最优。
三个特点:- 把原问题分解成几个相似的子问题
- 所有的子问题只需要解决一次。
- 存储子问题的解,会增加空间复杂度。
4.贪心法
贪心法是在每个决策点做出当前看来最佳的选择算法,也就是每一步都取最优,做出决策后不会再改变。贪心法能做到局部最优,期望达到全局最优。
使用贪心法的重要性质:
- 最优子结构。当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构。
- 贪心选择性质。指问题的整体最优解可以通过一系列局部最优的选择,即贪心选择来得到。这是贪心法和动态规划法的主要区别。
5.回溯法(深度优先)
有"通用的解题法"之称,用它可以系统地搜索一个问题的所有解或任一解。在包含问题的所有解的解空间树中,按照深度优先的策略,从根结点出发搜索解空间树。搜索至任一结点时,总是先判断该结点是否肯定不包含问题的解,如果不包含,则跳过对以该结点为根的子树的搜索,逐层向其祖先结点回溯;否则,进入该子树,继续按深度优先的策略进行搜索。回溯法一般用于解决迷宫、数独类的问题。
可以理解为先进行深度优先搜索,一直向下探测,当此路不通时,返回上一层搜索另外的分支,重复此步骤,这就是回溯,意为先一直探测,当不成功时再返回上一层。
6.分支限界法(广度优先)
类似于回溯法,也是一种在问题的解空间树上搜索问题解的算法。回溯法的求解目标是找出解空间树中满足约束条件的所有解,而分支限界法的求解目标是找出满足约束条件的一个解,或是在满足约束条件的解中找出使某一目标函数值达到极大或极小的解,即在某种意义下的最优解。回溯法以深度优先的方式搜索解空间树,而分支限界法以广度优先或以最小耗费优先的方式搜索解空间树。使用分支限界法可以解决大量离散最优化的实际问题。
| 算法 | 特点 | 经典问题 |
|---|---|---|
| 分治法 | 把一个问题拆分成多个小规模的相同子问题,一般可用递归解决 | 斐波那契数列、归并排序、快速排序、矩阵乘法、二分搜索、大整数乘法 |
| 回溯法 | 系统的搜索一个问题的所有解或任一解,即找出所有子问题的最优解。 | N皇后问题、迷宫 |
| 动态规划法 | 划分子问题,并把子问题结果使用数组/散列表存储 | 斐波那契数列、矩阵乘法、0-1背包问题、LCS最长公共子序列 |
| 贪心法 | 局部最优,但整体不见得最优。 | 邻分背包问题、多机调度、找零钱问题 |
第九章 数据库技术基础
1.基本概念
-
数据(Data)
是数据库中存储的基本对象,是描述事物的符号记录。
数据的种类:文本、图形、图像、音频、视频、学生的档案记录、货物的运输情况等。 -
数据库(Database, DB)
数据库是长期储存在计算机内、有组织的、可共享的大量数据的集合。
数据库的基本特征:数据按一定的数据模型组织、描述和储存;可为各种用户共享;冗余度较小;数据独立性较高;易扩展 -
数据库管理系统(DBMS)
是位于用户与操作系统之间的一层数据管理软件,是一个大型复杂的软件系统。
DBMS的用途:科学地组织和存储数据、高效地获取和维护数据 -
数据库系统(Database System,DBS)
是计算机系统中引入数据库后的系统构成。
数据库系统的构成:数据库、硬件平台、软件(应用程序)、数据库管理员
2.数据库的模式结构
三级模式(外模式、概念模式、内模式)、两级独立性(物理独立性、逻辑独立性)
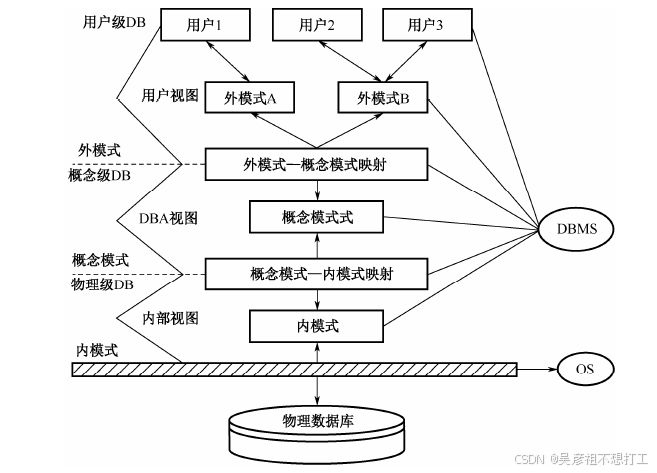
-
模式(概念模式、逻辑模式)
数据库中全体数据的逻辑结构和特征的描述
所有用户的公共数据视图,综合了所有用户的需求
一个数据库只有一个模式 -
外模式(子模式、用户模式)
数据库用户(包括应用程序员和最终用户)使用的局部数据的逻辑结构和特征的描述
数据库用户的数据视图,是与某一应用有关的数据的逻辑表示
外模式的地位:介于模式与应用之间 -
内模式(存储模式)
是数据物理结构和存储方式的描述
是数据在数据库内部的表示方式
一个数据库只有一个内模式 -
模式与外模式的关系:一对多、外模式通常是模式的子集;一个数据库可以有多个外模式。反映了不同的用户的应用需求、看待数据的方式、对数据保密的要求。
外模式的用途:保证数据库安全性的一个有力措施;每个用户只能看见和访问所对应的外模式中的数据 -
与三级模式相对应,数据库系统可以划分为三个抽象级:
- 用户级数据库:对应于外模式,是用户看到和使用的数据库,又称用户视图。一个数据库可有多个不同的用户视图。
- 概念级数据库:对应于概念模式,是所有用户视图的最小并集,一个数据库应用系统只有一个DBA视图。
- 物理级数据库:对应于内模式,是数据库的低层表示,它描述数据的实际存储组织,是最接近于物理存储的,又称为内部视图
3.数据模型
-
关系模型
在用户观点下,关系模型中数据的逻辑结构是一张二维表,它由行和列组成。
用表格结构表达实体集,用外键(外码)表示实体间联系。
优点:- 建立在严格的数学概念基础上
- 概念单一,结构简单、清晰,用户易懂易用
- 存取路径对用户透明,从而数据独立性、安全性好,简化数据库开发工作。
缺点:由于存取路径透明,查询效率往往不如非关系数据模型。
-
E-R模型
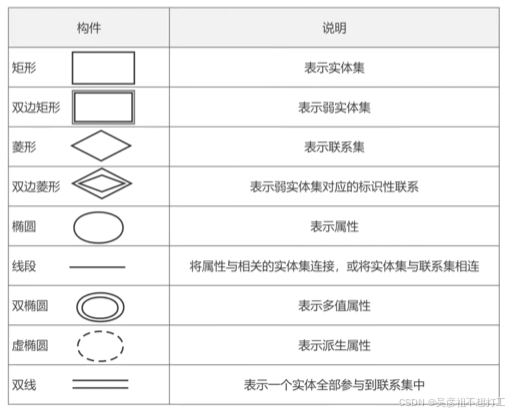
E-R模型,就是实体-联系模型,用来描述现实世界的概念模型,其中有三个主要的概念:实体、联系和属性。-
实体:用矩形表示,每个实体由一组属性表示,包括主键、候选键、外键。实体集是指具有相同属性的实体集合。
-
联系:用菱形表示,实体集之间的对应关系称为联系,分为一对一(
1:1)、一对多(1:n)、多对多(m:n)。
①一对一联系(1:1)。实体集A中的一个实体最多只与实体集B中的一个实体相联系,反之亦然。
②一对多联系(1:n或1:*)。实体集A中的一个实体可与实体集B中的多个实体相联系。
③多对多联系(m:n或*:*)。契体集A中的多个实体可与实体集B中的多个实体相联系。多对多的联系会产生一个新的关系模式,此关系模式的属性由联系的两个实体的主键以及自己的特有属性所组成。 -
属性:用椭圆表示,是实体某方面的特性。E-R模型中的属性分为:
①简单和复合属性:简单属性是原子的、不可再分的,复合属性可以划分为多个子属性,如通信地址。
②单值和多值属性:对于一个特定的实体都只有一个单独的值(单值属性)。例如,对于一个特定的员工,只对应一个员工号、员工姓名。而员工可能有0个、1个或多个亲属,那么员工的亲属姓名可能有多个,这样的属性称为多值属性。
③NULL属性:某个属性没有值或属性值未知时,使用NULL值,表示无意义或不知道。
④派生属性:派生属性可以从其他属性得来。例如,职工实体集中有“参加工作时间”和“工作年限”属性,那么“工作年限”的值可以由当前时间和参加工作时间得到。“工作年限”就是一个派生属性。
-
-
E-R图之间的冲突主要分为结构冲突、属性冲突和命名冲突三类。
- 因为结构冲突是指同一实体在不同的分E-R图中有不同的属性,同—对象在某一分E-R图中被抽象为实体而在另一分E-R图中又被抽象为属性,需要统一。
- 因为属性冲突是指同一属性可能会存在于不同的分E-R图,由于设计人员不同或是出发点不同,对属性的类型、取值范围、数据单位等可能会不一致,这些属性对应的数据将来只能以一种形式在计算机中存储,这就需要在设计阶段进行统一。
- 因为命名冲突是指相同意义的属性在不同的分E-R图上有着不同的命名,或是名称相同的属性在不同的分E-R图中代表着不同的意义,这些也要进行统一。
-
基本概念
域:一个现实中的实体(事物)常用若干特征来描述,这些特征称为属性。每个属性的取值范围对应的集合称为该属性的域。
整数、实数、{‘男’,‘女’}
笛卡尔积:给定一组域D1,D2,…,Dn,这些域中可以有相同的(所有元素的排列组合)。
D1,D2,…,Dn的笛卡尔积为:D 1 × D 2 × … × D n = { ( d 1 , d 2 , … , d n ) | d i ∈ D i , i = 1 , 2 , … , n } D1×D2×…×Dn = \{(d1,d2,…,dn)|di ∈Di,i=1,2,…,n\} D1×D2×…×Dn={(d1,d2,…,dn)|di∈Di,i=1,2,…,n}
关系的相关名词
候选码(Candidate Key):若关系中的某一属性或属性组的值能唯一地标识一个元组,则称该属性或属性组为候选码。
主码(Primary Key):若一个关系有多个候选码,则选定其中一个为主码
主属性(Non-Key attribute):包含在任何候选码中的诸属性称为主属性。不包含在任何候选码中的属性称为非码属性。
外码(Foreign Key):如果关系模式R中的属性或属性组不是该关系的主码,但它是其他关系的主码,那么该属性或属性组是关系模式R的外码。
员工(员工号,姓名,性别,参加工作时间,部门号),部门(部门号,名称,电话,负责人)
关系的三种类型- 基本关系。通常又称为基本表,它是实际存在的表,是实际存储数据的逻辑表示。
- 查询表。查询表是查询结果对应的表。
- 视图表。视图表是由基本表或其他视图表导出的表。由于它本身不独立存储在数据库中,数据库中只存放它的定义,所以常称为虚表。
关系数据库模式
关系的描述称为关系模式(Relation Schema),可以形式化地表示为:R ( U , D , d o m , F ) R(U, D, dom,F) R(U,D,dom,F)
其中,R表示关系名;U是组成该关系的属性名集合;D是属性的域;dom是属性向域的映像集合;F为属性间数据的依赖关系集合。
通常将关系模式简记为:R ( U ) 或 R ( A 1 , A 2 , … , A n ) R(U)或R(A1,A2,…,An) R(U)或R(A1,A2,…,An)
其中,R为关系名,A,A2…,An为属性名或域名,属性向域的映像常常直接说明属性的类型、长度。通常在关系模式主属性上加下划线表示该属性为主码属性。
员工(员工号,姓名,性别,参加工作时间,部门号)
完整性约束
完整性规则提供了一种手段来保证当用户对数据库做修改时不会破坏数据的一致性。防止对数据的意外破坏。
关系模型的完整性规则是对关系的某种约束条件。关系的完整性分为三类:
①实体完整性:关系的主属性不能取空。
②参照完整性:外键的值或者为空,或者必须等于对应关系中的主键值。
员工(员工号,姓名,性别,参加工作时间,部门号),部门(部门号,名称,电话,负责人)
③用户定义完整性:根据语义要求所自定义的约束条件。
关系运算
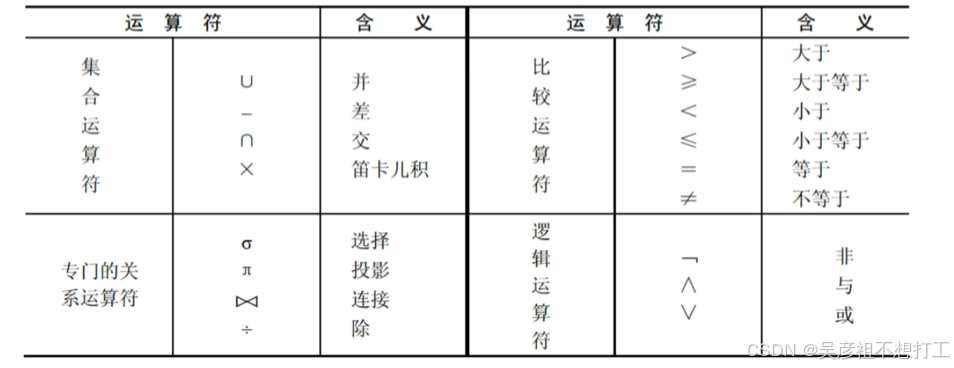
关系操作的特点是操作对象和操作结果都是集合)关系代数运算符有4类:集合运算符、专门的关系运算符、算术比较符和逻辑运算符。
4.数据库sql语言
SQL是结构化查询语言的简称,是关系数据库中最普遍使用的语言,包括数据查询、数据操纵、数据定义和数据控制,是一种通用的、功能强大的关系数据库标准语言。SQL语言支持关系数据库的三级模式。基本表和视图都是表,基本表是存储在数据库中的表,而视图是虚表,是从基本表或其他视图导出的表。数据库中只存放视图的定义,不存放视图的数据。用户可用SQL语言对视图或表进行查询等操作。
数据库语言的分类:作为独立语言使用、嵌入到高级语言中使用:嵌入式SQL、宿主语言。
-
数据类型
-
数值
- int 标准的整数 4个字节 常用的
- float 单精度浮点数 4个字节
- double 双精度浮点数 8个字节 (精度问题!)
- decimal 字符串形式的浮点数 金融计算的时候,一般是使用decimal
-
字符串 ‘xxxxxxxx’
- char 字符串固定大小的 0~255
- varchar 可变字符串 0~65535 常用的变量 String
- text 文本串 2^16-1
-
时间日期
'yyyy-MM-dd'``java.util.Date- data
yyyy-MM-dd日期格式 - time
HH:mm:ss时间格式 - datetime
YYYY-MM-DD HH:mm:ss最常用的时间格式 - timestamp 时间戳 1970.1.1到现在的毫秒数 也较为常用
- year 年份表示
- data
-
null
- 没有值,未知
- 注意:不要使用NULL进行运算,结果一定为NULL
-
-
基础语法
mysql -uroot -p123456 -- dos窗口连接数据库 ------------------------------------------------------------- `与库相关的指令` ------------------------------------------------------------- show databases; -- 查询所有的数据库 ------------------------------------------------------------- use 库名; -- 切换数据库 ------------------------------------------------------------- c -- 创建库 ------------------------------------------------------------- create database if not exists 库名; -- 判断是否存在并创建库 ------------------------------------------------------------- drop database 库名; -- 删除库 ------------------------------------------------------------- show create database 库名; -- 查询库字符集 ------------------------------------------------------------- alter database 库名(default) character 字符集格式; -- 修改库字符集 ------------------------------------------------------------- show databases; -- 查询库字符集语法 ------------------------------------------------------------- `与表相关指令` ------------------------------------------------------------- create table 表名( 字段名称1 数据类型, 字段名称1 数据类型, 字段名称1 数据类型 ); -- 创建表 ------------------------------------------------------------- drop table 表名; -- 删除表 drop table if exists 表名; -- 判断是否存在并删除表 ------------------------------------------------------------- alter table 旧表名 rename 新表名; -- 修改表名 ------------------------------------------------------------- alter table 表名 change 旧字段名 新字段名 数据类型; -- 更改字段名称 ------------------------------------------------------------- alter table 表名 modify 字段名 数据类型; -- 修改表的字段类型 ------------------------------------------------------------- alter table 表名 add 字段名 数据类型; -- 添加表的字段 ------------------------------------------------------------- desc student; -- 显示表的结构 ------------------------------------------------------------- show create table 表名; -- 展示表数据 ------------------------------------------------------------- alter table 表名 drop 字段名; -- 删除表的字段 ------------------------------------------------------------- drop table 表名; -- 删除表 drop table if exists 表名; -- 删除表(如果表存在,再删除) ------------------------------------------------------------- `注释` ------------------------------------------------------------- -- 单行注释 ------------------------------------------------------------- /* 多行注释 */ ------------------------------------------------------------- # 特殊注释 ------------------------------------------------------------- -
DML语言(数据库操作语言)
-
插入数据:
INSERT INTO 表名 (字段1, 字段2, ...) VALUES (值1, 值2, ...);-- 1.插入语句(标准添加信息) INSERT INTO 表名(字段名1,字段名2,字段名3...) VALUES( \ '值1'),('值2'),)'值3')...; -- 2.省略字段名,保证当前值与字段一致 INSERT INTO 表名 VALUES(值1,值2,值3,....值n); -- 3.插入部分字段,没有插入字段的值默认值null INSERT INTO 表名(字段名称1,字段名称2,部分字段) VALUES (值1,值2,部分字段值);插入表中记录注意事项:
- 插入全表字段的值的数量要和字段的数量匹配
- 插入同类型字段要注意(字段名称和字段值的类型必须匹配)
-
更新数据:
UPDATE 表名 SET 字段名1= 值1, 字段名2= 值2 WHERE 条件;-- 1.不带条件(where)修改,属于 "批量修改" (不推荐) UPDATE 表名 SET 字段名称 = 值 ; UPDATE 表名 SET 字段名称1= 值1 ,字段名称2 = 值2; -- 2.推荐:带条件修改 UPDATE 表名 SET 字段名称 = 值; UPDATE 表名 SET 字段名称1 = 值1,字段名称2=值2,...字段名称n = 值n WHERE 非业务字段名称=值;- where 子句 运算符 id等于某个值,大于某个值,在某个区间内修改
- 条件,筛选的条件,如果没有指定则会修改所有的列
- value,是一个具体的值,也可以是一个变量
-
删除数据:
DELETE FROM 表名 WHERE 条件;-- 1.删除数据(避免这样写,会全部删除) DELETE FROM 表名; -- 2.删除指定数据(带条件删除) DELETE FROM 表名 WHERE 条件(例如:id = 1); -- 3.删除表,会重新创建一个一样的空表 TRUNCATE TABLE 表名;delete from 表名;和truncate table 表名;的区别?-
共同点:
delete from表名和truncate table表名都是删除全表的数据 -
不同点:
delete from表名:仅仅只是删除表的记录,表的结构还在(约束相关的信息也就在) 不影响自增主键id的值,下一次插入数据之后,id值在上一次基础上继续自增!truncate table表名:不仅仅删除全表的记录, 会将表删除(表的结构都存在了),会自己创建一张结构一模一样的空表,直接影响自增长主键id 的值;
-
-
-
DQL语句(Data Query Language 数据查询语言)
-
查询数据:
SELECT 字段1, 字段2, ... FROM 表名;-- 1.查询全表:一般写全部字段(开发中)(可指定字段) SELECT 字段名称1,字段名称2,部分字段名称或者指定所有字段名称 FROM 表名; -- 2.查询的时候给字段名称起别名 select 字段名称1 as 别名1,字段名称2 as 别名2...from 表名; (as可以省略不写) -
查询数据:
SELECT 字段1, 字段2, ... FROM 表名 WHERE 条件;(带条件查询)-- 例子 where后面不能跟别名 SELECT name, math+chinese+english '总分' FROM student WHERE 200 < math+chinese+english;基本条件 where条件 筛选数据的条件,可以使用逻辑运算符(AND/OR)和比较运算符(=, <, >, <=, >=, !=)。同时,DML语言也支持子查询、聚合函数等高级操作。
操作符 含义 范围 结果 = 等于 5=6 false <>或!= 不等于 5<>6 true > 大于 5>6 false < 小于 5<6 true >= 大于等于 5>=6 false <= 小于等于 5<=6 true between … and … 在某个范围内 between 2 and 3 true and 我和你 && 5>1 and 1>2 false or 我或你 \ \ -
基本select查询,去除重复的字段值 (字段名称前面加上DISTINCT:去除重复字段值)重复的数据只显示一条
SELECT DISTINCT 字段名 '值' FROM 表名; -
模糊查询
-- LIKE 结合 %(代表任意个字符) _(代表一个字符) SELECT 字段(要查询的字段) FROM 表名 WHERE 字段名(要模糊查询的字段) LIKE '_关键字%'; -- IN关键字 等同于OR的关系,查询某个字段的值为多个值得成员信息 SELECT 字段(要查询的字段) FROM 表名 IN 字段名(值1,值2,值3,...); SELECT 字段(要查询的字段) FROM 表名 WHERE 字段名=值1 OR 字段名=值2 OR 字段名=值3...); -- 查询某个字段结果为null的成员信息 SELECT 字段(要查询的字段) FROM 表名 WHERE 字段名 IS NULL; -- 查询某个字段结果不为null的成员信息 SELECT 字段(要查询的字段) FROM 表名 WHERE 字段名 IS NOT NULL; -- 查询某个字段的值处于一个区间的值的成员信息(等同于AND的关系) SELECT 字段(要查询的字段) FROM 表名 WHERE 字段名 BETWEEN a AND b; SELECT 字段(要查询的字段) FROM 表名 WHERE 字段名>a AND 字段名<b;模糊查询: 比较运算符
运算符 语法 描述 IS NULL a is null 如果操作符为NULL,结果为真 IS NOT NULL a is not null 如果操作符不为NULL,结果为真 BETWEEN a between b and c 若a在b和c之间,则结果为真 like a like b SQL匹配,如果a匹配b,则结果为真( 小红 like 小XX)in a in (a1,a2,a3…) 假设a在a1,或者a2…其中的某一个值中,那结果为真 -
聚合函数
描述 函数名称 计数 COUNT() SELECT COUNT(常用非业务字段) '总和' FROM result
count (*) \ count (id)求和 SUM() SELECT SUM(求和字段) '总和' FROM result平均值 AVG() SELECT AVG(求平均字段) '平均值' FROM result最大值 MAX() SELECT MAX(求最大值字段) 最大值' FROM result最小值 MIN() SELECT MIN(求最小值字段) '最小值' FROM result… … -
排序查询 ORDER BY
-- 排序规则 -- 默认值 ASC(升序) -- DESC(降序) -- 单个排序条件 SELECT 字段(要查询的字段) FROM 表名 ORDER BY 字段名称 排序规则; -- 多个排序条件 先按第一个字段排序,第一个字段相同再根据第二个字段排序 SELECT 字段(要查询的字段) FROM 表名 ORDER BY 字段名称1 排序规则1, 字段名称2 排序规则2;查询条件 WHERE 要在 ORDER BY 的前面
-
分组查询 GROUP BYGROUP BY 后面跟分组字段,聚合函数在 GROUP BY 的后面不能使用
-- 分组基本查询 SELECT 字段列表 FROM 表名 GROUP BY 字段名称; -- 一般情况:group by 和where 搭配使用 SELECT 字段列表 FROM 表名 WHERE 条件 GROUP BY 字段名称;先满足条件:当前where 和group by一块使用,先执行where ,然后在执行group by 分组字段;
-
筛选查询 HAVING一个sql语句,where条件,有分组group by ,有having(它的后面可以跟聚合函数)依次先后顺序,先满足where,在分组,分组基础上进行筛选
SELECT 字段列表 FROM 表名 WHERE 条件 GROUP BY 字段名称 HAVING 筛选条件; -
分页查询 LIMIT
-- 语法: LIMIT 起始值,页面大小(每页数据的总量) 不同数据库语法不同 SELECT 字段列表 FROM 表名 LIMIT 起始行数,页面大小(每页数据的总量); -- 起始行数: = (当前页码数-1)*每页显示的条数; 数据库起始索引为0 -- 实际开发中:页码数currentPage/每页显示的条数pageSize (必须已知数据:前端传来的)
-
-
DQL语句的执行顺序
-- 编写顺序 SELECT 查询字段 FROM 表名 WHERE 查询条件 GROUP BY 分组条件 HAVING 分组后条件 ORDER BY 排序条件 LIMIT 分页参数-- 执行顺序 FROM 表名 WHERE 查询条件 GROUP BY 分组条件 HAVING 分组后条件 SELECT 查询字段 ORDER BY 排序条件 LIMIT 分页参数 -
DCL语句(Date Control Language 数据控制语言
用来管理数据库用户,控制数据库的访问权限
1.查询用户-- 用户信息全部在用户表中 user USE mysql; SELECT * FROM user;2.创建用户
-- 创建用户只能在当前主机 localhost 访问 密码 123456 CREATE USER 'user_name'@'localhost' IDENTIFIED BY '12345'; -- 创建用户可以在任意主机访问该数据库(使用%通配主机名) 密码 123456 CREATE USER 'user_name'@'%' IDENTIFIED BY '123456';3.修改用户密码
-- 修改用户的密码为666666 ALTER user 'user_name'@'%' IDENTIFIED WITH mysql_native_password BY '666666';4.删除用户
DROP user 'user_name'@'localhost';5.权限控制
-
授权
GRANT<权限>[<权限>]… [ON<对象类型><对象名>)TO<用户>[,<用户]>]…[WITH GRANT OPTION]- 若指定了WITH GRANT OPTION子句,那么获得了权限的用户还可以将权限赋给其他用户: 接受权限的用户可以是单个或多个具体的用户,PUBLIC参数可将权限赋给全体用户。不同类型的操作对象有不同的操作权限,常见的操作权限如表所示。
grant insert on table S to user1 with grant option;- 回收权限
REVOKE<权限>[,<权限>]… [ON<对象类型><对象名>]FROM<用户>[,<用户]>]… ;
revoke select on table S from user1; -
-
数据库约束
约束:限制用户操作数据库的行为*-
默认约束 DEFAULT
-
非空约束 NOT NULL
-
唯一约束 UNIQUE
-- 通过创建表 CREATE TABLE test( id INT PRIMARY KEY AUTO_INCREMENT, -- 编号(添加主键,同时自增长) name VARCHAR(10) NOT NULL , -- 姓名 不能为空 address VARCHAR(50) DEFAULT '西安市', -- 地址默认西安市 telephone VARCHAR(11) UNIQUE -- 电话号码(唯一) );-
-通过sql语句添加唯一约束
alter table 表名 add constraint(声明) 唯一约束索引的名称 unique(给哪个字段名称); ALTER TABLE test ADD CONSTRAINT unique_telephone UNIQUE (telephone) ; -
通过sql语句更改表,删除唯一约束
-- 错误语法: alter table test modify telephone varchar(11) ; -- 正常语法:alter table 表名 drop index 唯一约束的名称 (默认和当前的字段名称一致) ALTER TABLE test DROP INDEX telephone
-
-
主键约束 primary key
不能直接插入null值,不能重复primary key -- 作用每一张表的id(非业务字段,设置为主键) CREATE TABLE test( id INT PRIMARY KEY AUTO_INCREMENT, -- 创建表的时候添加主键,同时自增长 NAME VARCHAR(10) in );-
sql语句直接主键删除
alter table 表名 drop primary key ; – 将唯一删除,not null非空还存在
ALTER TABLE test DROP PRIMARY KEY ; -
sql语句添加主键约束(唯一特性加上)
alter table 表名 modify id int PRIMARY KEY ;
ALTER TABLE test MODIFY id INT PRIMARY KEY ;
-
-
外键约束
foreign key- 方式一
* 在创建表的时候,增加约束(麻烦,比较复杂) -- 主表 部门 CREATE TABLE dept( id INT PRIMARY KEY AUTO_INCREMENT, -- 部门id(必须是主键) deptName VARCHAR(10) -- 部门名称 ); -- 从表 员工 CREATE TABLE employee( id INT PRIMARY KEY AUTO_INCREMENT, -- 员工编号(主键自增) NAME VARCHAR(10), -- 员工姓名 gender VARCHAR(5), -- 性别 birthday DATE, -- 出生日期 salary DOUBLE, -- 薪水 dept_id INT, -- 部门ID(将部门信息与员工信息分开,然后做外键约束,使其关联) CONSTRAINT -- constraint: 后接外键名 主表名_从表名_fk dept_emp_fk FOREIGN KEY -- 要关联的字段 (dept_id) REFERENCES -- 主表的主键字段 dept(id) ); * 删除约束 alter table 表名 drop foreign key 外键名称;- 方式二
* 通过sql添加外键约束 alter table 表名 add constraint -- 外键名称 foreign key -- 要关联从表的字段 references -- 主表名(主键字段);-
从表的某个字段依赖于主表的主键字段
-
有了外键约束,不能直接操作主表(删除/修改),因为从表的数据和主表有关联!
-
要修改主表的主键字段,这个主键必须在与从表没有关联,比如先删除或修改有约束的项,取消关联
级联操作在添加外键时,声明级联操作
alter table 表名 add constraint -- 外键名称 foreign key -- 要关联从表的字段 references -- 表名(主键字段) on update cascade -- 级联修改 on delete cascade; -- 级联删除为什么要级联操作?
- 如果要修改外键的值,修改时十分麻烦:需要先将引用的外键
- 级联更新:【例】我将部门的id更新后,员工表中部门外键也一同更新
- 如果要研发部门和其部下的员工,需要先删除部门下的所有员工,再将该部门删除
- 级联删除:【例】属于研发部门和其部下的员工全删除,只需要在外键表中删除外键数据即可,关联的表中的数据一并删除
-
-
数据库范式
第一范式(1NF)
原子性:保证每一列不可再分
一个字段不能再细分出其他字段- 正确表格样式如下
id(学号) old_name(曾用名) new_name(姓名) age(年龄) gender(性别) 1 张三 张三丰 23 男 第二范式(2NF)
前提:满足第一范式
第二范式需要确保数据库表中的每一列非主键字段都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。(非主属性完全依赖于主键)-
每张表只描述一件事情
-
每一列非主键字段必须完全依赖于主键字段学院这个字段并不依赖于id,学院是属于学生信息以外得属性
| id(学号) | name(姓名) | age(年龄) | gender(性别) | college(学院) |
|---|---|---|---|---|
| 1 | 张三 | 23 | 男 | 理学院 |
采用外键(foreign key stu_coll_fk )约束,将学生信息与学院信息分开
正确表格样式如下:
-
主表(student)
id(学院编号) college_name(学院名称) 1 理学院 -
从表(college)
id(学号) name(姓名) age(年龄) gender(性别) college_id(学院编号) 1 张三 23 男 1 第三范式(3NF)
前提:满足第一范式和第二范式
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。(不能存在传递依赖,非主属性,直接依赖于主键)
规范数据库的设计,减少数据冗余 -
学生表(student)
id(学号)(主键) name(姓名) age(年龄) 1 张三 23 2 李四 21 3 王五 20 -
课程表(class)
id(课程编号) (主键) 课程名 授课教师 1 工程力学 岳不群 2 材料力学 左冷禅 -
中间表***(关联两个外键 学生id 和 课程id)***
id(主键) student_id(学号) class_id(课程编号) 1 1 2 2 2 1 3 3 2 规范性和性能的问题
关联查询的表不得超过三张表
-
考虑商业化的需求和目标(成本,用户体验)数据库的性能更加重要
-
在规范性能的问题的时候,需要适当的考虑一下规范性
-
故意给某些表增加一些冗余的字段。(从多表查询中变为单表查询)
-
故意增加一些计算列(从大数据库降低为小数据量的查询:索引)
-
数据库事务
什么是数据库的事务?
事务是用户定义的一个数据库操作序列,这些操作要么全做要么全不做,是一个不可分割的工作单位
关系型数据库中支持"多事务"
事务就是DBA(数据库管理员)操作多个sql的时候 将整个sql(多个sql)的执行看成一个"整体",要么同时执行成功,要么同时执行失败! 始终保证的数据的一致性(高并发中,读/写)要么都成功,要么都失败
核心:将一组SQL放在一个批次中去执行事务原则:ACID原则 原子性,一致性,隔离性,持久性
- 原子性表示,事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
- 一致性表示,事务前后的数据完整性要保证一致
- 持久性表示,一个事务一旦提交,他对数据库的修改应该永久保存在数据库中。
- 隔离性表示,多个事务并发执行时,一个事务的执行不应影响其他事务的执行,事务与事物之间是相互独立的
隔离级别:
1. read uncommitted; 读未提交,读取到其他事事务未提交的数据(脏读,但不允许更新丢失) 2. read committed; 读已提交,读取到其他事务已经提交的数据,在当前事务中前后数据不一致(不可重复读,不允许脏读) 3. repeatable read; 可重复读(MySql默认级别)(可能会出现幻读) 4. serializable; 串行话 `执行效率由高到低,安全性由低到高`-
脏读:事务A读到了事务B未提交的数据。
-
不可重复读:事务A第一次查询得到一行记录row1,事务B提交修改后,事务A第二次查询得到row1,但列内容发生了变化。
-
幻读:事务A第一次查询得到一行记录row1,事务B提交修改后,事务A第二次查询得到两行记录row1和row2。
-- 查询隔离级别 SELECT @@tx_isolation; -- 设置隔离级别 set global transaction isolation level (级别的名称) ;通过MySQL指令如何控制事务 ?
-- 开启事务: start transaction; -- 设置回滚命令 rollback; -- 永久更新数据(保证数据的持久性) commit;事务的传播性
事务的传播性(Transaction Propagation)指的是在多个事务之间进行操作时,事务的隔离级别和行为如何传播和影响其他事务。在关系型数据库中,常见的事务传播性有以下几种:- REQUIRED:如果当前存在事务,则加入该事务,如果没有事务则创建一个新的事务。这是默认的传播行为。
- REQUIRES_NEW:无论当前是否存在事务,都创建一个新的事务。如果当前存在事务,则将其挂起。
- SUPPORTS:如果当前存在事务,则加入该事务,如果没有事务则以非事务方式执行。
- NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,则将其挂起。
- MANDATORY:如果当前存在事务,则加入该事务,如果没有事务则抛出异常。
- NEVER:以非事务方式执行操作,如果当前存在事务,则抛出异常。
- NESTED:如果当前存在事务,则在一个嵌套的事务中执行。如果没有事务,则创建一个新的事务。这些传播性选项可以根据具体的业务需求和操作场景来选择,以确保事务的一致性和隔离性。在使用事务时,需要考虑事务的传播性,并根据需要进行适当的设置。
5.函数依赖
关系数据库设计的方法之一就是设计满足合适范式的模式。关系数据库规范化理论主要包括数据依赖、范式和模式设计方法。其中核心基础是数据依赖,数据依赖中最重要、最基本的就是函数依赖。
-
函数依赖
设R(U)是属性集U上的关系模式,X、Y是U的子集。若对R(U)的任何一个可能的关系r,r中不可能存在两个元组在X上的属性值相等,而在Y上的属性值不等,则称X函数决定Y或Y函数依赖于X,记作X →Y。 -
部分函数依赖
如果X → Y,但Y不完全函数依赖于X,则称Y对X部分函数依赖。 -
传递依赖
在R(U,F)中,如果X → Y,Y ⊈ X,Y → Z 支Z则称Z对X传递依赖。其中,U:属性集,F:是U上的一组函数依赖。
函数依赖求候选键:从一个或一组属性出发,通过函数依赖集中的依赖关系,能决定关系模式中的其他所有属性,则这个属性或属性组为候选键。 -
函数依赖的公理系统(Armstrong公理系统)设关系模式R(U,F),其中U为属性集,
F是U上的一组函数依赖,那么有以下推理规则。
A1自反律:若Y⊆X⊆U,则X→Y为F所蕴涵。
A2增广律:若X→Y为F所蕴涵,且Z⊆U,则XZ→YZ为F所蕴涵。
A3传递律:若X →Y,Y→Z为F所蕴涵,则X→Z为F所蕴涵。
6.规范化
关系数据库设计的方法之一就是设计满足适当范式的模式,通常可以通过判断分解后的模式达到几范式来评价模式规范化的程度。范式有:5NF ⊂ 4NF ⊂ BCNF ⊂ 3NF ⊂ 2NF ⊂ 1NF,其中级别最高,模式规范化程度也就越高。
-
1NF(第一范式)
定义:若关系模式R的每一个分量是不可再分的数据项,则关系模式R属于第一范式。即属性是原子不可再分的。1NF存在的问题:数据冗余、插入异常、删除异常等问题。 -
2NF(第二范式)
定义:若关系模式R ∈ 1NF,且每一个非主属性完全(函数)依赖于码,则关系模式R ∈ 2NF。即每个非主属性都由整个码决定。当1NF消除了非主属性对码的部分函数依赖,则称为2NF。 -
3NF(第三范式)
定义:若关系模式R(U,F)中不存在这样的码X,属性组Y及非主属性Z(Z⊈Y)使得X→Y(Y ⇏ X),Y→Z成立,则关系模式R E 3NF。即当2NF消除了非主属性对码的传递函数依赖,则称为3NF。 -
BCNF (巴克斯范式)
BCNF是修正的第三范式。规定了每个属性(包括主属性)都不传递依赖于码。 -
4NF(第四范式)
4NF主要是消除了多值依赖。
7.数据库的备份与恢复
-
数据库的故障类型
①事务内部故障:如运算溢出、除零错误、并发事务发生死锁等;
②系统故障:也称为软故障,是指造成系统停运的事件,如CPU故障、OS故障、突然停电等;
③介质故障:也称为硬故障,如磁盘损坏等;
④计算机病毒。 -
数据库的备份方法
数据库的转储分为静态转储和动态转储、海量转储和增量转储、日志文件。
①海量转储(完全转储)︰是指每次转储全部数据库;
②增量转储:是指每次只转储上次转储后更新过的数据,用于数据库很大,事务处理频繁的场景;
③差量转储:是对最近一次数据库完全备份以来发生的数据变化进行备份,优点是速度快,占用较小的时间
8.并发控制
并发操作就是在多用户系统中,可能出现多个事务同时操作同一数据的情况。并发操作会导致3种数据不一致的问题。
-
并发操作问题
-
丢失修改(丢失更新)
当两个事务T1和T2读入同一数据做修改,并发执行时,T1,把T2,或T2把T1的修改结果覆盖掉,造成了数据的丢失更新问题,导致数据不一致。 -
不可重复读
事务T1,读取了数据R,事务T2读取并更新了数据R。当事务T1再读取数据R以进行核对时,得到的两次读取数据不一致。 -
读脏数据
事务T1更新了数据R,事务T2读取了更新后的数据R,事务T1由于某种原因被撤销,进行了事务回滚,数据
R恢复原值,事务T2读取了脏数据。
-
-
封锁的类型,理并发控制的主要方法是采用封锁技术,有两种类型的封锁:
-
X封锁(排他型封锁)
-
S封锁(共享型封锁)
-
排他型封锁( X封锁)
如果事务T对数据A(可以是数据项、记录、数据集以至整个数据 库)实现了X封锁,那么只允许事务T读取和修改数据A,其他事务要等事务T解除X封锁以后,才能对数据A实现任何类型的封锁。 可见X封锁只允许一个事务独锁某个数据,具有排他性。 -
共享型封锁(S封锁)
S封锁允许并发读,但不允许修改,也就是说,如果事务T对数据 A实现了S封锁,那么允许事务T读取数据A,但不能修改数据A, 在所有S封锁解除之前决不允许任何事务对数据A实现X封锁。
-
9.数据仓库
数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
OLAP服务器:联机分析处理服务器,快速汇总大量数据并进行高效查询分析,为分析人员提供决策支持。
-
数据仓库与数据库的对比
数据仓库 数据库 面向主题的 面向事务的 数据结构是集成的,具有一致性 数据结构更为复杂 设计需要引入冗余 是动态变化的,业务发生,数据就更新 存储历史数据 存储实时、在线数据 设计需要引入冗余 设计尽量避免冗余
10.分布式数据库
分布式数据库通常使用较小的计算机系统,每台计算机可以单独放在一个地方,每台计算机中都可能有DBMS的一份完整拷贝副本或部分拷贝副本,并具有自己局部的数据库,位于不同地点的许多计算机通过网络互相连接,共同组成一个完整的、全局的逻辑上集中、物理上分布的大型数据库。
分布式数据库的核心:
- 数据分片:突破中心化数据库单机的容量限制,将数据分散到多节点,以更灵活、高效的方式来处理数据。分片方式包括①水平分片:按行进行数据分割,数据被分割为一个个数据组,分散到不同节点上;②垂直分片:按列进行数据分割,一个数据表的模式被切割为多个小的模式。
- 数据同步:由于数据库理论传统上是建立在单机数据库基础上,而引入分布式理论后,一致性原则被打破。因此需要引入数据库同步技术来帮助数据库恢复一致性。
分布式数据库的特点:高可扩展性、高并发性、高可用性。
-
分布式数据库透明性
分片透明:指用户或应用程序不需要知道逻辑上访问的表具体是怎么分块存储的。
复制透明:指采用复制技术的分布方法,用户不需要知道数据是复制到哪些节点,如何复制的。
位置透明:指用户无需知道数据存放的物理位置,
逻辑透明:局部数据模型透明,是指用户或应用程序无需知道局部场地使用的是哪种数据模型。
第十章 网络与信息安全基础
1.网络概述
-
计算机网络的发展
计算机网络是计算机技术与通信技术相结合的产物,它实现了远程通信、远程信息处理和资源共享。 -
计算机网络的功能
数据通信、资源共享、负载均衡、高可靠性。 -
计算机网络的分类
按分布范围划分:局域网、城域网、广域网 -
网络拓扑结构
网络拓扑结构是指网络中通信线路和结点的几何排序,用于表示整个网络的结构外貌,反映各结点之间的结构关系。常用的网络拓扑结构有总线型、星型、环型、树型和分布式结构等。
-
网络体系结构
ISO/OSI参考模型
ISO/OSI的参考模型一共有7层,由低层到高层分别为:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。
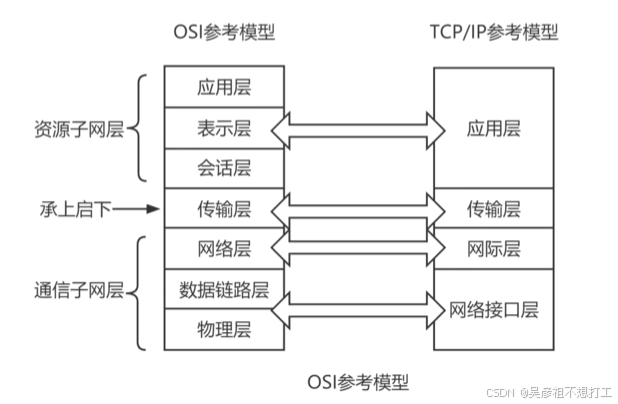
- 物理层:为数据链路层提供一个物理连接以及它们的机械、电气、功能和过程特性。传输的数据单位是比特。
- 数据链路层:负责在两个相邻结点间的线路上无差错地传输帧数据,并进行流量控制。传输的数据单位是帧。
- 网络层:将数据链路层的帧数据组成数据包,数据包中有源网络地址和目的网络地址,主要提供路由选择功能,除此之外还有差错检测和恢复、流量/拥塞控制、激活和终止网络连接等功能。传输的数据单位是数据包。
- 传输层:为会话层提供透明、可靠的端到端的数据传输服务。其功能有数据分段、数据传输、数据组装、差错控制、流量/拥塞控制等。传输的数据单位报文。
- 会话层:为表示层提供建立、维护和结束会话连接的功能,提供会话管理功能,传输的数据单位是报文。
- 表示层:提供格式化的表示和转换数据服务,如数据的压缩、解压缩、加密和解密等。
- 应用层:面向用户服务,提供网络与用户应用软件之间的接口服务,如文件传输、电子邮件、远程登录等。
2.网络互联设备
-
网络设备
-
物理层
中继器:信号在介质里传输的过程中会有衰减和噪声,使用中继器进行放大和去噪
集线器:是一种特殊的多路中继器 -
数据链路层
网桥:连接两个局域网,检查帧的源地址和目的地址,若两者在同一网络段上,则不转发,否则转发到另一个网络段上
交换机:检查以太网帧的目的地址MAC,在自己的地址表(端口号-MAC)中进行查找并转发 -
网络层
路由器:用于连接多个逻辑上分开的网络,最主要的功能是选择路由路径 -
应用层
网关:将协议进行转换,将数据重新分组,以便在两个不同类型的网络系统之间进行通信
-
-
网络的传输介质
-
有线介质
双绞线、同轴电缆、光纤 -
无线介质
微波、红外线、激光、卫星
-
3.网络协议与标准
计算机网络设备之间要进行通信,需要共同遵守一些规则、标准或者说约定,称为协议。
-
网络的标准
- 电信标准:V系列(针对调制解调器的标准)X系列(针对广域网的标准,X.1-X.39标准应用于终端形式、接口、服务设施和设备;X.25规定了数据包装和传送的协议;X.40-X.199标准管理网络结构、传输、发信号等)
-
国际标准:ANSI(美国国家标准研究所)NIST(美国国家标准技术研究所)IEEE(电气和电子工程师协会)EIA(电子工业协会)
-
Internet标准:自发的而非政府干预的,目前已组成了一个民间性质的协会ISOC进行必要的协调与管理
-
局域网协议
以太网规范:通过使用MAC地址来唯一标识每一个网络设备,并通过交换机进行数据传输,IEEE 802.3标准
令牌环网:IEEE 802.5
无线局域网WLAN技术标准:IEEE 802.11 -
广域网协议
PPP点对点协议(拨号上网):用于建立、配置和维护数据链路的连接
xDSL数字用户线:是各种数字用户线的统称
DDN数字专线、ISDN综合业务数字网、FR帧中继等 -
TCP/IP协议族
TCP/IP是Internet的核心协议,被广泛应用于局域网和广域网中,已成为事实上的国际标准。
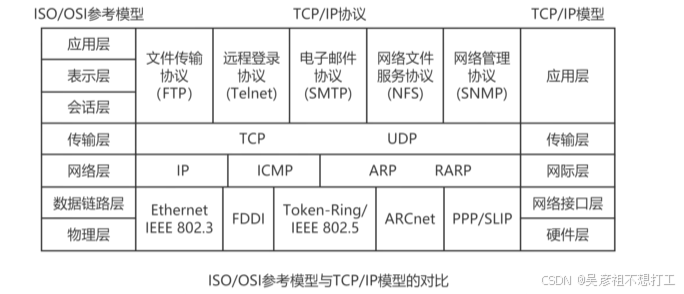
-
应用层:在模型的最高层,用户调用应用程序来访问TCP/IP互连网络,以享受网络上提供的各种服务。
-
传输层:提供应用程序之间的通信服务。
-
网际层:又称IP层,它主要有三个功能:①把数组分组封装到IP数据报中,填入数据报的首部,使用路由算法选择路由送达机器;②处理接收到的数据报,检验其正确性;③发出ICMP差错和控制报文,并处理收到的ICMP报文。
-
网络接口层:处于TCP/IP的最下层,主要负责为物理网络准备数据所需的全部服务程序和功能。
网际层协议:
IP只提供无连接、不可靠的服务,将上层数据(如TCP、UDP数据)或同层的其他数据(如ICMP数据)封装到IP数据报中,将IP数据报传送到最终目的地
ARP和RARP:地址解析协议及反地址解析协议,ARP将IP地址转换为物理(MAC)地址,RARP将物理(MAC)地址转回IP地址
ICMP:专门用于发送差错报文的协议,用于发送错误及检查信息
传输层协议:
TCP:在IP提供的不可靠数据服务的基础上为应用程序提供了一个可靠的、面向连接的、全双工的数据传输服务,TCP在建立和关闭连接时需要“三次握手”
UDP:一种不可靠的、无连接的协议,但有助于提高传输的高速率性
应用层协议:NFS、Telnet、SMTP、DNS、SNMP、FTP等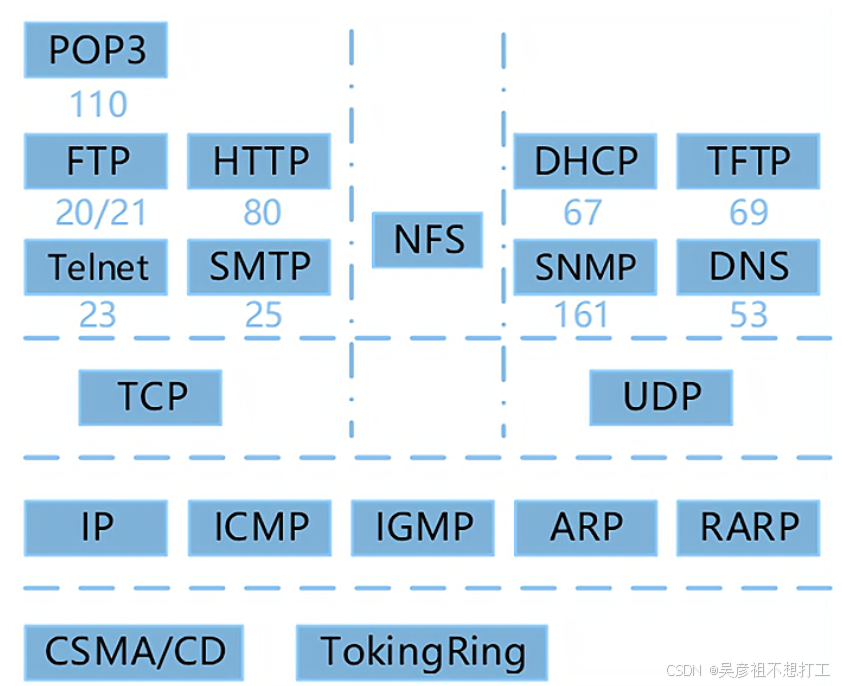
-
4.Internet及其应用
Internet是世界上规模最大、覆盖面最广且最具影响力的计算机互连网络,它是将分布在世界各地的计算机采用开放系统协议连接在一起,用来进行数据传输、信息交换和资源共享。
-
Internet地址
Internet地址有两种书写形式:域名形式和IP地址-
域名
一个完整、通用的层次性主机域名由4个部分组成:计算机主机名.本地名.组名.最高层域名。
例如: www.dzkjdx.edu.cn cn是地理性顶级域名,表示“中国”。
www.263.net net是组织性顶级域名,表示“网络技术组织机构”。
常用域名后缀: com(商业组织、公司),top(顶级、高端、适用于任何商业、公司、个人) ,edu(教育机构)。 -
IP地址
Internet中的主机地址是用IP地址来标识的。这是因为因特网使用的网络协议是TCP/IP协议,此每个主机必须用IP地址来标识。
IP地址(IPv4)由4个8位的二进制数来表示,共32位。为了便于使用,通常将二进制“翻译”十进制,数字之间用“.”分开。二进制IP地址 十进制IP地址 对应域名 11111111.00000000.00000000.00000001 127.0.0.1 localhost 域名与IP地址是一一对应的,域名更容易记忆。要访问某台计算机时,我们只需要使用域名,域名服务器(DNS)会帮助我们将域名转换成IP地址。
-
地址分配
Internet中的地址可分5类:A、B、C、D、E类。全0代表的是网络,全1代表的是广播
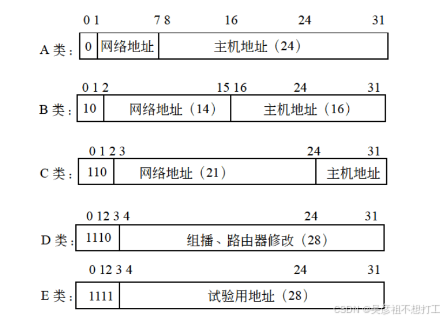
-
子网划分
采用子网划分的方法来划分网络,即自定义网络号位数,根据主机个数来划分最合适的方案,避免资源的浪费。
将主机号拿出几位作为子网号,就可以划分出多个子网,此时IP地址组成为:网络号+子网号+主机号。
子网掩码:网络号、子网号均为1+主机号均为0。 -
无分类编址
无分类编址自定义网络号位数,格式为:IP地址/网络号位数,例如:220.112.145.32/22,其网络号占22位,主机号占32-22=10位。 -
IPv6简介
IPv6数据包有一个40字节的基本首部,其后允许有0个或多个扩展首部,再后面是数据。IPv6的地址长度为128位,每组由4个十六进制数表示,用“:"分开。
①单播地址:传统的点对点通信。
②多播地址:一对多的通信,数据包交付到一组计算机中。
③任播地址:IPv6新增的类型。任播的目的站是一组计算机,但只交付其中一个,通常是距离最近的那个。 -
无效的IP地址:169.254.X.X(windows)和0.0.0.0(linux)。
-
-
Internet服务
Internet服务 说明 DNS域名服务 DNS域名解析协议,域名服务器将域名转换为IP地址,使用UDP端口,端口号为53 远程登录服务 Telnet协议,使用TCP端口,端口号为23 电子邮件(E-mail)服务 简单邮件传输协议SMTP(简单邮件发送协议,使用TCP端口,端口号为25),POP3(邮件接收协议,使用TCP端口,端口号为110),多用途邮件扩充协议MIME、增强私密邮件保护协议PEM www服务 超文本传输协议HTTP,使用TCP端口,端口号为80。HTTPS (具有安全性的SSL加密传输协议)端口443 文件传输服务 FTP协议,使用TCP端口,有两种TCP连接:①控制连接,传输口令和参数,端口号为21;②数据连接,传输文件,端口号为20。 网络文件服务 网络文件服务协议NFS,使用UDP端口,端口号为2049,允许客户端可以像本地文件系统一样,访问网络上计算机之间共享的文件和目录。 网络管理服务 简单网络管理协议SNMP,使用UDP端口,端口号:①用于数据传送与接收的161端口;②用于报警信息接收的162端口。它允许网络管理员监视和管理网络设备、服务器、路由器和其他网络设备的运行状态和性能。 -
网络管理常用命令
网管命令 说明 ipconfig 显示当前TCPIP协议所设置的值,如IP地址、子网掩码、缺省网关、Mac地址等 netstat 显示网络连接、路由表和网络接口信息 nslookup 查询Internet域名信息或诊断DNS服务器问题的工具 ping 检查网络是否连通 tracert 配置路由和查看当前路由情况 ipconfig 显示信息;
ipconfig /all 显示详细信息,可查看DHCP服务是否已启用;
ipconfig /renew 更新所有适配器;
ipconfig /release 释放所有匹配的连接。
5.信息安全基础知识
-
信息安全包括5个要素:机密性、完整性、可用性、可控性与可审查性。
-
计算机病毒具有隐蔽性、传染性、潜伏性、触发性和破坏性等特点。
类型 说明 蠕虫病毒(感染exe文件) 熊猫烧香、罗密欧与朱丽叶、恶鹰、尼姆达、冲击波、爱虫、永恒之蓝 木马 特洛伊木马、QQ消息尾巴木马 宏病毒(感染word、excel等、文件中的宏变量) 美丽沙、台湾1号 红色代码 新型网络病毒,将网络蠕虫、计算机病毒、木马程序合为一体 CIH病毒 史上唯一破坏硬件的病毒 冰河木马病毒 感染该病毒之后,黑客就可以通过网络远程控制该电脑 引导区病毒破坏的是引导盘、文件目录等;宏病毒破坏的是OFFICE文件相关;木马的作用一般强调控制操作。
6.网络安全概述
-
网络安全威胁
非授权访问:假冒、身份攻击、非法用户进入网络系统、合法用户以未授权方式进入等
信息泄露或丢失:通过对信息流向、流量等分析推测出有用信息
破坏数据完整性:恶意添加、修改等数据以干扰用户正常使用
拒绝服务攻击:不断对网络服务进行干扰,执行无关程序使系统响应减慢甚至瘫痪,影响正常使用
利用网络传播病毒:通过网络传播计算机病毒数据的机密性(保密性)是指数据在传输过程中不能被非授权者偷看;
数据的完整性是指数据在传输过程中不能被非法篡改,本题涉及到修改的只有完整性;
数据的真实性(不可抵赖性)是指信息的发送者身份的确认或系统中有关主体的身份确认,这样可以保证信息的可信度;
可用性指的是发送者和接受者双方的通信方式正常。 -
网络安全控制技术
防火墙技术:在内部网络和外部因特网之间增加的一道安全措施
加密技术:网络信息安全主动的、开放性的防御手段,主要有对称加密和非对称加密两大类
用户识别技术:识别访问者是否属于系统的合法用户
访问控制技术:控制不同用户对资源的访问权限
入侵检测技术:检测对系统资源的非授权使用包过滤防火墙
在网络层对数据包进行基础过滤,根据IP地址、端口等信息决定是否允许数据通过。
应用级网关防火墙
在应用层工作,对数据内容进行深入分析,监控和过滤应用数据流,如HTTP、FTP等协议的数据;web保护、网页保护、负载均衡等。
状态监测防火墙
状态监测防火墙结合了代理防火墙的安全性和包过滤防火墙的高速度等优点,在不损失安全性的技术上将代理防火墙的性能提高了10倍 -
入侵检测与防御
入侵检测系统(IDS)不仅检测外部入侵,也检测内部未授权(违规行为)的活动。对数据的分析是入侵检测的核心。IDS是防火墙之后的又一道防线,可以发现防火墙没有发现的入侵行为。
入侵防御系统((IPS)是在入侵检测系统的基础上发展起来的,不仅能检测到网络中的攻击行为而且能同时主动的对攻击行为发出响应,对攻击进行防御。网络攻击分为主动攻击和被动攻击两种。主动攻击包含攻击者访问他所需信息的故意行为。比如通过远程登录到特定机器的邮件端口以找出企业的邮件服务器的信息;伪造无效IP地址去连接服务器,使接受到错误IP地址的系统浪费时间去连接那个非法地址。攻击者是在主动地做一些不利于你或你的公司系统的事情。主动攻击包括拒绝服务攻击(DoS)、分布式拒绝服务(DDoS)、信息篡改、资源使用、欺骗、伪装、重放等攻击方法。
主要是收集信息而不是进行访问,数据的合法用户对这种活动一点也不会觉察到。被动攻击包括嗅探、信息收集等攻击方法(流量分析、系统干涉)。
第十一章 标准化和软件知识产权基础知识
1.标准的分类
-
根据适用的范围分类:
国际标准指国际化标准组织(ISO)、国际电工委员会(IEC)所制定的标准,以及ISO所收录的其他国际组织制定的标准。
国家标准:中华人民共和国国家标准(GB),美国国家标准(ANSI),英国国家标准(BS),日本工业标准(JIS)
区域标准:泛指按地理、经济或政治划分的标准。
行业标准:美国电气和电子工程师学会标准(IEEE),中华人民共和国国家军用标准(GJB),美国国防部标准(DOD- STD)
企业标准:由某一科研生产项目组织制定,且为该项任务专用的软件工程规范。
项目范围:根据规定,我国标准分为国家标准、行业标准、地方标准和企业标准。 -
根据标准的性质分类:
技术标准、管理标准、工作标准 -
根据标准化的对象和作用分类:
可分为基础标准、产品标准、方法标准、安全标准等
2.标准化组织
ISO(国际标准化组合)和IEC(国际电工委员会)是世界上两个最大、最具权威的国际标准化组织。目前,由ISO确认并公布的国际标准化组织还有国际计量局(BIPM)、联合国教科文组织(UNESCO)等27个国际组织。
3.知识产权
知识产权是指民事权利主体(公民、法人)基于创造性的智力成果。
-
根据国际公约,知识产权的保护对象包括:
①文学、艺术和科学作品;
②表演艺术家的表演,以及唱片和广播节目;
③人类一切活动领域的发明;
④科学发现;
⑤工业品外观设计;
⑥商标、服务标记、商业名称和标志;
⑦制止不正当竞争;
⑧在工业、科学、文学艺术领域内由于智力创造活动而产生的一切其他权利。根据世贸协议,知识产权还包括"未披露过的信息专有权",即商业秘密。 -
知识产权的分类:
工业产权:专利、实用新型、工业品外观设计、商标、服务标记、厂商名称、产地标记或原产地名称、制止不正当竞争、商业秘密、微生物技术和遗传基因技术等。
著作权(版权):①人身权(精神权利):发表权、署名权、修改权、保护作品完整性权;②财产权(经济权利):使用权、获得报酬权。 -
计算机软件著作权
《中华人民共和国著作权法》和《计算机软件保护条例》是构成我国保护计算机软件著作权的两个基本法律文件。-
获取软件著作权主体资格的途径如下:
①公民:独立开发、委托开发(约定归自己所有)、转让、合作开发、继承(署名权除外)
②法人:组织并提供创作条件;委托、转让等合同关系;主体变更。
③其他组织。
一般情况下属于职务作品,按国家著作权法规定,应属于单位所有。但如果刘某与单位事先有特别约定,应遵从约定。 -
计算机软件著作权的客体:计算机程序及其有关文档。
-
计算机软件受著作权法保护的条件:
①独立创作:非复制和抄袭。
②可被感知:创作思想在固定载体中的实际表达。
③逻辑合理。
-
4.知识产权的保护期限
| 客体类型 | 权利类型 | 保护期限 |
|---|---|---|
| 公民作品 | 署名权、修改权、保护作品完整权 | 无限制 |
| 公民作品 | 发表权、使用权和获得报酬权 | 作者终生及其死后50年(第50年的12月31日) |
| 单位作品 | 发表权、使用权和获得报酬权(属于集体,无署名权、修改权等) | 50年(首次发表后的第50年的12月31日),若期间未发表,不保护 |
| 公民软件产品 | 公民软件产品 | 无限制 |
| 公民软件产品 | 发表权、复制权、发行权、出租权、信息网络传播权、翻译权、使用许可权、获得报酬权、转让权 | 作者终生及其死后50年(第50年的12月31日),合作开发的,以最后死亡作者为准 |
| 单位软件产品 | 发表权、复制权、发行权、出租权、信息网络传播权、翻译权、使用许可权、获得报酬权、转让权 | 50年(首次发表后的第50年的12月31日),若期间未发表,不保护 |
| 注册商标 | 有效期10年(若注册人死亡或倒闭1年后,未转移则可注销;期满后6个月内必须续注) | |
| 发明专利权 | 保护期为20年(从申请日开始) | |
| 实用新型和外 | 保护期为10年(从申请日开始) | |
| 观设计专利权 | 保护期为10年(从申请日开始) | |
| 商业秘密 | 不确定,公开后公众可用 |

















 4224
4224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









