





 本文介绍了如何用C++从头开始实现单向链表,包括链表概念、结点结构、数组与链表的区别,以及如何声明和操作链表。重点在于通过实例演示链表的基本操作。
本文介绍了如何用C++从头开始实现单向链表,包括链表概念、结点结构、数组与链表的区别,以及如何声明和操作链表。重点在于通过实例演示链表的基本操作。
一、前言
曾经学数据结构,总是基于抽象化的学习,比如链表的插入,二叉树的平衡旋转,图的DFS和BFS等。
然而,实践和代码能力才是一个程序员的硬实力,所以我决定在此开一个新的专栏——数据结构,来记录我对抽象数据结构用C++的一一实现。
今天我学习链表中的:单向链表的建立,插入,删除
二、链表的概念
链表实际上是线性表的链式存储结构,与数组不同的是,它是用一组任意的存储单元来存储线性表中的数据,存储单元不一定是连续的。
且链表的长度不是固定的,链表数据的这一特点使其可以非常的方便地实现节点的插入和删除操作。
链表的每个元素称为一个节点,每个节点都可以存储在内存中的不同的位置,为了表示每个元素与后继元素的逻辑关系,以便构成“一个节点链着一个节点”的链式存储结构,
除了存储元素本身的信息外,还要存储其直接后继信息,因此,每个节点都包含两个部分,
第一部分称为链表的数据域,用于存储元素本身的数据信息,这里用data表示,它不局限于一个成员数据,也可是多个成员数据;
第二部分是一个结构体指针,称为链表的指针域,用于存储其直接后继的节点信息,这里用next表示。
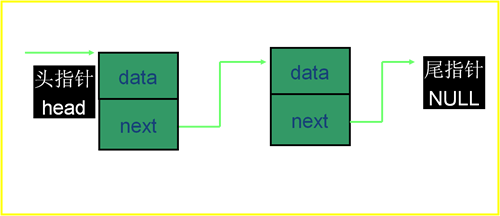
上图中,首先有一个头结点,头结点是放在第一个元素结点之前的结点,头结点不是链表中的必须元素,其数据域一般无意义,(有些情况下会存放链表的长度,或用作监视哨等)。
头结点的指针域指向下一个结构体,也就是下一个结点——首结点。
首结点具有其数据域,里面存放首结点的数据;
首结点的指针域存放第二个结点的地址,一个结构体的地址。
而这些地址不像连续存放的数组,他们是非连续存放的。
最后一个结点的指针域指向NULL,由此一个链表完成。
三、链表结点结构体
结点数据结构:
struct Node
{
int data;
struct Node* next;
};
一个结点是一个结构体,
data为其数据域,
next为其指针域,
next的类型是struct Node*,也就是一个Node类型的指针。
我们可以这样简化一下:
typedef struct Node
{
int data;
Node* next;
}Node;
上面这种只包含一个指针域、由n个节点链接形成的链表,就称为线型链表或者单向链表。
再看如下声明:
typedef struct Node
{
int data;
Node* next;
}Node,*LinkedList;
这里typedef后面跟了两个名称,
具体什么意思?我们看下面这一段解释:
typedef struct AAA{ ...... }b,*c
b是声明变量的别名,
比如b z;
就与struct AAA z;
等价。
c是声明指针的别名,
比如c y;
就与struct AAA *y;
等价。换句话说,
b是struct AAA的别名,
c是struct AAA *的别名。
再看原代码:
一个是Node,一个是*LinkedList。
这里Node是struct Node的别名,
*LinkedList是struct Node*的别名,也就是指针。
四、链表与数组
链表只能顺序访问,不能随机访问,链表这种存储方式最大缺点就是容易出现断链,
一旦链表中某个节点的指针域数据丢失,那么意味着将无法找到下一个节点,该节点后面的数据将全部丢失。
但是数组相较于链表也有以下不足:
数组(包括结构体数组)的实质是一种线性表的顺序表示方式,
虽然它的优点是使用直观,便于快速、随机地存取线性表中的任一元素,
但缺点是对其进行 插入和删除操作时需要移动大量的数组元素,
同时由于数组属于静态内存分配,定义数组时必须指定数组的长度,
程序一旦运行,其长度就不能再改变,实际使用个数不能超过数组元素最大长度的限制,否则就会发生下标越界的错误,
低于最大长度时又会造成系统资源的浪费,因此空间效率差。

















 2525
2525




 到【灌水乐园】发言
到【灌水乐园】发言







